Dans le chat du podcast "Zinc Prod", ils ont laissé tomber un article sur la façon dont certains types ont transféré toute la logique métier aux procédures stockées dans pl / pgsql. Et comme l'article présentait de nombreux avantages, cela signifie qu'il y a des gens, et peut-être même la majorité d'entre eux, qui ont positivement perçu un tel refactoring.
Je ne répandrai pas mes pensées le long de l'arbre, mais j'évoquerai immédiatement un tas d'inconvénients de l'utilisation de procédures stockées.
Inconvénients des procédures stockées
Gestion des versions
Si, dans le cas du code php, vous pouvez simplement basculer vers une autre branche dans git et voir ce qui s'est passé, les procédures stockées doivent encore être poussées dans la base de données. Et les migrations traditionnelles n'aideront pas ici: si vous écrivez toutes les modifications dans le stockage en tant que nouvelle PROCÉDURE DE CRÉATION OU DE REMPLACEMENT, alors il y aura un enfer sur la révision du code: il y a toujours un nouveau fichier, qui n'est pas clair avec quoi comparer. Par conséquent, vous devrez chercher des outils supplémentaires ou écrire votre vélo.
Le langage pl / pgsql lui-même
C'est un langage procédural désuet des années 90 qui n'a pas du tout évolué. Pas de POO ou FP ou quoi que ce soit. Syntaxe sans le moindre soupçon de sucre syntaxique.
Par exemple, les variables doivent être déclarées au début d'une procédure, dans un bloc DECLARE spécial. C'est ce que nos grands-pères ont fait, il y a une certaine nostalgie pour le langage Pascal là-dedans, mais merci, pas en 2020.
Comparez deux fonctions qui font la même chose en php et pl / pgsql:
CREATE OR REPLACE FUNCTION sum(x int, y int)
RETURNS int
LANGUAGE plpgsql
AS $$
DECLARE
result int;
BEGIN
result := x + y;
return result;
END;
$$;
function sum(int $x, int $y): int
{
$result = $x + $y;
return $result;
}
Environ 2-3 fois plus de gribouillis.
De plus, la langue est interprétée, pas de JIT, etc. (corrigez-moi si quelque chose a changé dans les versions récentes). Ceux. tout est très lent et triste. Si vous utilisez un type de stockage, alors en SQL pur ou v8 (c'est-à-dire javascript).
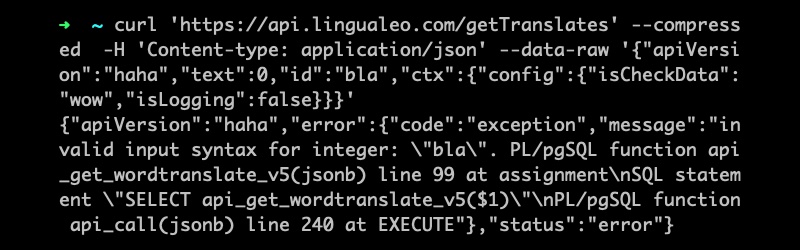
Débogage
Croyez-moi, le débogage du code php est 100500 fois plus facile. Vous venez de corriger quelque chose et de regarder le résultat. Vous pouvez superposer l'écho ou voir ce qu'il y a via xdebug directement dans l'EDI.
Le débogage des procédures stockées n'est pas pratique. Cela doit être fait dans pgadmin (en activant une extension spéciale). PgAdmin est loin de PHPstorm pour plus de commodité.
Journalisation et gestion des erreurs
Oubliez le beau json avec des traces tombant de stdout, puis de graylog et de sentinelle. Et pour que tout cela se passe automatiquement, donnant à l'utilisateur une erreur 500 si le contrôleur n'attrape pas l'exception.
Dans le stockage pl / pgsql, vous ferez tout manuellement:
GET DIAGNOSTICS stack = PG_CONTEXT;
RAISE NOTICE E'--- ---\n%', stack;
Collecte de métriques
Vous ne pouvez pas, comme dans golang, simplement ajouter le point de terminaison / metrics, qui sera aspiré par Prometheus, où vous entassez des affaires et d'autres métriques pour la surveillance. Je ne sais tout simplement pas comment m'en sortir avec pl / pgsql.
Mise à l'échelle
L'exécution de procédure stockée gaspille des ressources (par exemple, CPU) sur le serveur de base de données. Dans le cas d'autres langues, vous pouvez déplacer la logique vers d'autres nœuds.
Dépendances
En php, vous pouvez, en utilisant le gestionnaire de packages composer, extraire la bibliothèque souhaitée d'Internet en un seul geste. Tout comme dans js ce sera npm, dans Rust ce sera cargo, etc.
Dans le monde pl / pgsql, il faut souffrir. Il n'y a tout simplement pas de gestionnaire de dépendances dans cette langue.
Cadres
Dans le monde moderne, une application Web n'est souvent pas écrite à partir de zéro, mais assemblée sur la base d'un framework utilisant ses composants. Par exemple, sur Laravel, vous avez le routage, la validation des demandes, le moteur de modèle, l'authentification / autorisation, 100 500 aides pour toutes les occasions, etc. prêts à l'emploi. Pour tout écrire à la main à partir de zéro, dans une langue obsolète - non merci.
Il y aura beaucoup de vélos, qui devront être entretenus plus tard.
Tests unitaires
Il est même difficile d'imaginer à quel point il est pratique d'organiser des tests unitaires dans les magasins pl / pgsql. Je n'ai jamais essayé. Veuillez partager les commentaires.
Refactoring
Bien qu'il existe un IDE pour travailler avec une base de données (Datagrip), les outils de refactoring sont beaucoup plus riches pour les langages courants. Toutes sortes de linters, astuces pour simplifier le code, etc.
Un petit exemple: dans ces morceaux de code que j'ai donnés au début de l'article, PHPStorm a donné un indice que la variable est
$resultfacultative, et vous pouvez simplement return $x + $y;
le faire.Dans le cas de plpgsql - silence.
Avantages des procédures stockées
- Il n'y a pas de surcharge pour le transfert de données intermédiaires le long du chemin de la base de données principale.
- Le plan de requête est mis en cache dans des procédures stockées, ce qui peut économiser quelques ms. ceux. en tant que wrapper sur une requête, il est parfois logique de le faire (dans de rares cas, et non sur pl / pgsql, mais sur sql nu), s'il y a une charge élevée frénétique, et la requête elle-même est exécutée rapidement.
- Lorsque vous écrivez votre extension pour postgres, vous ne pouvez pas vous passer de stockage.
- Lorsque vous souhaitez masquer certaines données pour des raisons de sécurité, en donnant à l'application l'accès à seulement un ou deux stockages (cas rare).
conclusions
À mon avis, les procédures stockées ne sont nécessaires que dans de très, très rares cas, lorsque vous êtes sûr de ne pas pouvoir vous en passer. Dans d'autres cas, vous ne ferez que compliquer la vie des développeurs, et de manière significative.
Je comprendrais si dans l'article original une partie de la logique a été transférée à SQL, cela peut être compris. Mais pourquoi le stockage est un mystère.
Je serais heureux si vous pensez que je me trompe ou si vous connaissez d'autres situations liées aux procédures stockées (à la fois pour et contre), et écrivez à ce sujet dans les commentaires.
