- Bonsoir, je m'appelle Masha, je travaille dans le département d'analyse des données d'Eddila, et aujourd'hui nous avons une conférence sur les tests avec vous.

Tout d'abord, nous discuterons avec vous des types de tests en général, et j'essaierai de vous convaincre pourquoi vous devez écrire des tests. Ensuite, nous parlerons de ce que nous avons en Python pour travailler directement avec les tests, avec leurs modules d'écriture et auxiliaires. À la fin, je vais vous parler un peu de CI - une partie inévitable de la vie dans une grande entreprise.
Je voudrais commencer par un exemple. Je vais essayer d'expliquer avec des exemples très effrayants pourquoi il vaut la peine d'écrire des tests.
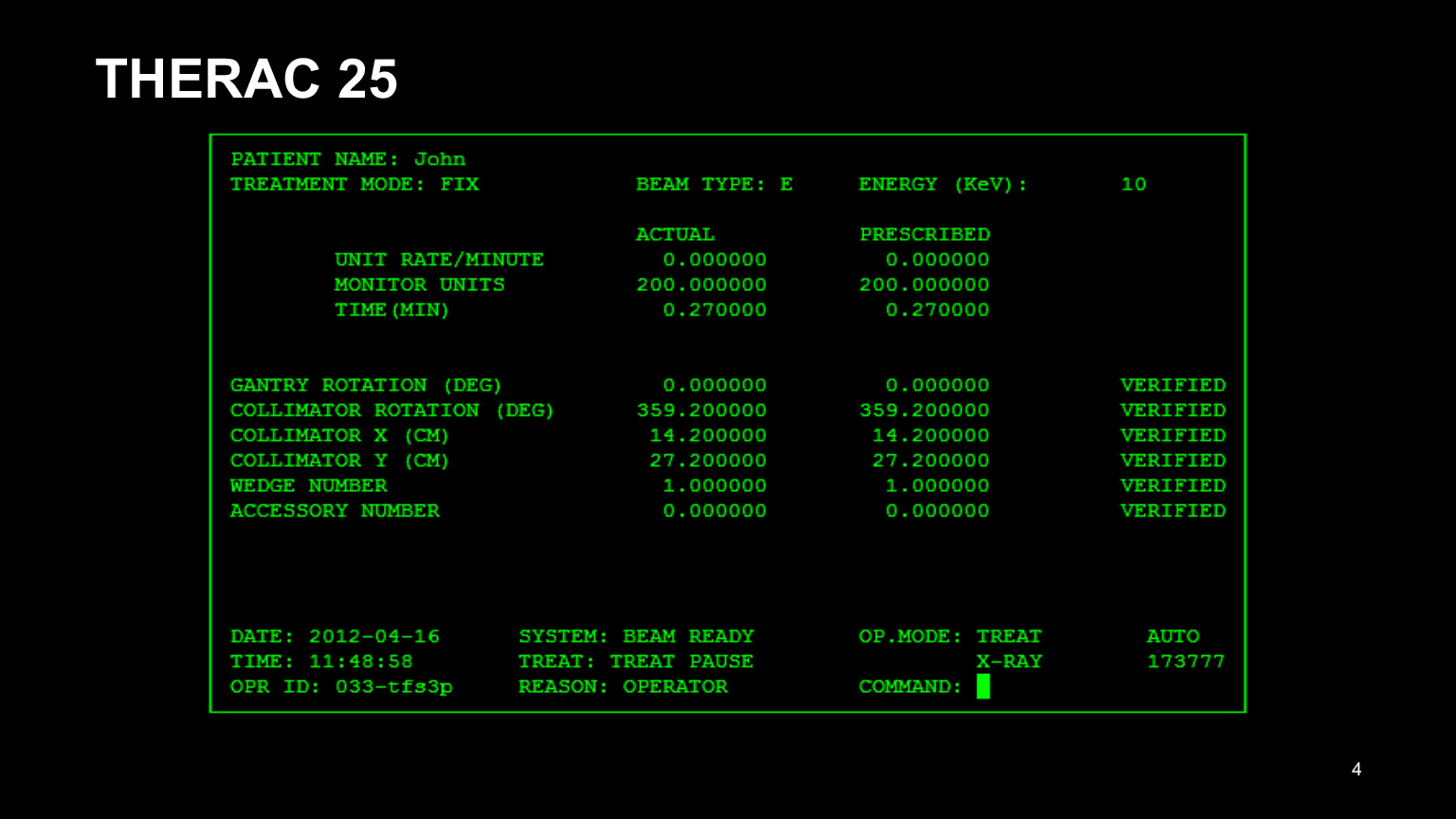
Voici l'interface du programme THERAC 25. C'était le nom de l'appareil de radiothérapie des patients cancéreux, et tout s'est très mal passé avec. Tout d'abord, il avait une mauvaise interface. En le regardant, on peut déjà comprendre qu'il n'est pas très bon: il n'était pas pratique pour les médecins de conduire dans tous ces nombres. En conséquence, ils ont copié les données du dossier du patient précédent et ont essayé de ne modifier que ce qui devait être modifié.
Il est clair qu'ils ont oublié de corriger la moitié d'entre eux et se sont trompés. En conséquence, les patients n'étaient pas traités correctement. L'interface utilisateur vaut également la peine d'être testée, il n'y a jamais trop de tests.
Mais en plus de la mauvaise interface, il y avait beaucoup plus de problèmes dans le backend. J'en ai identifié deux qui me paraissaient les plus flagrantes:
- . , . , . , .
- C . THERAC , — , . . , , , - , - — .
Cela vaudrait la peine d'écrire des tests. Parce que cela a abouti à cinq décès enregistrés, et on ne sait pas combien de personnes supplémentaires ont souffert d'avoir reçu trop de médicaments.

Il y a un autre exemple que dans certaines situations, l'écriture de tests peut vous faire économiser beaucoup d'argent. Il s'agit du Mars Climate Orbiter - un appareil qui était censé mesurer l'atmosphère dans l'atmosphère de Mars, pour voir ce qui s'y passait avec le climat.
Mais le module, qui était au sol, donnait des commandes dans le système SI, dans le système métrique. Et le module sur l'orbite de Mars pensait qu'il s'agissait d'un système de mesures britannique, l'a mal interprété.
En conséquence, le module est entré dans l'atmosphère au mauvais angle et s'est effondré. 125 millions de dollars viennent de tomber à la poubelle, même s'il semblerait qu'il soit possible de simuler la situation sur des tests et d'éviter cela. Mais ça n'a pas marché.
Je vais maintenant parler de raisons plus prosaïques pour lesquelles vous devriez écrire des tests. Parlons de chaque élément séparément:
- Les tests s'assurent que le code fonctionne et ils vous calment un peu. Dans les cas pour lesquels vous avez écrit des tests, vous pouvez être sûr que le code fonctionne - si, bien sûr, vous l'avez bien écrit. Mieux dormir. Il est très important.
- . . , , , . , . , .
, - , — , - . , . , , . , , , git blame, , , , . - . , . , . , , . - - , - - . , , , . - .
- , . ? , , , , : , . 500 -, . . .
- : — . , , . , , .
, , , . , , . - . — , . , , . , .
: - . , , . , , , - , .
Je voudrais maintenant parler un peu des classifications des types de tests. Il y en a beaucoup. Je n'en mentionnerai que quelques-uns.
Le processus de test est divisé en tests boîte noire, tests blancs et gris.
Le test de la boîte noire est un processus lorsque le testeur ne sait rien de ce qu'il contient. Il, comme un utilisateur ordinaire, fait quelque chose sans connaître les détails d'implémentation.
Le test en boîte blanche signifie que le testeur a accès à toutes les informations dont il a besoin, y compris le code source. Nous sommes dans une telle situation lorsque nous écrivons un test sur notre propre code.
Le test de la boîte grise est quelque chose entre les deux. C'est à ce moment que vous connaissez certains détails d'implémentation, mais pas le tout.
En outre, le processus de test peut être divisé en manuel, semi-automatique et automatique. Les tests manuels sont effectués par une personne. Disons qu'il clique sur des boutons dans le navigateur, clique quelque part, regarde pour voir ce qui est cassé ou non cassé. Le test semi-automatisé est lorsqu'un testeur exécute des scripts de test. Nous pouvons dire que nous sommes dans une telle situation lorsque nous exécutons et exécutons nos tests localement. Les tests automatisés n'impliquent pas de participation humaine: les tests doivent être exécutés automatiquement et non manuellement.
De plus, les tests peuvent être divisés par niveau de détail. Ici, ils sont généralement divisés en tests unitaires et d'intégration. Il peut y avoir des divergences. Il y a des gens qui appellent des tests unitaires d'autotests. Mais une division plus classique est quelque chose comme ça.
Les tests unitaires vérifient le fonctionnement des composants individuels du système et les tests d'intégration vérifient l'ensemble de certains modules. Parfois, il existe également des tests système qui vérifient le fonctionnement de l'ensemble du système dans son ensemble. Mais il semble que ce soit plus une grande variante des tests d'intégration.
Les tests de notre code sont des tests unitaires et d'intégration. Il y a des gens qui pensent que seuls les tests d'intégration devraient être écrits. Je ne suis pas de ceux-là, je pense que tout doit être modéré, et les deux tests unitaires, lorsque vous testez un composant, et les tests d'intégration, lorsque vous testez quelque chose de gros, sont utiles.
Pourquoi est-ce que je pense? Parce que les tests unitaires sont généralement plus rapides. Lorsque vous avez besoin de modifier quelque chose, vous serez très ennuyé d'avoir cliqué sur le bouton "exécuter le test", puis attendez trois minutes que la base de données démarre, les migrations sont effectuées, autre chose se produit. Dans de tels cas, les tests unitaires sont utiles. Ils peuvent être exécutés rapidement et facilement, un à la fois. Mais une fois que vous avez corrigé les tests unitaires, très bien, corrigeons les tests d'intégration.
Les tests d'intégration sont également une chose très nécessaire, un gros avantage est qu'ils concernent davantage le système. Un autre gros avantage: ils sont plus résistants au refactoring de code. Si vous êtes plus susceptible de réécrire une petite fonction, il est peu probable que vous changiez le pipeline global avec la même fréquence.

Il existe de nombreuses autres classifications différentes. Je reviendrai rapidement sur ce que j'ai écrit ici, mais je ne m'attarderai pas dans les détails, ce sont des mots que vous pouvez entendre ailleurs.
Les tests de fumée sont des tests de fonctionnalité critique, les premiers et les plus simples tests. S'ils se cassent, vous n'avez plus besoin de tester, mais vous devez aller les réparer. Disons que l'application a démarré, n'a pas planté - super, le test de fumée a réussi.
Il existe des tests de régression - des tests d'anciennes fonctionnalités. Disons que vous lancez une nouvelle version et que vous devez vérifier que rien n'a été cassé dans l'ancienne. C'est la tâche des tests de régression.
Il existe des tests de compatibilité, des tests d'installation. Ils vérifient que tout fonctionne correctement pour vous dans différents systèmes d'exploitation et différentes versions de système d'exploitation, dans différents navigateurs et différentes versions de navigateurs.
Les tests d'acceptation sont des tests d'acceptation. J'en ai déjà parlé, ils se demandent si votre changement peut être mis en production ou non.
Il existe également des tests alpha et bêta. Ces deux concepts sont davantage liés au produit. Habituellement, lorsque vous avez une version plus ou moins prête d'une version, mais que tout n'y est pas corrigé, vous pouvez la donner soit à des personnes externes conditionnelles, soit à des personnes externes, des bénévoles, afin qu'elles trouvent des bogues pour vous, les signalent et vous pouvez publier une très bonne version. Moins la version alpha est terminée, plus la version bêta est terminée. Dans les tests bêta, presque tout devrait bien se passer maintenant.
Ensuite, il y a les tests de performance et de stress, les tests de charge. Ils vérifient, par exemple, comment votre application gère la charge. Il y a du code. Vous avez calculé combien d'utilisateurs, de demandes il aura, quel RPS, combien de demandes arriveront par seconde. Nous avons simulé cette situation, l'avons lancée, regardé - elle tient, ne tient pas. Si cela ne tient pas, réfléchissez à la marche à suivre. Peut-être pour optimiser le code ou augmenter la quantité de matériel, il existe différentes solutions.
Les tests de résistance sont à peu près les mêmes, seule la charge est plus élevée que prévu. Si les tests de performance donnent le niveau de charge attendu, dans les tests de résistance, vous pouvez augmenter la charge jusqu'à ce qu'elle se brise.
Les linters sont séparés ici. Je vous parlerai des linters un peu plus tard, ce sont des tests de formatage de code, un guide de style. En Python, nous avons la chance d'avoir PEP8, un guide de style simple que tout le monde devrait suivre. Et lorsque vous écrivez quelque chose, vous avez généralement du mal à suivre le code. Supposons que vous ayez oublié de mettre une ligne vide, que vous ayez créé une ligne supplémentaire ou que vous ayez laissé une ligne trop longue. Cela vous gêne, car vous vous habituez au fait que votre code est écrit dans le même style. Les linters vous permettent d'attraper automatiquement de telles choses.
Avec la théorie, tout, alors je parlerai de ce qui est en Python.

Voici une liste de quelques bibliothèques. Je n'entrerai pas dans les détails sur chacun d'eux, mais je parlerai de la plupart d'entre eux. Bien sûr, nous parlerons d'unittest et d'un pytest. Ce sont des bibliothèques qui sont utilisées directement pour écrire des tests. Mock est une bibliothèque d'aide pour créer des objets simulés. Nous parlerons également d'elle. doctest est un module pour tester la documentation, flake8 est un linter, nous les examinerons également. Je ne parlerai pas de pylama et de tox. Si vous êtes intéressé, vous pouvez voir par vous-même. Pylama est aussi un linter, voire un metalinter, il combine plusieurs packages, très pratique et bon. Et la bibliothèque tox est nécessaire si vous devez tester votre code dans différents environnements - par exemple, avec différentes versions de Python ou avec différentes versions de bibliothèques. Tox aide beaucoup dans ce sens.
Mais avant de parler de différentes bibliothèques, je commencerai par la banalité. N'hésitez pas à utiliser assert dans votre code. Ce n'est pas une honte. Cela aide souvent à comprendre ce qui se passe.

Supposons qu'il y ait une fonction qui calcule des statistiques ordinales, deux assertions y sont écrites. Assert doit être écrit dans une fonction dans les cas où il s'agit d'un non-sens complètement extrême qui ne devrait pas être dans le code. Ce sont des cas très extrêmes, très probablement, vous ne les rencontrerez même pas en production. Autrement dit, si vous vous trompez dans le code, il échouera probablement dans vos tests.
Assert aide lorsque vous prototypez, vous n'avez pas encore de code de production, vous pouvez coller assert partout - dans la fonction appelée, n'importe où. Ce n'est pas bon pour les projets sérieux, mais plutôt bon au stade du prototypage.
Supposons que vous souhaitiez désactiver l'assertion pour une raison quelconque - par exemple, vous souhaitez qu'elle ne se déclenche jamais en production. Python a une option spéciale pour cela.

Je vais vous dire ce qu'est le doctest. Ceci est un module, une bibliothèque standard Python pour tester la documentation. Pourquoi est-il bon? La documentation écrite dans le code a tendance à se casser très souvent. Il y a une toute petite fonction jouet ici, vous pouvez tout voir. Mais quand vous avez un code volumineux, beaucoup de paramètres, et que vous avez ajouté quelque chose à la fin, alors avec une probabilité très élevée, vous oublierez de corriger les docstrings. Doctest évite ces choses. Vous corrigez quelque chose, ne mettez pas à jour ici, exécutez doctest, et il plantera pour vous. Ainsi, vous vous souviendrez exactement de ce que vous n'avez pas corrigé, allez-y et corrigez.
À quoi cela ressemble-t-il? Doctest recherche ces sapins de Noël dans des docstrings, puis les exécute et compare ce qui est obtenu.

Voici un exemple d'exécution de doctest. Nous l'avons commencé, nous voyons que nous avons deux tests et l'un d'eux est tombé - complètement sur le cas. Super, nous avons vu de bonnes informations claires sur l'erreur.

Lien de la diapositive
Le doctest a quelques directives utiles qui pourraient être utiles. Je ne parlerai pas de tous, mais de certains qui me semblaient les plus courants, j'ai mis sur la diapositive. La directive SKIP vous permet de ne pas exécuter de test sur un exemple marqué. La directive IGNORE_EXCEPTION_DETAIL ignore le test EXCEPTION. ELLIPSIS vous permet d'écrire des points de suspension au lieu de n'importe où dans la sortie. FAIL_FAST s'arrête après le premier test ayant échoué. Tout le reste peut être lu dans la documentation, il y en a beaucoup. Je ferais mieux de vous montrer un exemple.

Cet exemple a une directive ELLIPSIS et une directive IGNORE_EXCEPTION_DETAIL. Vous voyez les statistiques du K-ème ordinal dans la directive ELLIPSIS, et nous nous attendons à ce que quelque chose arrive qui commence par un neuf et se termine par un neuf. Il pourrait y avoir quelque chose au milieu. Un tel test n'échouera pas.
Ci-dessous se trouve la directive IGNORE_EXCEPTION_DETAIL, elle ne vérifiera que ce qui est venu dans l'AssertionError. Voyez, nous avons écrit bla bla bla là. Le test passera, il ne comparera pas bla bla bla avec l'itérable attendu comme premier argument. Il comparera uniquement AssertionError à AssertionError. Ce sont des choses utiles que vous pouvez utiliser.

Alors le plan est le suivant: je vais vous parler de unittest, puis de pytest. Je dirai tout de suite que je ne connais probablement pas les avantages d'unittest, à part qu'il fait partie de la bibliothèque standard. Je ne vois pas de situation qui me forcerait à utiliser unittest maintenant. Mais il y a des projets qui l'utilisent, en tout cas il est utile de savoir à quoi ressemble la syntaxe et de quoi il s'agit.
Autre point: les tests écrits en unittest savent comment exécuter pytest dès la sortie de la boîte. Il ne se soucie pas. (…)
Unittest ressemble à ceci. Il y a une classe commençant par le mot test. A l'intérieur, une fonction commençant par le mot test. La classe de test hérite de unittest.TestCase. Je dois dire tout de suite qu'un test ici est écrit correctement, et l'autre test est incorrect.
Le test supérieur, où l'assertion normale est écrite, échouera, mais il aura l'air étrange. Jetons un coup d'oeil.

Commande de démarrage. Vous pouvez écrire unittest main dans le code lui-même, vous pouvez l'appeler depuis Python.

Nous avons exécuté ce test et nous voyons qu'il a écrit une AssertionError, mais il n'a pas écrit où il est tombé - contrairement au test suivant, qui utilisait self.assertEqual. C'est clairement écrit ici: trois n'est pas égal à deux.

Il doit être réparé, bien sûr. Mais alors cette sortie magique n'était pas visible à l'écran.
Jetons un autre regard. Dans le premier cas, nous avons écrit assert, dans le second, self.assertEqual. Malheureusement, c'est le seul moyen d'unittest. Il existe des fonctions spéciales - self.assertEqual, self.assertnotEqual et 100 500 fonctions supplémentaires que vous devez utiliser si vous voulez voir un message d'erreur adéquat.
Pourquoi ça arrive? Parce que assert est une instruction qui reçoit un bool et éventuellement une chaîne, mais dans ce cas bool. Et il voit qu'il a vrai ou faux, et il n'a nulle part où prendre les côtés gauche et droit. Par conséquent, unittest a des fonctions spéciales qui afficheront correctement les messages d'erreur.
Ce n'est pas très pratique à mon avis. Plus précisément, ce n'est pas du tout pratique, car ce sont des méthodes spéciales qui ne sont que dans cette bibliothèque. Ils sont différents de ce à quoi nous sommes habitués dans le langage ordinaire.

Vous n'avez pas à vous en souvenir - nous parlerons de pytest plus tard, et j'espère que vous y écrirez principalement. Unittest a un zoo de fonctions à utiliser si vous voulez tester quelque chose et obtenir de bons messages d'erreur.
Ensuite, parlons de la façon d'écrire des fixtures en unittest. Mais pour ce faire, je dois d'abord vous dire quels sont les appareils. Ce sont des fonctions appelées avant ou après l'exécution du test. Ils sont nécessaires si le test doit effectuer un réglage spécial - créer un fichier temporaire après le test, supprimer le fichier temporaire; créer une base de données, supprimer une base de données; créer une base de données, y écrire quelque chose. En général, peu importe. Voyons à quoi cela ressemble en unittest.

Unittest a des méthodes spéciales setUp et tearDown pour écrire un fixture. Pourquoi ils ne sont toujours pas écrits selon PEP8 est un grand mystère pour moi. (...)
SetUp est ce qui est fait avant le test, tearDown est ce qui est fait après le test. Il me semble que c'est une conception extrêmement gênante. Pourquoi? Car, premièrement, ma main ne se lève pas pour écrire ces noms: je vis déjà dans un monde où il y a encore PEP8. Deuxièmement, vous avez un fichier temporaire dont vous n'avez rien dans les arguments du test lui-même. D'où est-ce qu'il venait? On ne sait pas très bien pourquoi il existe et de quoi il s'agit.
Quand on a une petite classe qui s'accroche à l'écran, c'est cool, ça peut être capturé avec un regard. Et quand vous avez cette énorme feuille, vous êtes torturé pour chercher ce que c'était et pourquoi il est comme ça, pourquoi il se comporte comme ça.
Il existe une autre fonctionnalité pas si pratique avec les luminaires en unittest. Supposons que nous ayons une classe de test qui a besoin d'un fichier temporaire et une autre classe de test qui a besoin d'une base de données. Excellent. Vous avez écrit une classe, fait setUp, tearDown, créé / supprimé un fichier temporaire. Nous avons écrit une autre classe, dans laquelle nous avons également écrit setUp, tearDown, créé / supprimé une base de données.
Question. Il existe un troisième groupe de tests qui nécessitent les deux. Que faire de tout ça? Je vois deux options. Ou prenez et copiez-collez le code, mais ce n'est pas très pratique. Ou créez une nouvelle classe, héritez-la des deux précédentes, appelez super. En général, cela fonctionnera aussi, mais cela ressemble à une exagération sauvage pour les tests.

Par conséquent, je veux que votre familiarité avec unittest reste ainsi, sur le plan théorique. Ensuite, nous parlerons d'un moyen plus pratique d'écrire des tests, d'une bibliothèque plus pratique, c'est pytest.
Tout d'abord, je vais essayer de vous dire pourquoi pytest est pratique.

Lien de la diapositive
Premier point: dans pytest, les assertions fonctionnent généralement, celles auxquelles vous êtes habitué, et elles donnent des informations d'erreur normales. Deuxièmement: il existe une bonne documentation pour pytest, où un tas d'exemples sont démontés, et tout ce que vous voulez, tout ce que vous ne comprenez pas peut être visualisé.
Troisièmement, les tests ne sont que des fonctions qui commencent par test_. Autrement dit, vous n'avez pas besoin d'une classe supplémentaire, vous écrivez simplement une fonction régulière, appelez-la test_ et elle sera exécutée via pytest. C'est pratique car plus il est facile d'écrire des tests, plus vous avez de chances d'écrire le test plutôt que de le noter.
Pytest a un tas de fonctionnalités pratiques. Vous pouvez écrire des tests paramétrés, il est pratique d'écrire des fixtures de différents niveaux, il y a aussi quelques subtilités que vous pouvez utiliser: xfail, raises, skip, et quelques autres. Il existe de nombreux plugins dans pytest, en plus vous pouvez écrire le vôtre.

Voyons un exemple. Voici à quoi ressemblent les tests écrits dans pytest. Le sens est le même que sur unittest, mais il semble beaucoup plus concis. Le premier test est généralement de deux lignes.

Exécutez la commande python -m pytest. Excellent. Deux tests réussis, tout va bien, nous pouvons voir ce qu'ils ont réussi et à quelle heure.

Maintenant, interrompons un test et faisons en sorte que nous ayons des informations sur l'erreur. Affiche l'assertion 3 == 2 et l'erreur. Autrement dit, nous voyons: malgré le fait que nous ayons écrit une assertion régulière, nous avons correctement affiché les informations sur l'erreur, bien qu'avant cela, dans unittest, nous disions que l'assert accepte un bool dans une chaîne ou un bool, il est donc problématique d'afficher des informations sur l'erreur.
On pourrait se demander pourquoi tout cela fonctionne? Parce que pytest a fait de son mieux et a nettoyé la partie laide de l'interface. Pytest analyse d'abord votre code, et il apparaît comme une sorte de structure arborescente, un arbre syntaxique abstrait. Dans cette structure, vous avez des opérateurs aux sommets et des opérandes aux feuilles. Assert est un opérateur. Il se trouve au sommet de l'arbre, et à ce moment, avant de tout donner à l'interprète, vous pouvez remplacer cette affirmation par une fonction interne qui fait de l'introspection et comprend ce qui se trouve dans vos côtés gauche et droit. En fait, cela est déjà transmis à l'interprète, avec assert remplacé.
Je n'entrerai pas dans les détails, il y a un lien, dessus, vous pouvez lire comment ils l'ont fait. Mais j'aime que tout fonctionne sous le capot. l'utilisateur ne voit pas cela. Il écrit affirmer, comme il en a l'habitude, que la bibliothèque elle-même fait le reste. Vous n'avez même pas à y penser.
Plus loin dans pytest pour les types standard, vous aurez quand même de bonnes informations d'erreur. Parce que pytest sait comment afficher ces informations d'erreur. Mais vous pouvez comparer des types de données personnalisés dans votre test, par exemple des arbres ou quelque chose de complexe, et pytest peut ne pas savoir comment afficher les informations d'erreur pour eux. Dans de tels cas, vous pouvez ajouter un hook spécial - voici une section dans la documentation - et dans ce hook écrivez à quoi devraient ressembler les informations d'erreur. Tout est très flexible et pratique.

Voyons à quoi ressemblent les appareils dans pytest. Si dans unittest il est nécessaire d'écrire setUp et tearDown, alors appelez ici la fonction habituelle comme vous le souhaitez. Nous avons écrit le décorateur pytest.fixture sur le dessus - super, c'est un luminaire.
Et ce n'est pas l'exemple le plus simple. L'appareil peut simplement faire un retour, renvoyer quelque chose, ce sera analogue à setUp. Dans ce cas, il fera une sorte de tearDown, c'est-à-dire qu'après la fin du test, il appellera close et le fichier temporaire sera supprimé.
Cela semble pratique. Vous avez une fonction arbitraire que vous pouvez nommer ce que vous voulez. Vous le passez explicitement au test. Passé dans Filled_file, vous savez ce que c'est. Rien de spécial ne vous est demandé. En général, utilisez-le. C'est beaucoup plus pratique qu'unittest.

Un peu plus sur les luminaires. Dans Pytest, il est très facile de créer des luminaires de différentes portées. Par défaut, l'appareil est créé avec le niveau de fonction. Cela signifie qu'il sera appelé pour chaque test auquel vous l'avez passé. Autrement dit, s'il y a un rendement ou quelque chose comme tearDown, cela se produira également après chaque test.
Vous pouvez déclarer scope = 'module' et ensuite le fixture sera exécuté une fois par module. Supposons que vous souhaitiez créer une base de données une fois et que vous ne souhaitiez pas supprimer et lancer toutes les migrations après chaque test.
Aussi dans les fixtures, il est possible de spécifier l'argument autouse = True, puis le fixture sera appelé indépendamment du fait que vous l'ayez demandé ou non. Il semble que cette option ne devrait jamais être utilisée, ou devrait l'être, mais très prudemment, car c'est une chose implicite. Il vaut mieux éviter l'implicite.

Nous avons exécuté ce code - voyons ce qui s'est passé. Il y a un test qui dépend de l'appareil appelez-moi une fois que vous en avez besoin, appelez-moi à chaque fois. Dans le même temps, appelez-moi une fois que vous utilisez un appareil au niveau du module. Nous voyons que la première fois que nous avons appelé les luminaires, appelez-moi une fois que vous en avez besoin, appelez-moi à chaque fois, ce qui génère ceci, mais le projecteur avec autouse a également été appelé, car cela ne fait rien, il est toujours appelé.
Le deuxième test dépend des mêmes appareils. Nous voyons que la deuxième fois que nous m'appelons une fois, l'utilisation en cas de besoin n'était pas imprimée, car elle est au niveau du module, elle a déjà été appelée une fois et elle ne sera plus appelée.
De plus, à partir de cet exemple, vous pouvez voir que pytest n'a pas les problèmes dont nous avons parlé en unittest, alors que dans un test, vous pouvez avoir besoin d'une base de données, dans un autre - un fichier temporaire. Comment les agréger normalement n'est pas clair. Voici la réponse à cette question dans pytest. Si deux appareils sont passés, il y aura deux appareils à l'intérieur.
Excellent, très confortable, pas de problème. Les luminaires sont très flexibles et peuvent dépendre d'autres luminaires. Il n'y a pas de contradiction à cela, et Pytest lui-même les appellera dans le bon ordre.

En fait, à l'intérieur, vous pouvez hériter des appareils d'autres appareils, les rendre différents dans leur portée et les utiliser automatiquement sans autouse. Il les organisera lui-même dans le bon ordre et les appellera.
Ici, nous avons le premier test, un test, qui dépend de rare_dependency_for_test_one, où cet appareil dépend d'un autre appareil - et un de plus. Voyons ce qui se passe dans l'échappement.
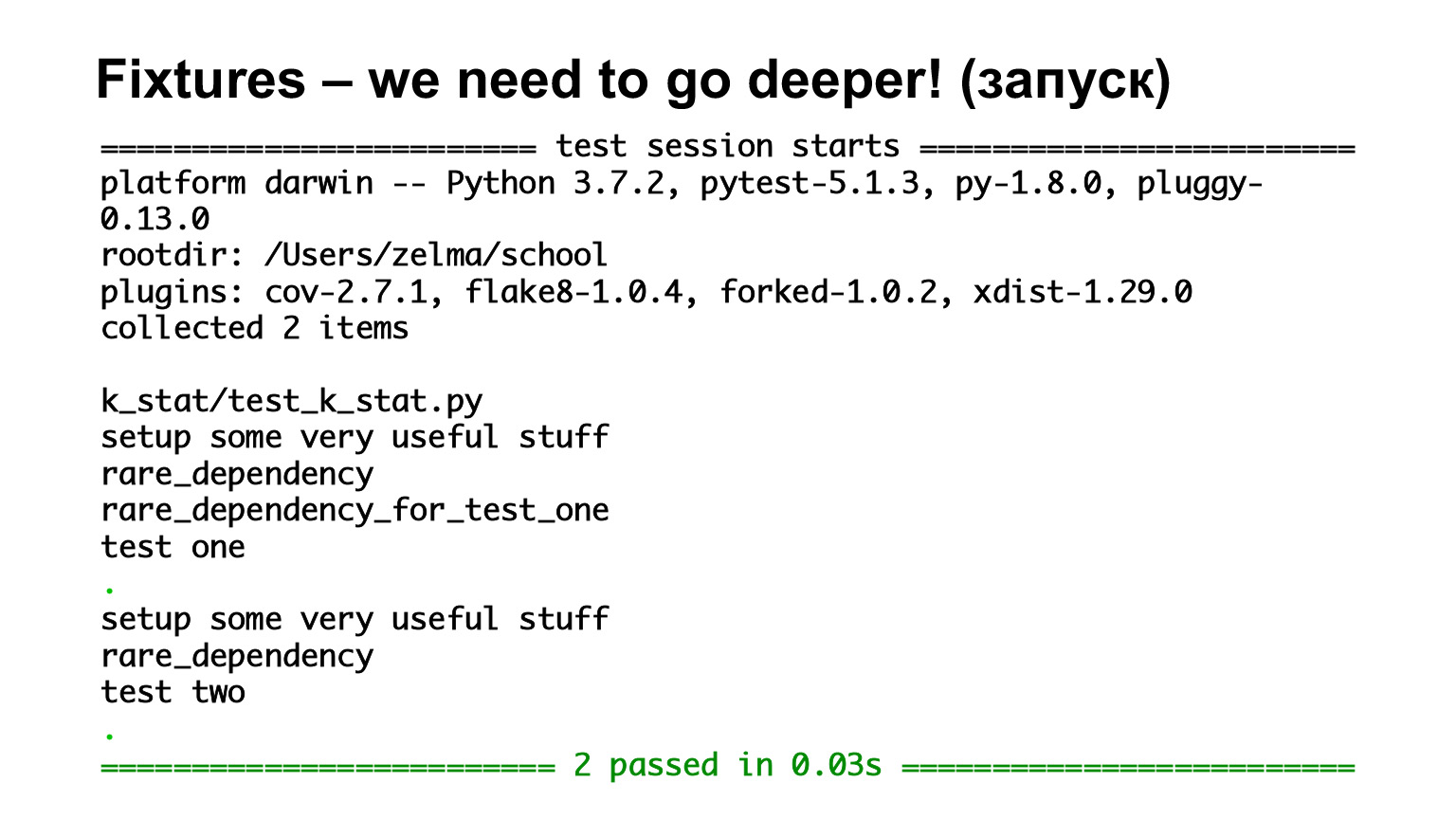
Nous avons vu qu'ils sont appelés par ordre d'héritage. Il existe tous les appareils de niveau fonction, ils sont donc tous appelés pour chaque test. Le deuxième test dépend de rare_dependency et rare_dependency dépend de some_common_dependency. Nous regardons l'échappement et voyons que deux appareils ont été appelés avant le test.
Pytest a un fichier de configuration spécial conftest.py où vous pouvez mettre tous les appareils, et c'est bien si vous le mettez: généralement, quand une personne regarde le code de quelqu'un d'autre, il va généralement regarder les appareils dans conftest.
Ce n'est pas obligatoire. S'il y a un appareil dont vous n'avez besoin que dans ce fichier et que vous savez avec certitude qu'il est spécifique, étroitement applicable et que vous n'en aurez pas besoin dans un autre fichier, vous pouvez le déclarer dans le fichier. Ou créez beaucoup de conftest et ils fonctionneront tous à différents niveaux.

Parlons des fonctionnalités de pytest. Comme je l'ai dit, il est très facile de paramétrer les tests. Ici, nous voyons un test qui a trois ensembles de paramètres: deux entrées et un qui est attendu. Nous les passons aux arguments de la fonction et voyons si ce que nous avons passé à l'entrée correspond à ce qui est attendu.

Voyons à quoi ça ressemble. On voit qu'il y a trois tests. Autrement dit, Pytest pense que ce sont trois tests. Deux sont passés, un est tombé. Qu'est-ce qui est bon ici? Pour le test qui est tombé, nous voyons les arguments, nous voyons sur quel ensemble de paramètres il est tombé.
Encore une fois, lorsque vous avez une petite fonction et que le paramètre dit trois, vous pouvez voir avec vos yeux ce qui est exactement tombé. Mais quand il y a beaucoup de jeux dans les paramètres, vous ne le verrez pas avec vos yeux. Plutôt, vous verrez, mais ce sera très difficile pour vous. Et il est très pratique que pytest affiche tout de cette manière - vous pouvez immédiatement voir dans quel cas le test a échoué.

Paramétrer est une bonne chose. Et lorsque vous avez écrit un test une fois, puis effectuez de très nombreux ensembles de paramètres, c'est une bonne pratique. Ne créez pas beaucoup de variantes de code pour des tests similaires, mais écrivez un test une fois, puis créez un grand ensemble de paramètres, et cela fonctionnera.
Il y a beaucoup plus de choses utiles dans pytest. Si vous en parlez, la conférence n'est manifestement pas suffisante, je n'en montrerai donc, encore une fois, que quelques-uns. Le premier test utilise pytest.raises () pour montrer que vous attendez une exception. Autrement dit, dans ce cas, si une AssertionError est déclenchée, le test passera. Vous devriez avoir une exception levée.
La deuxième chose pratique est xfail. C'est un décorateur qui permet au test d'échouer. Disons que vous avez beaucoup de tests, beaucoup de code. Vous avez remanié quelque chose, le test a commencé à échouer. En même temps, vous comprenez que soit ce n'est pas critique, soit il vous en coûtera très cher de le réparer. Et vous êtes comme ça: d'accord, je vais accrocher un décorateur dessus, il deviendra vert, je le réparerai plus tard. Ou supposons que le test commence à se répandre. Il est clair qu'il s'agit d'un accord avec sa propre conscience, mais parfois c'est nécessaire. De plus, xfail sous cette forme sera vert, que le test ait échoué ou non. Vous pouvez toujours le passer au paramètre Strict = True, alors ce sera une situation légèrement différente, pytest attendra que le test échoue. Si le test réussit, un message d'erreur sera renvoyé, et vice versa.
Une autre chose utile est skipif. Il y a juste un saut qui n'exécute pas les tests. Et il y a skipif. Si vous vous accrochez à ce décorateur, le test ne fonctionnera pas sous certaines conditions.
Dans ce cas, il est écrit que si j'ai une plate-forme Mac, ne commencez pas, car le test tombe pour une raison quelconque. Ça arrive. Mais en général, il existe des tests spécifiques à la plate-forme qui échoueront toujours sur une plate-forme spécifique. Alors c'est utile.

Commençons. Nous avons vu la lettre X, nous avons vu S. X se réfère ici à xfail, S - to skipif. Autrement dit, pytest montre quel test nous avons complètement manqué et lequel nous avons effectué, mais nous ne regardons pas le résultat.

Il existe de nombreuses options utiles dans Pytest lui-même. Je ne pourrai bien sûr pas les afficher ici, vous pouvez voir la documentation. Mais je vais vous en dire quelques-uns.
Voici une option utile --collect-only. Il affiche une liste des tests trouvés. Il existe une option -k - filtrage par nom de test. C'est l'une de mes options préférées: si un test échoue, surtout s'il est complexe et que vous ne savez pas encore comment le résoudre, filtrez-le et exécutez-le.
Vous voulez gagner du temps et probablement pas amusant d'exécuter 15 autres tests - vous savez qu'ils réussissent ou échouent, mais vous ne les avez pas encore atteints. Exécutez le test qui plante, corrigez-le et continuez.
Il y a aussi une très belle option -s, elle permet la sortie de stdout et stderr dans les tests. Par défaut, pytest affichera uniquement stdout et stderr pour les tests ayant échoué. Mais il y a des moments, généralement au stade du débogage, où vous voulez sortir quelque chose dans le test et que vous ne savez pas si le test échouera. Il se peut que cela ne tombe pas, mais vous voulez voir dans le test lui-même ce qui s'y trouve et en sortie. Ensuite, exécutez avec -s et vous devriez voir ce que vous voulez.
-v est l'option verbeuse standard, augmente la verbosité.
--lf, --last-failed est une option qui vous permet de redémarrer uniquement les tests qui ont échoué lors de la dernière exécution. --sw, --stepwise sont également des fonctions utiles comme -k. Si vous réparez les tests séquentiellement, puis exécutez avec --stepwise, il passe par les verts, et dès qu'il voit le test échoué, il s'arrête. Et lorsque vous exécutez à nouveau --sw, cela commence par ce test qui s'est écrasé. S'il retombe, il s'arrêtera à nouveau; s'il ne tombe pas, il continuera jusqu'à l'automne suivant.

Lien depuis la diapositive
Dans pytest, il y a un fichier de configuration principal pytest.ini. Dans celui-ci, vous pouvez modifier le comportement par défaut de pytest. J'ai donné ici les options que l'on retrouve très souvent dans le fichier de configuration.
Les chemins de test sont les chemins que pytest recherchera pour les tests. addopts est ce qui est ajouté à la ligne de commande au démarrage. Ici, j'ai ajouté des plugins flake8 et de couverture aux addopts. Nous les examinerons un peu plus tard.

Lien de la diapositive
Il existe de nombreux plugins différents dans pytest. J'ai écrit ceux qui, encore une fois, sont utilisés partout. flake8 est un linter, la couverture est la couverture du code par des tests. Ensuite, il y a tout un ensemble de plugins qui facilitent le travail avec certains frameworks: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. Il y a probablement autre chose.
Le plugin xdist est utilisé si vous souhaitez exécuter des tests en parallèle. Le plugin timeout vous permet de limiter le temps d'exécution du test: cela est pratique. Vous suspendez un décorateur de délai d'expiration sur le test, et si le test prend plus de temps, il échoue.

Jetons un coup d'oeil. J'ai ajouté une couverture et un flake8 à pytest.ini. Coverage m'a donné un rapport, j'ai un fichier avec des tests là-bas, quelque chose n'a pas été appelé, mais ce n'est pas grave :)
Voici le fichier k_stat.py, il contient jusqu'à cinq déclarations. C'est à peu près la même chose que cinq lignes de code. Et la couverture est de 100%, mais c'est parce que mon fichier est très petit.
En fait, la couverture n'est généralement pas à cent pour cent et, de plus, elle ne devrait pas être atteinte par tous les moyens. Subjectivement, il semble qu'une couverture de test de 60 à 70% soit tout à fait suffisante et normale pour le travail.
La couverture est une mesure telle que, même à cent pour cent, ne signifie pas que vous êtes génial. Le fait que vous ayez appelé ce code ne signifie pas que vous avez vérifié quelque chose. Vous pouvez également écrire assert True à la fin. Vous devez aborder la couverture de manière raisonnable, pour une couverture de test à 100%, il y a une décoloration et des robots, mais les gens n'ont pas besoin de le faire.
Dans pytest.ini, j'ai connecté un autre plugin. Ici vous pouvez voir --flake8, c'est le linter qui montre mes erreurs de style, et quelques autres, pas de PEP8, mais de pyflakes.

Ici, dans l'échappement est écrit le numéro d'erreur en PEP8 ou en pyflakes. En général, tout est clair. La ligne est trop longue, pour la redéfinition, vous avez besoin de deux lignes vides, vous avez besoin d'une ligne vide à la fin du fichier. À la fin, il dit que CitizenImport n'est pas utilisé pour moi. En général, les linters vous permettent de détecter les erreurs grossières et les erreurs de conception de code.

Nous avons déjà parlé du plugin timeout, il permet de limiter le temps d'exécution du test. Pour certains tests, le temps d'exécution est important. Et vous pouvez le limiter à l'intérieur des tests avec time.time et timeit. Ou en utilisant le plugin timeout, qui est également très pratique. Si le test fonctionne trop, il peut être profilé de différentes manières, par exemple cProfile, mais Yura en parlera dans sa conférence .
Si vous utilisez un IDE et que cela vaut la peine d'utiliser des outils auxiliaires, j'ai ici, en particulier, PyCharm, alors les tests sont très faciles à exécuter directement à partir de celui-ci.

Reste à parler de simulacre. Disons que nous avons le module A, nous voulons le tester et il y a d'autres modules que nous ne voulons pas tester. L'un d'eux va au réseau, l'autre à la base de données et le troisième est un simple module qui ne nous dérange aucunement. Dans de tels cas, la simulation nous aidera. Encore une fois, si nous écrivons un test d'intégration, nous allons très probablement ouvrir une base de données de test, écrire un client de test, et c'est bien aussi. C'est juste un test d'intégration.
Il y a des moments où nous voulons faire un test unitaire lorsque nous ne voulons tester qu'une seule pièce. Ensuite, nous avons besoin d'une simulation.

Mock est une collection d'objets qui peuvent être utilisés pour remplacer l'objet réel. Sur tout appel à des méthodes, à des attributs, il retourne également mock.

Dans cet exemple, nous avons un module simple. Nous le laisserons et remplacerons certains plus complexes par des simulacres. Nous allons maintenant voir comment cela fonctionne.

Cela est clairement montré ici. On l'a importé, on dit que m est un simulacre. Rappelé simulé. Ils ont dit que m a une méthode f. Rappelé moqueur. Ils ont dit que m est l'attribut is_alive. Super, un autre simulacre est de retour. Et nous voyons que m et f sont appelés une fois. Autrement dit, c'est un objet tellement délicat, à l'intérieur duquel la méthode getattr est réécrite.

Jetons un coup d'œil à un exemple plus clair. Disons qu'il existe un AliveChecker. Il utilise une sorte de http_session, il a besoin d'une cible, et il a une fonction do_check qui retourne Vrai ou Faux, selon ce qu'il a reçu: 200 ou pas 200. C'est un exemple légèrement artificiel. Mais supposons qu'à l'intérieur de do_check, vous puissiez créer une logique complexe.
Disons que nous ne voulons rien tester sur la session, nous ne voulons rien savoir de la méthode get. Nous voulons seulement tester do_check. Super, testons-le.

Vous pouvez le faire comme ça. Mock http_session, ici on l'appelle pseudo_client. Nous nous moquons de sa méthode get, nous disons que get est une simulation qui renvoie 200. Nous lançons, créons un AliveChecker à partir de là, le lançons. Ce test fonctionnera.
De plus, vérifions que get a été appelé une fois et avec exactement les mêmes arguments que ceux écrits. Autrement dit, nous avons appelé do_check sans rien savoir de la session ou de ses méthodes. Nous les avons juste gelés. La seule chose que nous savons, c'est qu'il a renvoyé 200.

Un autre exemple. C'est très similaire au précédent. La seule chose ici est side_effect au lieu de return_value. Mais c'est quelque chose que fait le simulacre. Dans ce cas, il lève une exception. La ligne d'assert a été modifiée pour assert not AliveChecker.do_check (). Autrement dit, nous voyons que le contrôle ne passera pas.
Voici deux exemples de la façon de tester la fonction do_check sans rien savoir de ce qui est venu d'en haut, de ce qui est entré dans cette classe.
L'exemple, bien sûr, semble artificiel: il n'est pas tout à fait clair pourquoi vérifier, 200 ou pas 200, il y a juste un minimum de logique. Mais imaginons faire quelque chose de délicat en fonction du code retour. Et puis un tel test commence à sembler beaucoup plus significatif. Nous avons vu que 200 arrivaient, puis nous vérifions la logique de traitement. Sinon 200 - le même.

Vous pouvez également patcher des bibliothèques à l'aide de mock. Disons que vous avez déjà une bibliothèque et que vous devez y changer quelque chose. Voici un exemple, nous avons corrigé le sinus. Maintenant, il revient toujours deux fois. Excellent.
On voit aussi que m a été appelé deux fois. Mock, bien sûr, ne sait rien des API internes des méthodes que vous vous moquez et, en général, n'est pas obligé de les égaler. Mais mock vous permet de vérifier ce que vous avez appelé, combien de fois et avec quels arguments. En ce sens, cela permet de tester le code.

Je veux vous mettre en garde contre un cas où il y a un module et une énorme maquette. Veuillez aborder tout raisonnablement. Si vous avez des choses simples, ne les mouillez pas. Plus vous avez de simulation dans votre test, plus vous vous éloignez de la réalité: votre API peut ne pas correspondre, et en général, ce n'est pas exactement ce que vous testez. Vous n'avez pas besoin de tout tremper inutilement. Abordez le processus intelligemment.

Nous avons encore la dernière petite partie sur l'intégration continue. Lorsque vous développez seul un projet pour animaux de compagnie, vous pouvez exécuter des tests localement, et ce n'est pas grave, ils fonctionneront.
Dès que le projet se développe et qu'il y a plus d'un développeur, il cesse de fonctionner. Premièrement, la moitié n'exécutera pas de tests localement. Deuxièmement, ils les exécuteront sur leurs versions. Il y aura des conflits quelque part, tout s'effondrera constamment.
Pour cela, il y a l'intégration continue, une pratique de développement qui consiste à injecter rapidement des candidats dans le courant dominant. Mais en même temps, ils doivent passer par une sorte d'assemblage automatique ou d'autotests dans un système spécial. Vous avez le code dans le référentiel, les commits que vous souhaitez fusionner dans la branche principale de votre projet. Sur ces commits, les tests sont passés dans un système spécial. Si les tests sont verts, alors soit le commit est versé en lui-même, soit vous avez la possibilité de le verser.
Un tel schéma, bien sûr, a ses inconvénients, ainsi que tout. À tout le moins, vous avez besoin de matériel supplémentaire - pas du fait que CI sera gratuit. Mais dans une entreprise plus ou moins grande, et pas une grande non plus, vous ne pouvez aller nulle part sans CI.
À titre d'exemple - une capture d'écran de TeamCity, l'un des CI. Il y a un assemblage, il s'est terminé avec succès. Il y a eu beaucoup de changements dedans, il a été lancé sur tel ou tel agent à tel et tel moment. C'est un exemple de quand tout va bien et où vous pouvez affluer.
Il existe de nombreux systèmes CI différents. J'ai écrit une liste, si vous êtes intéressé, jetez un œil: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Merci.
D'autres conférences du cours vidéo sur Python sont dans un article sur Habré .