Il est pratique de traiter du texte en langage naturel à l'aide de Python, car il s'agit d'un outil de programmation de assez haut niveau, doté d'une infrastructure bien développée et a fait ses preuves dans le domaine de l'analyse de données et de l'apprentissage automatique. Plusieurs bibliothèques et frameworks ont été développés par la communauté pour résoudre les problèmes de PNL en Python. Dans notre travail, nous utiliserons l'outil Web interactif pour développer des scripts python Jupyter Notebook, la bibliothèque NLTK pour l'analyse de texte et la bibliothèque wordcloud pour la construction d'un nuage de mots.
Le réseau contient une assez grande quantité de matériel sur le thème de l'analyse de texte, mais dans de nombreux articles (y compris en russe), il est proposé d'analyser le texte en anglais. L'analyse du texte russe présente certaines spécificités de l'utilisation de la boîte à outils PNL. A titre d'exemple, considérons l'analyse de fréquence du texte de l'histoire "Blizzard" par A. Pouchkine.
L'analyse de fréquence peut être grossièrement divisée en plusieurs étapes:
- Chargement et navigation des données
- Nettoyage et prétraitement du texte
- Supprimer les mots vides
- Traduire des mots en forme de base
- Calcul des statistiques d'occurrence des mots dans le texte
- Visualisation en nuage de la popularité des mots
Le script est disponible sur github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb , source - github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
Chargement des données
Nous ouvrons le fichier en utilisant la fonction intégrée ouverte, spécifions le mode de lecture et l'encodage. Nous lisons tout le contenu du fichier, en conséquence nous obtenons le texte de la chaîne:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
La longueur du texte - le nombre de caractères - peut être obtenue avec la fonction standard len:
len(text)
Une chaîne en python peut être représentée comme une liste de caractères, de sorte que l'accès à l'index et les opérations de découpage sont également possibles pour travailler avec des chaînes. Par exemple, pour afficher les 300 premiers caractères du texte, exécutez simplement la commande:
text[:300]
Prétraitement (prétraitement) du texte
Pour effectuer une analyse de fréquence et déterminer le sujet du texte, il est recommandé de supprimer le texte des signes de ponctuation, des espaces supplémentaires et des nombres. Vous pouvez le faire de différentes manières - en utilisant des fonctions de chaîne intégrées, en utilisant des expressions régulières, en utilisant le traitement de liste ou d'une autre manière.
Tout d'abord, convertissons les caractères en une seule casse, par exemple, plus bas:
text = text.lower()
Nous utilisons le jeu de caractères de ponctuation standard du module string:
import string
print(string.punctuation)
string.punctuation est une chaîne. Le jeu de caractères spéciaux à supprimer du texte peut être développé. Il est nécessaire d'analyser le texte source et d'identifier les caractères à supprimer. Ajoutons des sauts de ligne, des tabulations et d'autres caractères qui se trouvent dans notre texte source aux signes de ponctuation (par exemple, le caractère avec le code \ xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Pour supprimer des caractères, nous utilisons un traitement élémentaire de la chaîne - divisez la chaîne de texte d'origine en caractères, ne laissez que les caractères qui ne sont pas dans le jeu spec_chars, et combinez à nouveau la liste de caractères en une chaîne:
text = "".join([ch for ch in text if ch not in spec_chars])
Vous pouvez déclarer une fonction simple qui supprime le jeu de caractères spécifié du texte source:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Il peut être utilisé à la fois pour supprimer des caractères spéciaux et pour supprimer des nombres du texte d'origine:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Texte de tokenisation
Pour un traitement ultérieur, le texte effacé doit être divisé en ses composants: les jetons. L'analyse de texte en langage naturel utilise des ventilations de symboles, de mots et de phrases. Le processus de partitionnement est appelé tokenisation. Pour notre tâche d'analyse de fréquence, il est nécessaire de décomposer le texte en mots. Pour ce faire, vous pouvez utiliser la méthode prête à l'emploi de la bibliothèque NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
La variable text_tokens est une liste de mots (tokens). Pour calculer le nombre de mots dans le texte prétraité, vous pouvez obtenir la longueur de la liste de jetons:
len(text_tokens)
Pour afficher les 10 premiers mots, utilisons l'opération de tranche:
text_tokens[:10]
Pour utiliser les outils d'analyse de fréquence de la bibliothèque NLTK, vous devez convertir la liste des jetons en classe Text, qui est incluse dans cette bibliothèque:
import nltk
text = nltk.Text(text_tokens)
Déduisons le type du texte variable:
print(type(text))
Les opérations de tranche sont également applicables à une variable de ce type. Par exemple, cette action affichera les 10 premiers jetons du texte:
text[:10]
Calcul des statistiques d'occurrence des mots dans le texte
La classe FreqDist (distributions de fréquence) est utilisée pour calculer les statistiques de distribution de fréquence de mot dans le texte:
from nltk.probability import FreqDist
fdist = FreqDist(text)
Essayer d'afficher la variable fdist affichera un dictionnaire contenant des jetons et leurs fréquences - le nombre de fois que ces mots apparaissent dans le texte:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
Vous pouvez également utiliser la méthode most_common pour obtenir une liste de tuples avec les jetons les plus courants:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
La fréquence de distribution des mots dans un texte peut être visualisée à l'aide d'un graphique. La classe FreqDist contient une méthode de tracé intégrée pour tracer un tel tracé. Il est nécessaire d'indiquer le nombre de jetons dont les fréquences seront affichées sur la carte. Avec le paramètre cumulative = False, le graphique illustre la loi de Zipf : si tous les mots d'un texte suffisamment long sont classés par ordre décroissant de fréquence d'utilisation, alors la fréquence du nième mot d'une telle liste sera approximativement inversement proportionnelle à son nombre ordinal n.
fdist.plot(30,cumulative=False)
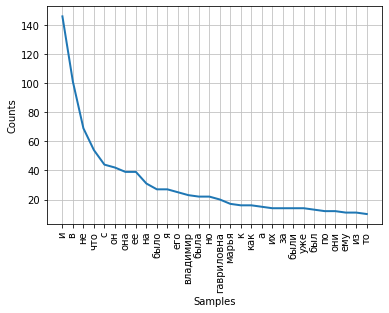
On peut noter qu'à l'heure actuelle, les fréquences les plus élevées ont des conjonctions, prépositions et autres parties de service du discours qui ne portent pas de charge sémantique, mais expriment uniquement des relations sémantiques-syntaxiques entre les mots. Pour que les résultats de l'analyse de fréquence reflètent le sujet du texte, il est nécessaire de supprimer ces mots du texte.
Supprimer les mots vides
Les mots vides (ou mots parasites), en règle générale, incluent les prépositions, les conjonctions, les interjections, les particules et autres parties du discours qui se trouvent souvent dans le texte, sont des mots de service et ne portent pas de charge sémantique - ils sont redondants.
La bibliothèque NLTK contient des listes de mots vides prêtes à l'emploi pour différentes langues. Obtenons une liste de cent mots pour la langue russe:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Il convient de noter que les mots vides sont sensibles au contexte - pour les textes de différents sujets, les mots vides peuvent différer. Comme dans le cas des caractères spéciaux, il est nécessaire d'analyser le texte source et d'identifier les mots vides qui ne sont pas inclus dans l'ensemble standard.
La liste des mots vides peut être étendue à l'aide de la méthode d'extension standard:
russian_stopwords.extend(['', ''])
Après avoir supprimé les mots vides, la fréquence de distribution des jetons dans le texte est la suivante:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
Comme vous pouvez le voir, les résultats de l'analyse de fréquence sont devenus plus informatifs et reflètent plus précisément le sujet principal du texte. Cependant, nous voyons dans les résultats des jetons tels que "vladimir" et "vladimira", qui sont, en fait, un mot, mais sous des formes différentes. Pour corriger cette situation, il est nécessaire de ramener les mots du texte source à leurs bases ou à leur forme originale - pour procéder à la radicalisation ou à la lemmatisation.
Visualisation en nuage de la popularité des mots
A la fin de nos travaux, nous visualisons les résultats de l'analyse fréquentielle du texte sous la forme d'un "nuage de mots".
Pour cela, nous avons besoin des bibliothèques wordcloud et matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Pour créer un nuage de mots, une chaîne doit être transmise à la méthode en entrée. Pour convertir la liste des jetons après le prétraitement et la suppression des mots vides, nous utiliserons la méthode join, en spécifiant un espace comme séparateur:
text_raw = " ".join(text)
Appelons la méthode de construction du cloud:
wordcloud = WordCloud().generate(text_raw)
En conséquence, nous obtenons un tel "nuage de mots" pour notre texte: en le

regardant, vous pouvez avoir une idée générale du sujet et des personnages principaux de l'œuvre.