Chemin de recherche
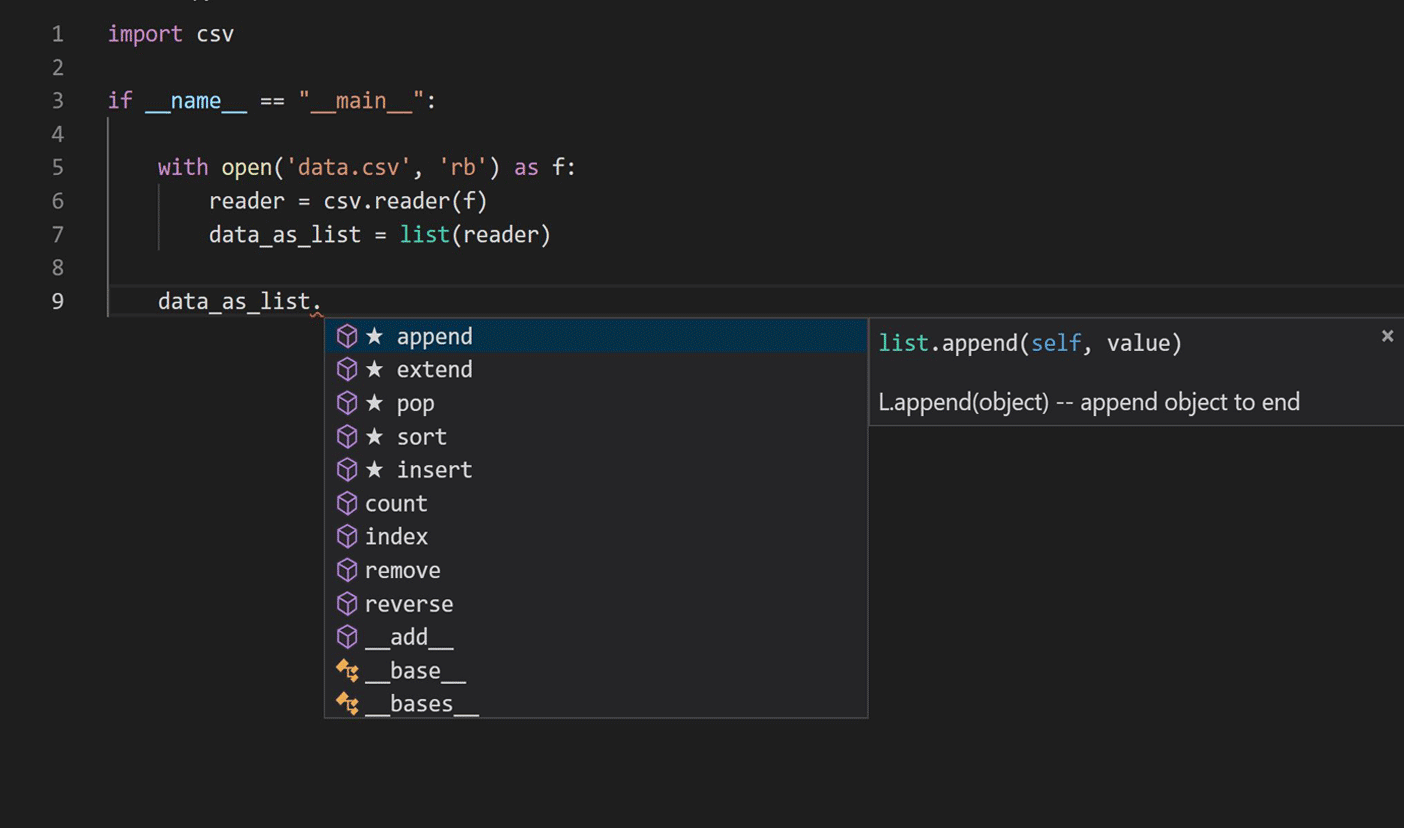
Le voyage a commencé par des recherches sur l'application des techniques de modélisation du langage au traitement du langage naturel pour apprendre le code Python. Nous nous sommes concentrés sur le script de complétion IntelliCode actuel, comme indiqué dans l'image ci-dessous.

La tâche principale est de trouver le fragment (membre) le plus probable du type, en tenant compte du fragment de code précédant l'appel du fragment (membre). En d'autres termes, étant donné l'extrait de code C d'origine, le vocabulaire V et l'ensemble de toutes les méthodes possibles M ⊂ V, nous aimerions définir:
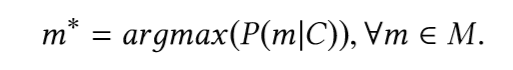
Pour trouver ce fragment, nous devons construire un modèle qui peut prédire la probabilité de fragments disponibles.
Les approches modernes antérieures basées sur les réseaux de neurones récurrents ( RNN ) utilisaient uniquement la nature séquentielle du code source, essayant de transmettre des techniques de langage naturel sans tirer parti des caractéristiques uniques de la syntaxe du langage de programmation et de la sémantique du code. La nature du problème de complétion de code en a fait un candidat prometteur pour la mémoire à court terme à long terme ( LSTM). Lors de la préparation des données pour l'apprentissage du modèle, nous avons utilisé un arbre de syntaxe abstraite (AST) partiel correspondant à des extraits de code contenant des expressions d'accès aux membres (membre) et des appels de fonction de module pour capturer la sémantique portée par le code distant.
La formation de réseaux de neurones profonds est une tâche gourmande en ressources qui nécessite des clusters de calcul hautes performances. Nous avons utilisé le cadre d' entraînement parallèle distribué d'Horovod avec l'optimiseur Adam , en conservant une copie du modèle neuronal complet sur chaque travailleur, en traitant différents mini-lots de l'ensemble de données d'entraînement en parallèle. Nous avons utilisé Azure Machine Learningpour la formation des modèles et le réglage des hyperparamètres, car son service de cluster GPU à la demande nous a permis de faire évoluer notre formation en fonction des besoins, et a également aidé à provisionner et à gérer des clusters de VM, à planifier des tâches, à collecter les résultats et à gérer les pannes. Le tableau présente les modèles d'architecture que nous avons testés, ainsi que leur précision respective et leur taille de modèle.

Nous avons choisi la fabrication par implémentation prédictive en raison de la taille plus petite du modèle et d'une amélioration de 20% de la précision du modèle par rapport au modèle de production précédent lors de l'évaluation du modèle hors ligne; la taille du modèle est essentielle pour les déploiements de production.
L'architecture du modèle est illustrée dans la figure ci-dessous:

Pour déployer le LSTM en production, nous avons dû améliorer la vitesse d'inférence du modèle et l'empreinte mémoire pour répondre aux exigences de complétion de code lors de l'édition. Notre budget mémoire était d'environ 50 Mo et nous devions maintenir la vitesse de sortie moyenne en dessous de 50 millisecondes. L'IntelliCode LSTM a été formé avec TensorFlow et nous avons choisi ONNX Runtime pour l'inférence afin d'obtenir les meilleures performances. ONNX Runtime fonctionne avec les frameworks d'apprentissage profond populaires et facilite l'intégration dans une variété d'environnements de service en fournissant des API qui couvrent plusieurs langages, y compris Python, C, C ++, C #, Java et JavaScript - nous avons utilisé des API C # compatibles avec .NET Core à intégrer dans Microsoft Python Language Server .
La quantification est une approche efficace pour réduire la taille du modèle et améliorer les performances lorsque la baisse de précision causée par l'approximation des nombres à petits chiffres est acceptable. Avec la quantification INT8 post-entraînement fournie par ONNX Runtime, l'amélioration résultante était significative: l'empreinte mémoire et le temps d'inférence ont été réduits à environ un quart des valeurs préquantifiées par rapport au modèle d'origine, avec une réduction acceptable de 3% de la précision du modèle. Vous pouvez trouver des informations détaillées sur la conception de l'architecture du modèle, le réglage des hyperparamètres, la précision et les performances dans un article de recherche que nous avons publié lors de la conférence KDD 2019.
La dernière étape de la mise en production consistait à mener des expériences A / B en ligne comparant le nouveau modèle LSTM au modèle de travail précédent. Les résultats de l'expérience A / B en ligne dans le tableau ci-dessous ont montré une amélioration d'environ 25% de la précision des recommandations de premier niveau (précision du premier élément d'achèvement recommandé dans la liste d'achèvement) et une amélioration de 17% du rang inverse moyen (MRR), ce qui nous a convaincus que le nouveau modèle LSTM est nettement meilleur. le modèle précédent.

Développeurs Python: essayez les modules complémentaires IntelliCode et envoyez-nous vos commentaires!
Grâce aux efforts considérables de l'équipe, nous avons terminé le déploiement par étapes du premier modèle d'apprentissage en profondeur auprès de tous les utilisateurs d' IntelliCode Python dans Visual Studio Code . Dans la dernière version de l'extension IntelliCode pour Visual Studio Code, nous avons également intégré le runtime ONNX et LSTM pour fonctionner avec la nouvelle extension Pylance , qui est entièrement écrite en TypeScript. Si vous êtes un développeur Python, installez l'extension IntelliCode et partagez votre avis avec nous.