... dans une requête bien conçue avec des conseils contextuels pour les nœuds de plan correspondants:

Dans cette transcription de la deuxième partie de mon discours à PGConf.Russia 2020, je vais vous dire comment nous avons réussi à faire cela.
La transcription de la première partie, qui traite des problèmes typiques de performance des requêtes et de leurs solutions, se trouve dans l'article «Recettes pour les requêtes SQL défaillantes» .
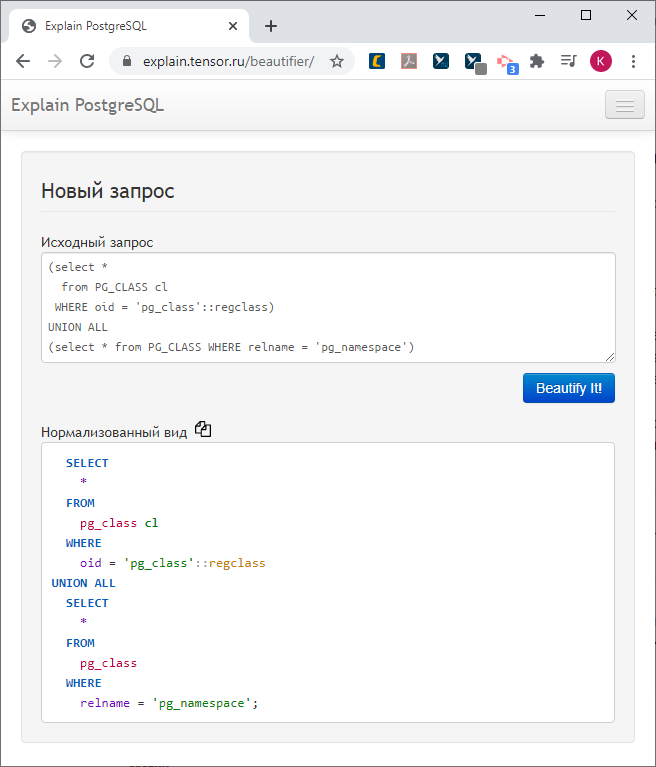
Tout d'abord, nous allons peindre - et nous ne peindrons plus le plan, nous l'avons déjà peint, nous l'avons déjà beau et compréhensible, mais une demande.
Il nous a semblé que la requête extraite du journal en utilisant une "feuille" non formatée semble très moche et donc peu pratique.

Surtout quand les développeurs dans le code "collent" le corps de la requête (c'est bien sûr un anti-pattern, mais ça arrive) sur une seule ligne. Horreur!
Dessinons-le en quelque sorte plus magnifiquement.
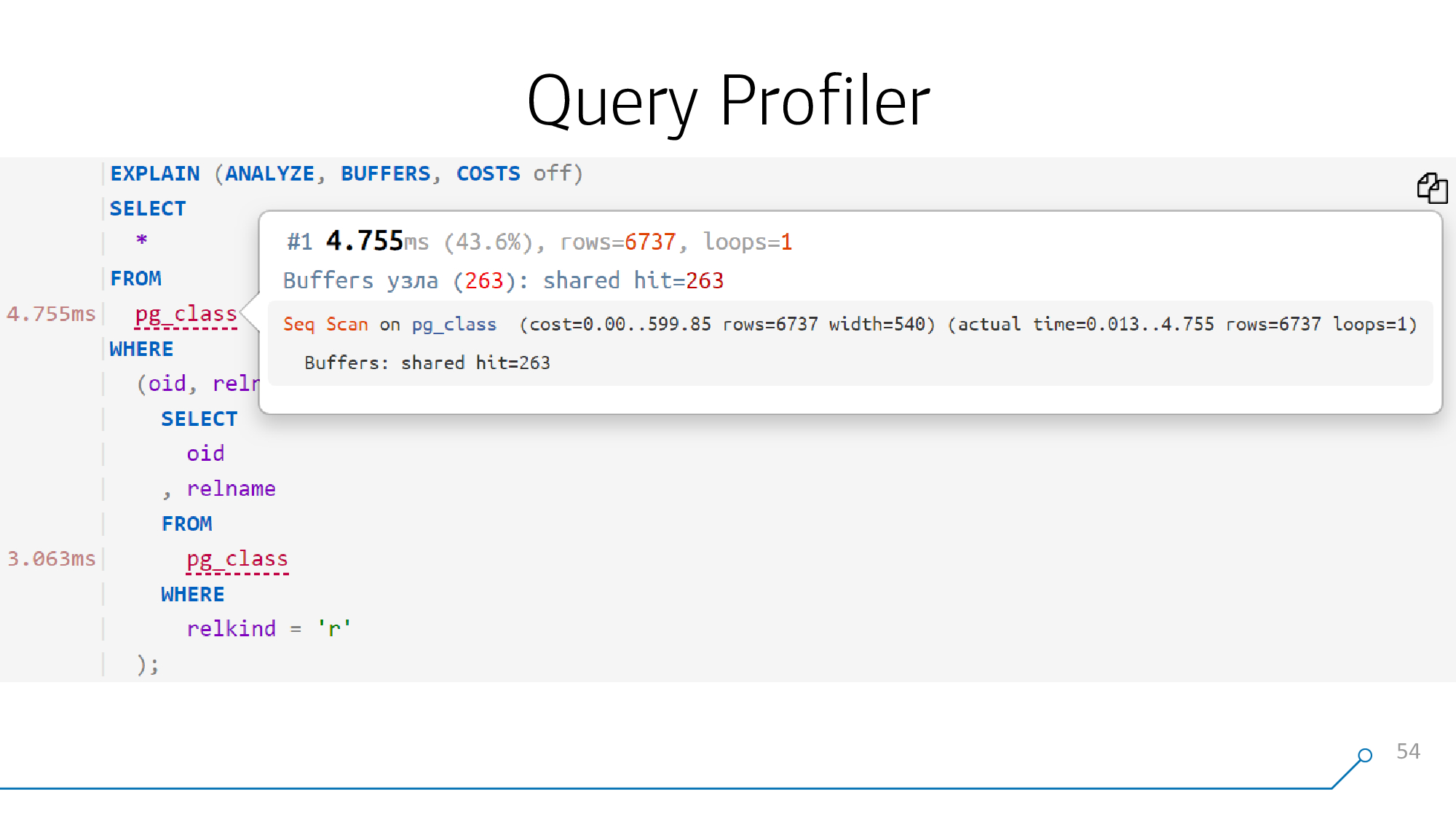
Et si nous pouvons le dessiner magnifiquement, c'est-à-dire démonter et remonter le corps de la requête, nous pouvons alors attacher un indice à chaque objet de cette requête - ce qui s'est passé au point correspondant du plan.
Arborescence de requêtes de syntaxe
Pour ce faire, la demande doit d'abord être analysée.
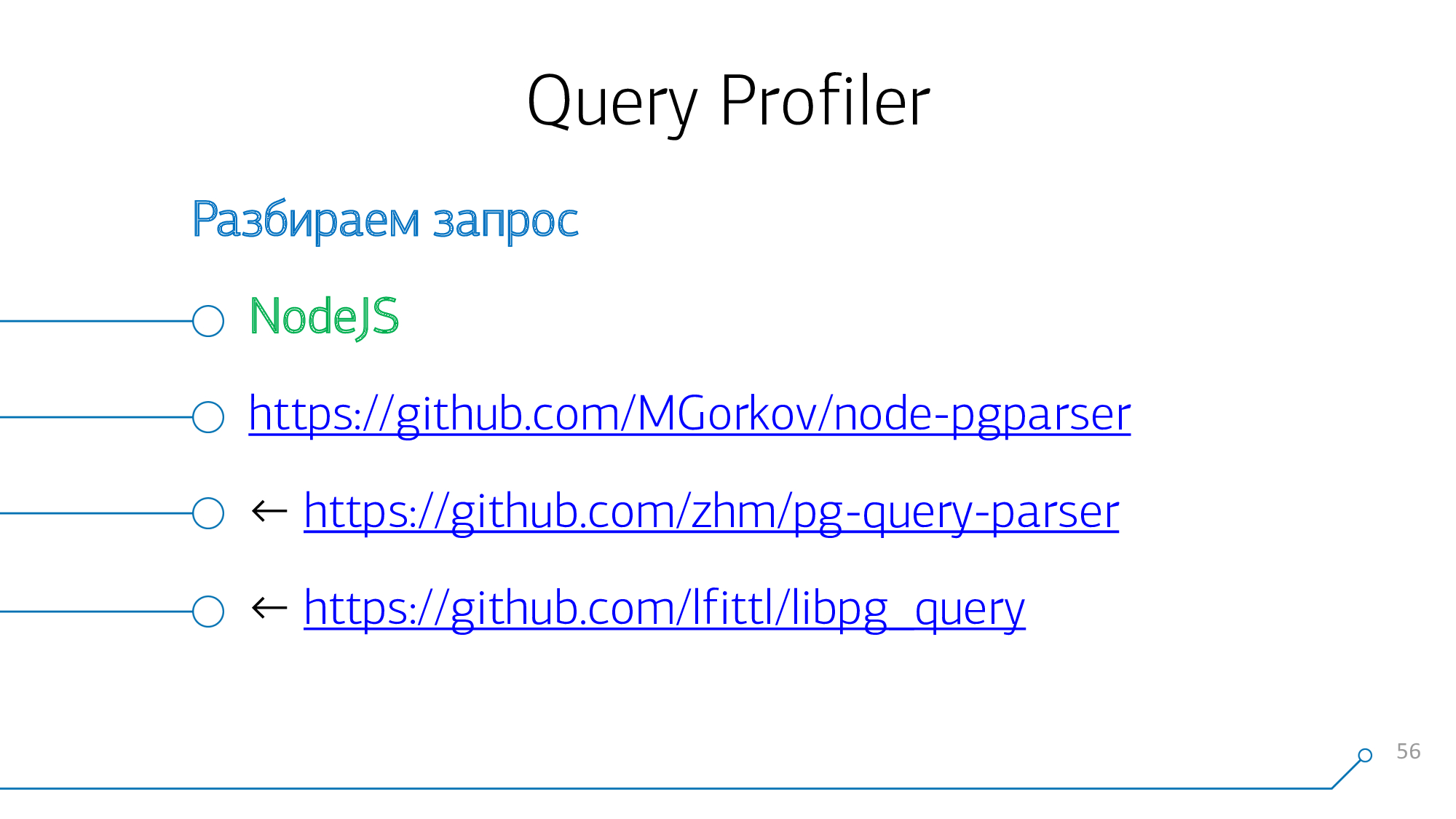
Étant donné que notre noyau système fonctionne sur NodeJS , nous avons créé des modules pour cela, vous pouvez le trouver sur GitHub . En fait, ce sont des "liaisons" étendues aux composants internes de l'analyseur PostgreSQL lui-même. Autrement dit, la grammaire est simplement compilée en binaire et des liaisons y sont effectuées du côté NodeJS. Nous avons pris les modules d'autres personnes comme base - il n'y a pas de grand secret ici.
Nous transmettons le corps de la requête à l'entrée de notre fonction - à la sortie, nous obtenons un arbre de syntaxe analysé sous la forme d'un objet JSON.

Vous pouvez maintenant parcourir cet arbre dans la direction opposée et collecter la requête avec les retraits, la coloration, la mise en forme que nous voulons. Non, ce n'est pas configurable, mais il nous a semblé que ce serait pratique.

Requête de mappage et nœuds de plan
Voyons maintenant comment nous pouvons combiner le plan que nous avons analysé dans la première étape et la requête que nous avons analysée dans la seconde.
Prenons un exemple simple - nous avons une requête qui génère un CTE et le lit deux fois. Il génère un tel plan.

CTE
Si vous regardez attentivement, avant la 12e version (ou à partir de celle-ci avec le mot-clé
MATERIALIZED), la formation de CTE est une barrière absolue pour le planificateur .
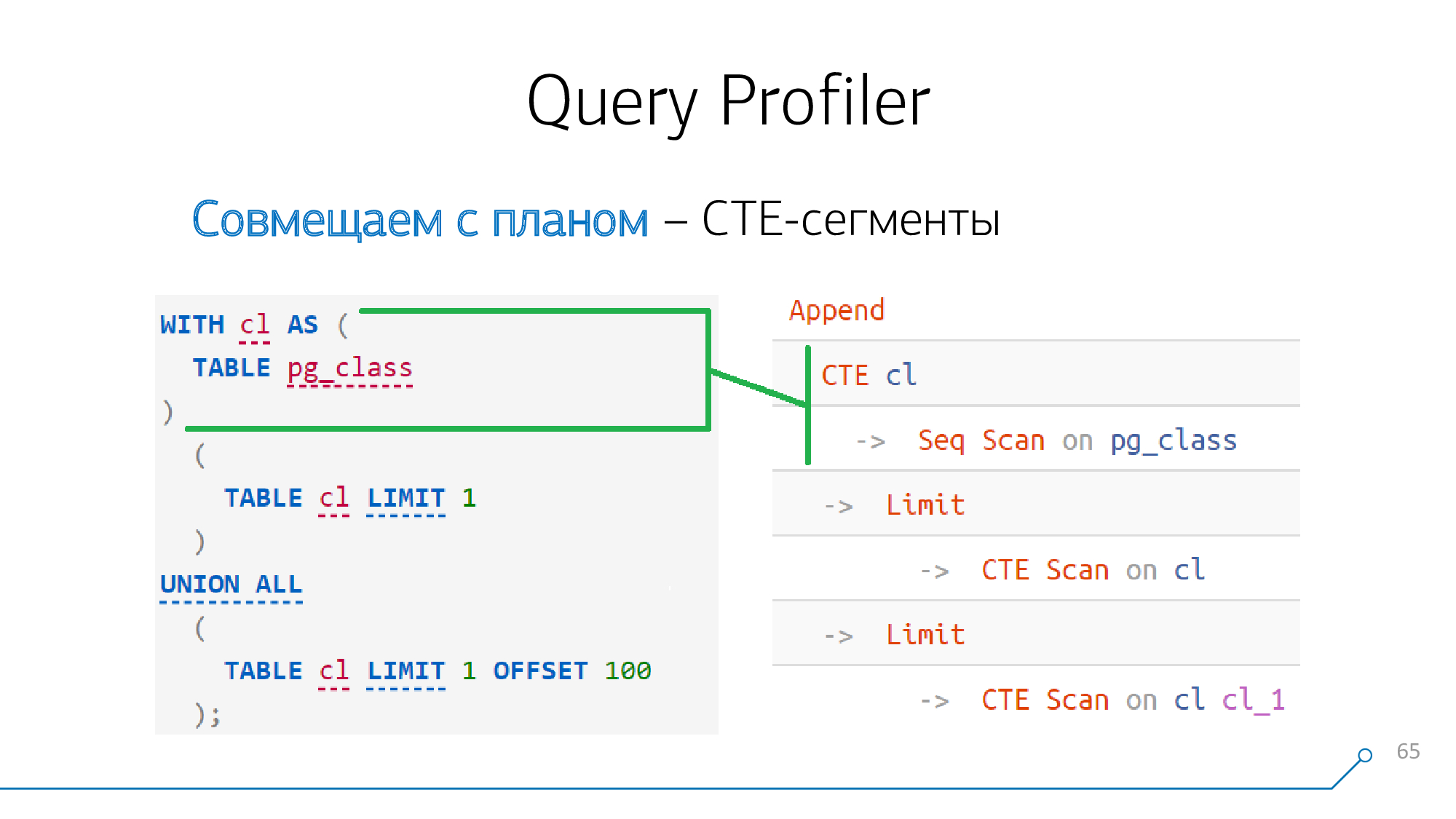
Cela signifie que si nous voyons la génération de CTE quelque part dans la requête et quelque part dans le plan un nœud
CTE, alors ces nœuds "se battent" définitivement les uns avec les autres, nous pouvons immédiatement les combiner.
Problème d'astérisque : les CTE peuvent être imbriqués.

Il y a très mal imbriqué, et même les mêmes noms. Par exemple, vous pouvez le
CTE Afaire à l' intérieur CTE X, et CTE Ble refaire au même niveau à l'intérieur CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...Vous devez comprendre cela lorsque vous comparez. Il est très difficile de comprendre cela avec des «yeux» - même en voyant le plan, voire en voyant le corps de la demande. Si votre génération CTE est complexe, imbriquée, les demandes sont volumineuses, alors elle est complètement inconsciente.
SYNDICAT
Si nous avons un mot-clé dans la requête
UNION [ALL](l'opérateur de jonction de deux sélections), alors soit un nœud Appendou un autre lui correspond dans le plan Recursive Union.

Ce qui est "au-dessus" est au-dessus
UNIONest le premier enfant de notre nœud, ce qui est "en dessous" est le second. Si UNIONplusieurs blocs sont "collés" à travers nous à la fois, il Appendn'y aura toujours qu'un seul nœud, mais il n'aura pas deux enfants, mais plusieurs - dans l'ordre au fur et à mesure, respectivement:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Problème "avec un astérisque" : à l'intérieur de la génération d'une sélection récursive (
WITH RECURSIVE), il peut aussi y en avoir plusieurs UNION. Mais seul le tout dernier bloc après le dernier est toujours récursif UNION. Tout ce qui précède est un mais différent UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...Vous devez également être capable de «coller» de tels exemples. Dans cet exemple, nous voyons qu'il
UNIONy avait 3 segments dans notre requête. En conséquence, l'un UNION correspond à un Append-node, et l'autre correspond à Recursive Union.

Données en lecture-écriture
Ça y est, on l'étale, maintenant on sait quelle partie de la demande correspond à quelle partie du plan. Et dans ces pièces, nous pouvons facilement et naturellement trouver ces objets qui sont «lisibles».
Du point de vue de la requête, on ne sait pas s'il s'agit d'une table ou d'un CTE, mais ils sont désignés par le même nœud
RangeVar. Et en termes de "lisible" - c'est aussi un ensemble assez limité de nœuds:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Nous connaissons la structure du plan et de la requête, nous connaissons la correspondance des blocs, nous connaissons les noms des objets - nous faisons une comparaison sans ambiguïté.

Encore une fois, un problème d'astérisque . Nous prenons la requête, l'exécutons, nous n'avons pas d'alias - nous la lisons juste deux fois à partir d'un CTE.

Nous regardons le plan - quel est le problème? Pourquoi notre pseudonyme est-il sorti? Nous ne l'avons pas commandé. Pourquoi est-il si "numéroté"?
PostgreSQL l'ajoute lui-même. Vous avez juste besoin de comprendre qu'un tel alias n'a aucun sens pour nous à des fins de comparaison avec le plan, il est simplement ajouté ici. Ne faisons pas attention à lui.
La deuxième tâche est "avec un astérisque" : si nous lisons à partir d'une table partitionnée, alors nous obtiendrons un nœud
AppendouMerge Append, Qui se composera d'un grand nombre de « enfants », et dont chacun est en quelque sorte Scan« e de la section de la table: Seq Scan, Bitmap Heap Scanou Index Scan. Mais, dans tous les cas, ces "enfants" ne seront pas des requêtes complexes - c'est ainsi que ces nœuds peuvent être distingués de Appendquand UNION.

Nous comprenons également ces nœuds, nous les rassemblons «en une seule pile» et disons: « tout ce que vous lisez à partir de mégatable est ici et en bas de l'arbre ».
Nœuds "simples" pour recevoir des données

Values Scandans le plan correspond VALUESà la demande.
Result- c'est une demande sans FROMpareil SELECT 1. Ou lorsque vous avez une expression sciemment fausse dans le WHERE-bloc (alors l'attribut se produit One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan"Mapper" à la SRF du même nom.
Mais avec les requêtes imbriquées, tout est plus compliqué - malheureusement, elles ne se transforment pas toujours en
InitPlan/ SubPlan. Parfois, ils se transforment en ... Joinou ... Anti Join, surtout lorsque vous écrivez quelque chose comme WHERE NOT EXISTS .... Et il n'est pas toujours possible de combiner là-bas - il n'y a pas d'opérateurs correspondant aux nœuds du plan dans le texte du plan.
Encore une fois, une tâche avec un astérisque : plusieurs
VALUESdans la requête. Dans ce cas et dans le plan, vous recevrez plusieurs nœuds Values Scan.

Les suffixes "numérotés" aideront à les distinguer les uns des autres - ils sont ajoutés exactement dans l'ordre de recherche des
VALUESblocs correspondants le long de la requête de haut en bas.
Traitement de l'information
Il semble que tout dans notre demande a été réglé - il ne reste que
Limit.
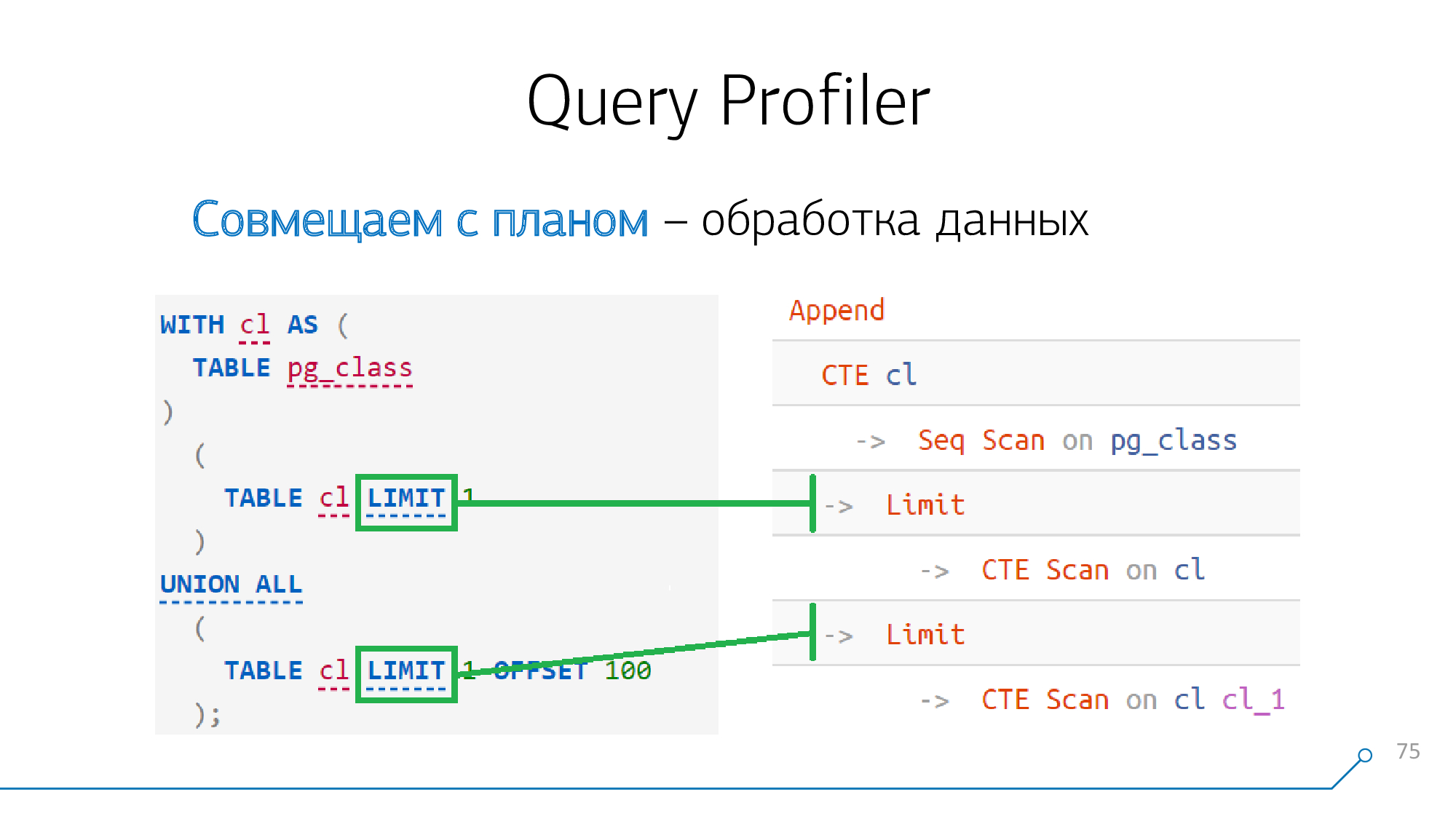
Mais tout est simple - comme les noeuds
Limit, Sort, Aggregate, WindowAgg, Unique« mapyatsya » one-to-one aux déclarations correspondantes dans la demande, si elles sont là. Il n'y a pas de "stars" et pas de difficultés.

JOINDRE
Des difficultés surviennent lorsque nous voulons combiner les
JOINuns avec les autres. Ce n'est pas toujours fait, mais vous le pouvez.

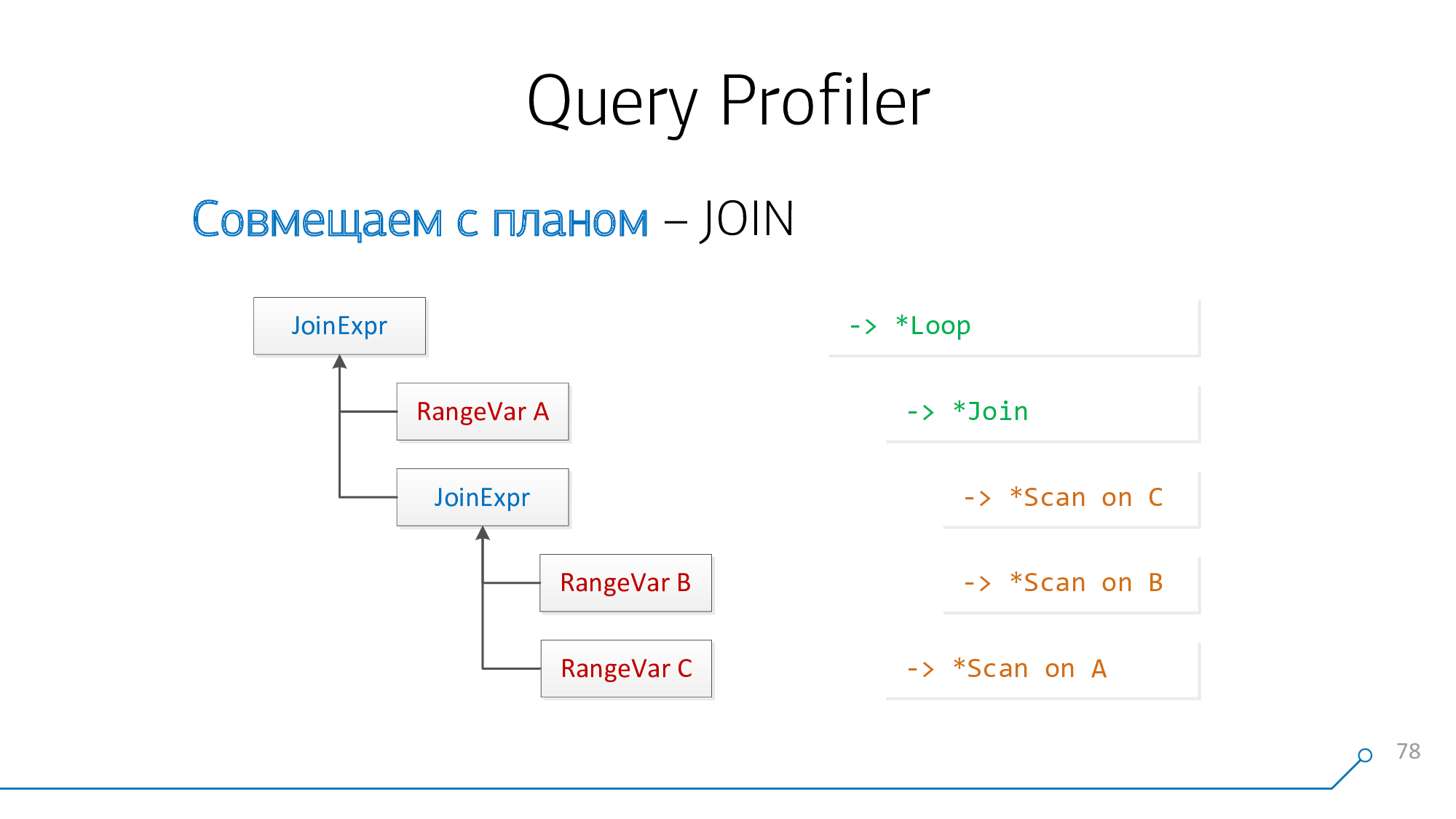
Du point de vue de l'analyseur de requêtes, nous avons un nœud
JoinExprqui a exactement deux enfants - gauche et droite. Ceci, respectivement, est ce qui est "au-dessus" de votre JOIN et ce qui est "sous" dans la requête est écrit.
Et du point de vue du plan, ce sont deux descendants de certains
* Loop/ * Join-node. Nested Loop, Hash Anti Join... - c'est quelque chose.
Utilisons une logique simple: si nous avons des plaques A et B qui "se rejoignent" dans le plan, alors dans la requête elles pourraient être localisées soit
A-JOIN-Bou B-JOIN-A. Essayons de le combiner de cette façon, essayons de le combiner dans l'autre sens, et ainsi de suite jusqu'à ce que ces paires soient épuisées.
Prenez notre arbre de syntaxe, prenez notre aperçu, regardez-les ... ça ne lui ressemble pas!
Redessinons-le sous forme de graphiques - oh, c'est déjà devenu quelque chose comme quelque chose!
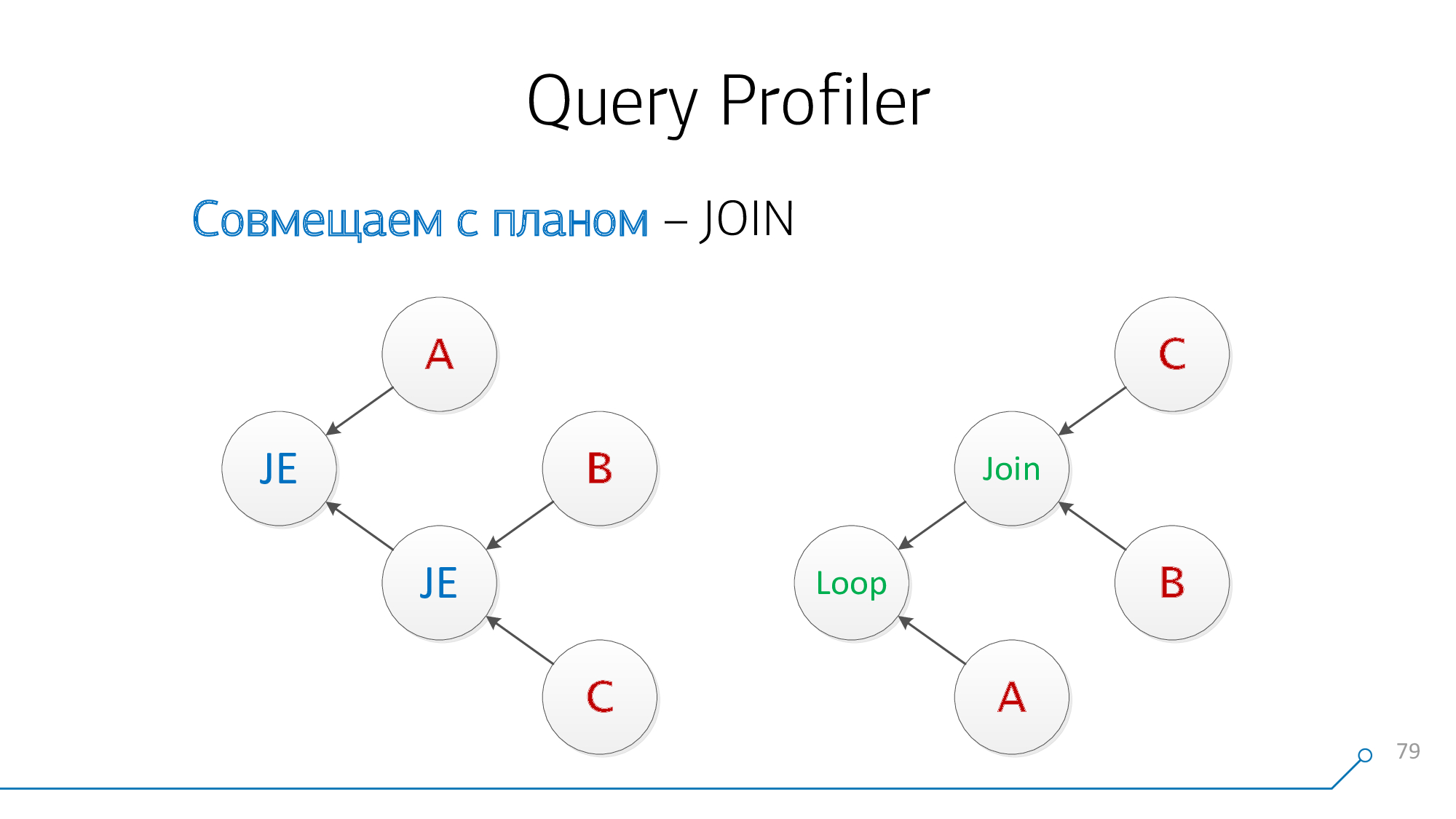
Remarquons que nous avons des nœuds qui ont des enfants B et C en même temps - peu importe dans quel ordre. Combinons-les et retournons l'image du nœud.

Voyons cela à nouveau. Maintenant, nous avons des nœuds avec des enfants A et des paires (B + C) - compatibles avec eux aussi.
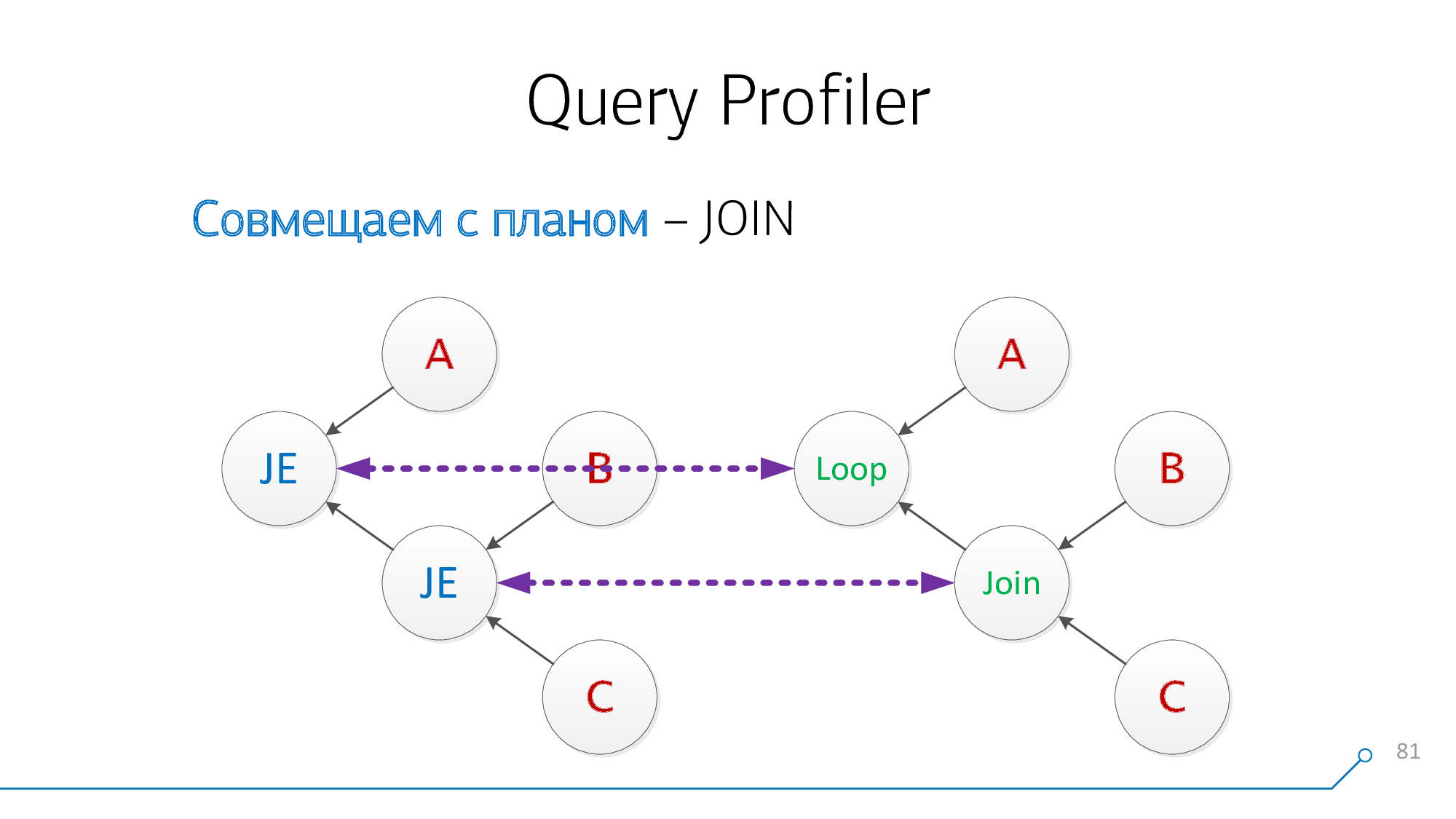
Excellent! Il s'avère que nous avons
JOINréussi à combiner ces deux éléments de la requête avec les nœuds du plan.
Hélas, cette tâche n'est pas toujours résolue.
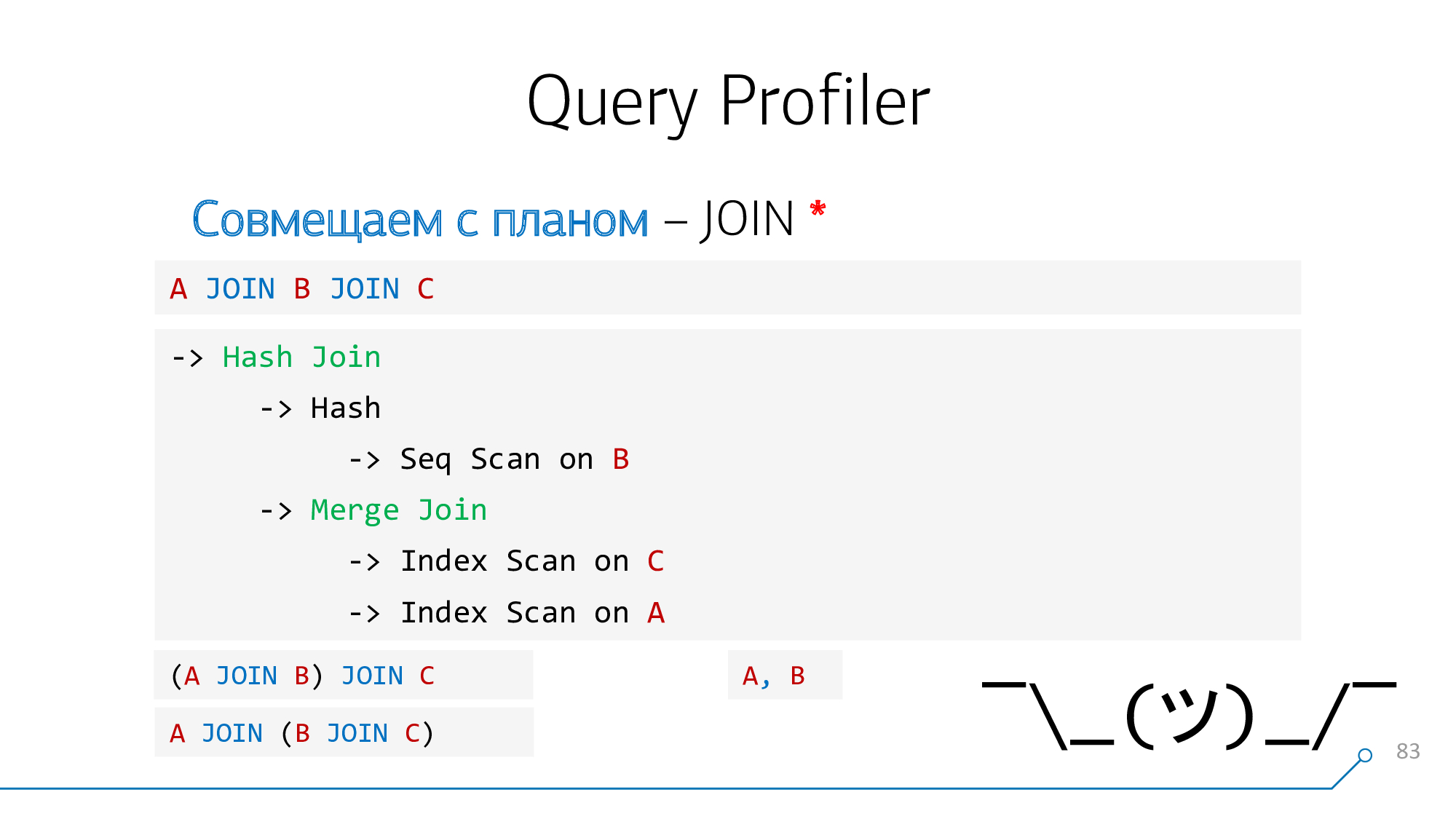
Par exemple, si dans la requête
A JOIN B JOIN C, mais dans le plan, les nœuds "extrêmes" A et C étaient connectés en premier. Et dans la requête, il n'y a pas d'opérateur de ce type, nous n'avons rien à mettre en évidence, il n'y a rien auquel lier l'indication. C'est la même chose avec la "virgule" lorsque vous écrivez A, B.
Mais, dans la plupart des cas, presque tous les nœuds peuvent être «déliés» et vous obtenez ce type de profilage à gauche dans le temps - littéralement, comme dans Google Chrome, lorsque vous analysez le code JavaScript. Vous pouvez voir combien de temps chaque ligne et chaque instruction ont été "exécutées".

Et pour que vous puissiez utiliser tout cela plus facilement, nous avons créé un stockage d' archives , dans lequel vous pouvez enregistrer puis retrouver vos plans avec les demandes associées ou partager un lien avec quelqu'un.
Si vous avez juste besoin de mettre une requête illisible sous une forme adéquate, utilisez notre "normalisateur" .