Limites du processeur et limitation
Comme beaucoup d'autres utilisateurs de Kubernetes, Google recommande vivement d'ajuster les limites du processeur . Sans cette configuration, les conteneurs du nœud peuvent consommer toute la puissance du processeur, ce qui, à son tour, empêchera les processus Kubernetes importants (par exemple
kubelet) de répondre aux requêtes. Ainsi, définir des limites de CPU est un bon moyen de protéger vos nœuds.
Les limites du processeur définissent le conteneur le temps processeur maximal qu'il peut utiliser pendant une période spécifique (100 ms par défaut), et le conteneur ne dépassera jamais cette limite. Kubernetes utilise un outil spécial CFS Quota pour étrangler le conteneur et l'empêcher de dépasser la limite.Cependant, au final, un tel processeur artificiel limite les performances inférieures et augmente le temps de réponse de vos conteneurs.
Que peut-il se passer si nous ne fixons pas de limites CPU?
Malheureusement, nous avons nous-mêmes dû faire face à ce problème. Chaque nœud a un processus responsable de la gestion des conteneurs
kubeletet il a cessé de répondre aux demandes. Le nœud, lorsque cela se produit, entrera dans l'état NotReady, et les conteneurs de celui-ci seront redirigés ailleurs et créeront déjà les mêmes problèmes sur les nouveaux nœuds. Pas un scénario idéal, pour le dire légèrement.
Manifestation de problèmes d'étranglement et de réactivité
La métrique clé pour le suivi des conteneurs est
trottlingle nombre de fois où votre conteneur a été limité. Nous avons remarqué avec intérêt la présence d'étranglement dans certains conteneurs, que la charge sur le processeur soit maximale ou non. Par exemple, jetons un coup d'œil à l'une de nos principales API:
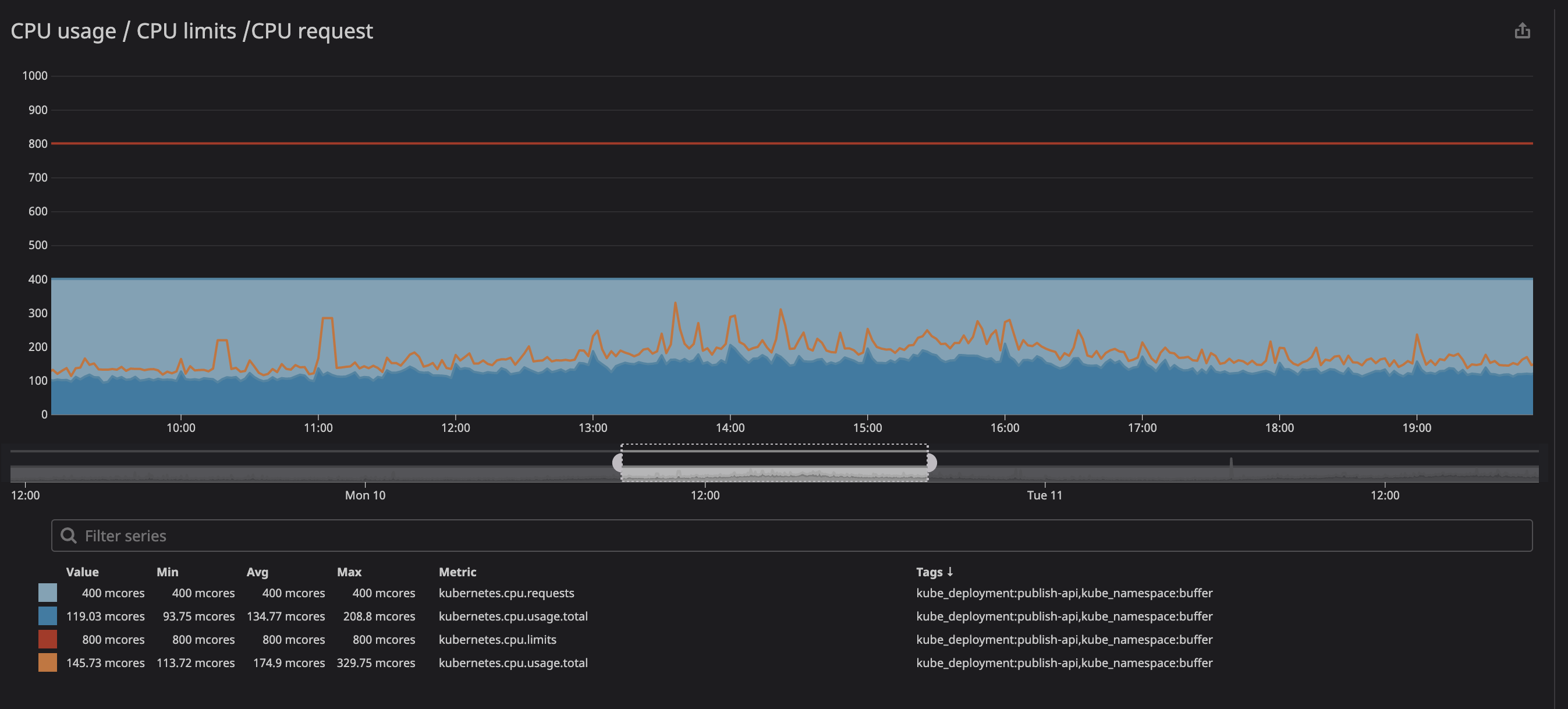
comme vous pouvez le voir ci-dessous, nous avons fixé la limite à
800m(0,8 ou 80% du cœur) et les valeurs maximales sont au mieux 200m(20% du cœur). Il semblerait que nous ayons encore beaucoup de puissance de traitement avant d'étrangler le service, cependant ...
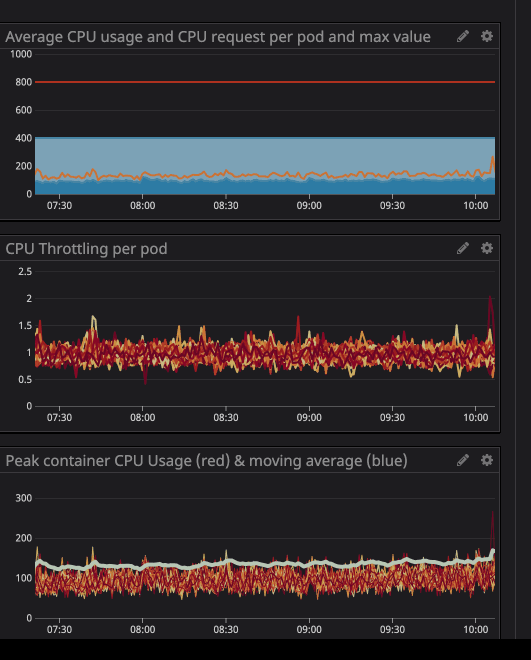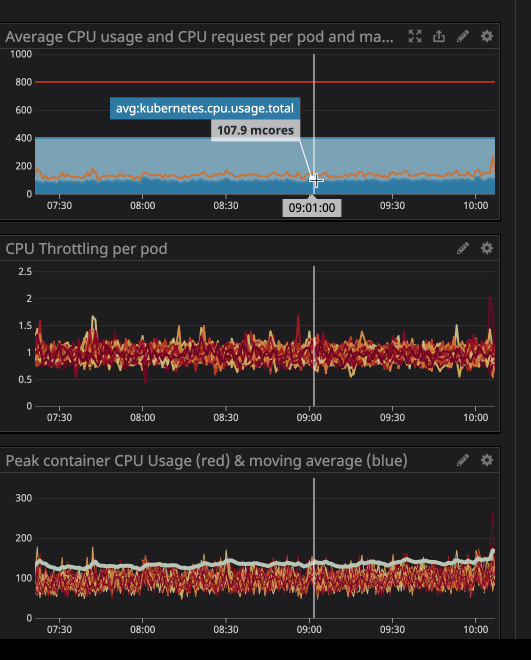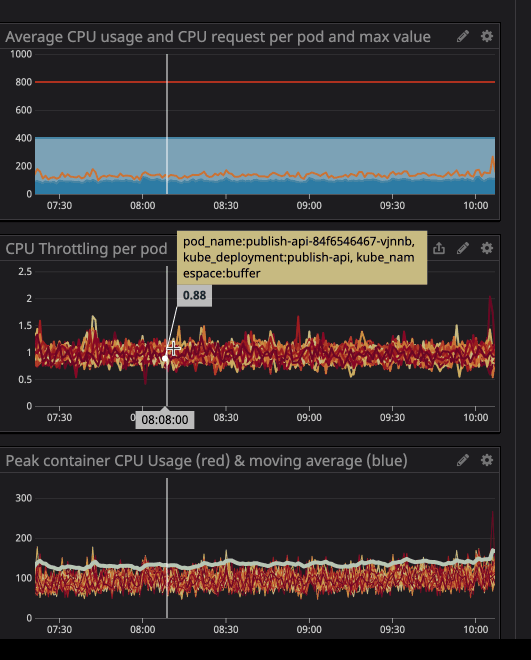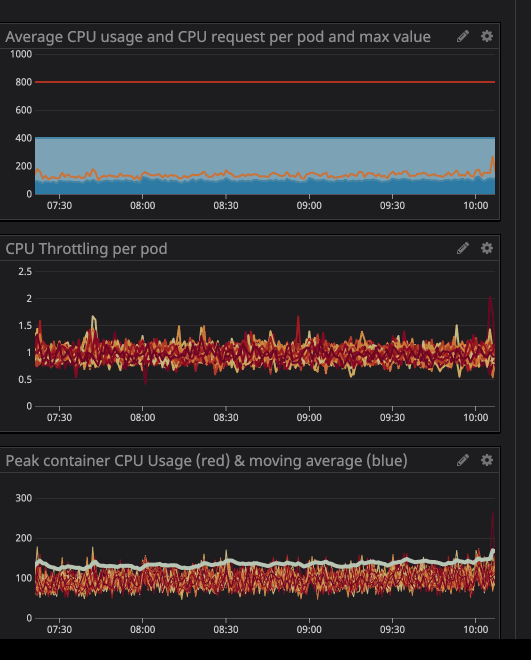
Vous avez peut-être remarqué que même lorsque la charge sur le processeur est inférieure aux limites spécifiées - beaucoup plus faibles - la limitation fonctionne toujours.
Face à cela, nous avons rapidement découvert plusieurs ressources (un problème sur github , une présentation sur zadano , un post sur omio ) sur la baisse des performances et du temps de réponse des services due à la limitation.
Pourquoi voyons-nous une limitation sous une faible utilisation du processeur? La version courte se lit comme suit: "Il y a un bogue dans le noyau Linux qui déclenche une limitation inutile des conteneurs avec des limites de processeur spécifiées." Si la nature du problème vous intéresse, vous pouvez lire la présentation ( vidéo et texte variantes) de Dave Chiluk.
Suppression des limites de processeur (avec une extrême prudence)
Après de longues discussions, nous avons décidé de supprimer les restrictions de processeur de tous les services qui affectent directement ou indirectement les fonctionnalités critiques pour nos utilisateurs.
La décision s'est avérée difficile, car nous attachons une grande importance à la stabilité de notre cluster. Par le passé, nous avons déjà expérimenté l'instabilité de notre cluster, puis les services consommaient trop de ressources et ralentissaient le travail de tout notre nœud. Maintenant, tout était un peu différent: nous avions une compréhension claire de ce que nous attendions de nos clusters, ainsi qu'une bonne stratégie pour mettre en œuvre les changements prévus.

Correspondance commerciale sur une question urgente.
Comment protéger vos nœuds lors de la suppression des restrictions?
Isoler des services «illimités»:
dans le passé, nous avons vu certains nœuds entrer dans un état
notReady, principalement en raison de services qui consommaient trop de ressources.
Nous avons décidé de placer ces services dans des nœuds séparés («étiquetés») afin qu'ils n'interfèrent pas avec les services «liés». En conséquence, en marquant certains nœuds et en ajoutant un paramètre de tolérance aux services «non liés», nous avons acquis plus de contrôle sur le cluster, et il est devenu plus facile pour nous d'identifier les problèmes avec les nœuds. Pour exécuter vous-même des processus similaires, vous pouvez vous familiariser avec la documentation .
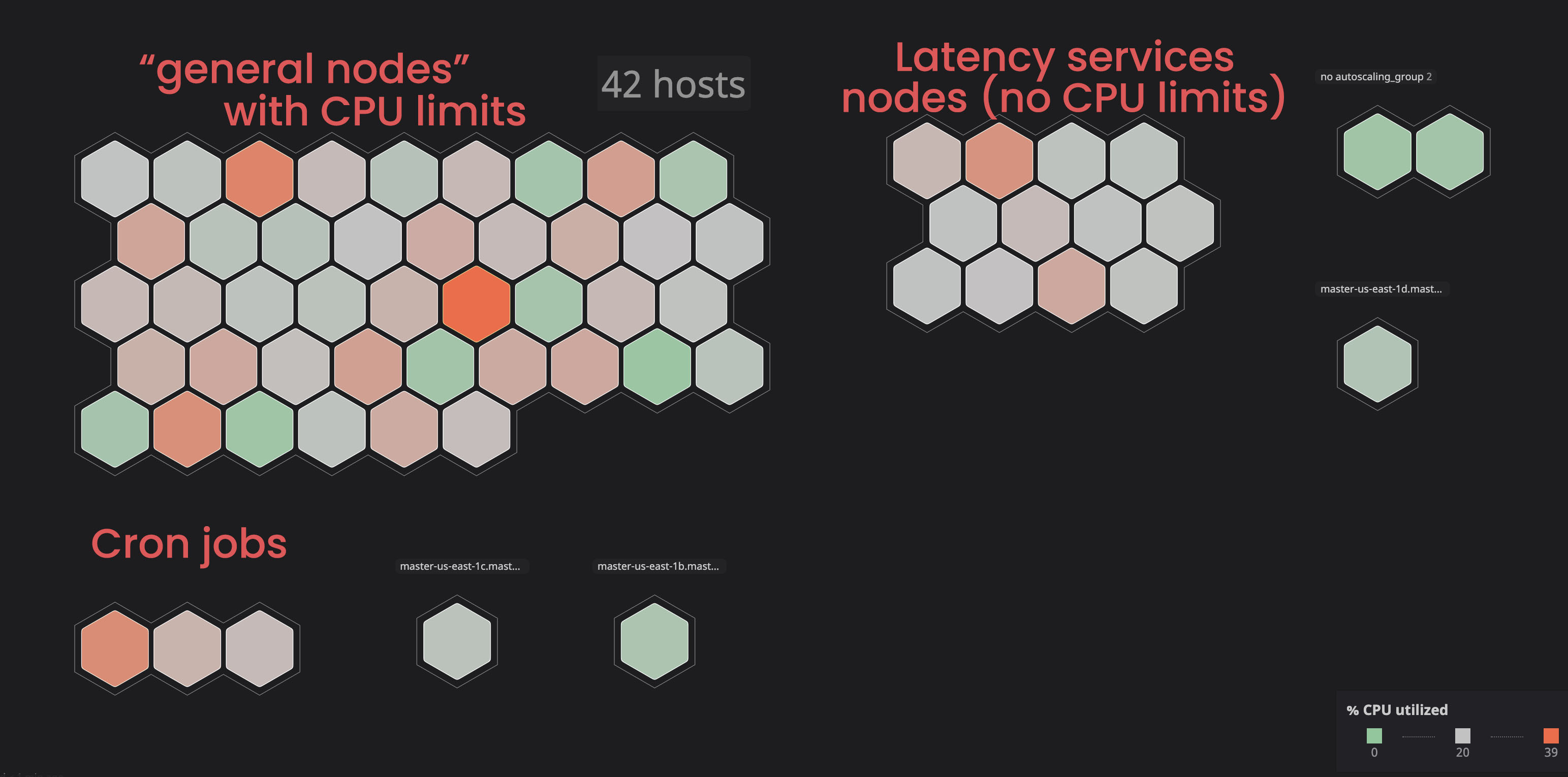
Affectation du processeur et de la demande de mémoire appropriés:
Surtout, nous craignions que le processus ne consomme trop de ressources et que le nœud cesse de répondre aux demandes. Puisque maintenant (grâce à Datadog) nous pouvions clairement observer tous les services sur notre cluster, j'ai analysé plusieurs mois de fonctionnement de ceux que nous prévoyions de désigner comme "non liés". J'ai simplement défini l'utilisation maximale du processeur avec une marge de 20%, et donc alloué de l'espace dans le nœud au cas où k8s essaie d'attribuer d'autres services au nœud.
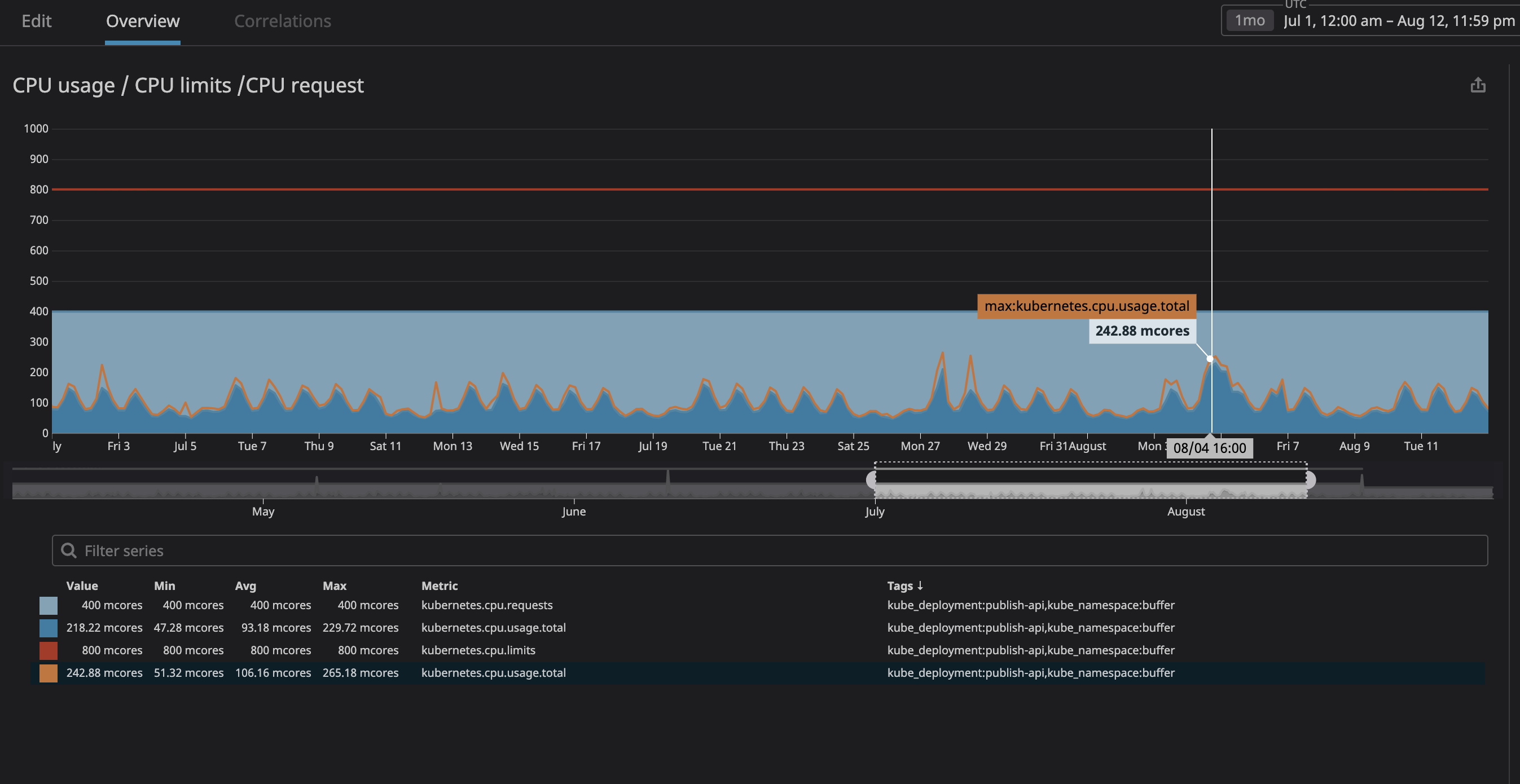
Comme vous pouvez le voir sur le graphique, la charge maximale du processeur a atteint
242mles cœurs de processeur (0,242 cœurs de processeur). Pour une requête processeur, il suffit de prendre un nombre légèrement supérieur à cette valeur. Notez que puisque les services sont centrés sur l'utilisateur, les pics de charge coïncident avec le trafic.
Faites de même avec l'utilisation de la mémoire et les requêtes, et le tour est joué, vous êtes prêt! Pour plus de sécurité, vous pouvez ajouter une mise à l'échelle automatique horizontale des pods. Ainsi, chaque fois que la charge sur les ressources est élevée, l'autoscaling créera de nouveaux pods et kubernetes les distribuera aux nœuds avec de l'espace libre. S'il n'y a plus d'espace dans le cluster lui-même, vous pouvez définir vous-même une alerte ou configurer l'ajout de nouveaux nœuds via leur autoscaling.
Parmi les inconvénients, il convient de noter que nous avons perdu dans la " densité des conteneurs ", c'est-à-dire le nombre de conteneurs travaillant dans un nœud. Nous pouvons également avoir beaucoup d '"indulgences" à faible densité de trafic, et il y a aussi une chance que vous atteigniez une charge de processeur élevée, mais l'autoscaling des nœuds devrait aider avec ce dernier.
résultats
Je suis ravi de publier ces excellents résultats d'expériences au cours des dernières semaines, nous avons déjà remarqué des améliorations significatives en réponse parmi tous les services modifiés:
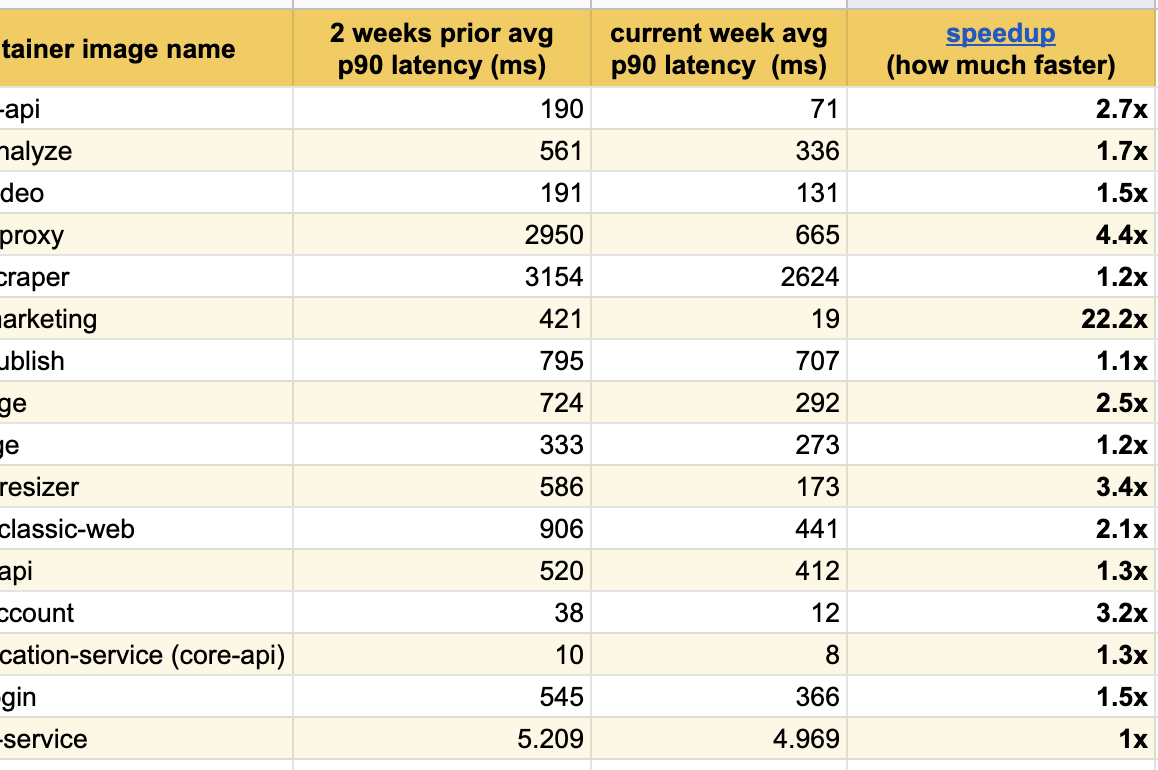
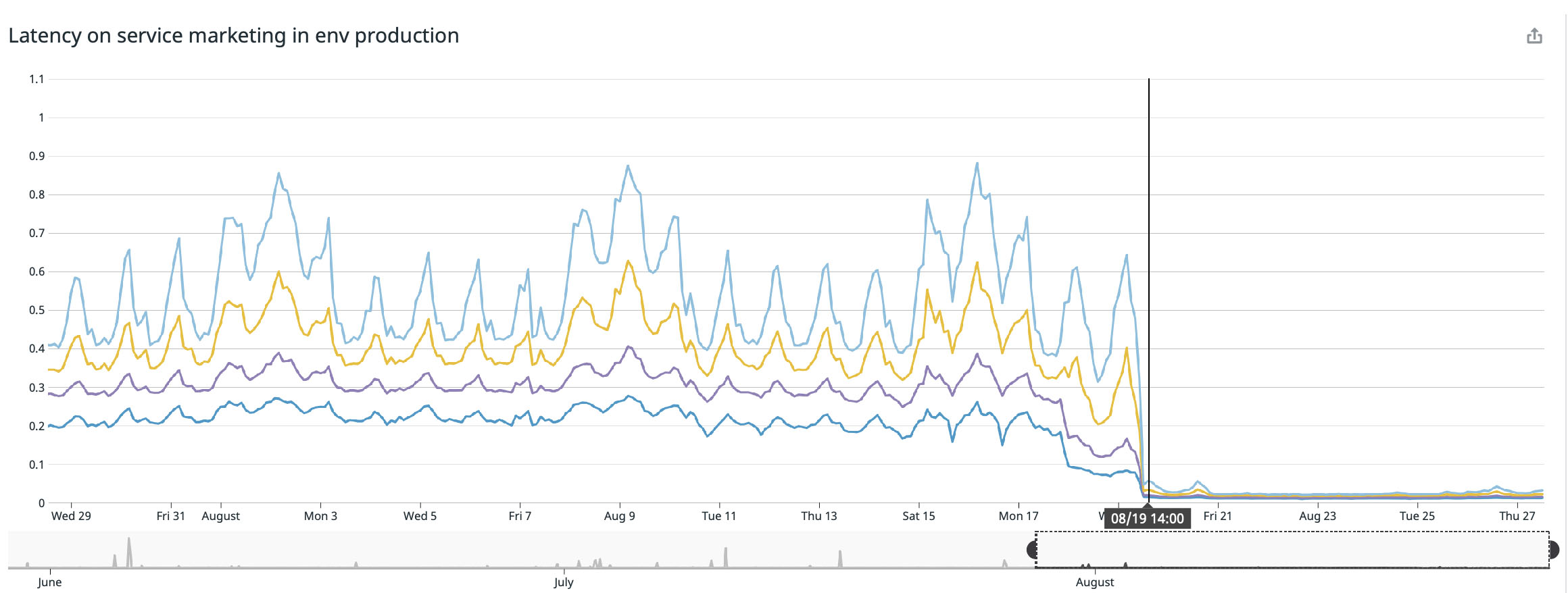
Nous avons obtenu le meilleur résultat sur notre page principale ( buffer.com ), là le service était vingt-deux fois plus rapide !
Le bogue du noyau Linux est-il corrigé?
Oui, le bogue a déjà été corrigé et le correctif a été ajouté au noyau des distributions version 4.19 et supérieures.
Cependant, en lisant le numéro de kubernetes sur github du 2 septembre 2020, nous rencontrons toujours des références à certains projets Linux avec un bogue similaire. Je crois que certaines distributions Linux ont toujours ce bogue et travaillent actuellement sur un correctif.
Si votre version de la distribution est inférieure à 4.19, je recommanderais la mise à jour vers la dernière version, mais vous devriez quand même essayer de supprimer les limites du processeur et voir si la limitation persiste. Vous trouverez ci-dessous une liste incomplète de la gestion des services Kubernetes et des distributions Linux:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
Et si le correctif résolvait le problème de limitation?
Je ne sais pas si le problème a été complètement résolu. Quand nous arriverons à la version fixe du noyau, je testerai le cluster et mettrai à jour la publication. Si quelqu'un a déjà mis à jour, j'aimerais revoir vos résultats avec intérêt.
Conclusion
- Si vous travaillez avec des conteneurs Docker sous Linux (peu importe Kubernetes, Mesos, Swarm ou autre), vos conteneurs peuvent perdre des performances en raison de la limitation;
- Essayez de mettre à jour vers la dernière version de votre distribution dans l'espoir que le bogue a déjà été corrigé;
- La suppression des limites du processeur résoudra le problème, mais c'est une technique dangereuse qui doit être utilisée avec une extrême prudence (il est préférable de mettre à jour le noyau d'abord et de comparer les résultats);
- Si vous avez supprimé les limites du processeur, surveillez attentivement l'utilisation de votre processeur et de la mémoire et assurez-vous que les ressources de votre processeur dépassent la consommation;
- Une option sûre serait de mettre à l'échelle automatiquement les pods pour créer de nouveaux pods en cas de charge élevée sur le matériel, afin que kubernetes les attribue à des nœuds libres.
J'espère que cet article vous aidera à améliorer les performances de vos systèmes de conteneurs.
PS Ici l' auteur est en correspondance avec des lecteurs et des commentateurs (en anglais).