
Il y a une telle blague dans les cercles informatiques que l'apprentissage automatique (ML) est comme le sexe chez les adolescents: tout le monde en parle, tout le monde prétend le faire, mais en fait, très peu de gens réussissent. FunCorp a réussi à introduire le ML dans la mécanique principale de son produit et à réaliser une amélioration radicale (près de 40%!) Des indicateurs clés. Intéressant? Bienvenue au chat.
Un peu de contexte
Pour ceux qui lisent le blog FunCorp de façon irrégulière, laissez-moi vous rappeler que notre produit le plus réussi est l'application iFunny UGC avec des éléments d'un réseau social pour les amateurs de mèmes. Les utilisateurs (et c'est un représentant sur quatre de la jeune génération aux États-Unis) téléchargent ou créent de nouvelles photos ou vidéos directement dans l'application, et un algorithme intelligent sélectionne (ou, comme on dit, «fonctionnalités», à partir du mot «vedette») le meilleur d'entre eux et forme chacun jour de 7 numéros de 30 à 60 unités de contenu dans un flux séparé, avec lequel 99% de l'audience interagit. En conséquence, en entrant dans l'application, chaque utilisateur voit les meilleurs mèmes, vidéos et images amusantes. Si vous visitez fréquemment, le flux défile rapidement et l'utilisateur attend le prochain numéro dans quelques heures. Cependant, si vous visitez moins souvent, le contenu en vedette s'accumule et le flux peut atteindre 1 000 articles en quelques jours.
En conséquence, la tâche s'est posée: montrer à chaque utilisateur le contenu le plus pertinent pour lui, regrouper les mèmes qui l'intéressent personnellement au début du fil.
Depuis plus de 9 ans d'existence d'iFunny, il y a eu plusieurs approches à cette tâche.
Tout d'abord, nous avons essayé la manière évidente de trier le flux par le nombre de sourires (notre analogue de "j'aime") - Taux de sourire . C'était mieux que de trier par ordre chronologique, mais en même temps conduit à l'effet de la "température moyenne à l'hôpital": il y a peu d'humour que tout le monde aime, et il y aura toujours ceux qui ne sont pas intéressés (et même franchement ennuyeux) des sujets populaires aujourd'hui ... Mais vous voulez aussi voir toutes les nouvelles blagues amusantes de votre dessin animé préféré.
Dans l'expérience suivante, nous avons essayé de prendre en compte les intérêts des microcommunautés individuelles: fans d'anime, de sports, de mèmes avec des chats et des chiens, etc. Pour ce faire, ils ont commencé à former plusieurs flux thématiques et proposent aux utilisateurs de choisir des sujets qui les intéressent, à l'aide de balises et de textes reconnus dans les images. Quelque chose s'est amélioré, mais l'effet du réseau social a été perdu: il y a moins de commentaires sur le contenu présenté, qui a joué un grand rôle dans l'engagement des utilisateurs. De plus, sur le chemin des flux segmentés, nous avons perdu beaucoup de mèmes très populaires. Ils ont regardé "Favorite Cartoon", mais n'ont pas vu les blagues sur "The Last Avengers".
Depuis que nous avons déjà commencé à implémenter des algorithmes d'apprentissage automatique dans notre produit, que nous avons présenté lors de notre propre rencontre, ils voulaient faire une autre approche en utilisant cette technologie.
Il a été décidé d'essayer de construire un système de recommandation basé sur le principe du filtrage collaboratif. Ce principe est bon dans les cas où l'application a très peu de données sur les utilisateurs: peu indiquent leur âge ou leur sexe lors de leur inscription, et seule l'adresse IP permet de supposer leur emplacement géographique (bien que l'on sache sans diseurs de bonne aventure que la grande majorité des utilisateurs d'iFunny sont résidents États-Unis), et par modèle de téléphone - niveau de revenu. Sur ce, en général, tout. Le filtrage collaboratif fonctionne comme ceci: l'historique des évaluations positives du contenu de l'utilisateur est pris, d'autres utilisateurs avec des notes similaires sont trouvés, puis il est recommandé ce que les mêmes utilisateurs ont déjà aimé (avec des notes similaires).
Caractéristiques de la tâche
Les mèmes sont un contenu assez spécifique. Premièrement, il est très sensible aux tendances en évolution rapide. Le contenu et la forme qui sont allés au sommet et ont fait sourire 80% du public il y a une semaine, peuvent aujourd'hui être gênants par leur nature secondaire et leur non-pertinence.
Deuxièmement, une interprétation très non linéaire et situationnelle de la signification du mème. Dans la sélection de nouvelles, vous pouvez attraper des noms bien connus, des sujets qui sont assez régulièrement utilisés par un utilisateur particulier. Dans une sélection de films, vous pouvez découvrir la distribution, le genre et bien plus encore. Oui, vous pouvez comprendre tout cela dans une sélection de mèmes personnels. Mais comme il serait décevant de rater un véritable chef-d'œuvre de l'humour, qui utilise des images ou un vocabulaire qui ne rentre pas du tout dans le contenu sémantique!

Enfin, une très grande quantité de contenu généré dynamiquement. Chez iFunny, les utilisateurs créent des dizaines de milliers de publications chaque jour. Tout ce contenu doit être «ratissé» le plus rapidement possible, et dans le cas d'un système de recommandation personnalisé, non seulement pour trouver des «diamants», mais aussi pour pouvoir prédire l'appréciation du contenu par différents représentants de la société.
Que signifient ces fonctionnalités pour le développement de modèles d'apprentissage automatique? Tout d'abord, le modèle doit être constamment formé sur les données les plus récentes. Au tout début de l'immersion dans le développement d'un système de recommandation, il n'est pas encore tout à fait clair s'il s'agit d'une dizaine de minutes ou de quelques heures. Mais les deux signifient la nécessité d'un recyclage constant du modèle, ou encore mieux - d'une formation en ligne sur un flux continu de données. Toutes ces tâches ne sont pas les plus faciles du point de vue de la recherche d'une architecture de modèle appropriée et de la sélection de ses hyperparamètres: cela garantirait que dans quelques semaines, les métriques ne commenceront pas à se dégrader avec confiance.
Une autre difficulté est la nécessité de suivre le protocole de test a / b que nous avons adopté. Nous n'implémentons jamais rien sans vérifier au préalable certains utilisateurs, en comparant les résultats avec un groupe témoin.
Après de longs calculs, il a été décidé de démarrer un MVP avec les caractéristiques suivantes: nous n'utilisons que des informations sur l'interaction des utilisateurs avec le contenu, nous formons le modèle en temps réel, directement sur un serveur équipé d'une grande quantité de mémoire qui permet de stocker l'historique complet de l'interaction d'un groupe d'utilisateurs de test pendant une période assez longue. Nous avons décidé de limiter le temps de formation à 15-20 minutes afin de maintenir l'effet de nouveauté, ainsi que d'avoir le temps d'utiliser les dernières données des utilisateurs qui viennent massivement sur l'application lors des versions.
Modèle
Tout d'abord, nous avons commencé à déformer le filtrage collaboratif le plus classique avec la décomposition matricielle et l'entraînement en ALS (alternance des moindres carrés) ou SGD (descente de gradient stochastique). Mais ils ont vite compris: pourquoi ne pas commencer tout de suite avec le réseau de neurones le plus simple? Avec un simple maillage monocouche, dans lequel il n'y a qu'un seul calque d'incrustation linéaire, et il n'y a pas d'habillage de calques cachés, afin de ne pas vous enterrer dans les semaines de sélection de ses hyperparamètres. Un peu au-delà de MVP? Peut être. Mais entraîner un tel maillage n'est guère plus difficile qu'une architecture plus classique, si vous avez du matériel équipé d'un bon GPU (il fallait débourser pour cela).
Au départ, il était clair qu'il n'y avait que deux options pour le développement d'événements: soit le développement donnera un résultat significatif en métriques produit, puis il sera nécessaire d'approfondir les paramètres des utilisateurs et du contenu, dans une formation supplémentaire sur les nouveaux contenus et les nouveaux utilisateurs, dans les réseaux de neurones profonds, ou le classement de contenu personnalisé n'apportera pas augmentation tangible et «magasin» peuvent être couverts. Si la première option se produit, tout ce qui précède devra être vissé au calque d'intégration de départ.
Nous avons décidé d'opter pour la machine de factorisation neurale . Le principe de son fonctionnement est le suivant: chaque utilisateur et chaque contenu sont codés par des vecteurs de même longueur fixe - des plongements, qui sont ensuite formés sur un ensemble d'interactions connues entre l'utilisateur et le contenu.
L'ensemble de formation comprend tous les faits sur les utilisateurs qui consultent le contenu. En plus des sourires, il a été décidé d'envisager des clics sur les boutons «partager» ou «enregistrer», ainsi que la rédaction d'un commentaire, pour un retour positif sur le contenu. S'il est présent, l'interaction est marquée par 1 (un). Si, après la visualisation, l'utilisateur n'a pas laissé de commentaires positifs, l'interaction est marquée d'un 0 (zéro). Ainsi, même en l'absence d'échelle de notation explicite, un modèle explicite est utilisé (un modèle avec une notation explicite de l'utilisateur), et non un modèle implicite, qui ne prendrait en compte que les actions positives.
Nous avons également essayé le modèle implicite, mais cela n'a pas fonctionné tout de suite, nous nous sommes donc concentrés sur le modèle explicite. Peut-être, pour le modèle implicite, vous devez utiliser des fonctions de perte de classement plus délicates qu'une simple entropie croisée binaire.
La différence entre la factorisation de matrice neurale et le filtrage collaboratif neuronal standard réside dans la présence de la couche dite de regroupement bi-interaction au lieu de la couche entièrement connectée habituelle qui relierait simplement l'utilisateur et les vecteurs d'incorporation de contenu. La couche Bi-Interaction convertit un ensemble de vecteurs d'incorporation (il n'y a que 2 vecteurs dans iFunny: l'utilisateur et le contenu) en un seul vecteur en les multipliant élément par élément.
En l'absence de couches cachées supplémentaires au-dessus de Bi-Interaction, nous obtenons le produit scalaire de ces vecteurs et, en ajoutant le biais de l'utilisateur et le biais du contenu, l'enveloppons dans un sigmoïde. Il s'agit d'une estimation de la probabilité de commentaires positifs de l'utilisateur après avoir consulté ce contenu. C'est en fonction de cette évaluation que nous classons le contenu disponible avant de le démontrer sur un appareil spécifique.
Ainsi, la tâche de la formation est de s'assurer que l'utilisateur et les incorporations de contenu pour lesquelles il y a une interaction positive sont proches les unes des autres (ont le produit scalaire maximal) et que les incorporations d'utilisateur et de contenu pour lesquelles il y a une interaction négative sont éloignées les unes des autres. (produit scalaire minimum).
À la suite de cette formation, les plongements d'utilisateurs qui sourient de la même chose se rapprochent d'eux-mêmes. Et ceci est une description mathématique pratique des utilisateurs qui peut être utilisée dans de nombreuses autres tâches. Mais c'est une autre histoire.
Ainsi, l'utilisateur entre dans le flux et commence à regarder le contenu. Chaque fois que vous regardez, souriez, partagez, etc. le client envoie des statistiques à notre stockage analytique (dont, s'il est intéressé, nous avons parlé plus tôt dans l'article Passer de Redshift à Clickhouse ). En chemin, nous sélectionnons les événements qui nous intéressent et les envoyons au serveur ML, où ils sont stockés en mémoire.
Toutes les 15 minutes, le modèle est recyclé sur le serveur, après quoi les nouvelles statistiques utilisateur sont prises en compte dans les recommandations.
Le client demande la page suivante du flux, elle est formée de manière standard, mais sur la façon dont la liste de contenu est envoyée au service ML, qui la trie en fonction des poids donnés par le modèle entraîné pour cet utilisateur particulier.

En conséquence, l'utilisateur voit d'abord les images et vidéos qui, selon le modèle, lui seront les plus préférables.
Architecture de service interne
Le service fonctionne sur HTTP. Flask est utilisé comme serveur HTTP en conjonction avec Gunicorn. Il gère deux requêtes: add_event et get_rates.
La requête add_event ajoute une nouvelle interaction entre l'utilisateur et le contenu. Il est ajouté à une file d'attente interne, puis traité dans un processus séparé (avec un pic jusqu'à 1600 rps).
La requête get_rates calcule les poids pour la liste user_id et content_id selon le modèle (au sommet d'une centaine de rps).
Le principal processus interne est le Dispatcher. Il est écrit en asyncio et implémente la logique de base:
- traite la file d'attente des requêtes add_event et les stocke dans un énorme hashmap (200M d'événements par semaine);
- recalcule le modèle dans un cercle;
- enregistre les nouveaux événements sur le disque toutes les demi-heures, tout en supprimant les événements de plus d'une semaine de la carte de hachage.

Le modèle entraîné est placé dans la mémoire partagée, d'où il est lu par les nœuds de calcul HTTP.
résultats
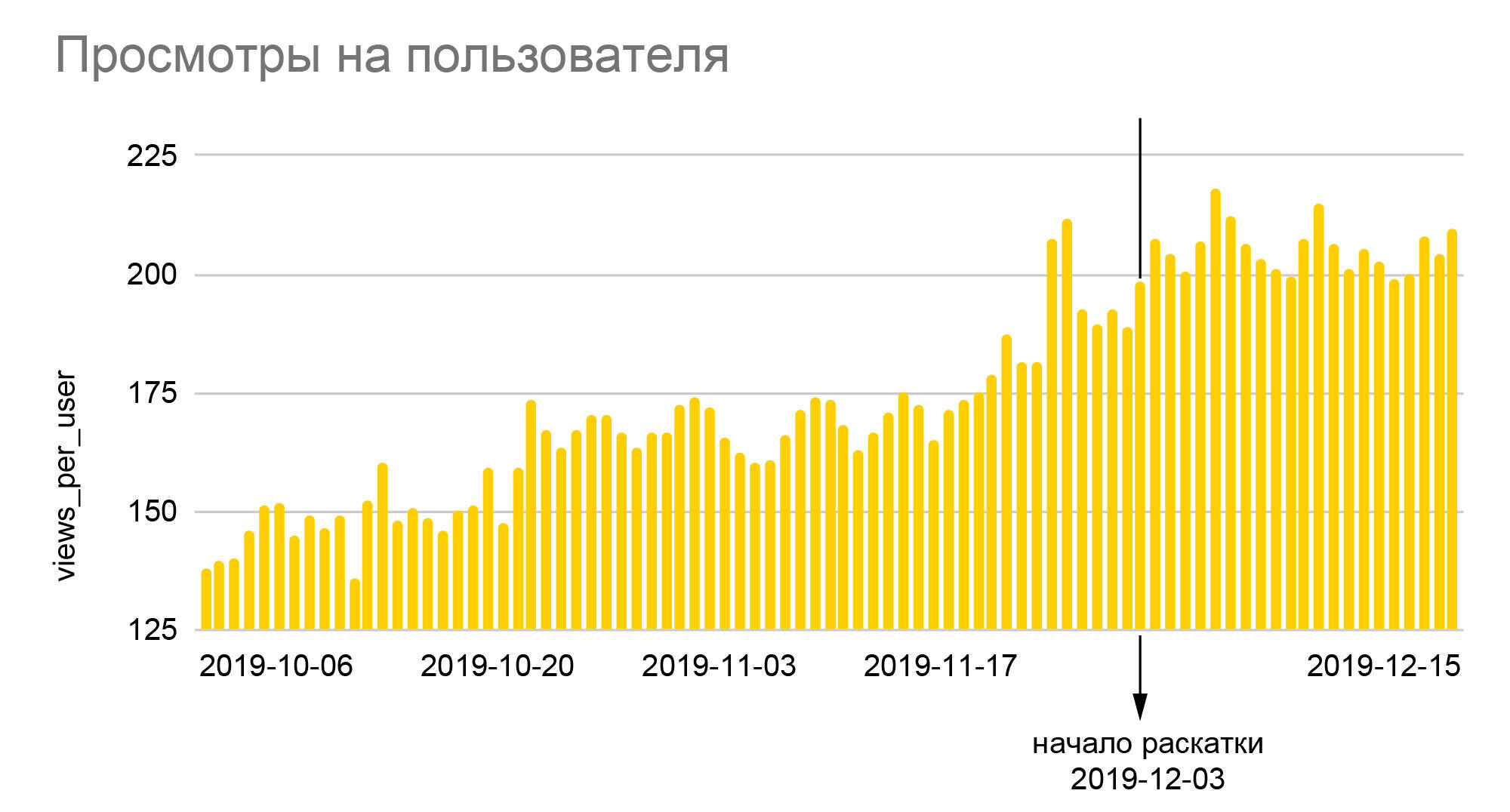

Les graphiques parlent d'eux-mêmes. La croissance de 25% du nombre relatif de smileys et de près de 40% de la profondeur des vues que l'on y voit est le résultat du déploiement du nouvel algorithme à l'ensemble du public à l'issue du test A / B 50/50, soit une réelle augmentation par rapport aux valeurs de base était presque deux fois plus grand. Étant donné qu'iFunny gagne de l'argent grâce à la publicité, l'augmentation en profondeur signifie une augmentation proportionnelle des revenus, ce qui, à son tour, nous a permis de traverser les mois de crise de 2020 assez calmement. Une augmentation du nombre de smileys se traduit par une plus grande fidélité, ce qui signifie une probabilité plus faible d'abandonner l'application à l'avenir; les utilisateurs fidèles commencent à se rendre dans d'autres sections de l'application, à laisser des commentaires, à communiquer entre eux. Et surtout, nous n'avons pas seulement créé une base fiable pour améliorer la qualité des recommandations,mais a également jeté les bases de la création de nouvelles fonctionnalités basées sur la quantité colossale de données comportementales anonymes que nous avons accumulées au fil des années de l'application.
Conclusion
Le service ML Content Rate est le résultat d'un grand nombre d'améliorations et d'améliorations mineures.
Premièrement, les utilisateurs non enregistrés ont également été pris en compte dans la formation. Au départ, il y avait des questions à leur sujet, car ils ne pouvaient a priori pas laisser d'émoticônes - les retours les plus fréquents après la visualisation du contenu. Mais il est vite devenu clair que ces craintes étaient vaines et ont fermé un très grand point de croissance. De nombreuses expérimentations sont faites avec la configuration de l'échantillon de formation: pour y placer une plus grande proportion d'audience ou pour allonger l'intervalle de temps des interactions prises en compte. Au cours de ces expériences, il s'est avéré que non seulement la quantité de données joue un rôle important pour les métriques du produit, mais également le temps de mise à jour du modèle. Souvent, l'augmentation de la qualité du classement s'est noyée dans les 10 à 20 minutes supplémentaires pour recalculer le modèle, ce qui a obligé à abandonner les innovations.
De nombreuses améliorations, même les plus minimes, ont donné des résultats: elles ont soit amélioré la qualité de l'apprentissage, soit accéléré le processus d'apprentissage, soit économisé de la mémoire. Par exemple, il y avait un problème avec le fait que les interactions ne rentraient pas dans la mémoire - elles devaient être optimisées. De plus, le code a été modifié et il est devenu possible d'y pousser, par exemple, plus d'interactions pour le recalcul. Cela a également conduit à une meilleure stabilité du service.
À présent, des travaux sont en cours pour utiliser efficacement les paramètres d'utilisateur et de contenu connus, afin de créer un modèle incrémentiel et de recyclage rapide, et de nouvelles hypothèses pour de futures améliorations émergent.
Si vous souhaitez en savoir plus sur la manière dont nous avons développé ce service et quelles autres améliorations nous avons réussi à mettre en œuvre, écrivez dans les commentaires, après un certain temps, nous serons prêts à écrire la deuxième partie.
À propos des auteurs
Malheureusement, Habr ne permet pas d'indiquer plusieurs auteurs pour l'article. Bien que l'article ait été publié à partir de mon compte, la majeure partie a été écrite par le développeur principal des services FunCorp ML - Grisha Kuzovnikov (PhoenixMSTU), ainsi qu'un analyste et data scientist - Dima Zemtsov. Votre serviteur récalcitrant est principalement responsable des blagues sexuelles des adolescents, de la section introduction et résultats, ainsi que du travail éditorial. Et, bien sûr, toutes ces réalisations n'auraient pas été possibles sans l'aide des équipes de développement backend, de l'assurance qualité, des analystes et de l'équipe produit, qui ont inventé tout cela et passé plusieurs mois à mener et ajuster des expériences A / B.