Partie 1. Début
1.1 Introduction et énoncé du problème
Chez MTS, nous contrôlons de manière centralisée la qualité des réseaux de transmission de données ou, plus simplement, le réseau de transport (à ne pas confondre avec le réseau de transport logistique), ci-après dénommé TS. Et, dans le cadre de notre activité, nous devons constamment résoudre deux tâches principales:
- Une dégradation des services client (par rapport au TS) a été détectée - il est nécessaire de déterminer le chemin de leur connexion via le TS et de savoir si la raison de la dégradation des services est une partie du TS. De plus, nous appellerons cela le problème direct.
- Une dégradation de la qualité du canal de transport ou de la séquence de canaux est détectée - il est nécessaire de déterminer quels services dépendent de ce canal ou de ces canaux pour déterminer l'impact. De plus, nous appellerons cela le problème inverse.
Les services TS s'entendent comme toute connexion d'équipement client. Il peut s'agir de stations de base (BS), de clients B2B (utilisant MTS TS pour organiser l'accès à Internet et / ou de superposer des réseaux VPN), de clients à accès fixe (accès dit haut débit), etc. etc.
Nous avons à notre disposition deux systèmes d'information centralisés:
| Système de surveillance des performances | Paramètres de réseau et données de topologie |
|---|---|
 |
 |
| Métriques, KPI TS | Paramètres de configuration, canaux L2 / L3 |
Tout réseau de transport est intrinsèquement un graphe orienté dans lequel chaque bord a une bande passante non négative. Ainsi, dès le début, la recherche de solutions à ces problèmes a été menée dans le cadre de la théorie des graphes.
Premièrement, le problème de la comparaison des indicateurs de qualité du TS et des services avec la topologie TS a été résolu en combinant et en représentant littéralement la topologie et les données de qualité sous la forme d'un graphe de réseau.
La vue du graphique formée en fonction de la topologie et des données de performance a été implémentée à l'aide du logiciel open source Gephi . Cela a permis de résoudre le problème de la représentation automatique de la topologie, sans travail manuel sur sa mise à jour. Cela ressemble à ceci:
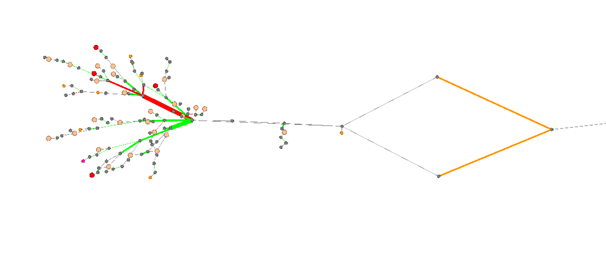
Ici, les nœuds sont, en fait, les nœuds du TS (routeurs, commutateurs) et les nœuds de base, les bords sont les canaux du TS. Le codage couleur, respectivement, indique la présence de dégradations de qualité et l'état de traitement de ces dégradations.
Il semblerait que ce soit assez clair et que vous puissiez travailler, mais:
- Le problème direct (du service au chemin du service) ne peut être résolu assez précisément que si la topologie TS elle-même est assez simple - un arbre ou juste une connexion série, sans anneaux ni routes alternatives.
- Le problème inverse peut être résolu dans une condition similaire, mais en même temps, au niveau de l'agrégation et du cœur du réseau, il est impossible de résoudre ce problème en principe, car ces segments sont régis par des protocoles de routage dynamique et ont de nombreuses routes alternatives potentielles.
Aussi, gardez à l'esprit qu'en général, la topologie du réseau est beaucoup plus compliquée (le fragment ci-dessus est entouré en rouge):

Et ce n'est pas le plus petit segment - la topologie est de plus en plus complexe:

Ainsi, cette option convenait à l'analyse méditative de cas individuels, mais en aucun cas pour un travail rationalisé et, de plus, pas pour automatiser la solution du direct et du reverse.
Partie 2. Automatisation v1.0
Laissez-moi vous rappeler les tâches que nous avons résolues:
- Déterminer le chemin du service à travers le véhicule - Tâche directe.
- Détermination des services dépendants à partir du canal TC - Problème inverse.
2.1. Services de transport pour les stations de base (BS)
Généralement, l'organisation du transport du nœud central (contrôleur / passerelle) vers la BS ressemble à ceci:

Sur les segments d'agrégation et au cœur du TS, les connexions se font via les services de transport du réseau MPLS: VPN L2 / L3, VLL. Sur les segments d'accès, les connexions sont effectuées, en règle générale, via des VLAN dédiés.
Permettez-moi de vous rappeler que nous avons une base de données où se trouvent tous les paramètres réels (dans une certaine période) et la topologie du véhicule.
2.2. Solution de segment commuté (accès)
Nous prenons des données sur le VLAN de l'interface logique BS et, étape par étape, nous «parcourons» les liens, dont les ports contiennent cet ID Vlan, jusqu'à ce que nous atteignions le routeur frontalier (MBN).

Pour résoudre un problème aussi simple, j'ai fini par devoir:
- Ecrire un algorithme de traçage pas à pas de la "propagation" de VlanID depuis BS à travers les canaux du réseau d'agrégation
- Tenez compte des lacunes de données existantes. Cela était particulièrement vrai pour les joints entre les nœuds sur les sites.
- En fait, écrivez un algorithme SPF afin de supprimer à la fin les branches sans issue qui ne mènent pas au routeur MVN.
L'algorithme est issu d'un processus principal et de sept sous-processus. Il a fallu 3-4 semaines de temps de travail pur pour l'implémenter et le déboguer.
De plus, nous avons eu un plaisir particulier ...
2.2.1. JOIN SQL
En raison de sa structure, le modèle relationnel pour parcourir le graphe nécessite une approche récursive explicite avec des opérations de jointure à chaque niveau, tout en parcourant à plusieurs reprises le même ensemble d'enregistrements. Ceci, à son tour, entraîne une dégradation des performances du système, en particulier sur les grands ensembles de données.
Pour des raisons évidentes, je ne peux pas citer le contenu des requêtes dans la base de données ici, mais évaluez - chaque "rebord" dans le texte de la requête est la connexion de la table suivante, qui est nécessaire, dans ce cas, pour obtenir une correspondance unifiée entre Port et VlanID:

Et cette demande est pour obtenir, sous une forme unifiée, des interconnexions VlanID à l'intérieur du commutateur:

Considérant que le nombre de ports était de plusieurs dizaines de milliers, et le VLAN était 10 fois plus, tout cela était très réticent à tourner et tourner. Et de telles demandes devaient être faites pour chaque nœud et VlanID. Et «tout décharger en même temps et calculer» est impossible, car il s'agit d'un calcul séquentiel du chemin c avec des opérations pas à pas qui dépendent des résultats de l'étape précédente.
2.3. Définition d'un chemin de service dans les segments acheminés
Ici, nous avons commencé avec un fournisseur MVN dont le système de gestion a fourni des données sur les LSP actuels et en veille sur le segment MPLS. Connaissant l'interface d'accès qui était connectée à l'accès (L2 Vlan), il était possible de trouver le LSP puis, grâce à une série de requêtes au système NBI, d'obtenir le chemin du LSP, constitué de routeurs et de liens entre eux.

- Comme pour le segment commuté, la description du déchargement du chemin LSP du service MPLS a abouti à un algorithme avec déjà 17 sous-programmes.
- La solution ne fonctionnait que sur les segments servis par ce fournisseur
- Il était nécessaire de décider de la définition des liaisons entre les services MPLS (par exemple, au centre du segment, il y avait un service VPLS général, et EPIPE ou L3VPN en divergeait)
Nous avons travaillé sur la question pour d'autres fournisseurs de MVN, où il n'y avait pas de systèmes de contrôle, ou ils n'ont pas fourni de données sur le passage actuel du LSP en principe. Nous avons trouvé une solution pour plusieurs, mais - le nombre de LSP passant par le routeur n'est plus le nombre de VanID, qui est enregistré sur le commutateur. Retarder un tel volume de données «à la demande» (après tout, nous avons besoin d'informations opérationnelles) - il y a un risque de mettre le matériel hors service.
En outre, des questions supplémentaires se sont posées:
- – , , . .. – MPLS .
- , LSP, . . .
2.4. .
Les données reçues sur les chemins de connexion des services doivent être écrites quelque part, afin que nous puissions y faire référence ultérieurement lors de la résolution de nos problèmes Direct et Inverse.
L'option de stockage dans une base de données relationnelle a été immédiatement exclue: est-il si difficile d'agréger des données provenant de nombreuses sources pour pouvoir ensuite les trier dans les ensembles de tables suivants? Ce n'est pas notre méthode. De plus, rappelez-vous des jointures à plusieurs étages et de leurs performances.
Les données doivent contenir des informations sur la structure du service et les dépendances de ses composants: liens, nœuds, ports, etc.
Comme solution de test, le format XML et Native-XML DB - Exist ont été choisis.
En conséquence, chaque service a été enregistré dans la base de données dans le format (les détails sont omis par souci de compacité):
<services>
<service>
<id>,<description> (, )
<source>
<target> Z
<<segment>> L2/L3
<topology> (, /, )
<<joints>> (, /, )
</service>
</services>La requête de données pour les problèmes directs et inverses a été effectuée à l'aide du protocole XPath:

Tout. Maintenant, le système fonctionne - pour une requête avec le nom de la BS, la topologie de sa connexion via le réseau de transport est renvoyée, pour une requête avec le nom du nœud et du port du TS, une liste des BS qui en dépendent pour la connexion est renvoyée. Par conséquent, nous avons tiré les conclusions suivantes ...
2.5.

Au lieu de se diriger vers les conclusions de la partie 2
2.5.1. Pour le segment commuté (réseaux sur commutateurs Ethernet L2)
- Des données complètes sur la topologie et le port - la correspondance VlanID sont requises. S'il n'y a pas de données VlanID sur un lien, l'algorithme s'arrête, le chemin n'a pas été trouvé
- Requêtes improductives à plusieurs niveaux sur une base de données relationnelle. Lorsqu'un nouveau fournisseur apparaît avec ses propres spécificités, paramètres - ajout de demandes à toutes les étapes du travail
2.5.2. Pour un segment acheminé
- Limité par les capacités du MVN SU à fournir des données sur la topologie des services LSP MPLS.
- – , .. LSP .
- LSP – ( , “” ).
2.5.3.
- , , , , ( – , ), , – .
- . 3-4 .
- , .. , MPLS .
- – , .
2.6. -
- , , .. – .
- , -
- (, VlanID)
Après avoir évalué les options possibles pour la mise en œuvre de nos souhaits, nous avons décidé de la classe de systèmes qui fourniraient tout cela "prêt à l'emploi" - c'est ce qu'on appelle. bases de données de graphes.
Bien que la dernière phrase se lit comme quelque chose de linéaire et simple, étant donné qu'auparavant aucun de nous (et nos informaticiens, comme il s'est avéré aussi) n'avait jamais rencontré une telle classe de base de données, ils ont pris une décision un peu par accident: des bases de données similaires ont été mentionnées (mais n'a pas compris) dans le cours de présentation du Big Data. En particulier, il a mentionné le produit Neo4j... Non seulement, à en juger par la description, il a satisfait à toutes nos exigences, mais il dispose également d'une version communautaire fonctionnelle entièrement gratuite. Ceux. - pas un essai de 30 jours, pas coupé la fonctionnalité principale, mais un produit entièrement fonctionnel que vous pouvez étudier lentement. Ce n'est pas le dernier (sinon le principal) rôle dans le choix qui a été joué par le large support des algorithmes de graphes .
Partie 3. Un exemple de mise en œuvre du problème direct dans Neo4j
Afin de ne pas faire glisser le récit linéaire sur la façon dont le modèle TS est implémenté dans la base de données de graphes Neo4j, nous montrerons immédiatement le résultat final avec un exemple.
3.1. Tracer le chemin de l'interface Iub pour 3G BS

Le chemin de connexion du service passe par deux segments: un MVN acheminé et une ligne de relais radio commuté (les stations de relais radio fonctionnent comme des commutateurs Ethernet). Le chemin à travers le segment RRL est déterminé de la même manière que celle décrite dans la partie 2 - par le passage de l'interface BS VlanID le long du segment RRL jusqu'au routeur frontière MVN. Le segment MVN connecte le routeur frontière (avec le segment RRL) - avec le routeur auquel le contrôleur BS (RNC) est connecté.
Initialement, à partir du paramètre Iub, nous savons exactement quel MVN est la passerelle pour la BS (frontière MVN) et quel contrôleur est desservi par la BS.
Sur la base de ces conditions initiales, nous allons créer 2 requêtes dans la base de données pour chacun des segments. Toutes les requêtes vers la base de données sont construites dans le langage Cypher... Afin de ne pas être distrait par sa description maintenant, considérez-le simplement comme «SQL pour les graphes».
3.1.1. Segment RRL. Chemin VlanID
Demande de chiffrement pour tracer le chemin du service en fonction des données de topologie VlanID et L2 disponibles:
| Fragment d'une requête Cypher
(construction WITH - passage des résultats d'une étape de la requête à la suivante (pipelining du traitement)) |
Résultats de la requête intermédiaire (représentation visuelle dans la console Neo4j - « Navigateur Neo4j ») |
|---|---|
Obtention des nœuds BS et MVN entre lesquels le chemin du service Iub sera recherché
|
 |
Réception des nœuds Vlan de l'interface BS Iub
|
 |
Nous sélectionnons les nœuds du véhicule sur le même site que le BS, sur les ports desquels VlanID Iub BS est enregistré
|
 |
en utilisant l'algorithme de Dijkstra, on trouve le chemin le plus court depuis le VlanID du TS du site de la BS jusqu'à la frontière MVN
|
 |
De la chaîne Vlan, nous obtenons une liste de nœuds, de ports et de connexions entre les ports, ce qui, à la fin, sera le moyen de connecter le service Iub de la BS au routeur frontalier
Résultat: |
|
 |
|
Comme vous pouvez le voir, le chemin a été obtenu, même malgré un manque partiel de données. Dans ce cas, il n'y a aucune information sur la jonction du port BS avec le port de la station relais radio.
3.1.2. Segment RRL. Chemin de topologie L2
Disons qu'une tentative est faite dans la clause 3.1.1. échec en raison d'une absence totale ou partielle de données sur le paramètre VlanID. En d'autres termes, une telle chaîne continue atteignant le nœud MVN n'est pas construite:
Ensuite, vous pouvez essayer de définir la connexion de service comme le chemin le plus court vers le MVN selon la topologie L2:
Résultat: |
 |
Comme vous pouvez le voir, le même résultat est obtenu. Ici, le manque d'information sur la jonction de la BS avec le RRS est compensé en passant la connexion à travers l'objet (nœud) du site où ils se trouvent. Bien sûr, la précision de cette méthode sera moindre, car en général, Vlan peut ne pas être enregistré le long du chemin le plus court suggéré par l'algorithme de Dijkstra. Mais la demande consiste en seulement deux opérations.
3.1.3 Segment MVN. Tracer le chemin de la limite MVN au contrôleur
Ici, nous utilisons également l'algorithme de Dijkstra.
Un chemin à un coût minime
|
 |
Top 2 des chemins avec un coût minime (principal + alternative)
|
 |
Top 3 des chemins avec un coût minimal (principal + deux alternatives)
|
 |
De même, dans ce cas, il n'y a aucune information sur les liaisons directes du MVN avec le RNC. Mais cela ne nous empêche pas de construire un chemin de service, même s'il est supposé par l'algorithme (nous en reparlerons plus tard).
3.2. Les coûts de main-d'œuvre
La mise en œuvre du problème direct, illustrée maintenant, est très différente de l'approche «développer un algorithme, un programme, une méthode de stockage et de récupération des résultats» - tout se résume à «écrire une requête dans la base de données». Pour l'avenir, nous notons que l'ensemble du cycle de développement d'un modèle de graphique simple, de chargement de données dans Neo4j à partir d'une base de données relationnelle, d'écriture de requêtes et jusqu'à ce que le résultat soit obtenu, a pris un total d'une journée.
3-4 mois vs 1 jour !!! C'était la dernière raison du départ définitif vers la base de données de graphiques.
Partie 4. Base de données graphique Neo4j et chargement des données
4.1. Comparaison des bases de données relationnelles et graphiques



4.2. Modèle de données
Le modèle de base de la présentation TS jusqu'au niveau de topologie L3 inclus:

Bien sûr, le modèle est plus étendu que celui présenté, et contient également des services MPLS et des interfaces virtuelles, mais pour simplifier, nous en considérerons un fragment limité.
Dans un tel modèle, la relation entre deux éléments de réseau de la même région peut être représentée par:

4.3. Chargement des données
Nous chargeons les données de la base de données des paramètres et de la topologie du véhicule. Pour charger dans Neo4j à partir de la base de données SQL, la bibliothèque APOC est utilisée - apoc.load.jdbc , qui prend en entrée une chaîne de connexion au SGBDR et le texte d'une requête SQL, et renvoie un ensemble de chaînes qui sont mappées à des nœuds, des liens ou des paramètres via des expressions CYHPER. Ces opérations sont effectuées couche par couche pour chaque type d'objet modèle.
Par exemple, une passe pour charger / mettre à jour des nœuds représentant des éléments de réseau (nœuds):
|
Appel de la procédure apoc.load.jdbc,
obtention d'un ensemble de données |
|
Pour chaque ligne de l'ensemble
de données par région et code de site, les nœuds sont recherchés qui représentent les sites correspondants |
|
Pour chaque objet de site, les
éléments de réseau (noeud) associés sont mis à jour . L'instruction MERGE + SET est utilisée, qui met à jour les paramètres de l'objet s'il existe déjà dans la base de données, sinon , il crée l'objet. Les paramètres du nœud Node et ses connexions avec le nœud PL sont également enregistrés. |
Et ainsi de suite - à tous les niveaux du modèle TS.
Le champ Mis à jour permet de contrôler la pertinence des données de la colonne - les objets qui ne sont pas mis à jour pendant plus d'une certaine période sont supprimés.
Partie 5. Résolution du problème inverse dans Neo4j
Au début, l'expression "trace de service" a d'abord fait apparaître les associations suivantes:

Autrement dit, le chemin actuel du service est tracé directement, à un moment donné.
Ce n'est pas exactement ce que nous avons dans une base de données de graphes. Dans le GDB, un service est tracé en fonction des relations d'objets qui déterminent sa configuration dans chaque élément de réseau impliqué. Autrement dit, une configuration est représentée sous la forme d'un modèle de graphe et la trace résultante est un passage sur le modèle représentant cette configuration.
Comme, contrairement au segment commuté, les routes de service réelles dans le segment mpls sont déterminées par des protocoles dynamiques, nous avons dû accepter certains ...
5.1. Hypothèses pour les segments acheminés
Parce que à partir des données de configuration des services mpls, il n'est pas possible de déterminer leur chemin exact à travers les segments contrôlés par des protocoles de routage dynamique (surtout si Traffic Engineering est utilisé) - pour la solution, l'algorithme de Dijkstra est utilisé.
Oui, il existe des systèmes de gestion qui peuvent fournir le chemin réel des LSP de service via l'interface NBI, mais jusqu'à présent, nous n'avons qu'un seul fournisseur de ce type, et il y a plus d'un fournisseur dans le segment MVN.
Oui, il existe des systèmes d'analyse des protocoles de routage au sein de l'AS, qui, à l'écoute de l'échange de protocoles IGP, peuvent déterminer l'itinéraire actuel du préfixe d'intérêt. Mais il existe de tels systèmes - comme le Boeing abattu, et étant donné qu'un tel système doit être déployé sur tous les AS du même backhole mobile - le coût de la solution, ainsi que toutes les licences, sera le coût d'un Boeing abattu par un pont en fonte lié à la fusée Angara lorsqu'il est entièrement ravitaillé. Et ceci malgré le fait que de tels systèmes ne résolvent pas complètement le problème de la comptabilisation des routes à travers plusieurs AS utilisant BGP.
Par conséquent - jusqu'à présent. Bien sûr, nous avons ajouté plusieurs accessoires aux conditions de l'algorithme standard de Dijkstra:
- Comptabilisation de l'état des interfaces / ports. Le lien déconnecté augmente de coût et va à la fin des options de chemin possibles.
- Prise en compte de l'état du lien de sauvegarde. Selon le système de surveillance des performances, la présence de trafic keepalive uniquement dans le canal mpls est calculée, respectivement, le coût d'un tel canal augmente également.
5.2. Comment résoudre le problème inverse dans Neo4j
Rappel. La tâche inverse consiste à obtenir une liste de services qui dépendent d'un canal ou d'un nœud spécifique du réseau de transport (TS).
5.2.1. Segment L2 commuté
Pour le segment commuté, où le chemin de service et la configuration de service sont pratiquement les mêmes, le problème peut encore être résolu par des requêtes CYPHER. Par exemple, pour un vol de relais radio à partir des résultats de la résolution du problème Direct dans la clause 3.1.1., Nous allons faire une demande du modem de liaison de relais radio - «étendre» toutes les chaînes Vlan qui le traversent:
match (tn:node {name:'RRN_29_XXXX_1'})-->(tn_port:port {name:'Modem-1'})-->(tn_vlan:vlan)
with tn, tn_vlan, tn_port
call apoc.path.spanningTree(tn_vlan,{relationshipFilter:"ptp_vlan>|v_ptp_vlan>", maxLevel:20}) yield path as pp
with tn_vlan,pp,nodes(pp)[-1] as last_node, tn_port
match (last_node)-[:vlan]->(:port)-->(n:node)
return pp, n, tn_portLe nœud rouge indique le modem dont nous déployons le Vlan. 3 BS ont été encerclés sur lesquels, en conséquence, le déploiement du transit Vlan avec Modem1 a conduit.

Cette approche pose plusieurs problèmes:
- Le Vlan configuré doit être connu pour les ports et chargé dans le modèle.
- En raison d'une possible fragmentation, la chaîne Vlan ne sort pas toujours vers le nœud terminal
- Il est impossible de déterminer si le dernier nœud de la chaîne Vlan appartient à un nœud terminal ou si le service continue réellement.
Autrement dit, il est toujours plus pratique de tracer un service entre les nœuds d'extrémité / points de son segment, plutôt qu'à partir d'un «milieu» arbitraire et d'une couche OSI.
5.2.2. Segment acheminé
Avec un segment acheminé, comme déjà décrit dans la clause 5.1, il n'est pas nécessaire de choisir - il n'y a aucun moyen de résoudre le problème inverse basé sur les données de la configuration actuelle d'une liaison MPLS intermédiaire - la configuration ne définit pas explicitement la trace de service.
5.3. Décision
La décision a été prise comme suit.
- Le chargement complet du modèle de véhicule est effectué, y compris les BS et les contrôleurs
- Pour toutes les BS, le problème direct est résolu - traçage des services Iub, S1 de la BS au MVN frontière, puis du MVN frontière aux contrôleurs ou passerelles correspondants.
- Les résultats de la trace sont écrits dans une base de données SQL standard au format: nom BS - un tableau d'éléments de chemin de service
Par conséquent, lors de l'accès à la base de données avec la condition Node TS ou Node TS + Port, une liste de services (BS) est renvoyée, dont le tableau de chemins contient le Node ou Node + Port requis.

Partie 6. Résultats et conclusions
6.1. résultats
En conséquence, le système fonctionne comme suit:

Pour le moment, pour résoudre le problème direct, c'est-à-dire Lors de l'analyse des causes de la dégradation des services individuels, une application Web a été développée qui montre le résultat de la trace (chemin) de Neo4j, avec des données superposées sur la qualité et les performances des sections individuelles du chemin.

Pour obtenir une liste de services qui dépendent des nœuds ou des canaux du TS (résolution du problème inverse), une API pour les systèmes externes (en particulier, Remedy) a été développée.
6.2. conclusions
- Les deux solutions ont porté l'automatisation de l'analyse de la qualité des services et du réseau de transport à un niveau qualitativement nouveau.
- De plus, en présence de données toutes faites sur les itinéraires des services BS, il est devenu possible de fournir rapidement des données aux business units sur la possibilité technique d'inclure des clients B2B sur des sites spécifiques - en termes de capacité et de qualité de l'itinéraire.
- Neo4j s'est avéré être un outil très puissant pour résoudre les problèmes de graphe de réseau. La solution est bien documentée , bénéficie d'un large support dans diverses communautés de développeurs et est constamment développée et améliorée.
6.3. Des plans
Nous avons des plans:
- expansion des segments technologiques modélisés dans la base de données Neo4j
- développement et mise en œuvre d'algorithmes de traçage pour les services haut débit
- augmentation des performances de la plate-forme serveur
Merci de votre attention!