Dans cet article, nous allons essayer d'écrire un classificateur pour définir des articles sarcastiques à l'aide de l'apprentissage automatique et de TensorFlow.
L'article est une traduction de Machine Learning Foundations: Partie 10 - Utilisation de la PNL pour créer un classificateur de sarcasme
L' ensemble de données Sarcasm in News Headlines de Rishab Mishra est utilisé comme ensemble de données d'entraînement . C'est un ensemble de données intéressant qui recueille les gros titres des sources d'information conventionnelles, ainsi que quelques autres comiques provenant de faux sites d'information.
L'ensemble de données est un fichier JSON avec trois colonnes.
is_sarcastic- 1 si l'entrée est sarcastique, sinon 0headline- le titre de l'articlearticle_link- URL du texte de l'article
Nous allons simplement regarder les en-têtes ici. Nous avons donc un ensemble de données très simple avec lequel travailler. L'en-tête est notre fonctionnalité, et is_sarcastic est notre raccourci.
Les données JSON ressemblent à ceci.
{
"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5",
"headline": "former versace store clerk sues over secret 'black code' for minority shoppers",
"is_sarcastic": 0
}Chaque enregistrement est un champ JSON avec des paires nom-valeur affichant la colonne et les données associées.
Voici le code pour charger des données en Python
import json
with open("sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link']) . -, import json json Python. sarcasm.json. json.load(), . , URL-. . , URL- .
.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(oov_token="")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
print(word_index)
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape) . 25 000 , . word_index . .
... 'blowing': 4064, 'packed': 4065, 'deficit': 4066, 'essential': 4067, 'explaining': 4068, 'pollution': 4069, 'braces': 4070, 'protester': 4071, 'uncle': 4072 ..., , . , , , .
[ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
(26709, 40). , . 26 709 , 40 .
, .
voiceab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type = 'post'
padding_type = 'post'
oov_tok = ""
training_size = 20000 26 000 20 000 , training_size, 6000 .
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:], , , , .
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) , , . training_sentence. . test_sentences , . training_sequences training_sentences. , . testing_sentences .
, , , . — , , . , . .
, «Bad» «Good». , . , .

«meh» , . .
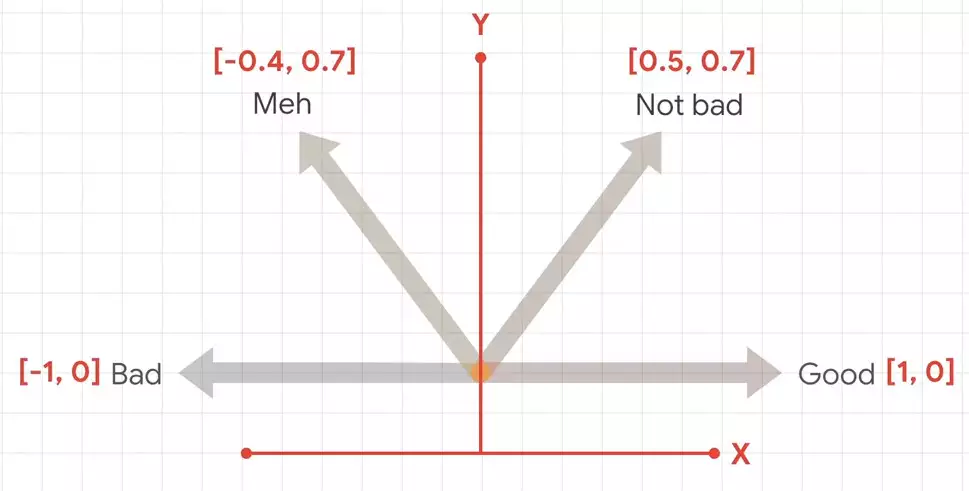
«not bad», , «Good», , . , .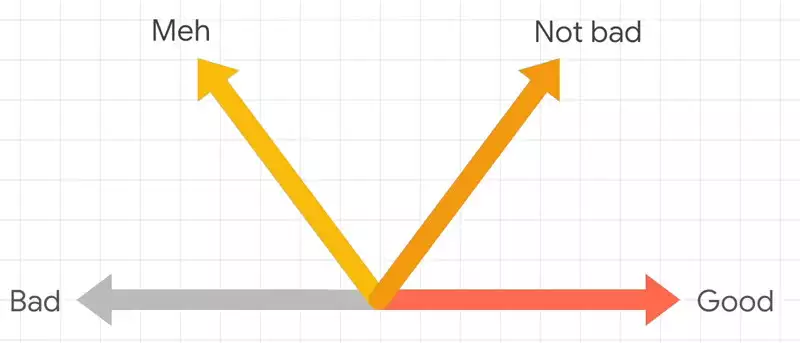
, . .
, .
, Keras, Embedding.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])Embedding . , , , . 16, . , Embedding 10 016 , . , , .
, .
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2) training_padded, .
, Google Colab, .