Le projet a grandi, la bibliothèque résout désormais toutes les tâches de base du traitement de la langue russe naturelle: segmentation en jetons et phrases, analyse morphologique et syntaxique, lemmatisation, extraction d'entités nommées.

Pour les articles de presse, la qualité sur toutes les tâches est comparable ou supérieure aux solutions existantes... Par exemple, Natasha fait face à la tâche NER de 1 point de pourcentage pire que Deeppavlov BERT NER (F1 PER 0.97, LOC 0.91, ORG 0.85), le modèle pèse 75 fois moins (27 Mo), fonctionne sur le CPU 2 fois plus vite (25 articles / sec ) que BERT NER sur GPU.
Il y a 9 référentiels dans le projet , la bibliothèque Natasha les combine sous une seule interface. Dans l'article, nous parlerons de nouveaux outils, les comparerons avec des solutions existantes: Deeppavlov , SpaCy , UDPipe .

Ce longridu précédé d'une série de publications sur le site natasha.github.io :Si la taille du texte ci-dessous vous fait peur, regardez les 20 premières minutes du tube stream sur l'histoire du projet Natasha, il y a un court récit:
- Natasha - NER compact de qualité pour la langue russe
- Navec - intégration compacte pour la langue russe
- Corus - collection d'ensembles de données PNL en russe
- Razdel - segmentation du texte en langue russe en jetons et offres
- Naeval - Comparaison quantitative des systèmes pour la PNL russophone
- Nerus est un grand ensemble de données synthétiques en russe avec un balisage de la morphologie, de la syntaxe et des entités nommées
Le texte utilise des notes et des discussions du chat t.me/natural_language_processing , les liens vers de nouveaux matériaux apparaissent au même endroit:
- Pourquoi Natasha n'utilise pas de transformateurs. BERT en 100 lignes
- Modèles Slovnet BERT
- Tube stream sur l'histoire du projet Natasha
- Documentation Yargy mise à jour
- Ressources supplémentaires sur l'analyseur Yargy
Pour ceux qui aiment écouter plus, consultez le discours horaire au Datafest 2020, il couvre presque cet article:
Contenu:
- Natasha — .
- Razdel —
- Slovnet — deep learning
- Navec —
- Nerus — ,
- Corus — +
- Naeval — NLP
- Yargy- —
- Ipymarkup —
Natasha — .

Auparavant, la bibliothèque Natasha résolvait le problème NER pour la langue russe, était construite sur des règles , montrait une qualité et des performances moyennes. Maintenant, Natasha est un grand projet, il se compose de 9 référentiels . La bibliothèque Natasha les réunit sous une seule interface, résout les tâches de base du traitement de la langue russe naturelle: segmentation en jetons et phrases, plongements pré-entraînés, analyse de la morphologie et de la syntaxe, lemmatisation, NER. Toutes les solutions affichent les meilleurs résultats dans les sujets d'actualité , fonctionnent rapidement sur le processeur.
Natasha est similaire à d'autres bibliothèques combinées: SpaCy , UDPipe , Stanza... SpaCy initialise et appelle implicitement les modèles, l'utilisateur passe le texte à la fonction magique
nlp, obtient un document entièrement analysé.
import spacy
# load ,
# , NER
nlp = spacy.load('...')
# ,
text = '...'
doc = nlp(text)
L'interface de Natasha est plus verbeuse. L'utilisateur initialise explicitement les composants: charge les imbrications pré-entraînées, les transmet aux constructeurs de modèles. Sam appelle des méthodes
segment, tag_morph, la parse_syntaxsegmentation en jetons et de la demande, l' analyse de la morphologie et de la syntaxe.
>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = ' , , 2019 () ...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
ADP
PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
┌──► nsubj
│
│ ┌► case
│ └─
│ ┌─
│ └► flat:name
┌─────┌─└───
│ │ ┌──► , punct
│ │ │ ┌► mark
│ └►└─└─ ccomp
│ │ ┌► case
│ └──►└─ obl
...
L'extracteur d'entité nommé ne dépend pas des résultats de l'analyse morphologique et de l'analyse, il peut être utilisé séparément.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
, ,
LOC──── LOC──── PER───────
2019
LOC──────────────
()
LOC─── ORG───────────────────────────────────────
...
PER────────────
Natasha résout le problème de la lemmatisation, utilise Pymorphy2 et les résultats de l'analyse morphologique.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
'': '',
',': ',',
'': '',
'': ''
...
Pour ramener la phrase à une forme normale, il ne suffit pas de trouver les lemmes des mots individuels, pour le ministère russe des Affaires étrangères, ce sera le ministère russe des Affaires étrangères, pour l'Organisation des nationalistes ukrainiens - l'Organisation nationaliste ukrainienne. Natasha utilise les résultats de l'analyse, prend en compte les relations entre les mots, normalise les entités nommées.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'': '',
'': '',
' ': ' ',
' ': ' ',
'': '',
' ()': ' ()',
' ': ' ',
...
Natasha trouve des noms, des noms d'organisations et des noms de lieux dans le texte. Pour les noms dans la bibliothèque, il existe un ensemble de règles prêtes à l' emploi pour l' analyseur Yargy , le module divise les noms normalisés en parties, à partir de "Viktor Fedorovich Yushchenko" est obtenu
{first: , last: , middle: }.
>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
' ': {'first': '', 'last': ''},
'': {'last': ''},
' ': {'first': '', 'last': ''}}
La bibliothèque contient des règles d'analyse des dates, des montants d'argent et des adresses, elles sont décrites dans la documentation et le livre de référence .
La bibliothèque Natasha est bien adaptée à la démonstration des technologies de projet, utilisées dans l'éducation. Les archives avec des pondérations de modèle sont intégrées dans le package, après l'installation, vous n'avez pas besoin de télécharger et de configurer quoi que ce soit.
Natasha combine d'autres bibliothèques de projets sous une seule interface. Pour résoudre des problèmes pratiques, vous devez les utiliser directement:
- Razdel - segmentation du texte en phrases et jetons;
- Navec - encastrements compacts de haute qualité;
- Slovnet - modèles compacts modernes pour la morphologie, la syntaxe, le NER;
- Yargy - règles et vocabulaires pour extraire des informations structurées;
- Ipymarkup - visualisation du NER et du balisage syntaxique;
- Corus - une collection de liens vers des ensembles de données publics en russe;
- Nerus est un grand corpus avec un balisage automatique d'entités nommées, de morphologie et de syntaxe.
Razdel - segmentation du texte en langue russe en jetons et offres

La bibliothèque Razdel fait partie du projet Natasha, divise le texte en russe en jetons et en phrases. Instructions d'installation , exemple d'utilisation et mesures de performances dans le référentiel Razdel.
>>> from razdel import tokenize, sentenize
>>> text = '- 0.5 (50/64 ³, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='-'),
Substring(start=14, stop=16, text=''),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text=''),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - " ?" - " --".
... . . . . ,
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- " ?"'),
Substring(start=24, stop=40, text='- " --".'),
Substring(start=41, stop=56, text=' . . . .'),
Substring(start=57, stop=76, text=' , ')]
Les modèles modernes ne se soucient souvent pas de la segmentation, utilisent BPE , montrent des résultats remarquables, se souviennent de toutes les versions de GPT et du zoo BERT . Natasha résout les problèmes d'analyse de la morphologie et de la syntaxe, ils n'ont de sens que pour des mots séparés dans une phrase. Par conséquent, nous abordons de manière responsable l'étape de la segmentation, nous essayons de répéter le balisage des ensembles de données ouverts populaires: SynTagRus , OpenCorpora , GICRYA .
La vitesse et la qualité de Razdel sont comparables ou supérieures à celles d'autres solutions open source pour la langue russe.
| Solutions de segmentation de jetons | Erreurs pour 1000 jetons | Temps de traitement, secondes |
| Regexp-baseline | 19 | 0,5 |
| SpaCy
|
17 | 5,4 |
| NLTK
|
130 | 3.1 |
| MyStem
|
19 | 4,5 |
| Moïse
|
Onze | 1,9 |
| SegTok
|
12 | 2,1 |
| SpaCy Russian Tokenizer
|
8 | 46.4 |
| RuTokenizer
|
15 | 1.0 |
| Razdel
|
7 | 2.6 |
| 1000 | , | |
| Regexp-baseline | 76 | 0.7 |
| SegTok
|
381 | 10.8 |
| Moses
|
166 | 7.0 |
| NLTK
|
57 | 7.1 |
| DeepPavlov
|
41 | 8.5 |
| Razdel | 43 | 4.8 |
Nombre moyen d'erreurs pour 4 jeux de données : SynTagRus , OpenCorpora , GICRYA et RNC . Plus de détails dans le référentiel Razdel .
Pourquoi avez-vous besoin de Razdel, si une ligne de base avec une ligne régulière donne une qualité similaire et qu'il existe de nombreuses solutions toutes faites pour la langue russe? En fait, Razdel n'est pas seulement un tokenizer, mais un petit moteur de segmentation basé sur des règles. La segmentation est une tâche de base, souvent rencontrée dans la pratique. Par exemple, il y a un acte judiciaire, vous devez mettre en évidence le dispositif et le diviser en paragraphes. Naturellement, les solutions standard ne peuvent pas faire cela. Découvrez comment écrire vos propres règles dans le code source . En outre, nous parlerons de la façon de vous pousser et de créer une solution optimale pour les jetons et les offres sur notre moteur.
Quelle est la difficulté?
En russe, les phrases se terminent généralement par un point, un point d'interrogation ou un point d'exclamation. Divisons simplement le texte avec une expression régulière
[.?!]\s+. Cette solution donnera 76 erreurs pour 1000 phrases. Types et exemples d'erreurs:
Abréviations
... toute plate-forme avec une audience de 3 000 personnes ou plus est un blogueur.
... un battement les surmonta depuis la fin du 17e siècle;
… Au théâtre musical de chambre nommé d'après ▒B.A. Pokrovsky.
Les initiales
dans le sillage de l'opéra "Idomeneo" V.A.▒Motsarta - R.▒Shtrausa ...
Listes
2.▒dumal sera dans le consulat finlandais assez longue file d'attente ...
g.▒bilety entraîne les chemins de fer russes ...
La fin de la phrase smiley ou points typographiques
Celui qui propose un moyen de se débarrasser des inconvénients - grâce à ça :) ▒ J'ai regardé, réfléchi ... ▒ Maintenant, c'est plus désagréable, car le contenu sera cassé.
Citations, discours direct, à la fin de la phrase un guillemet
- avez-vous une épouse en ville? »▒« Pour qui a une épouse? »
«C'est tellement bon que je ne suis pas comme ça!» «Maintenant, en traduisant, j'ai commis une erreur freudienne:« idologie ».
Razdel prend en compte ces nuances, réduisant le nombre d'erreurs de 76 à 43 pour 1000 phrases.
La situation est similaire avec les jetons. Une bonne solution de base est un regex
[--]+|[0-9]+|[^-0-9 ], il fait 19 erreurs pour 1000 jetons. Exemples:
nombres fractionnaires, ponctuation complexe
... Fin des années 1980 - début des années 1990
... BS-▒3 peut être noté un peu moins de masse (3▒, ▒6 t)
- et elle est morte ▒.▒. Comprends-tu la fille, faucon? ▒!
Razdel réduit le taux d'erreur à 7 pour 1000 jetons.
Principe d'opération
Le système est construit sur des règles. Le principe de segmentation en jetons et offres est le même.
Collection de candidats
On retrouve dans le texte tous les candidats pour la fin de la phrase: points, ellipses, crochets, guillemets.
6.▒ L'option de réponse la plus fréquente et en même temps la plus cotée «Je suis content» ▒ (13 affirmations, 25 points) ▒– les situations d'approbation et d'encouragement. ▒7.▒ Il convient de noter que dans la réponse «Je sais», il est estimé comme , mais seulement une fois que la réponse «je suis une femme» est rencontrée ▒; ▒ il y a des déclarations «un seul mariage est tout ce qui m'attend dans cette vie» ▒ et «tôt ou tard je devrai accoucher» ▒.▒ Compilateurs: V.▒P.▒Golovin , F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov.
Pour les jetons, nous divisons le texte en atomes. La frontière du jeton ne passe pas exactement à l'intérieur de l'atome.
À la fin de 1980▒-▒▒-début1990▒-▒▒
BS▒-▒3▒ il est possible▒de marquer▒ une masse légèrement▒ plus petite▒ (▒3▒, ▒6▒▒) ▒
▒— Da▒and▒umerla▒.▒.▒.▒Got ▒ligirl, ▒le faucon▒? ▒!
syndicat
Nous contournons systématiquement les candidats à la séparation, supprimons ceux qui ne sont pas nécessaires. Nous utilisons une liste d'heuristiques.
Élément de liste. Le séparateur est un point ou une parenthèse, à gauche un chiffre ou une lettre
6. La réponse la plus fréquente et en même temps très appréciée «Je suis content» (13 affirmations, 25 points) est une situation d'approbation et d'encouragement. 7.▒ Il est à noter que dans la réponse "Je sais" ...
Initiales. Séparateur - point, une lettre majuscule à gauche
... Compilateurs: V.▒P.▒Golovin, F.▒V.▒Zanichev, A.▒L.▒Rastorguev, R.▒V.▒Savko, I.▒I.▒Tuchkov ...
Il n'y a pas d'espace à droite du séparateur
... mais une seule fois est la réponse "Je suis une femme" ▒; il y a des déclarations «un seul mariage est tout ce qui m'attend dans cette vie» et «tôt ou tard je devrai accoucher» ▒.
Il n'y a pas de marque de fin de phrase avant le guillemet fermant ou la parenthèse, ce n'est pas une citation ou un discours direct
6. La réponse la plus fréquente et la plus appréciée est «Je suis content» «(13 affirmations, 25 points) ▒ - situations où l'on obtient l'approbation et l'encouragement. ... "un seul mariage est tout ce qui m'attend dans cette vie" et "tôt ou tard je devrai accoucher".
En conséquence, il reste deux séparateurs, nous les considérons comme des fins de phrases.
6. La variante la plus fréquente et en même temps très appréciée des réponses «Je suis content» (13 affirmations, 25 points) est une situation d'approbation et d'encouragement. Il est à noter que dans la réponse «Je sais», il est évalué comme le plus stéréotypé, mais seulement une fois que la réponse «Je suis une femme» est rencontrée; il y a des déclarations «un seul mariage est tout ce qui m'attend dans cette vie» et «tôt ou tard je devrai accoucher.» ▒Composants: V.P. Golovin, F.V. Zanichev, A.L. Rastorguev, R.V. Savko, I. I. Tuchkov.
La procédure est similaire pour les jetons, les règles sont différentes.
Fraction ou nombre rationnel
... (3▒, ▒6 t) ...
Ponctuation complexe
- oui, et mort.▒.▒. Comprends-tu la fille, faucon? ▒!
Il n'y a pas d'espace autour du trait d'union, ce n'est pas le début du discours direct
Fin 1980▒-▒ - début 1990▒-▒
BS▒-▒3 on peut le noter ...
Tout ce qui reste est considéré comme les limites des jetons.
À la fin des années 1980-x▒-début -1990-x▒
BS-3▒, il est possible▒de▒notifier▒légèrement basse (▒3,6▒t▒) ▒
▒ - oui et décédé. ..▒Got it▒li▒girl, ▒sokol▒?!
Limites
Les règles Razdel sont optimisées pour un texte parfaitement écrit avec une ponctuation correcte. La solution fonctionne bien avec les articles de presse, les textes littéraires. Sur les posts des réseaux sociaux, les transcriptions de conversations téléphoniques, la qualité est moindre. S'il n'y a pas d'espace entre les phrases ou pas de point à la fin, ou si la phrase commence par une lettre minuscule, Razdel fera une erreur. Lisez
comment écrire des règles pour vos tâches dans le code source , ce sujet n'a pas encore été divulgué dans la documentation.
Slovnet - modélisation d'apprentissage en profondeur pour le traitement naturel de la langue russe

Dans le cadre du projet, Natasha Slovnet est engagée dans l'enseignement et l'inférence de modèles modernes de PNL russophone. La bibliothèque contient des modèles compacts de haute qualité pour l'extraction d'entités nommées, l'analyse de la morphologie et de la syntaxe. La qualité de toutes les tâches est comparable ou supérieure à d' autres solutions ouvertes pour la langue russe sur les textes d'actualité. Instructions d'installation , exemples d'utilisation - dans le référentiel Slovnet . Regardons de plus près comment la solution du problème NER est arrangée, pour la morphologie et la syntaxe, tout est par analogie.
Fin 2018, après un article de Google sur BERT , il y avait beaucoup de progrès dans la PNL anglophone. En 2019, les gars du projet DeepPavlovadapté du BERT multilingue pour le russe, RuBERT est apparu . Un chef CRF a été formé au sommet , il s'est avéré DeepPavlov BERT NER - SOTA pour la langue russe. Le modèle a une excellente qualité, 2 fois moins d'erreurs que le plus proche poursuivant DeepPavlov NER , mais la taille et les performances sont effrayantes: 6 Go - consommation de RAM GPU, 2 Go - taille du modèle, 13 articles par seconde - performances sur un bon GPU.
En 2020, dans le projet Natasha, nous avons réussi à nous rapprocher en qualité de DeepPavlov BERT NER, la taille du modèle s'est avérée 75 fois plus petite (27 Mo), la consommation de mémoire est 30 fois inférieure (205 Mo), la vitesse est 2 fois plus élevée sur le CPU (25 articles par seconde) ).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER / LOC / ORG F1 par tokens, moyenne par Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0,97 / 0,91 / 0,85 | 0,98 / 0,92 / 0,86 |
| Taille du modèle | 27 Mo | 2 Go |
| Consommation de mémoire | 205 Mo | 6 Go (GPU) |
| Performance, articles de presse par seconde (1 article ≈ 1KB) | 25 par processeur (Core i5) | 13 GPU (RTX 2080 Ti), 1 processeur |
| Temps d'initialisation, secondes | 1 | 35 |
| La bibliothèque prend en charge | Python 3.5+, PyPy3 | Python 3.6+ |
| Dépendances | NumPy | TensorFlow |
La qualité de Slovnet NER est 1 point de pourcentage inférieure à celle de SOTA DeepPavlov BERT NER, la taille du modèle est 75 fois plus petite, la consommation de mémoire est 30 fois inférieure, la vitesse est 2 fois plus élevée sur le CPU. Comparaison avec SpaCy, PullEnti et d'autres solutions pour NER russophone dans le référentiel Slovnet .
Comment obtenez-vous ce résultat? Recette courte:
Slovnet NER = Slovnet BERT NER - analogue de DeepPavlov BERT NER + distillation par balisage synthétique ( Nerus ) dans WordCNN-CRF avec plongements quantifiés ( Navec ) + moteur d'inférence sur NumPy.
Maintenant en ordre. Le plan est le suivant: former un modèle lourd avec l'architecture BERT sur un petit jeu de données annoté manuellement. Nous le marquons avec un corpus d'actualités et nous obtenons un gros jeu de données d'entraînement synthétique sale. Entraînons-y un modèle primitif compact. Ce processus s'appelle la distillation: le modèle lourd est l'enseignant, le modèle compact est l'élève. On s'attend à ce que l'architecture BERT soit redondante pour le problème NER, le modèle compact ne perdra pas grand-chose en qualité face au lourd.
Enseignant modèle
DeepPavlov BERT NER se compose d'un encodeur RuBERT et d'une tête CRF. Notre modèle d'enseignant lourd répète cette architecture avec des améliorations mineures.
Tous les benchmarks mesurent la qualité du TNS sur les textes d'actualité. Entraînons RuBERT aux nouvelles. Le référentiel Corus contient des liens vers un corpus d'actualités public en russe, soit un total de 12 Go de textes. Nous utilisons les techniques de l'article Facebook sur RoBERTa : gros lots agrégés, masque dynamique, refus de prédire la phrase suivante (NSP). RuBERT utilise un vaste vocabulaire de 120 000 sous-jetons - un héritage du BERT multilingue de Google. En réduisant la taille aux 50 000 actualités les plus fréquentes, la couverture diminuera de 5%. Obtenir des actualités, le modèle prédit des sous-jetons déguisés dans l'actualité 5 points de pourcentage mieux que RuBERT (63% dans le top 1).
Entraînons l'encodeur NewsRuBERT et la tête CRF pour 1000 articles de Collection5 . Nous obtenons Slovnet BERT NER , la qualité est supérieure de 0,5 point de pourcentage à celle de DeepPavlov BERT NER, la taille du modèle est 4 fois plus petite (473 Mo), cela fonctionne 3 fois plus vite (40 articles par seconde).
NewsRuBERT = RuBERT + 12 Go d'actualités + techniques de RoBERTa + dictionnaire 50K.
Slovnet BERT NER (analogue de DeepPavlov BERT NER) = NewsRuBERT + CRF head + Collection5.
Désormais, pour entraîner des modèles avec une architecture de type BERT, il est courant d'utiliser les Transformers de Hugging Face. Les transformateurs sont 100 000 lignes de code Python. Lorsque la perte ou les déchets explosent par déduction, il est difficile de comprendre ce qui n'a pas fonctionné. D'accord, beaucoup de code y est dupliqué. Même si nous formons RoBERTa, nous pouvons localiser rapidement le problème à ~ 3000 lignes de code, mais c'est aussi beaucoup. Avec PyTorch moderne, la bibliothèque Transformers n'est pas aussi pertinente. Avec
torch.nn.TransformerEncoderLayerle code modèle de type RoBERTa prend 100 lignes:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Ce n'est pas un prototype, le code est copié du référentiel Slovnet . Les transformateurs sont bons à lire, ils font beaucoup de travail, bourrent le code des articles avec Arxiv, souvent la source Python est plus claire que l'explication dans un article scientifique.
Ensemble de données synthétiques
Marquons 700 000 articles du corpus Lenta.ru avec un modèle lourd. Nous obtenons un énorme ensemble de données d'entraînement synthétique. L'archive est disponible dans le référentiel Nerus du projet Natasha. Le balisage est de très haute qualité, F1 estime par jetons: PER - 99,7%, LOC - 98,6%, ORG - 97,2%. De rares exemples d'erreurs:
ORG────────────── LOC────────────────────────────
241- 4- 10-
<
LOC─── LOC──────
>.
───────────~~~~~~~~~~~
ORG────────────────────~~~~~~~~~~~~~~~~
.
LOC───
<>
~~~~~~~~ LOC──────────────────
.
~~~~ ~~~~~~ LOC───
.
LOC────
-
PER─────────────────────
M&A.
~~~
:
~~~~~~~~~~~~ORG─── LOC──
,
PER─────── LOC───
,
ORG─ LOC─────────────
.
LOC
Apprenant modèle
Il n'y a eu aucun problème avec le choix de l'architecture du modèle de l'enseignant lourd, il n'y avait qu'une seule option - les transformateurs. Le modèle étudiant compact est plus difficile, il existe de nombreuses options. De 2013 à 2018, de l'avènement de word2vec à l'article sur BERT, l'humanité a proposé un tas d'architectures de réseaux neuronaux pour résoudre le problème des NER. Tous ont un schéma commun:
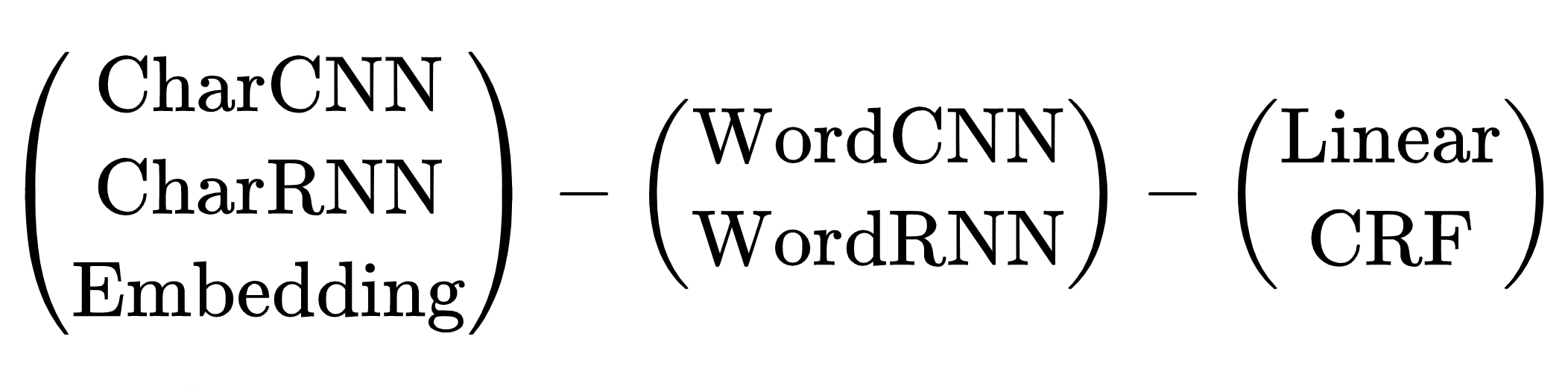
Schéma d'architectures de réseau neuronal pour la tâche NER: encodeur de jetons, encodeur de contexte, décodeur de balises. Explications des abréviations dans un article de synthèse de Yang (2018) .
Il existe de nombreuses combinaisons d'architectures. Lequel choisir? Par exemple, (CharCNN + Embedding) -WordBiLSTM-CRF est un diagramme de modèle d'un article sur DeepPavlov NER , SOTA pour la langue russe jusqu'en 2019.
On saute les options avec CharCNN, CharRNN, lancer un petit réseau de neurones par symboles sur chaque token n'est pas notre chemin, trop lent. Je voudrais aussi éviter WordRNN, la solution devrait fonctionner sur le CPU, multiplier les matrices sur chaque jeton lentement. Pour NER, le choix entre Linéaire et CRF est conditionnel. Nous utilisons l'encodage BIO, l'ordre des balises est important. Nous devons endurer de terribles freins, utiliser CRF. Il reste une option - Embedding-WordCNN-CRF. Ce modèle n'est pas sensible à la casse, pour NER c'est important, «espoir» n'est qu'un mot, «espoir» est peut-être un nom. Ajouter ShapeEmbedding - intégration avec des contours de jetons, par exemple: "NER" - EN_XX, "Vainovich" - RU_Xx, "!" - PUNCT_!, "Et" - RU_x, "5.1" - NUM, "New York" - RU_Xx-Xx. Schéma Slovnet NER - (WordEmbedding + ShapeEmbedding) -WordCNN-CRF.
Distillation
Entraînons Slovnet NER sur un énorme ensemble de données synthétiques. Comparons le résultat avec le modèle d'enseignement lourd Slovnet BERT NER. La qualité est calculée et moyennée sur la Collection5, Gareev, factRuEval-2016, BSNLP-2019 marquée manuellement. La taille de l'échantillon de formation est très importante: pour 250 articles de presse (factRuEval-2016), la moyenne pour PER, LOC, LOG F1 est de 0,64, pour 1000 (analogue à Collection5) - 0,81, pour l'ensemble de données - 0,91, la qualité Slovnet BERT NER est de 0,92.
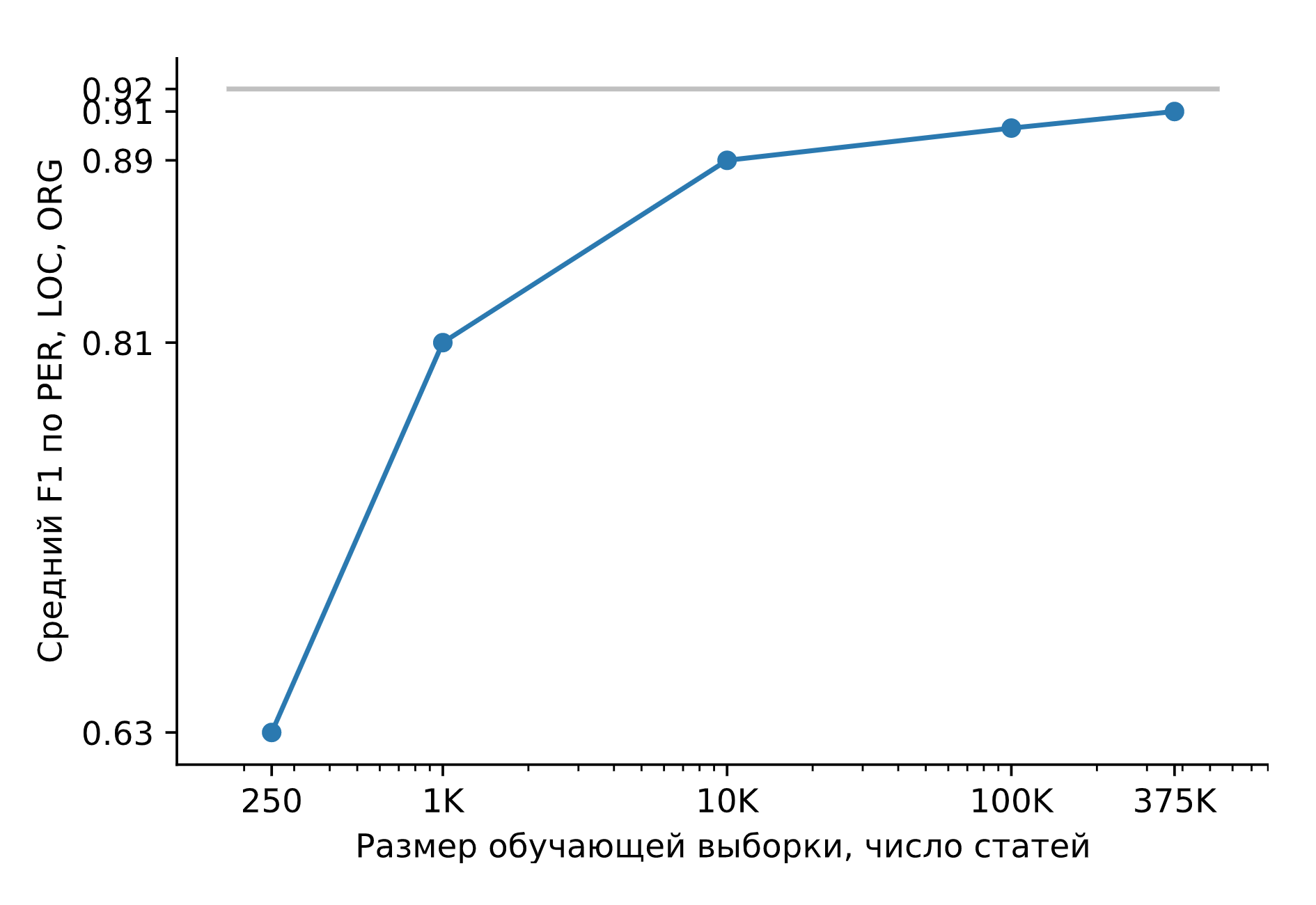
Qualité Slovnet NER, dépendance du nombre d'exemples de formation synthétique. Ligne grise - qualité Slovnet BERT NER. Slovnet NER ne voit pas d'exemples marqués à la main, il s'entraîne uniquement sur des données synthétiques.
Le modèle d'élève primitif est de 1 point de pourcentage pire que le modèle d'enseignant dur. C'est un résultat magnifique. Une recette universelle se propose:
Nous marquons manuellement certaines données. Nous formons un transformateur lourd. Nous générons beaucoup de données synthétiques. Nous formons un modèle simple sur un grand échantillon. On obtient la qualité du transformateur, la taille et les performances d'un modèle simple.
Dans la bibliothèque Slovnet, il y a deux autres modèles formés selon cette recette: Slovnet Morph - marqueur morphologique, Slovnet Syntax - analyseur syntaxique. Slovnet Morph est en retard de 2 points de pourcentage sur le modèle des enseignants lourds , la syntaxe Slovnet - de 5 . Les deux modèles offrent une meilleure qualité et de meilleures performances que les solutions russes existantes pour les articles de presse.
Quantification
Slovnet NER mesure 289 Mo. 287 Mo sont occupés par une table avec des plongements. Le modèle utilise un vocabulaire étendu de 250 000 lignes et couvre 98% des mots des textes d'actualité. À l'aide de la quantification , remplacez les vecteurs flottants de 300 dimensions par des vecteurs de 8 bits à 100 dimensions. La taille du modèle sera réduite 10 fois (27 Mo), la qualité ne changera pas. La bibliothèque Navec fait partie du projet Natasha, une collection de plongements pré-entraînés quantifiés. Les poids entraînés sur la fiction prennent 50 Mo, en contournant tous les modèles statiques de RusVectores selon des estimations synthétiques .
Inférence
Slovnet NER utilise PyTorch pour la formation. Le package PyTorch pèse 700 Mo, je ne veux pas le faire glisser en production pour en déduire. PyTorch ne fonctionne pas non plus avec l'interpréteur PyPy . Slovnet est utilisé en conjonction avec un analyseur Yargy, un analogue de l' analyseur Yandex Tomita . Avec PyPy, Yargy fonctionne 2 à 10 fois plus vite, selon la complexité des grammaires. Je ne veux pas perdre de vitesse à cause de ma dépendance à PyTorch.
La solution standard consiste à utiliser TorchScript ou à convertir le modèle en ONNX , à faire l' inférence dans ONNXRuntime . Slovnet NER utilise des blocs non standard: plongements quantifiés, décodeur CRF. TorchScript et ONNXRuntime ne prennent pas en charge PyPy.
Slovnet NER est un modèle simple,implémentez manuellement tous les blocs dans NumPy , utilisez les poids calculés par PyTorch. Appliquons un peu de magie NumPy, implémentons soigneusement le bloc CNN , le décodeur CRF , le déballage de l'incorporation quantifiée prend 5 lignes . La vitesse d'inférence sur le processeur est la même qu'avec ONNXRuntime et PyTorch, 25 articles de presse par seconde sur Core i5.
La technique fonctionne sur des modèles plus complexes: Slovnet Morph et Slovnet Syntax sont également implémentés dans NumPy. Slovnet NER, Morph et Syntax partagent une table d'intégration commune. Sortons les poids dans un fichier séparé, la table n'est pas dupliquée en mémoire et sur disque:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Limites
Natasha extrait des entités standards: noms, noms de toponymes et organisations. La solution se montre de bonne qualité dans l'actualité. Comment travailler avec d'autres entités et types de textes? Nous devons former un nouveau modèle. Ce n'est pas facile à faire. Nous payons pour la taille compacte et la vitesse de travail par la complexité de la préparation du modèle. Ordinateur portable de script pour préparer un modèle d'enseignant lourd , ordinateur portable de script pour un modèle d'étudiant , instructions pour préparer des plongements quantifiés .
Navec - intégration compacte pour la langue russe

Les modèles compacts sont faciles à utiliser. Ils démarrent rapidement, utilisent peu de mémoire et davantage de processus parallèles tiennent sur une seule instance.
En PNL, 80 à 90% des pondérations du modèle se trouvent dans la table d'intégration. La bibliothèque Navec fait partie du projet Natasha, une collection d'incorporations pré-entraînées pour la langue russe. En termes de métriques de qualité intrinsèque, elles sont légèrement en dessous des meilleures solutions de RusVectores , mais la taille de l'archive avec des poids est 5 à 6 fois plus petite (51 Mo), le dictionnaire est 2 à 3 fois plus grand (500 000 mots).
| Qualité * | Taille du modèle, Mo | Taille du dictionnaire, × 10 3 | |
| Navec | 0,719 | 50,6 | 500 |
| RusVectores | 0,638-0,726 | 220,6–290,7 | 189-249 |
Nous parlerons des bons vieux plongements mot par mot qui ont révolutionné la PNL en 2013. La technologie est toujours d'actualité. Dans le projet Natasha, les modèles d' analyse de la morphologie , de la syntaxe et de l' extraction d'entités nommées fonctionnent sur les incorporations Navec mot par mot et montrent une qualité supérieure à d'autres solutions ouvertes .
RusVectores
Pour la langue russe, il est d'usage d'utiliser des plongements pré-entraînés de RusVectores , ils ont une caractéristique désagréable: le tableau ne contient pas de mots, mais des paires «word_POS-tag». L'idée est bonne, pour le couple "four_VERB" on attend un vecteur similaire à "cook_VERB", "cook_VERB", et pour "four_NOUN" - "hut_NOUN", "four_NOUN".
En pratique, il n'est pas pratique d'utiliser de tels plongements. Il ne suffit pas de diviser le texte en jetons, pour chacun, vous devez définir d'une manière ou d'une autre la balise POS. La table d'intégration gonfle. Au lieu d'un mot «devenir», nous stockons 6: 2 raisonnables «devenir_VERB», «devenir_NOUN» et 4 étranges «devenir_ADV», «devenir_PROPN», «devenir_NUM», «devenir_ADJ». Il y a 195 000 mots uniques dans une table de 250 000 entrées.
Qualité
Estimons la qualité des plongements sur le problème de proximité sémantique. Prenons quelques mots, pour chacun, nous trouverons un vecteur d'intégration et calculerons la similitude cosinus. Navec pour les mots similaires «tasse» et «cruche» renverra 0,49, pour «fruit» et «four» - -0,0047. Collectons de nombreuses paires avec des repères de similitude, calculons la corrélation de Spearman avec nos réponses.
Les auteurs de RusVectores utilisent une petite liste de tests soigneusement vérifiée et révisée de paires SimLex965 . Ajoutons un nouveau Yandex LRWC et des jeux de données du projet RUSSE : HJ , RT , AE , AE2 :
| Qualité moyenne sur 6 jeux de données | Temps de chargement, secondes | Taille du modèle, Mo | Taille du dictionnaire, × 10 3 | ||
| Navec | hudlit_12B_500K_300d_100q |
0,719 | 1.0 | 50,6 | 500 |
news_1B_250K_300d_100q |
0,653 | 0,5 | 25,4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0,692 | 3,3 | 220,6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0,691 | 5,0 | 290,0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0,726 | 5.2 | 290,7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0,638 | 8,0 | 2741,9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0,664 | 16,4 | 2752,1 | 195 |
La qualité est
hudlit_12B_500K_300d_100qcomparable ou meilleure que celle des solutions RusVectores, le dictionnaire est 2 à 3 fois plus grand, la taille du modèle est 5 à 6 fois plus petite. Comment avez-vous obtenu cette qualité et cette taille?
Principe d'opération
hudlit_12B_500K_300d_100q- Intégration GloVe entraînée pour 145 Go de fiction . Prenons l'archive avec les textes du projet RUSSE . Nous allons utiliser la mise en œuvre du Glove original en C et l' envelopper dans une interface de Python pratique .
Pourquoi pas word2vec? Les expériences sur un grand ensemble de données sont plus rapides avec GloVe. Une fois que nous avons calculé la matrice de collocation, utilisez-la pour préparer des plongements de différentes dimensions, choisissez la meilleure option.
Pourquoi pas fastText? Dans le projet Natasha, nous travaillons avec des textes d'actualité. Il y a peu de fautes de frappe, le problème des jetons OOV est résolu par un grand dictionnaire. 250 000 lignes du tableau
news_1B_250K_300d_100qcouvrent 98% des mots des articles de presse.
Taille du dictionnaire
hudlit_12B_500K_300d_100q- 500 000 entrées, il couvre 98% des mots des textes de fiction. La dimension optimale des vecteurs est de 300. Une table de 500 000 × 300 de nombres flottants prend 578 Mo, la taille de l'archive avec des poids hudlit_12B_500K_300d_100qest 12 fois plus petite (48 Mo). C'est une question de quantification.
Quantification
Remplaçons les nombres flottants 32 bits par des codes 8 bits: [−∞, −0,86) - code 0, [−0,86, -0,79) - code 1, [-0,79, -0,74) - 2,…, [0,86, ∞) - 255. La taille de la table diminuera de 4 fois (143 Mo).
:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
────── ──────
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
────── ──────
:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
─── ───
76 251 191 188 118 207 195 18 118
─── ───
Les données sont rugueuses, différentes valeurs -0,005 et -0,003 remplacent un code 127, -0,030 et -0,031 - 118 Remplaçons
par le code non pas un, mais 3 nombres. Nous regroupons tous les triplets de nombres de la table d'intégration en utilisant l'algorithme k-means en 256 clusters, au lieu de chaque triplet, nous stockerons un code de 0 à 255. La table diminuera de 3 fois (48 Mo). Navec utilise la bibliothèque PQk-means , il divise la matrice en 100 colonnes, les clusters chacun séparément, la qualité sur les tests synthétiques diminuera de 1 point de pourcentage. La quantification est claire dans l'article Quantificateurs de produits pour k-NN .
Les plongements quantifiés sont plus lents que ceux habituels. Le vecteur compressé doit être décompressé avant utilisation. Nous mettons soigneusement en œuvre la procédure, appliquons la magie Numpy, dans PyTorch, nous utilisons torch.gather . Dans Slovnet NER, l'accès à la table d'intégration prend 0,1% du temps de calcul total.
Un module
NavecEmbeddingde la bibliothèque Slovnet intègre Navec dans les modèles PyTorch:
>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus est un grand ensemble de données synthétiques avec un balisage de morphologie, de syntaxe et d'entités nommées

Dans le projet Natasha, l'analyse de la morphologie, la syntaxe et l'extraction des entités nommées sont faites par 3 modèles compacts: Slovnet NER , Slovnet Morph et Slovnet Syntax . La qualité des solutions est de 1 à 5 points de pourcentage inférieure à celle de leurs homologues lourds dotés d'une architecture BERT, leur taille est 50 à 75 fois plus petite et la vitesse du processeur est 2 fois plus élevée. Les modèles sont formés sur un énorme ensemble de données synthétiques Nerus , dans une archive de 700000 articles de presse avec balisage CoNLL-U- de la morphologie, de la syntaxe et des entités nommées:
# newdoc id = 0
# sent_id = 0_0
# text = - , ...
1 - _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 _ ADP _ _ 4 case _ Tag=O
3 _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 _ ADP _ _ 11 case _ Tag=O
10 _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 _ ADP _ _ 18 case _ Tag=O
18 _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = , , , ...
1 _ ADP _ _ 2 case _ Tag=O
2 _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax - modèles primitifs. Lorsqu'il y a 1000 exemples dans l'ensemble de formation, Slovnet NER est en retard de 11 points de pourcentage par rapport à l'analogue lourd BERT, alors que 10000 exemples - de 3 points, quand 500000 - de 1.
Nerus est le résultat du travail, des modèles lourds avec l'architecture BERT : Slovnet BERT NER , Slovnet BERT Morph , Syntaxe Slovnet BERT . Le traitement de 700 000 articles de presse prend 20 heures sur le Tesla V100. Nous économisons le temps des autres chercheurs, nous mettons l'archive finie en libre accès. Dans SpaCy-Ru, enseignez à Nerus modèle qualitatif pour le SpaCy russophone, préparez un patch dans le référentiel officiel.

Le balisage synthétique est de haute qualité: la précision de la détermination des balises morphologiques est de 98%, les liens syntaxiques - 96%. Pour le NER, les estimations F1 par jetons: PER - 99%, LOC - 98%, ORG - 97%. Pour évaluer la qualité, nous balisons SynTagRus , Collection5 et la nouvelle tranche GramEval2020 , comparons le balisage de référence avec le nôtre, pour plus de détails dans le référentiel Nerus . En raison d'erreurs dans le balisage syntaxique, il existe des boucles et des racines multiples, les balises POS ne correspondent parfois pas aux arêtes syntaxiques. Il est utile d'utiliser le validateur de dépendances universelles , ignorez ces exemples.
Le package Python Nerus organise une interface pratique pour le chargement et le rendu du balisage:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='- , ...',
tokens=[NerusToken(
id='1',
text='-',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='',
pos='ADP',
...
>>> doc.ner.print()
- ,
PER───────────── LOC───
, . ,
ORG──────── PER──────
...
>>> sent = doc.sents[0]
>>> sent.morph.print()
- NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
ADP
ADJ|Case=Dat|Degree=Pos|Number=Plur
NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
┌►┌─┌───── - nsubj
│ │ │ ┌──► case
│ │ │ │ ┌► amod
│ │ └►└─└─ nmod
│ └────►┌─ appos
│ └► flat:name
┌─└─────────
│ ┌──────► , punct
│ │ ┌──► case
│ │ │ ┌► det
│ │ ┌►└─└─ obl
│ │ │ └──► nmod
└──►└─└───── ccomp
│ ┌► advmod
│ ┌►└─ amod
└►┌─└─── nsubj:pass
│ ┌► case
└──►└─ nmod
┌► , punct
┌─┌─└─
│ └►┌─ nsubj
│ └► appos
└────► . punct
Instructions d'installation, exemples d'utilisation , évaluations de la qualité dans le référentiel Nerus.
Corus - une collection de liens vers des ensembles de données publics en russe + fonctions à télécharger

La bibliothèque Corus fait partie du projet Natasha, une collection de liens vers des ensembles de données NLP publics en langue russe + un package Python avec des fonctions de chargement. Liste de liens vers les sources , instructions d'installation et exemples d'utilisation dans le référentiel Corus.
>>> from corus import load_lenta
# Corus Lenta.ru, :
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2, 750 000
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title=' \xa0 ...',
text='- ...',
topic='',
tags=''
)
Les ensembles de données ouverts utiles pour la langue russe sont si bien cachés que peu de gens les connaissent.
Exemples de
Corpus d'articles de presse
Nous voulons former le modèle linguistique sur des articles de presse, nous avons besoin de beaucoup de textes. La première chose qui me vient à l'esprit est une nouvelle tranche de l' ensemble de données Taiga (~ 1 Go). Beaucoup de gens connaissent le dump Lenta.ru (2 Go). D'autres sources sont plus difficiles à trouver. En 2019, Dialogue a organisé un concours pour générer des titres ; les organisateurs ont préparé une décharge de RIA Novosti pendant 4 ans (3,7 Go). En 2018, Yuri Baburov a publié un téléchargement à partir de 40 ressources d'actualités en russe (7,5 Go). Les volontaires de l' ODS partagent les archives (7 Go) collectées pour le projet sur l'analyse de l'agenda de l'actualité .
Dans le registre Corusliens vers ces ensembles de données avec le tag «nouvelles», pour toutes les sources ont une fonction chargeurs:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.
NER
Nous voulons enseigner le NER pour la langue russe, nous avons besoin de textes annotés. Tout d'abord, nous rappelons les données du concours factRuEval-2016 . Le balisage a des inconvénients: son format complexe, les travées d'entités se chevauchent, il y a des catégories "LocOrg" ambiguës. Tout le monde ne connaît pas la collection Named Entities 5, le successeur de Persons-1000 . Mise en page au format standard , les travées ne se croisent pas, beauté! Les trois autres sources ne sont connues que des fans les plus dévoués du NER russophone. Nous écrirons à Rinat Gareev par e-mail, joignons un lien vers son article de 2013, et en retour nous recevrons 250 articles de presse avec des noms et des organisations tagués. Le concours BSNLP-2019 a eu lieu en 2019sur les NER pour les langues slaves, nous écrirons aux organisateurs, nous obtiendrons 450 textes plus marqués. Le projet WiNER a eu l'idée de créer un balisage NER semi-automatique à partir de décharges Wikipédia , un gros téléchargement pour le russe est disponible sur Github .
Liens et fonctions pour charger le registre Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.
Collection de liens
Avant d'obtenir un bootloader et d'entrer dans le registre, les liens vers les sources sont accumulés dans la section avec Tickets . La collection de 30 jeux de données: une nouvelle version de Taiga , 568GB texte russe de la commune Crawl , critiques c Banki.ru et Auto.ru . Nous vous invitons à partager vos découvertes, à créer des tickets avec des liens.
Fonctions du chargeur
Le code d'un jeu de données simple est facile à écrire vous-même. Le dump Lenta.ru est bien formé, la mise en œuvre est simple . Taiga est composé d'environ 15 millions de fichiers zip CoNLL-U . Pour que le téléchargement fonctionne rapidement, ne pas utiliser beaucoup de mémoire et ne pas ruiner le système de fichiers, vous devez être confus, implémenter soigneusement le travail avec des fichiers zip à un niveau bas .
Pour 35 sources, le package Corus Python a des fonctions de chargement. L'interface pour accéder à Taiga n'est pas plus compliquée que le vidage Lenta.ru:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre=' ',
topic='',
author=Author(
name='',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title=' !',
url='http://www.proza.ru/2015/12/31/1875'
),
text='... ...\n... ..\n...
)
Nous invitons les utilisateurs à faire des pull requests, à envoyer leurs fonctions de chargeur, une brève instruction dans le référentiel Corus.
Naeval - Comparaison quantitative des systèmes pour la PNL russophone

Natasha n'est pas un projet scientifique, il n'y a pas de but pour battre SOTA, mais il est important de vérifier la qualité sur des benchmarks publics, pour essayer de prendre une place élevée sans perdre grand-chose en performances. Comme ils le font à l'académie: mesurez la qualité, obtenez un chiffre, prenez des comprimés d'autres articles, comparez ces chiffres avec les leurs. Ce schéma présente deux problèmes:
- Oubliez les performances. Ils ne comparent pas la taille du modèle, la vitesse de travail. L'accent est mis uniquement sur la qualité.
- Ne publiez pas le code. Il y a généralement un million de nuances dans le calcul d'une métrique de qualité. Comment a-t-il été compté exactement dans d'autres articles? Inconnue.
Naeval fait partie du projet Natasha, un ensemble de scripts pour évaluer la qualité et la vitesse des outils open-source pour le traitement de la langue russe naturelle:
| Tâche | Ensembles de données | Solutions |
| Tokenisation | SynTagRus, OpenCorpora, GICRYA, RNC
|
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel
|
| SynTagRus, OpenCorpora, GICRYA, RNC
|
SegTok, Moses, NLTK, RuSentTokenizer, Razdel
|
|
| SimLex965, HJ, LRWC, RT, AE, AE2
|
RusVectores, Navec
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph
|
|
| GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga)
|
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax
|
|
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER
|
DeepPavlov NER , DeepPavlov BERT NER , DeepPavlov Slavic BERT NER , PullEnti , SpaCy , Stanza , Texterra , Tomita , MITIE , Slovnet NER , Slovnet BERT NER
|
Examinons de plus près le problème du NER ci-dessous.
Ensembles de données
Il y a 5 points de repère publics pour les NER russophones: factRuEval-2016 , Collection5 , Gareev , BSNLP-2019 , Winer . Les liens sources sont collectés dans le registre Corus . Tous les ensembles de données sont constitués d'articles de presse, de sous-chaînes avec des noms, des noms d'organisations et des toponymes sont indiqués dans les textes. Qu'est-ce qui pourrait être plus facile?
Toutes les sources ont un format de balisage différent. Collection5 utilise le format Standoff des utilitaires Brat , Gareev et WiNER - différents dialectes du balisage BIO , BSNLP-2019 a son propre format , factRuEval-2016 a également sa propre spécification non triviale... Naeval convertit toutes les sources dans un format commun. Le balisage se compose de travées. Span - trois: type d'entité, début et fin de la sous-chaîne.
Types d'entités. factRuEval-2016 et Collection5 marquent séparément les demi-noms-semi-organisations: "Kremlin", "UE", "URSS". BSNLP-2019 et WiNER soulignent les noms des événements: "Championnat de Russie", "Brexit". Naeval adapte et supprime certaines balises, laisse les balises de référence PER, LOC, ORG: noms de personnes, noms de toponymes et organisations.
Portées imbriquées. En fait RuEval-2016, les travées se chevauchent. Naeval simplifie le balisage:
:
, 5 Retail Group,
org_name───────
Org────────────
"", "" "",
org_descr───── org_name─ org_name─── org_name
Org──────────────────────
org_descr─────
Org─────────────────────────────────────
org_descr─────
Org──────────────────────────────────────────────────
, .
:
, 5 Retail Group,
ORG────────────
"", "" "",
ORG────── ORG──────── ORG─────
, .
Des modèles
Naeval compare 12 solutions ouvertes au problème russe des NER. Tous les outils sont emballés dans des conteneurs Docker avec une interface Web:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data \
' \
\
'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="" />
<Name_FirstName val="" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Certaines solutions sont si difficiles à lancer et à configurer que peu de gens les utilisent. PullEnti , un système sophistiqué basé sur des règles, a pris la première place du concours factRuEval en 2016. L'outil est distribué sous forme de SDK pour C #. Le travail sur Naeval s'est transformé en un projet séparé avec un ensemble de wrappers pour PullEnti: PullentiServer - un serveur Web en C #, pullenti-client - un client Python pour PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = ' ' \
... ' ' \
... ' '
>>> result = client(text)
>>> result.graph
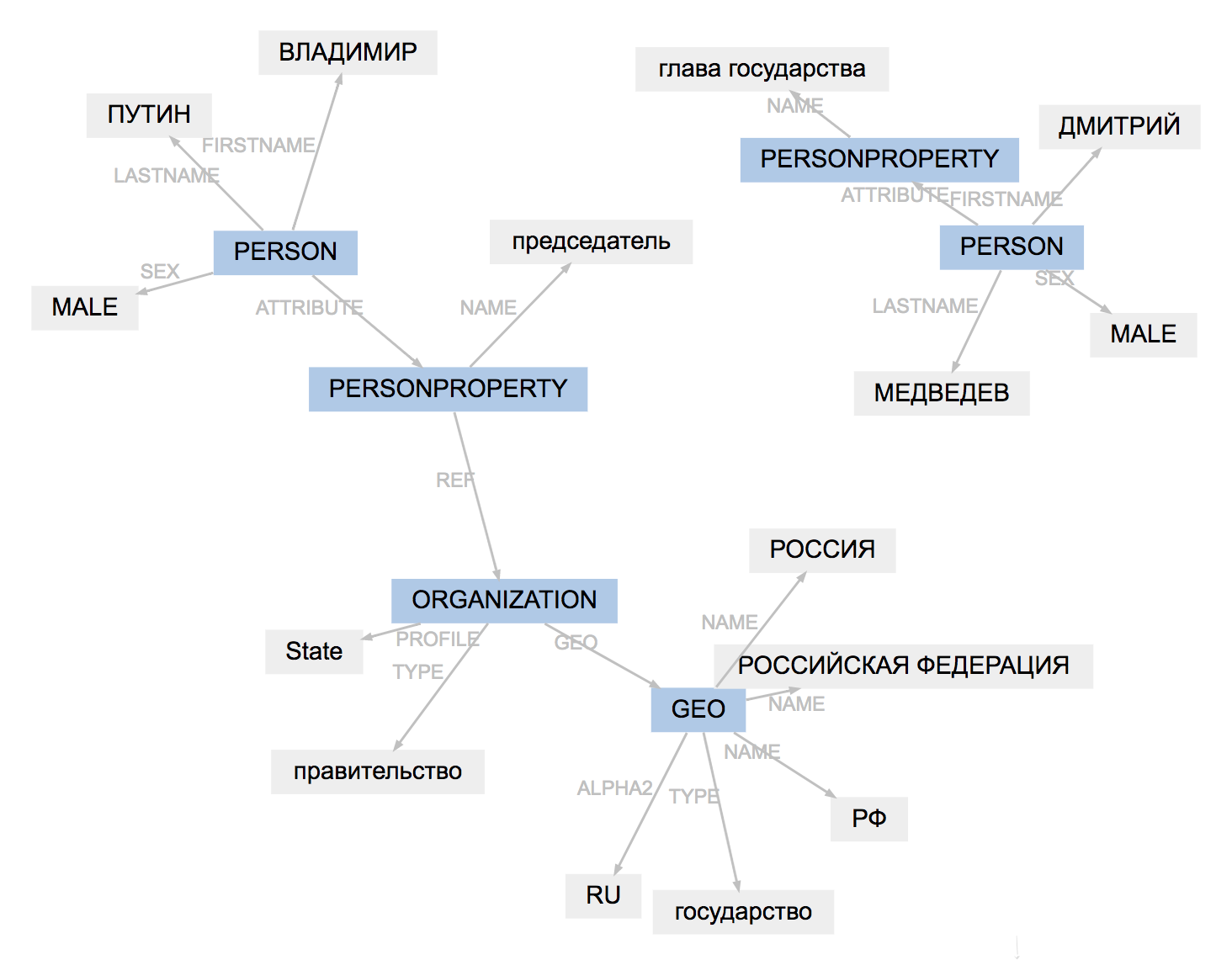
Le format de balisage pour tous les outils est légèrement différent. Naeval charge les résultats, adapte les types d'entités, simplifie la structure des travées:
(PullEnti):
, 19
ORGANIZATION──────────
GEO─────────
PERSON────────────────
PERSONPROPERTY───────
──────────────── PERSON───────────────────────
PERSONPROPERTY──────────────
ORGANIZATION───
.
────────────────
:
, 19
ORG────── LOC─────────
PER───────────── ORG────────────
.
PER─────────────
Le résultat du travail de PullEnti est plus difficile à adapter que le balisage factRuEval-2016. L'algorithme supprime la balise PERSONPROPERTY, divise la PERSONNE, ORGANISATION et GEO imbriquées en PER, LOC, ORG sans chevauchement.
Comparaison
Pour chaque paire de "modèle, ensemble de données" Naeval calcule la mesure F1 par jetons , publie un tableau avec des scores de qualité .
Natasha n'est pas un projet scientifique, la praticité de la solution est importante pour nous. Naeval mesure l'heure de début, la vitesse d'exécution, la taille du modèle et la consommation de RAM. Table avec les résultats dans le référentiel .
Nous avons préparé des ensembles de données, enveloppé 20 systèmes dans des conteneurs Docker et calculé des métriques pour 5 autres tâches de PNL en langue russe, résultats dans le référentiel Naeval : tokenisation , segmentation en phrases , incorporations , morphologie et analyse syntaxique .
Yargy- —

L'analyseur Yargy est un analogue de l' analyseur Yandex Tomita pour Python. Instructions d'installation , exemple d'utilisation , documentation dans le référentiel Yargy. Les règles d'extraction d'entités sont décrites à l'aide de grammaires et de dictionnaires sans contexte . Il y a deux ans, j'ai écrit sur Habr un article sur Yargy et la bibliothèque Natasha , parlant de la résolution du problème du NER pour la langue russe. Le projet a été bien accueilli. Yargy-parser a remplacé Tomita dans de grands projets au sein de Sberbank, Interfax et RIA Novosti. De nombreux matériels pédagogiques sont apparus. Une grande vidéo d'un atelier à Yandex, une heure et demie sur le processus de développement de grammaires avec des exemples:
La documentation a été mise à jour, j'ai passé au peigne fin la section d'introduction et le livre de référence . Plus important encore, le livre de recettes est apparu - une section avec des pratiques utiles. Il contient les réponses aux questions les plus fréquemment posées sur t.me/natural_language_processing :
- comment sauter une partie du texte ;
- comment soumettre des jetons, pas du texte ;
- que faire si l'analyseur ralentit .
L'analyseur Yargy est un outil complexe. Le livre de recettes décrit des points non évidents qui surviennent lorsque vous travaillez avec de grands ensembles de règles:
Nous avons plusieurs grands services en cours d'exécution dans le laboratoire Yargy. J'ai relu le code, collecté des modèles dans le livre de recettes qui ne sont pas décrits au public:
- génération de règles ;
- fait d'héritage (particulièrement utile, aucune solution en pratique ne peut se passer de cette technique).
Après avoir lu la documentation, il est utile de regarder le référentiel avec des exemples :
Le projet Natasha dispose également d'un référentiel d' utilisation de natasha . C'est là que va le code des utilisateurs de l'analyseur Yargy publié sur Github. 80% des liens sont des projets éducatifs, mais il existe également des exemples informatifs:
- analyse des informations sur les travaux du métro de Saint-Pétersbourg ;
- analyse d'annonces pour la livraison de logements sur les réseaux sociaux ;
- extraction d'attributs à partir des noms de pneus automobiles ;
- analyse des postes vacants du canal des emplois du chat ODS ;
Les cas les plus intéressants d'utilisation de l'analyseur Yargy, bien sûr, ne sont pas publiés publiquement sur Github. Écrivez à PM si l'entreprise utilise Yargy et, si cela ne vous dérange pas, ajoutez votre logo à natasha.github.io .
Ipymarkup - visualisation du balisage d'entité nommée et des relations syntaxiques

Ipymarkup est une bibliothèque primitive nécessaire pour la mise en évidence de sous-chaînes dans le texte, la visualisation NER. Instructions d'installation , exemple d'utilisation dans le référentiel Ipymarkup. La bibliothèque est similaire à display et display ENT , inestimables pour le débogage des grammaires pour l'analyseur Yargy.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)

Le projet Natasha a une solution au problème d'analyse . Il était nécessaire non seulement de mettre en évidence les mots dans le texte, mais aussi de dessiner des flèches entre eux. Il y a beaucoup de solutions toutes faites, il y a même un article scientifique sur le sujet .
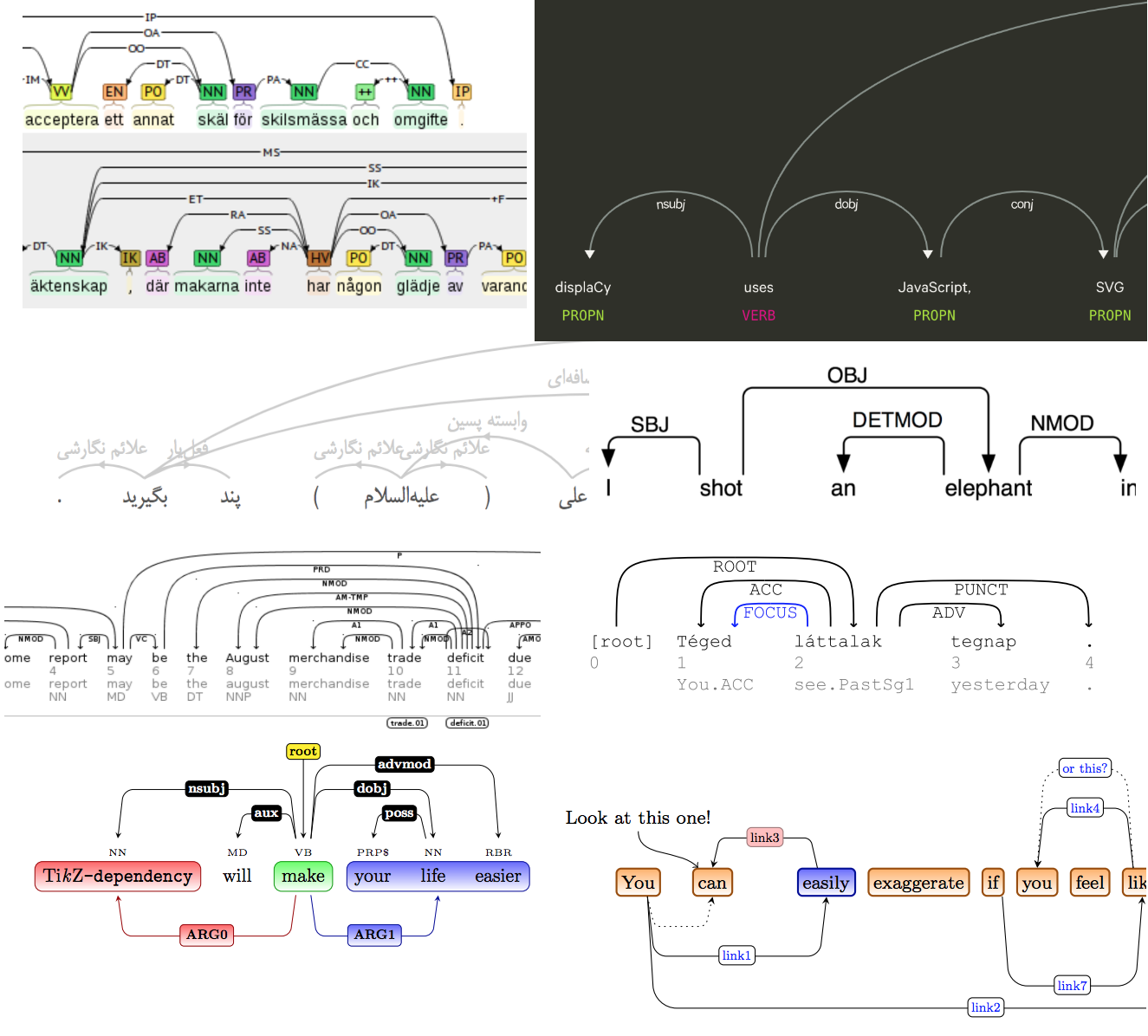
Bien sûr, aucun de ceux existants n'est apparu, et un jour j'ai été vraiment confus, j'ai appliqué toute la fameuse magie du CSS et du HTML, j'ai ajouté une nouvelle visualisation à Ipymarkup. Instructions d'utilisation dans le dock.
>>> from ipymarkup import show_dep_markup
>>> words = ['', '', '', '', '', '', '-', '', '', '', '', '', '', '', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
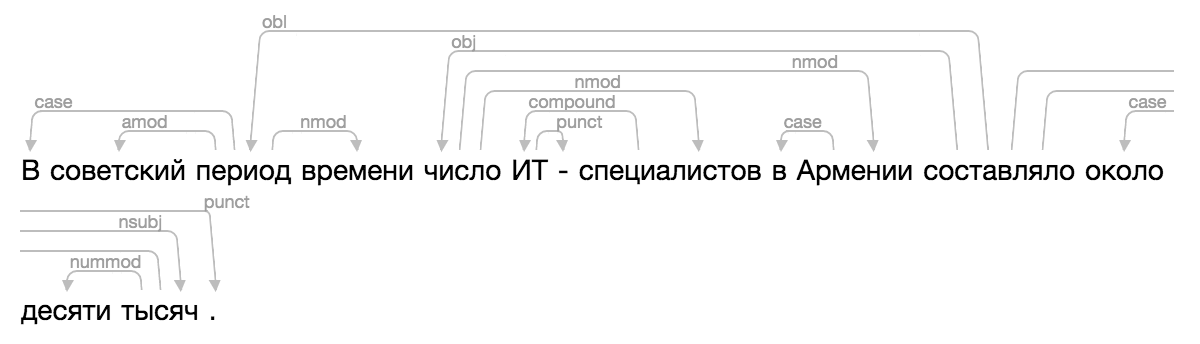
Maintenant, dans Natasha et Nerus, il est pratique de voir les résultats de l'analyse.
