Mais toutes ces solutions n'avaient pas ce dont j'avais besoin:
- Installation centralisée
- Résultats de la recherche en tenant compte des droits d'accès
- Recherche par contenu de document
- Morphologie
Et j'ai décidé de créer le mien.
Je vais divulguer point par point ce que j'ai dans le formulaire pour éviter la différence d'interprétation et les malentendus.
Installation centralisée - exécution client-serveur. Toutes les solutions ci-dessus présentent un problème fondamental: chaque utilisateur crée son propre index de recherche local, ce qui, dans le cas de grands volumes de stockage, retarde l'indexation, le profil de l'utilisateur sur la machine augmente et est généralement gênant en cas d'arrivée ou de passage d'un nouvel employé sur une nouvelle machine.
Résultats de la recherche en tenant compte des droits - tout est simple ici - les résultats doivent correspondre aux droits de l'employé sur la ressource fichier. Sinon, il s'avère que même si l'employé n'a pas de droits sur la ressource, il peut tout lire depuis le cache de recherche. Cela va s'avérer gênant, d'accord? Recherche par le contenu du document - recherche par le texte du document, tout est évident, me semble-t-il, et il ne peut y avoir de divergence.
La morphologie est encore plus simple. Spécifié dans la requête "couteau" et a reçu à la fois "couteau" et "couteaux", "couteau" et "couteau". Il est souhaitable que cela fonctionne pour le russe et l'anglais.
Nous avons décidé de la formulation du problème, nous pouvons procéder à la mise en œuvre.
En tant que moteur de recherche, j'ai choisi le système Sphinx, et le langage de développement d'interface était C # et .net, et par conséquent, le projet a été nommé Vidocq (Vidocq) d'après le nom du détective français. Eh bien, comme, il trouve tout et c'est tout.
Du point de vue architectural, l'application ressemble à ceci: Le
robot de recherche explore de manière récursive une ressource de fichier et traite les fichiers selon une liste d'extensions donnée. Le traitement consiste à récupérer le contenu du fichier, à compresser le texte - les guillemets, virgules, espaces supplémentaires, etc. sont supprimés du texte, puis le contenu est placé dans la base de données (MS SQL), la date de placement est marquée et le robot avance.
L'indexeur Sphins fonctionne directement avec la base reçue, formant son propre index et renvoyant un pointeur vers le fichier trouvé et un extrait du fragment de texte trouvé comme réponse.
Un formulaire a été développé en C # qui communiquait avec le Sphinx via le connecteur MySQL. Sphinx donne un tableau de fichiers conformément à la demande, puis le tableau est filtré pour le droit d'accès de l'utilisateur qui recherche, la sortie est formatée et présentée à l'utilisateur.
Nous devons stocker les informations suivantes sur le fichier:
- ID de fichier
- Nom de fichier
- Le chemin d'accès au fichier
- Contenu du fichier
- Expansion
- Date ajoutée à la base
Tout cela est fait dans une seule table et le robot de recherche y ajoutera tout. La date d'ajout est nécessaire pour que, lors du prochain tour, le robot compare la date de la modification du fichier avec la date à laquelle il a été placé dans la base de données et si les dates diffèrent, mettez à jour les informations sur le fichier.
Ensuite, configurez le moteur de recherche lui-même. Je ne décrirai pas la configuration entière, elle sera disponible dans l'archive du projet, mais je n'en couvrirai que les points principaux.
La requête principale qui forme la base des
documents sources: documents_base
{
sql_query = \
select \
DocumentId as 'Id', \
DocumentPath as 'Path', \
DocumentTitle as 'Title', \
DocumentExtention as 'Extension', \
DocumentContent as 'Content' \
from \
VidocqDocs
}Mise en place de la morphologie grâce à un lemmatiseur.
index documents
{
source = documents
path = D:/work/VidocqSearcher/Sphinx/data/index
morphology = lemmatize_ru_all, lemmatize_en_all
}Après cela, vous pouvez définir l'indexeur sur la base et vérifier le travail.
d:\work\VidocqSearcher\Sphinx\bin\indexer.exe documents --config D:\work\VidocqSearcher\Sphinx\bin\main.conf –rotateIci, le chemin vers l'indexeur est suivi du nom de l'index dans lequel placer l'index traité, le chemin vers la configuration et le drapeau –rotate signifie que l'indexation sera effectuée à la volée, c'est-à-dire avec le service de recherche en cours d'exécution. Une fois l'indexation terminée, l'index sera remplacé par celui mis à jour.
Nous vérifions le travail dans la console. En tant qu'interface, vous pouvez utiliser un client MySQL, extrait, par exemple, du kit serveur Web.
mysql -h 127.0.0.1 -P 9306après cette demande, sélectionnez l'identifiant dans les documets; devrait retourner une liste de documents indexés, si, bien sûr, vous avez démarré le service Sphinx lui-même et avez tout fait correctement.
D'accord, la console est géniale, mais nous n'allons pas forcer les utilisateurs à taper des commandes, non?
J'ai esquissé un formulaire comme celui-ci
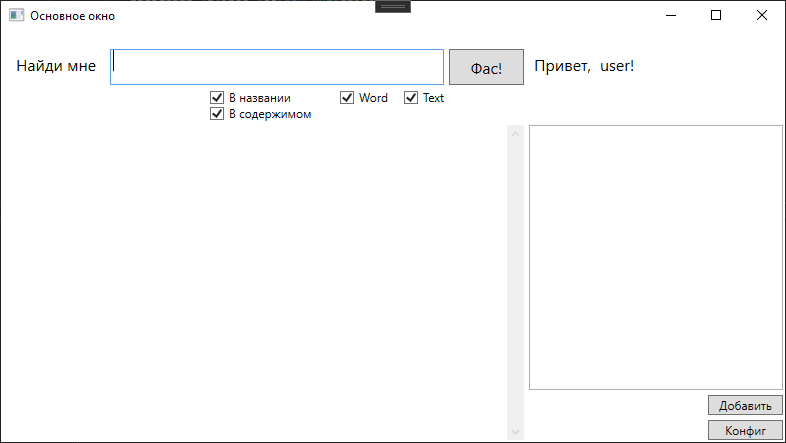
Et ici avec les résultats de la recherche

Lorsque vous cliquez sur un résultat spécifique, un document s'ouvre.
Comment mis en œuvre.
using MySql.Data.MySqlClient;
string connectionString = "Server=127.0.0.1;Port=9306";
var query = "select id, title, extension, path, snippet(content, '" + textBoxSearch.Text.Trim() + "', 'query_mode=1') as snippet from documents " +
"where ";
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == true)
{
query += "match ('@(title,content)" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == false && checkBoxContent.IsChecked == true)
{
query += "match ('@content" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxTitle.IsChecked == true && checkBoxContent.IsChecked == false)
{
query += "match ('@title" + textBoxSearch.Text.Trim() + "')";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == true)
{
query += "and extension in ('.docx', '.doc', '.txt');";
}
if (checkBoxWord.IsChecked == true && checkBoxText.IsChecked == false)
{
query += "and extension in ('.docx', '.doc');";
}
if (checkBoxWord.IsChecked == false && checkBoxText.IsChecked == true)
{
query += "and extension in ('.txt');";
}Oui, il existe un code bydloc, mais c'est un MVP.
En fait, une demande au Sphinx est formée ici, en fonction des cases à cocher définies. Les cases à cocher indiquent le type de fichiers dans lesquels rechercher et la zone de recherche.
Ensuite, la demande est envoyée au Sphinx, puis le résultat est analysé.
using (var command = new MySqlCommand(query, connection))
{
connection.Open();
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
var id = reader.GetUInt16("id");
var title = reader.GetString("title");
var path = reader.GetString("path");
var extension = reader.GetString("extension");
var snippet = reader.GetString("snippet");
bool isFileExist = File.Exists(path);
if (isFileExist == true)
{
System.Windows.Controls.RichTextBox textBlock = new RichTextBox();
textBlock.IsReadOnly = true;
string xName = "id" + id.ToString();
textBlock.Name = xName;
textBlock.Tag = path;
textBlock.GotFocus += new System.Windows.RoutedEventHandler(ShowClickHello);
snippet = System.Text.RegularExpressions.Regex.Replace(snippet, "<.*?>", String.Empty);
Paragraph paragraph = new Paragraph();
paragraph.Inlines.Add(new Bold(new Run(path + "\r\n")));
paragraph.Inlines.Add(new Run(snippet));
textBlock.Document = new FlowDocument(paragraph);
StackPanelResult.Children.Add(textBlock);
}
else
{
counteraccess--;
}
}
}
}Au même stade, le problème est généré. Chaque élément du numéro est une richtextbox avec un événement permettant d'ouvrir un document au clic. Les éléments sont placés sur le StackPanel et avant cela, le fichier est vérifié pour l'utilisateur. Ainsi, un fichier inaccessible à l'utilisateur ne sera pas inclus dans la sortie.
Les avantages de cette solution:
- L'indexation a lieu de manière centralisée
- Affichage précis basé sur les droits d'accès
- Recherche personnalisable par type de document
Bien entendu, pour le fonctionnement à part entière d'une telle solution, une archive de fichiers doit être correctement organisée dans l'entreprise. Idéalement, les profils d'utilisateurs itinérants, etc. doivent être configurés. Et oui, je connais SharePoint, Windows Search et très probablement quelques autres solutions. Ensuite, vous pouvez discuter à l'infini du choix d'une plateforme de développement, du moteur de recherche Sphinx, Manticore ou Elastic, etc. Mais c'était intéressant pour moi de résoudre le problème avec les outils dans lesquels je comprends un peu. Il fonctionne actuellement en mode MVP, mais je le développe.
Mais dans tous les cas, je suis prêt à écouter vos suggestions sur les points à améliorer ou à refaire dans l'œuf.