Analyse
Qu'est-ce que l'analyse? Il s'agit de la collecte et de la systématisation des informations publiées sur des sites Web à l'aide de programmes spéciaux qui automatisent le processus.
L'analyse syntaxique est couramment utilisée pour l'analyse des prix et la récupération de contenu.
Début
Pour collecter de l'argent auprès des bookmakers, je devais recevoir rapidement des informations sur les cotes de certains événements sur plusieurs sites. Nous n'entrerons pas dans la partie mathématique.
Depuis que j'ai étudié le C # dans ma sharaga, j'ai décidé de tout écrire. Les gars de Stack Overflow ont conseillé d'utiliser Selenium WebDriver. Il s'agit d'un pilote de navigateur (bibliothèque de logiciels) qui vous permet de développer des programmes contrôlant le comportement du navigateur. C'est ce dont nous avons besoin, ai-je pensé.
J'ai installé la bibliothèque et j'ai couru pour regarder les guides sur Internet. Au bout d'un moment, j'ai écrit un programme qui pouvait ouvrir un navigateur et suivre quelques liens.
Hourra! Bien s'arrêter, comment appuyer sur les boutons, comment obtenir les informations nécessaires? XPath nous aidera ici.
XPath
En termes simples, c'est un langage pour interroger des éléments de document XML et XHTML.
Pour cet article, j'utiliserai Google Chrome. Cependant, d'autres navigateurs modernes devraient avoir, sinon la même chose, une interface très similaire.
Pour voir le code de la page sur laquelle vous vous trouvez, appuyez sur F12.

Pour voir où dans le code il y a un élément sur la page (texte, image, bouton), cliquez sur la flèche dans le coin supérieur gauche et sélectionnez cet élément sur la page. Passons maintenant à la syntaxe.
Syntaxe standard pour l'écriture de XPath:
// tagname [@ attribute = 'value']
// : sélectionne tous les nœuds dans le document html à partir du nœud actuel
Tagname : tag du nœud courant.
@ : Sélectionne les attributs
Attribut : nom de l'attribut du nœud.
Valeur : la valeur de l'attribut.
Cela peut ne pas être clair au début, mais après les exemples, tout devrait se mettre en place.
Regardons quelques exemples simples:
// input [@ type = 'text']
// label [@ id = 'l25']
// input [@ value = '4']
// a [@ href = 'www.walmart. com ']
Prenons des exemples plus complexes pour le html'i donné:
<div class ='contentBlock'>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habr</span>
</a>
<div class = 'textConainer'>
<span class='description'>cool site</span>
"text2"
</div>
</div>
<div class = 'listItem'>
<a class = 'link' href = 'habr.com'>
<span class='name'>habrhabr</span>
</a>
<div class = 'textConainer'>
<span class='description'>the same site</span>
"text1"
</div>
</div>
</div>XPath = // div [@ class = 'contentBlock'] // div
Les éléments suivants seront sélectionnés pour ce XPath:
<div class = 'listItem'>
<div class = 'textConainer'>
<div class = 'listItem'>
<div class = 'textConainer'>XPath = // div [@ class = 'contentBlock'] / div
<div class = 'listItem'>
<div class = 'listItem'>Notez la différence entre / (récupère le nœud racine) et // (récupère les nœuds du nœud actuel quel que soit leur emplacement). Si ce n'est pas clair, regardez à nouveau les exemples ci-dessus.
// div [@ class = 'contentBlock'] / div [@ class = 'listItem'] / a [@ class = 'link'] / span [@ class = 'name']
Cette requête est la même avec ce html :
// div / div / a / span
// span [@ class = 'name']
// a [@ class = 'link'] / span [@ class = 'name']
// a [@ class = ' lien 'ethref= 'habr.com'] / span
// span [text () = 'habr' or text () = 'habrhabr']
// div [@ class = 'listItem'] // span [@ class = 'name' ]
// a [contient (href, 'habr')] / span
// span [contient (text (), 'habr')]
Résultat:
<span class='name'>habr</span>
<span class='name'>habrhabr</span>// span [text () = 'habr'] / parent :: a / parent :: div
Égal à
// div / div [@ class = 'listItem'] [1]
Résultat:
<div class = 'listItem'>parent :: - Renvoie le parent d'un niveau supérieur.
Il y a aussi une fonctionnalité super cool telle que following-sibling :: - retourne de nombreux éléments au même niveau après l'actuel, similaire à precedent-sibling :: - retourne de nombreux éléments au même niveau précédant l'actuel.
// span [@ class = 'name'] / following-sibiling :: text () [1]
Résultat:
"text1"
"text2"Je pense que c'est plus clair maintenant. Pour consolider le matériel, je vous conseille de vous rendre sur ce site et d'écrire quelques requêtes pour retrouver quelques éléments de ce html'i.
<div class="item">
<a class="link" data-uid="A8" href="https://www.walmart.com/grocery/?veh=wmt" title="Pickup & delivery">
<span class="g_b">Pickup and delivery</span>
</a>
<a class="link" data-uid="A9" href="https://www.walmart.com/" title="Walmart.com">
<span class="g_b">Walmart.com</span>
</a>
</div>
<div class="item">
<a class="link" data-uid="B8" href="https://www.walmart.com/grocery/?veh=wmt" title="Savings spotlight">
<span class="g_b">Savings spotlight</span>
</a>
<a class="link" data-uid="B9" href="https://www.walmartethics.com/content/walmartethics/it_it.html" title="Walmart.com">
<span class="g_b">Walmart.com(Italian)</span>
"italian virsion"
</a>
</div>Maintenant que nous savons ce qu'est XPath, revenons à l'écriture du code. Étant donné que les modérateurs Habr n'aiment pas les bookmakers, ils analyseront les prix du café chez Walmart.
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
IWebDriver driver = new ChromeDriver(pathToFile);
driver.Navigate().GoToUrl("https://walmart.com");
Thread.Sleep(5000);
IWebElement element = driver.FindElement(By.XPath("//button[@id='header-Header sparkButton']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//button[@data-tl-id='GlobalHeaderDepartmentsMenu-deptButtonFlyout-10']"));
element.Click();
Thread.Sleep(2000);
element = driver.FindElement(By.XPath("//div[text()='Coffee']/parent::a"));
driver.Navigate().GoToUrl(element.GetAttribute("href"));
Thread.Sleep(10000);
List<string> names = new List<string>(), prices = new List<string>();
List<IWebElement> listOfElements =driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-title']/div")).ToList();
foreach (IWebElement a in listOfElements)
names.Add(a.Text);
listOfElements = driver.FindElements(By.XPath("//div[@class='tile-content']/div[@class='tile-price']/span/span[contains(text(),'$')]")).ToList();
foreach (IWebElement a in listOfElements)
prices.Add(a.Text);
for (int i = 0; i < prices.Count; i++)
Console.WriteLine(names[i] + " " + prices[i]);Thread.Sleep a été écrit pour que la page Web ait le temps de se charger.
Le programme ouvrira le site Web du magasin Walmart, appuyez sur quelques boutons, ouvrira la section café et obtiendra le nom et les prix des produits.
Si la page Web est assez volumineuse et que les XPath prennent donc beaucoup de temps ou sont difficiles à écrire, vous devez utiliser une autre méthode.
Requêtes HTTP
Voyons d'abord comment le contenu apparaît sur le site.

En termes simples, le navigateur fait une demande au serveur avec une demande de fournir les informations nécessaires, et le serveur, à son tour, fournit ces informations. Tout cela se fait à l'aide de requêtes HTTP.
Pour consulter les demandes que votre navigateur envoie sur un site spécifique, ouvrez simplement ce site, appuyez sur F12 et allez dans l'onglet Réseau, puis rechargez la page.

Reste maintenant à trouver la demande dont nous avons besoin.
Comment faire? - considérez toutes les demandes avec le type de récupération (troisième colonne dans l'image ci-dessus) et regardez l'onglet Aperçu.

S'il n'est pas vide, il doit être au format XML ou JSON, sinon, continuez à chercher. Si tel est le cas, voyez si les informations dont vous avez besoin se trouvent ici. Pour vérifier cela, je vous conseille d'utiliser une sorte de visionneuse JSON ou de visionneuse XML (google et ouvrez le premier lien, copiez le texte de l'onglet Réponse et collez-le dans la visionneuse). Lorsque vous trouvez la requête dont vous avez besoin, enregistrez son nom (colonne de gauche) ou l'hôte de l'URL (onglet En-têtes) quelque part, afin de ne pas effectuer de recherche plus tard. Par exemple, si vous ouvrez un rayon café sur le site Web de Walmart, une demande sera envoyée, dont la valeur légale commence par walmart.com/cp/api/wpa. Il y aura toutes les informations sur le café en vente.
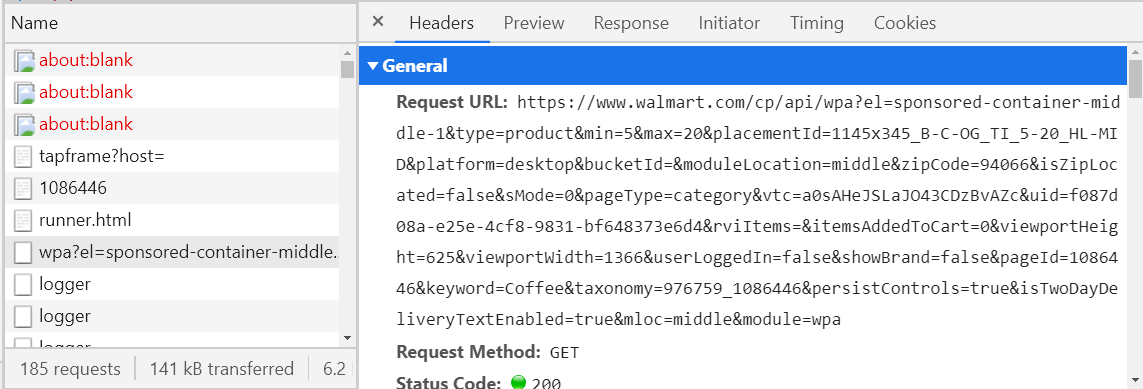
À mi-chemin, cette demande peut maintenant être "falsifiée" et envoyée immédiatement via le programme, recevant les informations nécessaires en quelques secondes. Il reste à analyser JSON ou XML, et c'est beaucoup plus facile que d'écrire des XPath. Mais souvent, la formation de telles demandes est une chose plutôt désagréable (voir l'URL dans l'image ci-dessus) et si vous réussissez même, dans certains cas, vous recevrez une telle réponse.
{
"detail": "No authorization token provided",
"status": 401,
"title": "Unauthorized",
"type": "about:blank"
}Vous allez maintenant apprendre comment vous pouvez éviter les problèmes liés à l'imitation d'une requête en utilisant une alternative - un serveur proxy.
Serveur proxy
Un serveur proxy est un appareil qui sert d'intermédiaire entre un ordinateur et Internet.
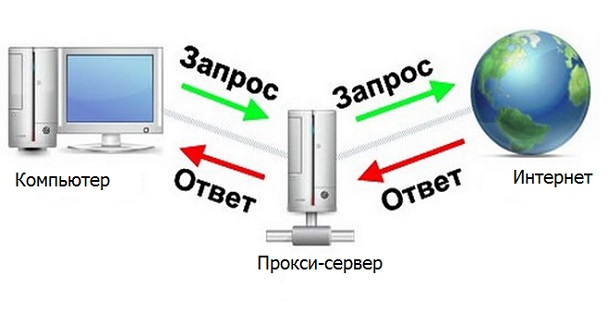
Ce serait formidable si notre programme était un serveur proxy, alors vous pouvez traiter rapidement et facilement les réponses nécessaires du serveur. Ensuite, il y aurait une telle chaîne Navigateur - Programme - Internet (serveur de site qui est analysé).
Heureusement pour si sharp, il existe une merveilleuse bibliothèque pour de tels besoins - Titanium Web Proxy.
Créons la classe PServer
class PServer
{
private static ProxyServer proxyServer;
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")){
Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}
}Passons maintenant en revue chaque méthode séparément.
public PServer()
{
proxyServer = new ProxyServer();
proxyServer.BeforeResponse += OnResponse;
var explicitEndPoint = new ExplicitProxyEndPoint(IPAddress.Loopback, 8000, true);
explicitEndPoint.BeforeTunnelConnectRequest += OnBeforeTunnelConnectRequest;
proxyServer.AddEndPoint(explicitEndPoint);
proxyServer.Start();
}proxyServer.BeforeRepsone + = OnRespone - ajoute une méthode pour traiter une réponse du serveur. Il sera appelé automatiquement lorsque la réponse arrivera.
explicitEndPoint - Configuration du serveur proxy,
ExplicitProxyEndPoint (IPAddress ipAddress, int port, bool decryptSsl = true)
IPAddress et port sur lequel le serveur proxy s'exécute.
decryptSsl - s'il faut déchiffrer SSL. En d'autres termes, si decrtyptSsl = true, le serveur proxy traitera toutes les demandes et réponses.
explicitEndPoint.BeforeTunnelConnectRequest + = OnBeforeTunnelConnectRequest - ajoute une méthode pour traiter la demande avant de l'envoyer au serveur. Il sera également appelé automatiquement avant l'envoi de la demande.
proxyServer.Start () - "démarrer" le serveur proxy, à partir de ce moment, il commence le traitement des requêtes et des réponses.
private async Task OnBeforeTunnelConnectRequest(object sender, TunnelConnectSessionEventArgs e)
{
if (!e.HttpClient.Request.Url.Contains("www.walmart.com")){
e.DecryptSsl = false;
}
}e.DecryptSsl = false - la demande et la réponse actuelles ne seront pas traitées.
Si la requête ou la réponse ne nous intéresse pas (par exemple, une image ou une sorte de script), alors pourquoi la déchiffrer? Beaucoup de ressources sont consacrées à cela, et si toutes les demandes et réponses sont décodées, le programme fonctionnera longtemps. Par conséquent, si la requête actuelle ne contient pas l'hôte de la requête qui nous intéresse, alors il est inutile de la décrypter.
public async Task OnResponse(object sender, SessionEventArgs e)
{
if (e.HttpClient.Response.StatusCode == 200 && (e.HttpClient.Request.Method == "GET" || e.HttpClient.Request.Method == "POST"))
{
string url = e.HttpClient.Request.Url;
if (url.Contains("walmart.com/cp/api/wpa")) Console.WriteLine(await e.GetResponseBodyAsString());
}
}
}wait e.GetResponseBodyAsString () - renvoie une réponse sous forme de chaîne.
Pour que WebDriver se connecte au serveur proxy, vous devez écrire ce qui suit:
string pathToFile = AppDomain.CurrentDomain.BaseDirectory + '\\';
ChromeOptions options = new ChromeOptions();
options.AddArguments("--proxy-server=" + IPAddress.Loopback + ":8000");
IWebDriver driver = new ChromeDriver(pathToFile, options);Vous pouvez désormais gérer les demandes que vous souhaitez.
Conclusion
Avec WebDriver, vous pouvez parcourir les pages, cliquer sur des boutons et imiter le comportement d'un utilisateur régulier. Avec XPaths, vous pouvez extraire les informations dont vous avez besoin à partir de pages Web. Si les XPath ne fonctionnent pas, un serveur proxy peut toujours aider, qui peut intercepter les requêtes entre le navigateur et le site.