1.1 Qu'est-ce que l'arbre de décision?
1.1.1 Exemple d'arbre de décision
Par exemple, nous avons le jeu de données suivant (date définie): météo, température, humidité, vent, golf. Selon la météo et tout le reste, nous sommes allés (〇) ou n'avons pas (×) joué au golf. Supposons que nous ayons 14 options préconçues.

À partir de ces données, nous pouvons composer une structure de données montrant dans quels cas nous sommes allés au golf. Cette structure s'appelle l'arbre de décision en raison de sa forme ramifiée.
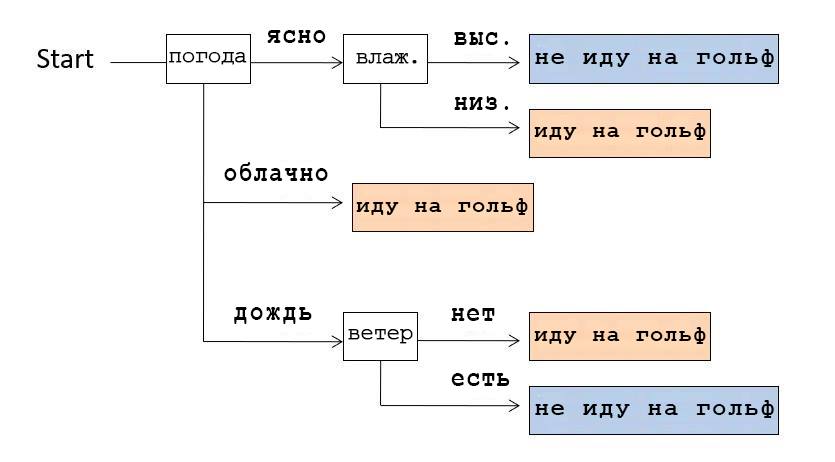
Par exemple, si nous regardons l'arbre de décision montré dans l'image ci-dessus, nous nous rendons compte que nous avons d'abord vérifié la météo. Si c'était clair, nous avons vérifié l'humidité: si elle est élevée, alors nous ne sommes pas allés jouer au golf, si elle est basse, nous y sommes allés. Et si le temps était nuageux, ils allaient jouer au golf, quelles que soient les autres conditions.
1.1.2 À propos de cet article
Il existe des algorithmes qui créent automatiquement de tels arbres de décision en fonction des données disponibles. Dans cet article, nous utiliserons l'algorithme Python ID3.
Cet article est le premier d'une série. Les articles suivants:
(Note du traducteur: "si vous êtes intéressé par la suite, merci de nous le faire savoir dans les commentaires.")
- Principes de base de la programmation Python
- Principes de base essentiels de la bibliothèque pour l'analyse des données Pandas
- Principes de base de la structure des données (dans le cas de l'arbre de décision)
- Bases de l'entropie de l'information
- Apprendre un algorithme pour générer un arbre de décision
1.1.3 Un peu sur l'arbre de décision
La génération d'arbre de décision est liée à l'apprentissage automatique supervisé et à la classification. La classification dans l'apprentissage automatique est un moyen de créer un modèle menant à la bonne réponse en fonction de la formation à la date fixée avec les bonnes réponses et les données y menant. Le Deep Learning, très prisé ces dernières années, notamment dans le domaine de la reconnaissance d'images, fait également partie du machine learning basé sur la méthode de classification. La différence entre Deep Learning et Decision Tree est de savoir si le résultat final est réduit à une forme dans laquelle une personne comprend les principes de génération de la structure de données finale. La particularité du Deep Learning est que nous obtenons le résultat final, mais ne comprenons pas le principe de sa génération. Contrairement au Deep Learning, l'arbre de décision est facile à comprendre par les humains, ce qui est également une fonctionnalité importante.
Cette fonctionnalité de l'arbre de décision est utile non seulement pour l'apprentissage automatique, mais également pour l'extraction de dates, où la compréhension des données par l'utilisateur est également importante.
1.2 À propos de l'algorithme ID3
ID3 est un algorithme de génération d'arbre de décision développé en 1986 par Ross Quinlan. Il présente deux caractéristiques importantes:
- Données catégoriques. Ces données sont similaires à notre exemple ci-dessus (go golf ou pas), données avec une étiquette catégorielle spécifique. ID3 ne peut pas utiliser de données numériques.
- L'entropie d'information est un indicateur qui indique une séquence de données avec la moindre variance des propriétés d'une classe de valeurs.
1.2.1 À propos de l'utilisation des données numériques
L'algorithme C4.5, qui est une version plus avancée d'ID3, peut utiliser des données numériques, mais comme l'idée de base est la même dans cette série, nous utiliserons d'abord ID3.
1.3 Environnement de développement
Le programme que j'ai décrit ci-dessous, j'ai testé et exécuté dans les conditions suivantes:
- Ordinateurs portables Jupyter (à l'aide de blocs-notes Azure)
- Python 3.6
- Bibliothèques: math, pandas, functools (n'a pas utilisé scikit-learn, tensorflow, etc.)
1.4 Exemple de programme
1.4.1 En fait, le programme
Tout d'abord, copions le programme dans Jupyter Notebook et exécutons-le.
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2 Résultat
Si vous exécutez le programme ci-dessus, notre arbre de décision sera représenté sous forme de tableau de symboles comme indiqué ci-dessous.
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3 Changer les attributs (tableaux de données) que nous voulons explorer
Le dernier tableau du jeu de dates d est un attribut de classe (le tableau de données que nous voulons classer).
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}Par exemple, si vous permutez les tableaux "Golf" et "Wind", comme indiqué dans l'exemple ci-dessus, vous obtenez le résultat suivant:
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']Essentiellement, nous créons une règle dans laquelle nous disons au programme de se diversifier d'abord par la présence et l'absence de vent et par le fait que nous allons jouer au golf ou non.
Merci d'avoir lu!
Nous serons très heureux si vous nous dites si vous avez aimé cet article, la traduction était-elle claire, vous a-t-elle été utile?