
Le navigateur Chromium, le parent open source en expansion rapide de Google Chrome et du nouveau Microsoft Edge, a reçu une attention négative sérieuse pour une fonctionnalité bien intentionnée qui vérifie si le FAI d'un utilisateur vole des résultats de requête de domaine inexistants.
Intranet Redirect Detector , qui crée de fausses requêtes pour des «domaines» aléatoires qui sont statistiquement improbables, est responsable d'environ la moitié du trafic total reçu par les serveurs DNS racine dans le monde. Matt Thomas, ingénieur chez Verisign, a écrit un long article sur le blog de l'APNIC décrivant le problème et évaluant son ampleur.
Comment les recherches DNS sont généralement effectuées
Ces serveurs sont l'autorité ultime à contacter pour résoudre .com, .net, etc., afin qu'ils vous indiquent que frglxrtmpuf n'est pas un domaine de premier niveau (TLD).
DNS, ou Domain Name System, est un système par lequel les ordinateurs peuvent traduire des noms de domaine mémorables comme arstechnica.com en adresses IP beaucoup moins pratiques, telles que 3.128.236.93. Sans DNS, Internet ne pourrait pas exister sous une forme conviviale, ce qui signifie qu'une charge inutile sur l'infrastructure de niveau supérieur est un réel problème.
Le chargement d'une seule page Web moderne peut nécessiter un nombre inimaginable de recherches DNS. Par exemple, lorsque nous avons analysé la page d'accueil ESPN, nous avons compté 93 noms de domaine distincts, allant de a.espncdn.com à z.motads.com. Tous sont nécessaires pour un chargement complet de la page!
DNS est conçu comme une hiérarchie à plusieurs niveaux pour gérer ce type de charge de travail qui doit servir le monde entier. Au sommet de cette pyramide se trouvent les serveurs racine - chaque domaine de premier niveau, tel que .com, a sa propre famille de serveurs, qui sont l'autorité ultime pour chaque domaine en dessous d'eux. Un cran au-dessus de ces serveurs se trouvent les serveurs racine eux-mêmes, de
a.root-servers.netà m.root-servers.net.
A quelle fréquence ceci se passe-t-il?
En raison de la hiérarchie de mise en cache à plusieurs niveaux de l'infrastructure DNS, un très petit pourcentage des requêtes DNS dans le monde atteignent les serveurs racine. La plupart des gens obtiennent leurs informations de résolution DNS directement auprès de leur FAI. Lorsque l'appareil d'un utilisateur a besoin de savoir comment accéder à un site spécifique, une demande est d'abord envoyée à un serveur DNS géré par ce fournisseur local. Si le serveur DNS local ne connaît pas la réponse, il transmet la requête à ses propres "transitaires" (si spécifié).
Si ni le serveur DNS du FAI local ni ses «redirecteurs» configurés n'ont de réponse en cache, la demande est acheminée directement vers le serveur faisant autorité dans le domaine au-dessus de celui que vous essayez de résoudre . Quand
.comcela signifie que la demande est envoyée aux serveurs faisant autorité du domaine lui com- même , qui se trouvent à gtld-servers.net.
Le
gtld-serverssystème demandé répond avec une liste de serveurs de noms faisant autorité pour le domaine domain.com, ainsi qu'au moins un enregistrement glue contenant l'adresse IP d'un de ces serveurs de noms. Ensuite, les réponses descendent dans la chaîne - chaque transitaire transmet ces réponses au serveur qui les a demandées, jusqu'à ce que la réponse atteigne enfin le serveur du fournisseur local et l'ordinateur de l'utilisateur. En même temps, ils mettent tous en cache cette réponse afin de ne pas perturber inutilement les systèmes de niveau supérieur.
Dans la plupart des cas, les enregistrements du serveur de noms pour domain.comsera déjà mis en cache sur l'un de ces redirecteurs, de sorte que les serveurs racine ne sont pas perturbés. Cependant, pour l'instant, nous parlons de la forme habituelle d'une URL - une URL qui est convertie en un site Web régulier. Les requêtes Chrome se situent à un niveau supérieur à cela, à l'échelon des clusters eux-mêmes
root-servers.net.
Vérification du vol de Chrome et NXDomain
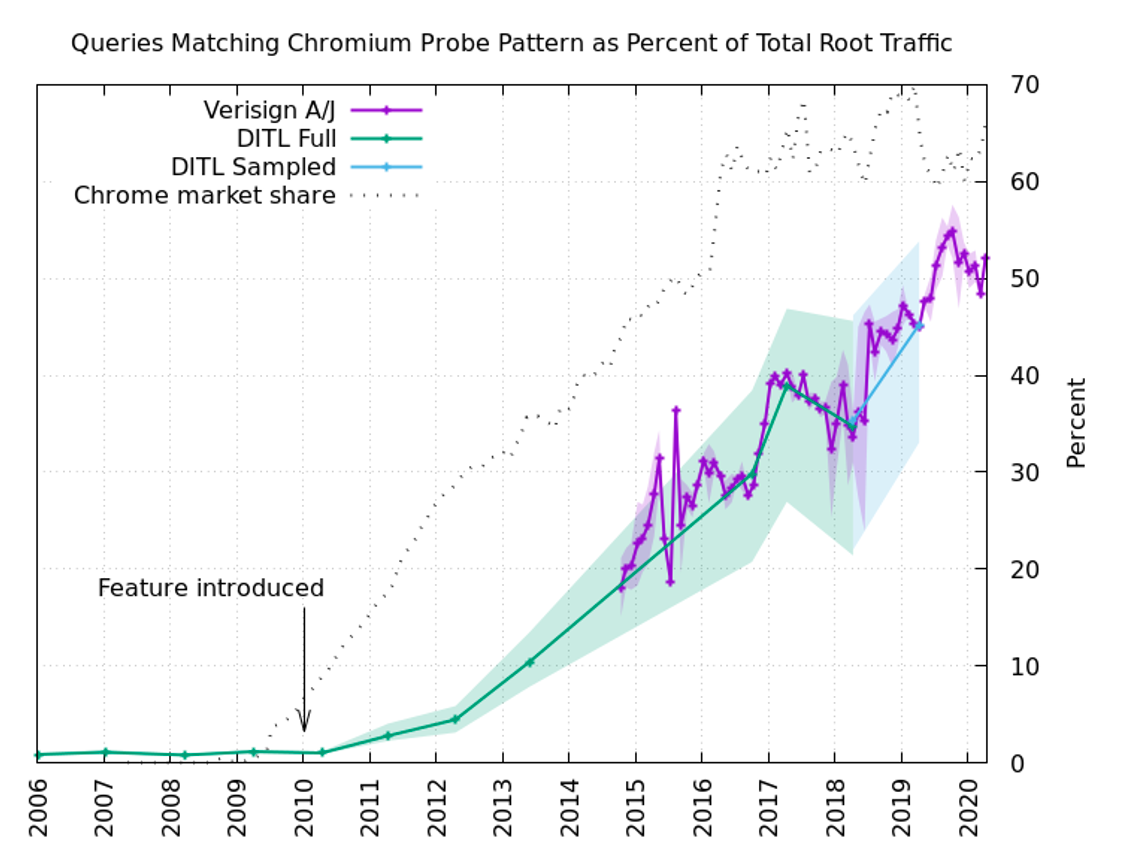
Chromium vérifie "Ce serveur DNS me trompe-t-il?" représentent près de la moitié de tout le trafic atteignant le cluster de serveurs racine DNS Verisign.
Le navigateur Chromium, le projet parent de Google Chrome, le nouveau Microsoft Edge et d'innombrables navigateurs moins connus, veulent offrir aux utilisateurs la facilité de recherche dans un seul champ, parfois appelé «Omnibox». En d'autres termes, l'utilisateur entre à la fois les URL réelles et les requêtes des moteurs de recherche dans la même zone de texte en haut de la fenêtre du navigateur. Pour aller plus loin dans la simplification, cela n'oblige pas non plus l'utilisateur à saisir une partie de l'URL avec
http://ou https://.
Aussi pratique que cela puisse être, cette approche nécessite que le navigateur comprenne ce qu'il faut compter comme URL et quoi comme requête de recherche. Dans la plupart des cas, cela est assez évident - par exemple, une chaîne avec des espaces ne peut pas être une URL. Mais les choses peuvent devenir plus délicates lorsque l'on considère les intranets - des réseaux privés qui peuvent également utiliser des domaines privés de premier niveau pour résoudre de vrais sites Web.
Si un utilisateur saisit «marketing» sur l'intranet de son entreprise et que l'intranet de son entreprise possède un site Web interne portant le même nom, Chromium affiche une boîte d'informations demandant à l'utilisateur s'il souhaite rechercher «marketing» ou accéder à
https://marketing... Tout va bien, mais de nombreux FAI et fournisseurs de Wi-Fi publics «détournent» chaque URL mal orthographiée, redirigeant l’utilisateur vers une page remplie de bannières publicitaires.
Génération aléatoire
Les développeurs de Chromium ne voulaient pas que les utilisateurs des réseaux ordinaires voient une fenêtre d'informations à chaque fois qu'ils recherchent un mot, leur demandant ce qu'ils voulaient dire, ils ont donc mis en œuvre un test: lors du démarrage d'un navigateur ou du changement de réseau, Chromium effectue des recherches DNS de trois "domaines" générés aléatoirement. de haut niveau, de sept à quinze caractères. Si deux de ces requêtes renvoient avec la même adresse IP, Chromium suppose que le réseau local «vole» les erreurs
NXDOMAINqu'il devrait recevoir, de sorte que le navigateur considère toutes les requêtes saisies du même mot comme des tentatives de recherche jusqu'à nouvel ordre.
Malheureusement, sur des réseaux qui ne sont pasvoler les résultats des requêtes DNS, ces trois opérations vont généralement tout en haut, aux serveurs de noms racine eux-mêmes: le serveur local ne sait pas comment
qwajuixkrésoudre, donc il transmet cette requête à son transitaire, qui fait de même, jusqu'à ce que finalement, a.root-servers.netou l'un des ses «frères» ne seront pas obligés de dire «Désolé, mais ce n'est pas un domaine».
Puisqu'il y a environ 1,67 * 10 ^ 21 faux noms de domaine possibles de sept à quinze caractères, il est courant pour chacun de ces tests, effectués sur un réseau «équitable», d'arriver au serveur racine. Cela équivaut à la moitié de la charge totale sur le DNS racine, selon les statistiques de la partie des clusters
root-servers.netappartenant à Verisign.
L'histoire se répète
Ce n'est pas la première fois qu'un projet bien intentionné a inondé ou presque inondé une ressource publique avec un trafic inutile - cela nous a immédiatement rappelé la longue et triste histoire de D-Link et du serveur NTP de Pole-Henning Camp au milieu des années 2000. X.
En 2005, Poul-Henning, développeur de FreeBSD, qui possédait également le seul serveur de protocole de temps réseau Stratum 1 du Danemark, a reçu une facture inattendue et importante pour le trafic transmis. En bref, la raison était que les développeurs D-Link ont enregistré les adresses des serveurs NTP Stratum 1, y compris le serveur Campa, dans le micrologiciel de la gamme de commutateurs, routeurs et points d'accès de la société. Cela a instantanément multiplié par neuf le trafic du serveur Kampa, ce qui a amené Danish Internet Exchange (le point d'échange Internet du Danemark) à modifier son tarif de «gratuit» à «9 000 dollars par an».
Le problème n'était pas qu'il y avait trop de routeurs D-Link, mais qu'ils «violaient la chaîne de commandement». Tout comme DNS, NTP doit fonctionner de manière hiérarchique - les serveurs de la couche 0 relaient les informations aux serveurs de la couche 1, qui relaient les informations aux serveurs de la couche 2, et ainsi de suite dans la hiérarchie. Un routeur domestique, un commutateur ou un point d'accès typique, comme celui que D-Link demandait des adresses de serveur NTP, devait envoyer des requêtes à Stratum 2 ou Stratum 3.
Le projet Chromium, probablement avec les meilleures intentions, a répété le problème avec NTP dans le problème avec DNS en chargeant les serveurs racine d'Internet avec des requêtes qu'ils ne devraient jamais avoir à gérer.
Il y a de l'espoir pour une solution rapide
Il existe un bogue ouvert dans le projet Chromium qui nécessite que le détecteur de redirection intranet par défaut soit désactivé pour résoudre ce problème. Nous devons rendre hommage au projet Chrome: un bug a été trouvé avant , Matt Thomas de Verisign a attiré son attention sur son grand poste dans le blog APNIC. Le bug a été découvert en juin, mais est resté dans l'oubli jusqu'au poste de Thomas; après le jeûne, il a commencé à être surveillé de près.
On espère que le problème sera bientôt résolu et que les serveurs DNS racine n'auront plus à répondre à environ 60 milliards de fausses requêtes chaque jour.
La publicité
Les serveurs Epic sont des VPS Windows ou Linux avec de puissants processeurs AMD EPYC et des disques Intel NVMe très rapides. Dépêchez-vous de commander!
