Nous, une petite équipe de développement de l'un des départements de YaKurier, voulions vraiment contribuer au développement rapide de l'espace des technologies sans pilote. Acheté une Prius pour l'expérimentation, un peu de périphérie, a conçu son propre truc avec l'accent du système intelligent, imitant l'attention du conducteur. Nous avons commencé. Et qu'en est-il du système de vision par ordinateur intelligent lui-même et, avec lui, du système «subintelligent» qui assure la détection de la nouveauté, c'est-à-dire cette attention même?
TensorFlow ou quelque chose de similaire - prêt à l'emploi? Plusieurs expériences montrent clairement que pour les cas multifactoriels dynamiques avec réarrangements des tableaux d'entrée, de nombreuses sous-tâches, l'incertitude évidente de nombreuses classes de données reconnues, l'évolutivité inévitable du système en cours de développement, avec le désir d'ajouter les convolutions et les couches de votre propre auteur, l'option est "prête à l'emploi", assez curieusement, nécessite de la sueur, du sang, des budgets et de la frustration des erreurs dans les premiers pas, qui gâchent tout, et qui ne peuvent plus être réparées (sauf avec des béquilles ennuyeuses). Et comme nous sommes une équipe plutôt naïve, nous avons décidé de jouer à notre manière. Il y a une opinion que le point n'est pas dans TensorFlow, mais dans la technologie qu'il met en œuvre, et nous pourrons simplifier quelque chose, améliorer quelque chose et changer quelque chose complètement.
Parlons d'abord des approches de la classification et de la reconnaissance des formes, nous sommes sûrs que vous savez tout à leur sujet, mais où aller sans eye-liner. Nous nous en tiendrons à des abstractions et des visualisations plus humaines au lieu de parler dans un langage mathématique strict et prendrons un cas abstrait de reconnaissance des concombres et des tomates conventionnels.
Classification et reconnaissance de formes
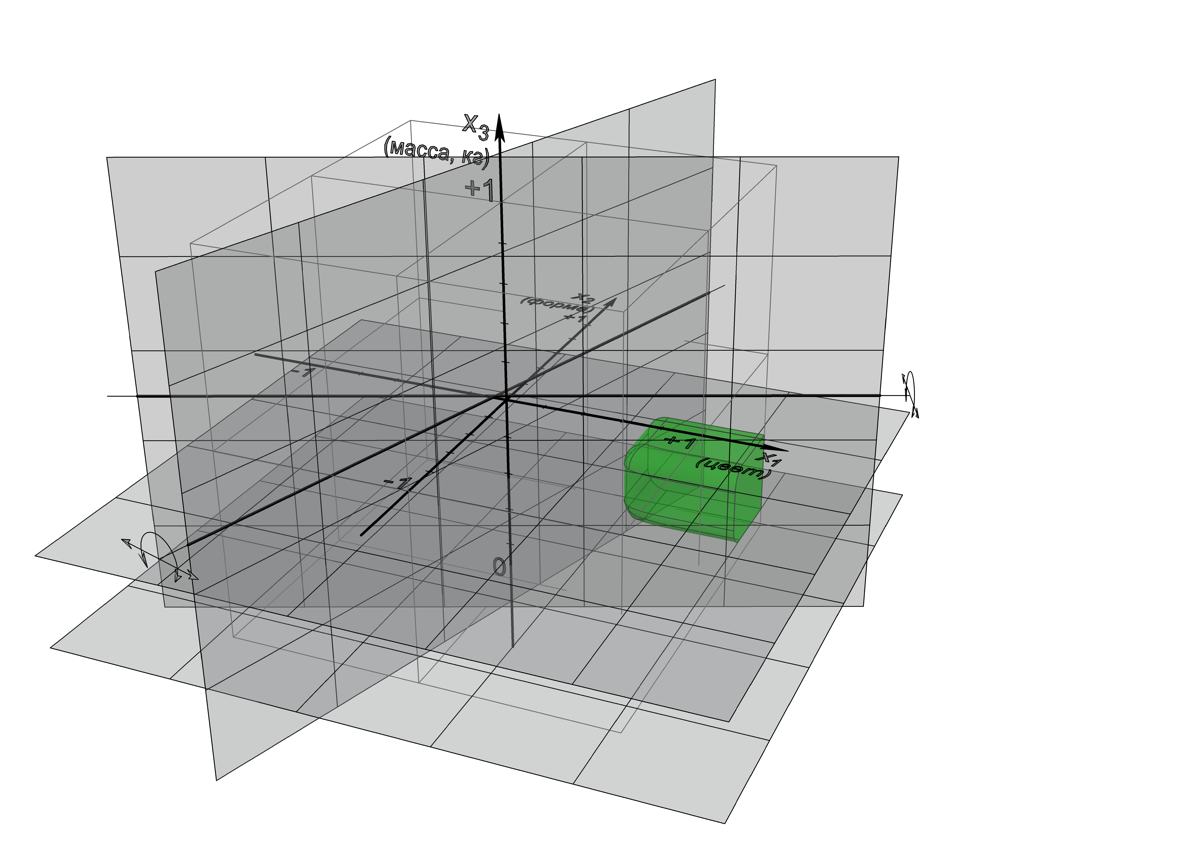
- , , : ( ) ( ). «», , // , , , , , , x_1 x_2.
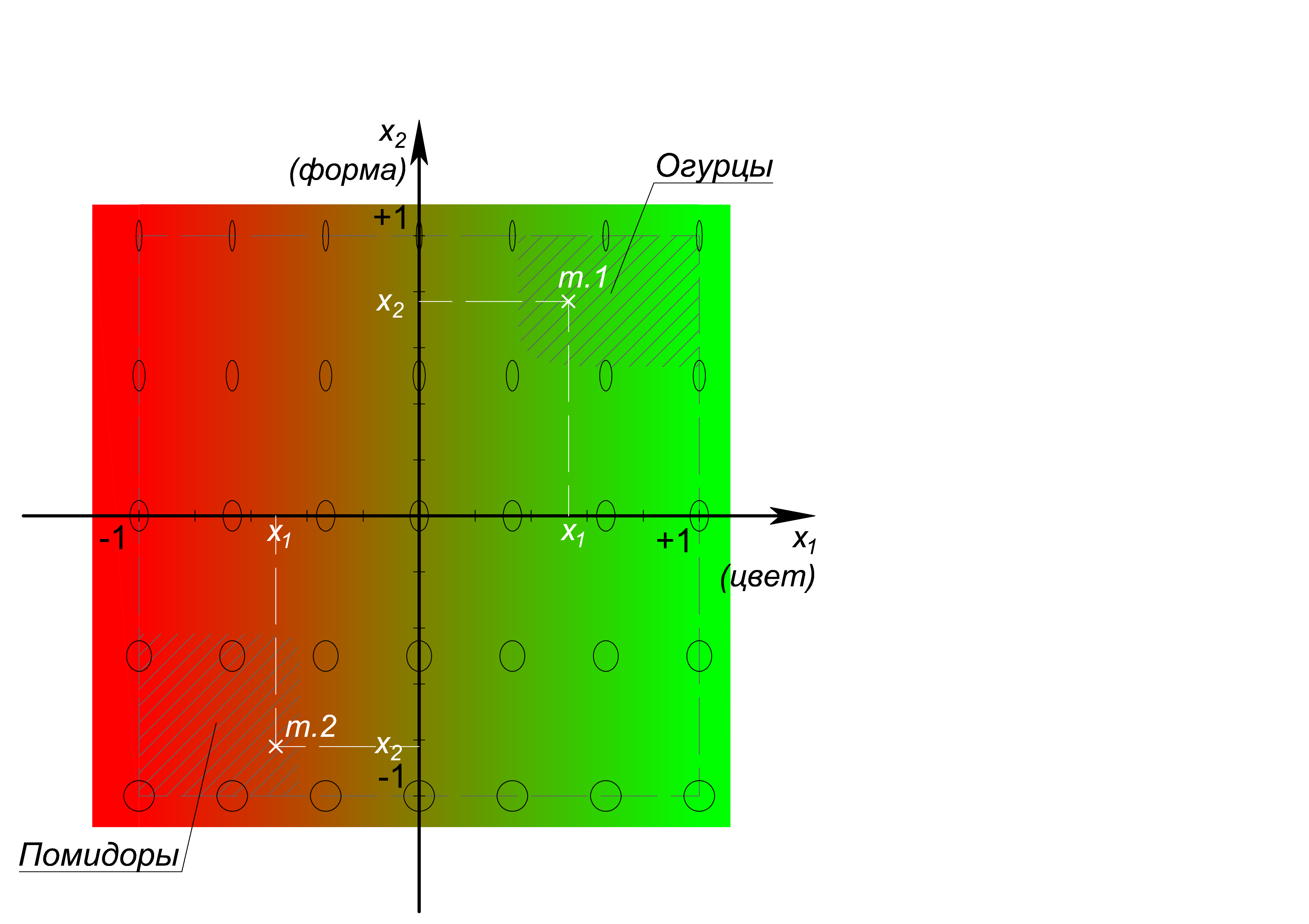
, , x_1: (-1), (+1); x_2: (-1), () 1/5 (+1). – , – , . , , , , , 1 {(x_1=0,53@x_2=0,77)} – , 2 {(x_1=-0,51@x_2=-0,82)} – .
, , – – 2 . , , , -, , -, , , , , , , 900 (3030 px) , 900- . , , , (, ).
? , . , , , - ? , , . , . , , : , , , , , :
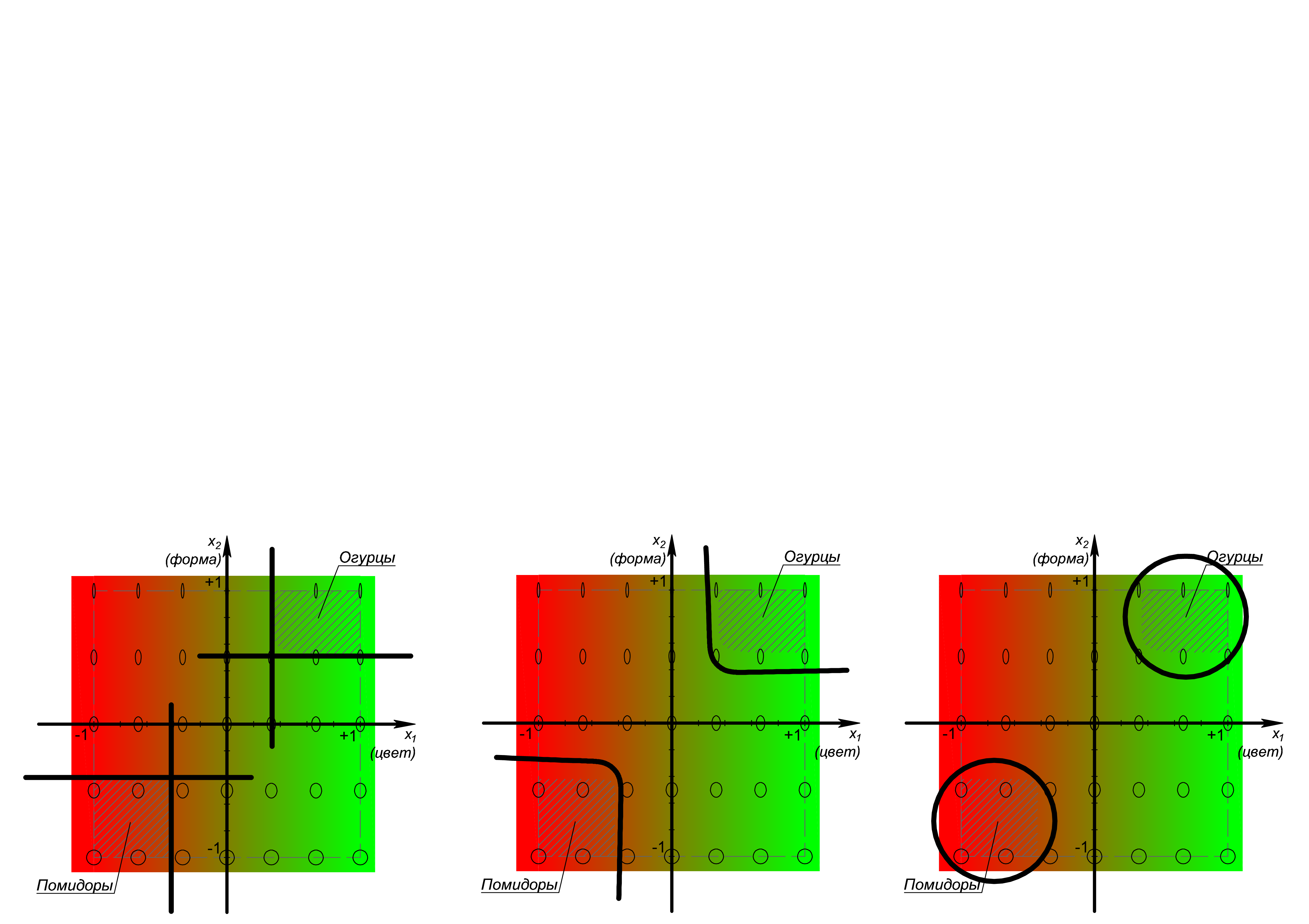
, 4- , .. N- .
II-
, , . , , , . :
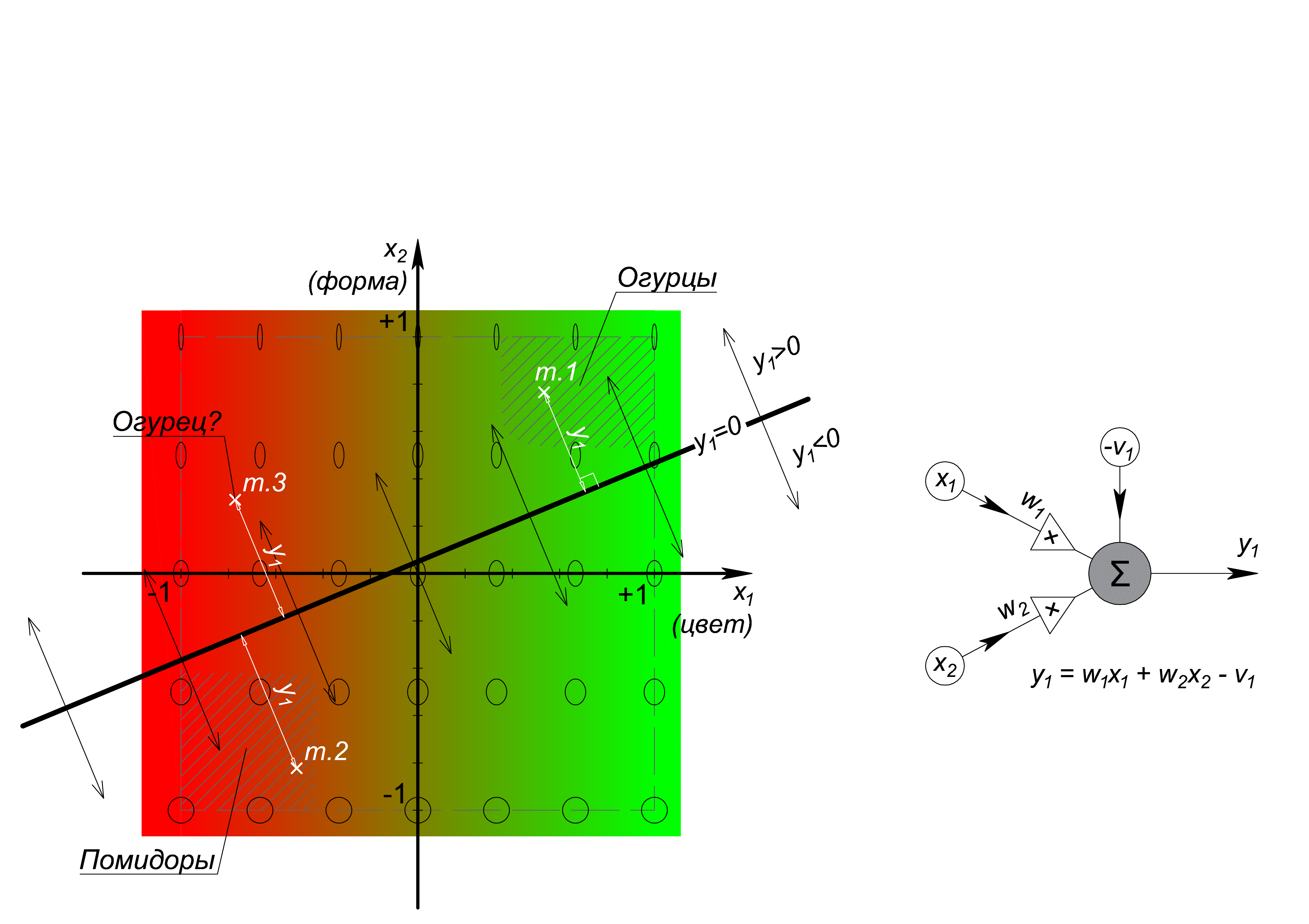
: Ax+By+C=0, A, B C w_1, w_2 -v_1, {x;y} {x_1;x_2 }. , N- – N-1. 0, () , , – « », – « », () – . «», «» «- » , - , (. ). . , , . .
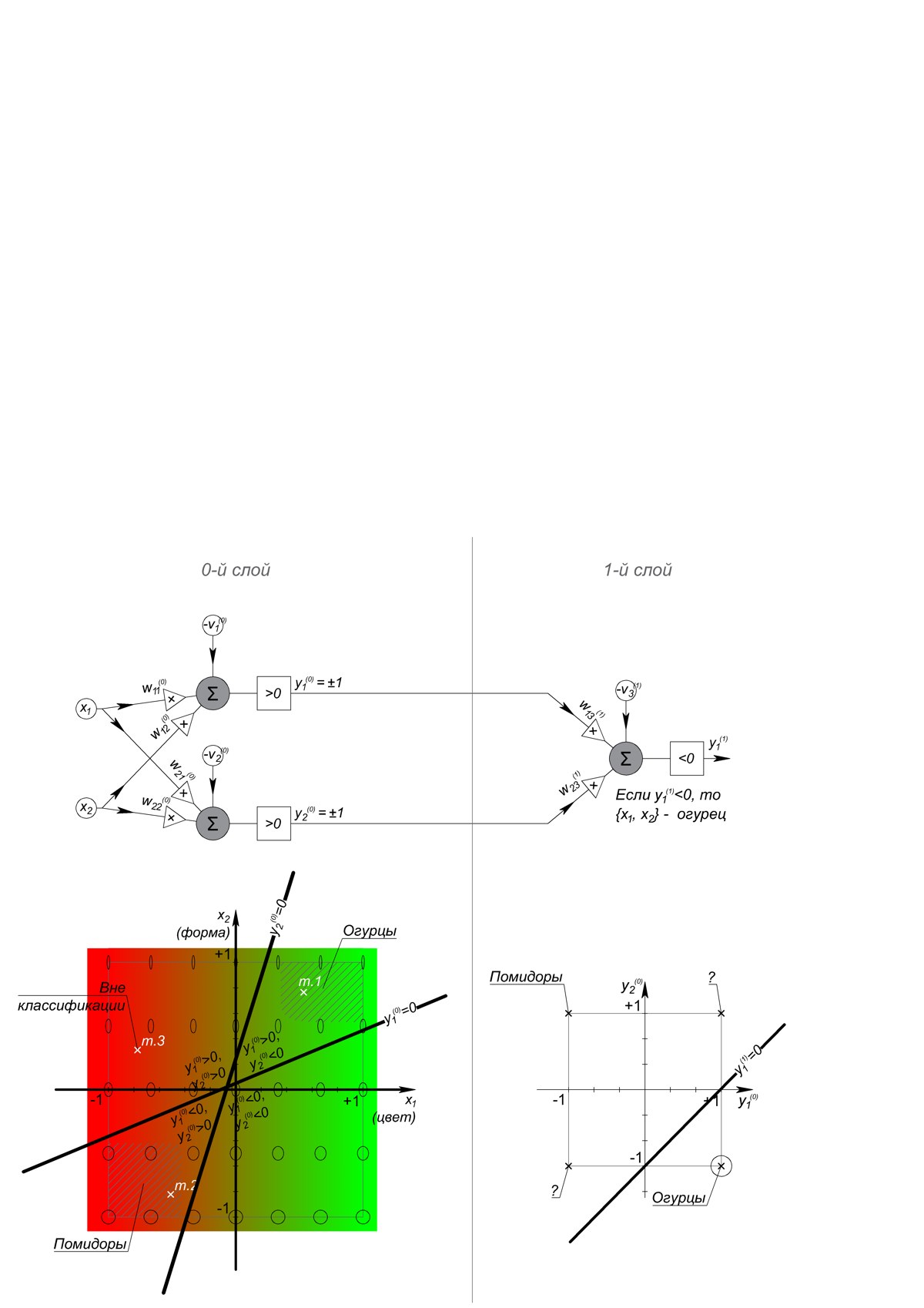
0, «» « », «», «» « » « » 1- .
w (k)/j, , N- – . , , , . , 0 1 .
– , ( , – ):

– , , ( ), Ax2+By2+Cxy+Dx+Ey+F=0, . - , , ( , ). , / , , . .
, - . – , , , – , – . : S-, A-, R- . , , MNIST, : , , :
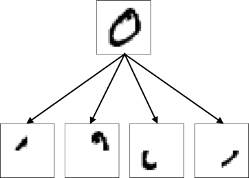
/ …
! , 1- :

. . -, , , , , (cost function) , , , . , - , «» , , , , , , , , , , , , – ( – , – ):

-, , , , , - , . , , , , , . . . 2-- - :
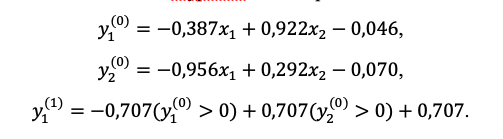
? , x_1: – (-1), – (+1); x_2: – (-1), 1/5 – (+1). , 2- - , , 900- ? , 1- , – . , . , II- – , , .
. , , , , . . , , .
, , , , .
, , , , : , , , / , , . , , , , , , , , , , - .
. ? -, , , -, , , , . , , . , , , – .
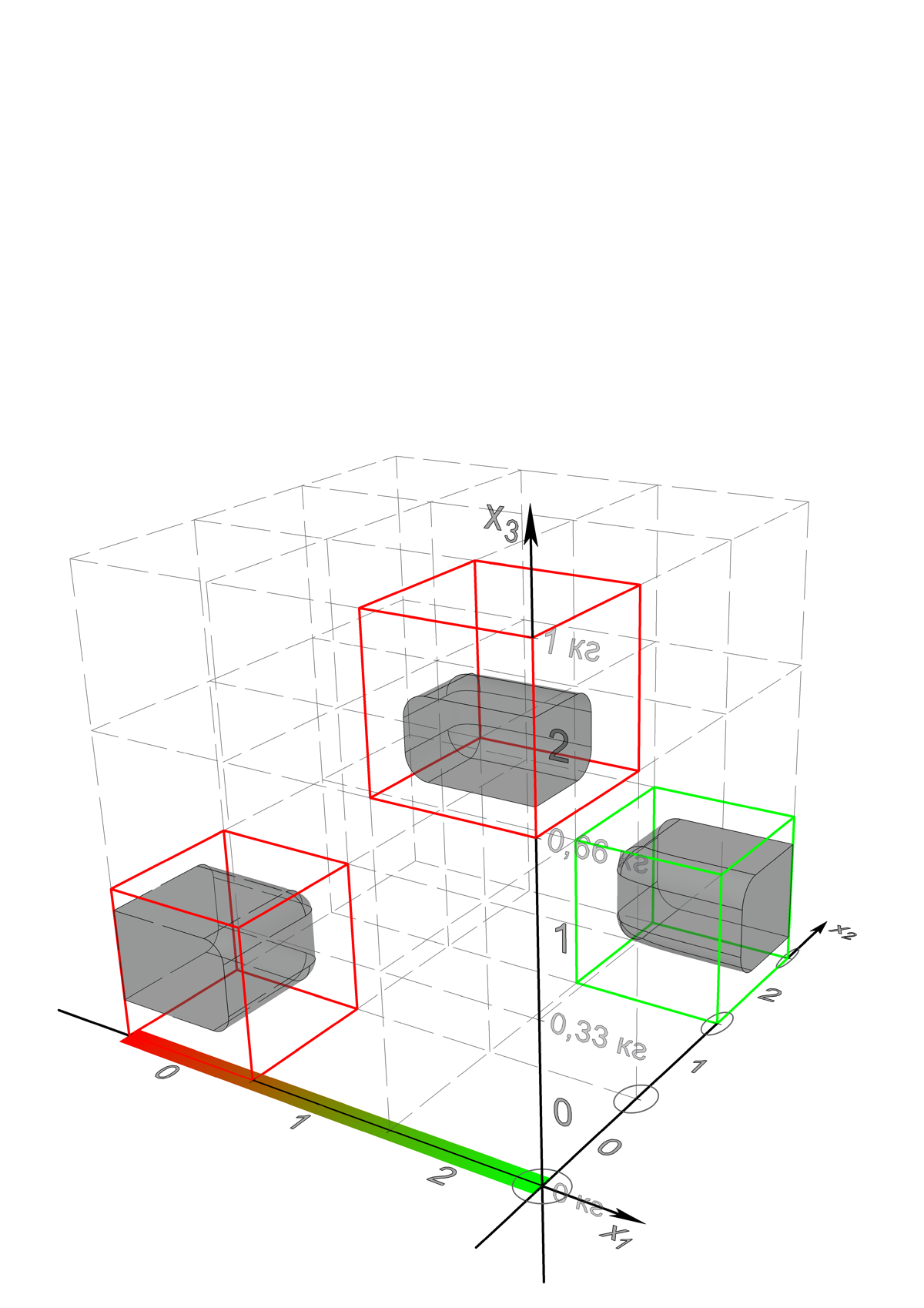
? {0;0;0} {2;0;2} , {2;2;0} – . , , . , , , , , , , .. , . , , , , , , , , .
. , , , , , , , , .
:


w_i – , b_i – , . h. , /, , – .
? , , , , , – . . , , , , , GPU CUDA.
MNIST, 28x28 px. 10 10 , , – . , , .
, , , , , 30÷60 .
, , , . – MNIST, – , – .
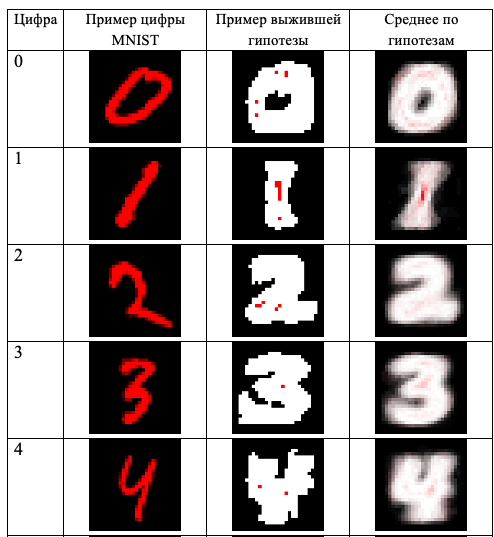
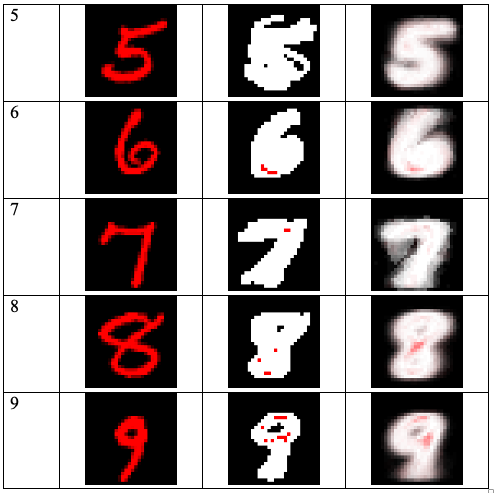
, , . , , .
« » .
( « »), , « » « ». , , , , «».
, , , (), , , ( , ). , TensorFlow 2- , , MNIST 2,6%, . , .
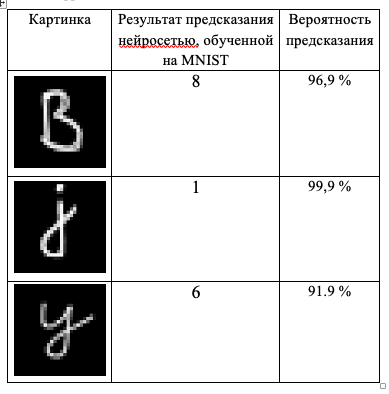
MNIST (10 000 ) « ».
, + 25%:

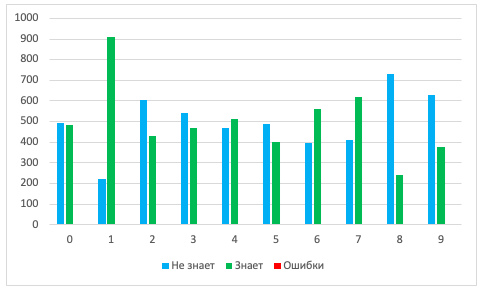
:
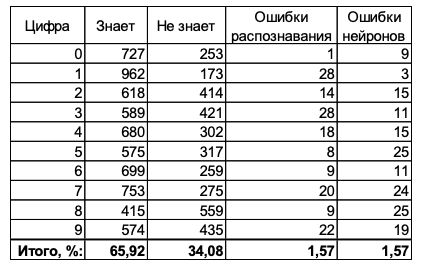
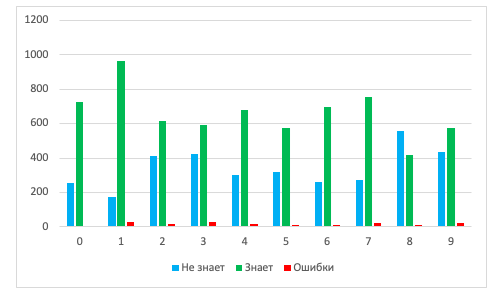
:
- ;
- , , , .
:
- , , , , ;
- ;
- , , ;
- .
, , , , , .
Hmm, qu'est-ce que la technologie sans pilote mentionnée au début a à voir avec cela? Nous sommes convaincus que c'est dans ce domaine que notre réseau intelligent trouvera ses principales applications, nous permettant de surmonter les barrières existantes liées à la multiplicité, la variabilité et l'hétérogénéité dans la perception et la reconnaissance de l'environnement.