Le fait est que toutes nos équipes sont construites autour de systèmes d'information, de microservices et de fronts séparés, de sorte que les équipes ne voient pas la santé globale de l'ensemble du système dans son ensemble. Par exemple, ils peuvent ne pas savoir comment une petite partie du backend profond affecte le front-end. L'éventail de leurs intérêts se limite aux systèmes avec lesquels leur système est intégré. Si l'équipe et son service A n'ont presque rien à voir avec le service B, alors un tel service est presque invisible pour l'équipe.
Notre équipe, quant à elle, travaille avec des systèmes qui sont très fortement intégrés les uns aux autres: il y a beaucoup de connexions entre eux, c'est une très grande infrastructure. Et le travail de la boutique en ligne dépend de tous ces systèmes (dont, d'ailleurs, nous en avons un grand nombre).
Il s'avère donc que notre département n'appartient à aucune équipe, mais est un peu distant. Dans toute cette histoire, notre tâche est de comprendre de manière complexe le fonctionnement des systèmes d'information, leurs fonctionnalités, leurs intégrations, les logiciels, le réseau, le matériel et comment tout cela est interconnecté.
La plateforme sur laquelle nos boutiques en ligne opèrent ressemble à ceci:
- de face
- middle-office
- back-office
Autant que nous le souhaiterions, mais il n'y a pas de telle chose que tous les systèmes fonctionnent correctement et sans problème. Le point, encore une fois, est le nombre de systèmes et d'intégrations - avec ce que nous avons, certains incidents sont inévitables, malgré la qualité des tests. De plus, à la fois dans un système séparé et en termes d'intégration. Et vous devez surveiller l'état de l'ensemble de la plate-forme de manière complète, et non d'une partie séparée de celle-ci.
Idéalement, la surveillance de l'état de santé de l'ensemble de la plate-forme devrait être automatisée. Et nous sommes arrivés à la surveillance comme une partie inévitable de ce processus. Initialement, il était construit uniquement pour la partie avant, tandis que les administrateurs réseau, logiciels et matériels avaient leurs propres systèmes de surveillance par couches. Toutes ces personnes n'ont suivi le suivi qu'à leur propre niveau; personne n'avait non plus une compréhension globale.
Par exemple, si une machine virtuelle tombe en panne, dans la plupart des cas, seul l'administrateur responsable du matériel et de la machine virtuelle en a connaissance. Dans de tels cas, l'équipe frontale a vu le fait même du crash de l'application, mais elle n'avait aucune donnée sur le crash de la machine virtuelle. Et l'administrateur peut savoir qui est le client et imaginer à peu près ce qui est en cours d'exécution sur cette machine virtuelle en ce moment, à condition qu'il s'agisse d'une sorte de grand projet. Il ne sait probablement pas pour les petits. Dans tous les cas, l'administrateur doit aller chez le propriétaire, lui demander ce qu'il y avait sur cette machine, ce qui doit être restauré et ce qu'il faut changer. Et si quelque chose de très grave tombait en panne, ils se mettaient à tourner en rond - parce que personne ne voyait le système dans son ensemble.
En fin de compte, ces histoires disparates affectent l'ensemble du front-end, les utilisateurs et notre principale fonction commerciale, les ventes en ligne. Comme nous ne faisons pas partie d'une équipe, mais que nous sommes engagés dans l'exploitation de toutes les applications de commerce électronique dans le cadre d'une boutique en ligne, nous avons pris la tâche de créer un système de surveillance complet pour la plate-forme de commerce électronique.
Structure et pile du système
Nous avons commencé par identifier plusieurs couches de surveillance pour nos systèmes, dans le cadre desquelles nous devons collecter des métriques. Et tout cela devait être combiné, ce que nous avons fait lors de la première étape. À ce stade, nous finalisons maintenant la collection de mesures de la plus haute qualité pour toutes nos couches afin de construire une corrélation et de comprendre comment les systèmes s'influencent mutuellement.
L'absence de suivi complet aux premiers stades du lancement de l'application (depuis que nous avons commencé à la construire alors que la plupart des systèmes étaient en fonctionnement) nous a conduit au fait que nous avions une dette technique importante pour mettre en place un suivi de l'ensemble de la plateforme. Nous ne pouvions pas nous permettre de nous concentrer sur la mise en place de la surveillance d'un seul SI et d'en élaborer une surveillance en détail, car le reste des systèmes serait resté sans surveillance pendant un certain temps. Pour résoudre ce problème, nous avons identifié une liste des métriques les plus nécessaires pour évaluer l'état du système d'information par couches et avons commencé à l'implémenter.
Par conséquent, ils ont décidé de manger l'éléphant par parties.
Notre système se compose de:
- Matériel;
- système opérateur;
- Logiciel;
- Parties de l'interface utilisateur dans l'application de surveillance;
- mesures commerciales;
- applications d'intégration;
- sécurité de l'information;
- les réseaux;
- équilibreur de trafic.
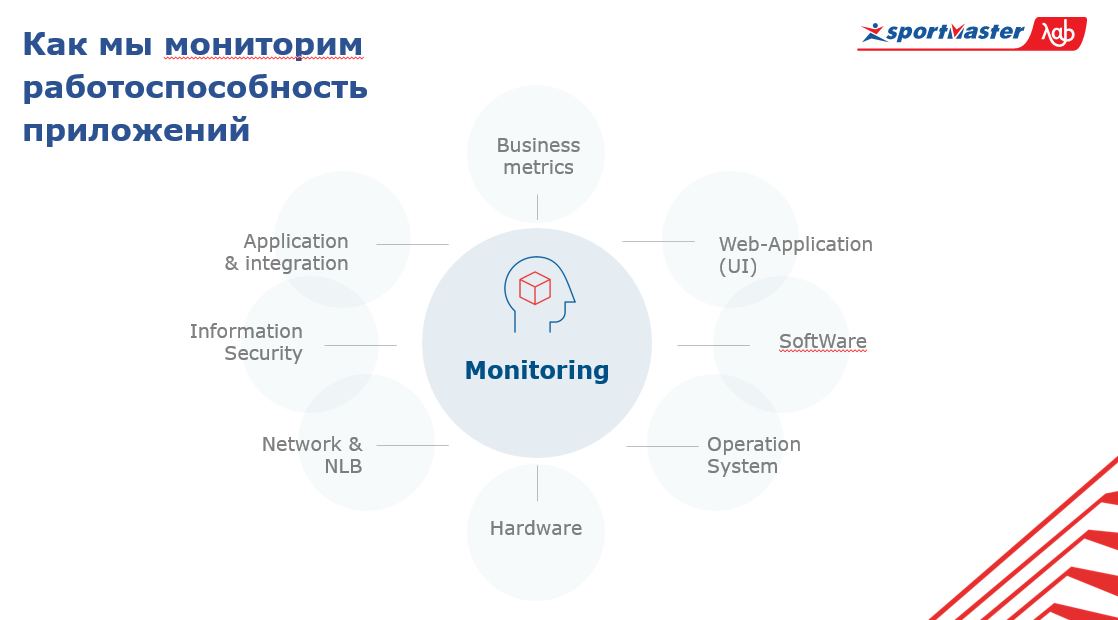
Au centre de ce système se surveille lui-même. Afin de comprendre de manière générale l'état de l'ensemble du système, vous devez savoir ce qui se passe avec les applications sur toutes ces couches et dans le contexte de l'ensemble des applications.
Donc, à propos de la pile.

Nous utilisons des logiciels open source. Au centre, nous avons Zabbix, que nous utilisons principalement comme système d'alerte. Tout le monde sait qu'il est idéal pour surveiller les infrastructures. Qu'est-ce que ça veut dire? Ce sont les mesures de bas niveau dont dispose chaque entreprise qui possède son propre centre de données (et Sportmaster a ses propres centres de données) - température du serveur, état de la mémoire, raid, mesures des périphériques réseau.
Nous avons intégré Zabbix avec Telegram Messenger et Microsoft Teams, qui sont activement utilisés en équipe. Zabbix couvre la couche du réseau réel, du matériel et partiellement des logiciels, mais ce n'est pas une panacée. Nous enrichissons ces données à partir de certains autres services. Par exemple, en termes de niveau matériel, nous nous connectons directement via l'API à notre système de virtualisation et collectons des données.
Quoi d'autre. En plus de Zabbix, nous utilisons Prometheus, qui permet de surveiller les métriques dans une application d'environnement dynamique. Autrement dit, nous pouvons recevoir des métriques d'application via le point de terminaison HTTP et ne pas nous soucier des métriques à charger ou non. Sur la base de ces données, vous pouvez élaborer des requêtes analytiques.
Les sources de données pour d'autres couches, par exemple les métriques métier, sont divisées en trois composants.
Premièrement, ce sont des systèmes commerciaux externes, Google Analytics, nous collectons des métriques à partir de journaux. D'eux, nous obtenons des données sur les utilisateurs actifs, les conversions et tout ce qui concerne l'entreprise. Deuxièmement, il s'agit d'un système de surveillance de l'interface utilisateur. Il devrait être discuté plus en détail.
Il était une fois, nous avons commencé avec des tests manuels, et cela a évolué vers des tests automatiques fonctionnels et d'intégration. Nous en avons fait la surveillance, ne laissant que la fonctionnalité principale, et liés à des marqueurs aussi stables que possible et qui ne changent pas souvent avec le temps.
La nouvelle structure d'équipe implique que toute l'activité applicative est verrouillée dans les équipes produit, nous avons donc arrêté de faire des tests purs. Au lieu de cela, nous avons fait une surveillance de l'interface utilisateur à partir de tests, écrits en Java, Selenium et Jenkins (utilisés comme système pour lancer et générer des rapports).
Nous avons fait beaucoup de tests, mais finalement nous avons décidé de passer à la route principale, la métrique de haut niveau. Et si nous avons beaucoup de tests spécifiques, il sera difficile de maintenir les données à jour. Chaque version ultérieure cassera considérablement l'ensemble du système, et nous ne ferons que le réparer. Par conséquent, nous nous sommes attachés à des choses très fondamentales qui changent rarement et nous ne faisons que les surveiller.
Enfin, troisièmement, la source de données est un système de journalisation centralisé. Pour les journaux, nous utilisons Elastic Stack, puis nous pouvons faire glisser ces données dans notre système de surveillance pour les métriques commerciales. En plus de tout cela, notre propre service d'API de surveillance, écrit en Python, fonctionne, qui interroge tous les services via l'API et en transfère les données à Zabbix.
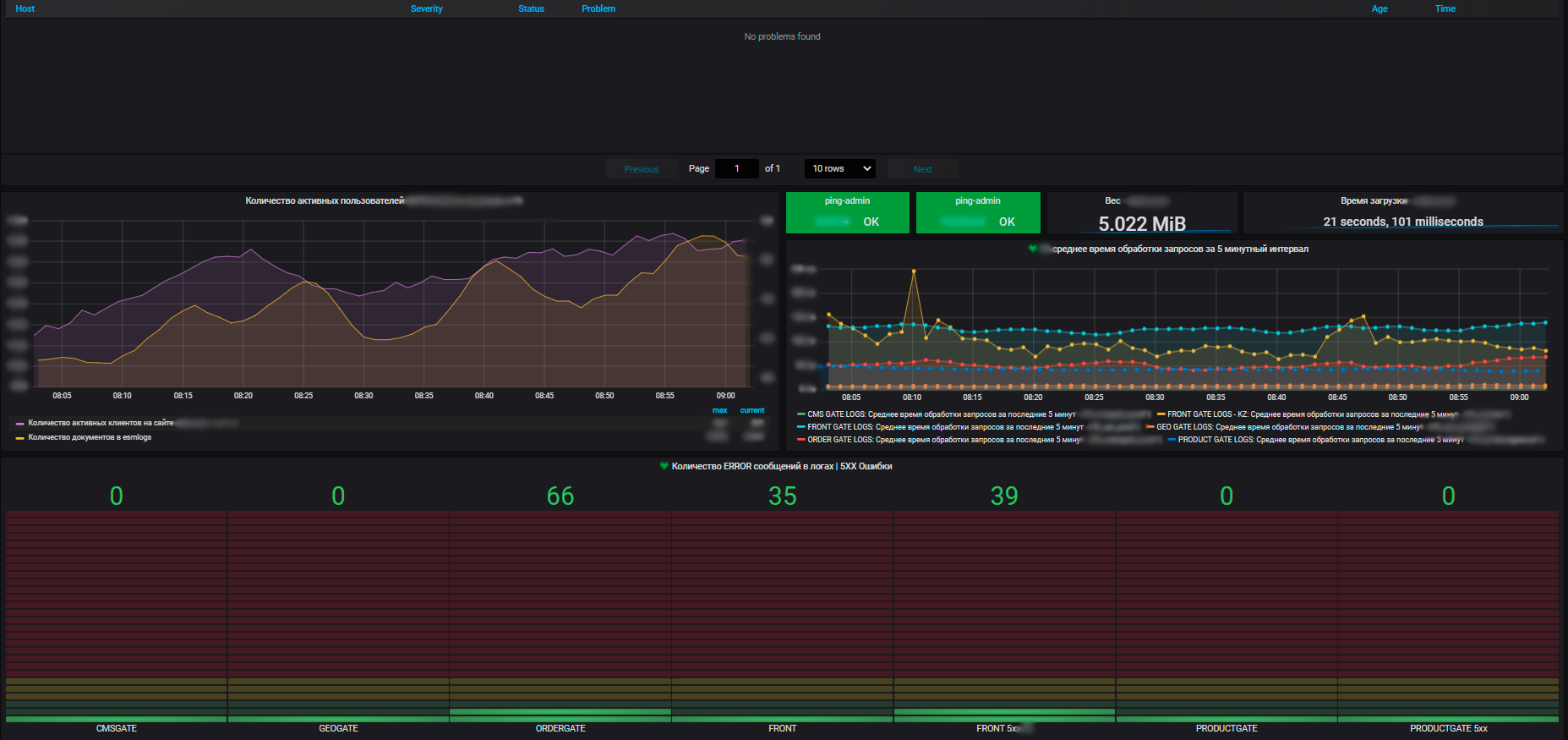
La visualisation est un autre attribut irremplaçable de la surveillance. Nous le construisons sur la base de Grafana. Parmi les autres systèmes de visualisation, il se distingue en ce qu'il est possible de visualiser les métriques de différentes sources de données sur le tableau de bord. Nous pouvons collecter les métriques de haut niveau de la boutique en ligne, par exemple, le nombre de commandes passées dans la dernière heure à partir du SGBD, les métriques de performance du système d'exploitation sur lequel cette boutique en ligne s'exécute depuis Zabbix et les métriques des instances de cette application de Prometheus. Et tout cela sera sur un tableau de bord. Visuel et accessible.
Permettez-moi de mentionner la sécurité - nous sommes en train de finaliser le système, que nous intégrerons par la suite au système mondial de surveillance. À mon avis, les principaux problèmes rencontrés par le commerce électronique dans le domaine de la sécurité de l'information sont liés aux bots, aux analyseurs et à la force brute. Cela doit être surveillé car ils peuvent tous affecter de manière critique à la fois les performances de nos applications et la réputation d'un point de vue commercial. Et nous couvrons avec succès ces tâches avec la pile choisie.
Un autre point important est que la couche application est collectée par Prometheus. Lui-même est également intégré à Zabbix. Et nous avons également sitespeed, un service qui nous permet de regarder en conséquence des paramètres tels que la vitesse de chargement de notre page, les goulots d'étranglement, le rendu des pages, le chargement des scripts, etc., il est également intégré via l'API. Ainsi, les métriques sont collectées dans Zabbix, respectivement, nous alertons également à partir de là. Toutes les alertes jusqu'à présent concernent les principales méthodes d'envoi (pour l'instant, ce sont les e-mails et les télégrammes, ils ont récemment connecté MS Teams). Il est prévu de transmettre l'alerte à un état tel que les robots intelligents fonctionnent comme un service et fournissent des informations de surveillance à toutes les équipes de produits intéressées.
Pour nous, non seulement les métriques des systèmes d'information individuels sont importantes, mais également les métriques générales pour toute l'infrastructure utilisée par les applications: clusters de serveurs physiques exécutant des machines virtuelles, équilibreurs de trafic, équilibreurs de charge réseau, le réseau lui-même, utilisation des canaux de communication. Plus des métriques pour nos propres centres de données (nous en avons plusieurs et l'infrastructure est assez importante).
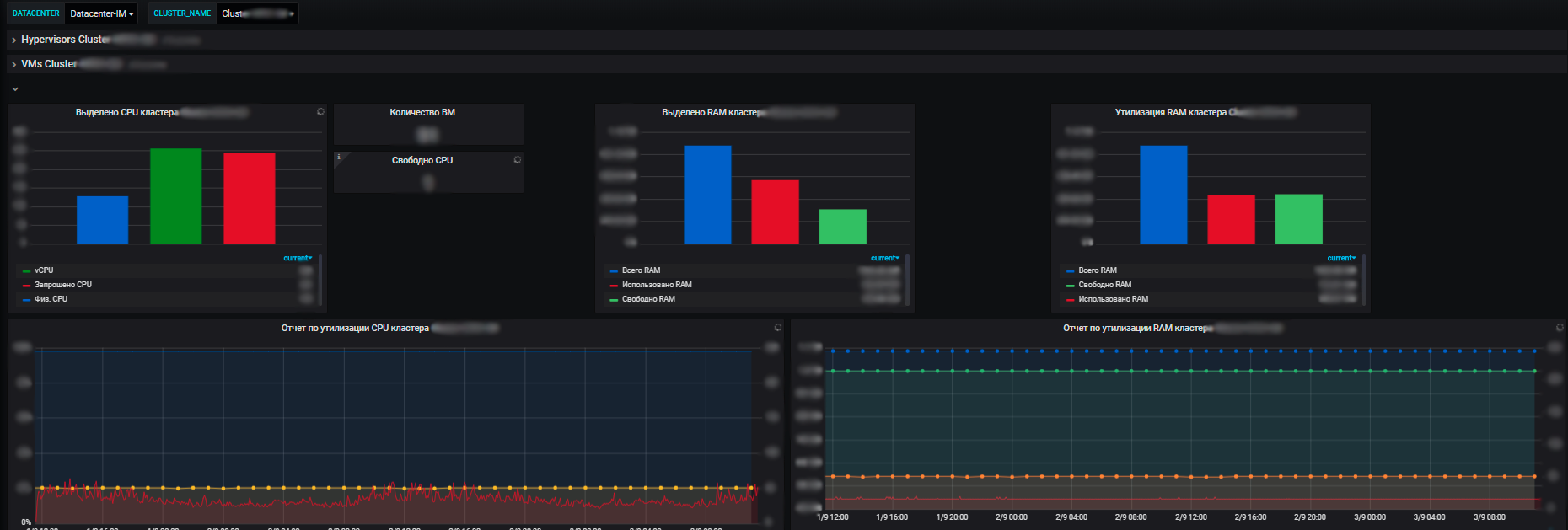
Les avantages de notre système de surveillance sont qu'avec son aide, nous pouvons voir l'état de santé de tous les systèmes, nous pouvons évaluer leur impact les uns sur les autres et sur les ressources communes. Et finalement, cela permet la planification des ressources, qui est également de notre responsabilité. Nous gérons les ressources du serveur - un pool dans le cadre du commerce électronique, introduisons et mettons hors service de nouveaux équipements, achetons de nouveaux équipements, effectuons un audit de l'utilisation des ressources, etc. Chaque année, les équipes planifient de nouveaux projets, développent leurs systèmes et il est important pour nous de leur fournir des ressources.
Et à l'aide de métriques, nous voyons la tendance de la consommation de ressources par nos systèmes d'information. Et déjà sur leur base, nous pouvons planifier quelque chose. Au niveau de la virtualisation, nous collectons des données et voyons des informations sur la quantité de ressources disponibles dans le contexte des centres de données. Et déjà à l'intérieur du centre de données, vous pouvez voir l'utilisation et la distribution réelle, la consommation des ressources. De plus, à la fois avec des serveurs autonomes et des machines virtuelles et des clusters de serveurs physiques, sur lesquels toutes ces machines virtuelles tournent vigoureusement.
Points de vue
Nous avons maintenant le cœur du système dans son ensemble prêt, mais il reste encore suffisamment de points sur lesquels travailler. Au moins, il s'agit d'une couche de sécurité de l'information, mais il est également important d'accéder au réseau, de développer des alertes et de résoudre le problème de corrélation. Nous avons beaucoup de couches et de systèmes, il y a beaucoup plus de métriques sur chaque couche. Il s'avère une matriochka au degré d'une matriochka.
Notre tâche est finalement de faire les bonnes alertes. Par exemple, s'il y avait un problème avec le matériel, encore une fois, avec une machine virtuelle, et il y avait une application importante, et le service n'a été sauvegardé d'aucune façon. Nous découvrons que la machine virtuelle est morte. Ensuite, ils alerteront les métriques métier: les utilisateurs ont disparu quelque part, il n'y a pas de conversion, l'interface utilisateur de l'interface n'est pas disponible, les logiciels et les services sont également morts.
Dans cette situation, nous recevrons du spam d'alertes, et cela ne correspond plus au format d'un système de surveillance correct. La question de la corrélation se pose. Par conséquent, idéalement, notre système de surveillance devrait dire: "Les gars, votre machine physique est morte, et avec elle cette application et ces métriques", avec l'aide d'une alerte au lieu de nous bombarder furieusement avec une centaine d'alertes. Elle doit signaler l'essentiel - la raison, qui contribue à la rapidité de l'élimination du problème en raison de sa localisation.
Notre système de notification et de gestion des alertes est construit autour d'un service de hotline 24/7. Toutes les alertes considérées comme incontournables pour nous et incluses dans la liste de contrôle y sont envoyées. Chaque alerte doit avoir une description: ce qui s'est passé, ce qu'elle signifie réellement, ce qu'elle affecte. Et aussi un lien vers le tableau de bord et des instructions sur ce qu'il faut faire dans ce cas.
C'est tout pour les exigences de construction de l'alerte. En outre, la situation peut évoluer dans deux directions - soit il y a un problème et il doit être résolu, soit il y a eu une défaillance du système de surveillance. Mais dans tous les cas, vous devez aller le découvrir.
En moyenne, une centaine d'alertes nous tombent aujourd'hui par jour, ceci compte tenu du fait que la corrélation des alertes n'a pas encore été correctement configurée. Et si nous devons effectuer un travail technique et que nous éteignons quelque chose de force, leur nombre augmente considérablement.
En plus de surveiller les systèmes que nous exploitons et de collecter des métriques jugées importantes de notre côté, le système de surveillance nous permet de collecter des données pour les équipes produits. Ils peuvent influencer la composition des métriques au sein des systèmes d'information surveillés ici.
Notre collègue peut venir demander d'ajouter une métrique qui sera utile pour nous et pour l'équipe. Ou, par exemple, l'équipe peut ne pas avoir suffisamment de mesures de base dont nous disposons, elle doit en suivre une spécifique. Dans Grafana, nous créons un espace pour chaque équipe et émettons des droits d'administrateur. Aussi, si une équipe a besoin de tableaux de bord, mais qu'elle ne sait pas / ne sait pas comment le faire, nous les aidons.
Comme nous sommes en dehors du flux de la création de valeur d'équipe, de leurs versions et de leur planification, nous arrivons progressivement à la conclusion que les versions de tous les systèmes sont transparentes et peuvent être déployées quotidiennement, sans coordination avec nous. Et il est important pour nous de suivre ces versions, car elles peuvent potentiellement affecter le fonctionnement de l'application et casser quelque chose, ce qui est essentiel. Pour gérer les versions, nous utilisons Bamboo, d'où nous obtenons des données via l'API et pouvons voir quelles versions de quels systèmes d'information sont sortis et leur statut. Et le plus important est à quelle heure. Nous mettons des marqueurs de publication sur les principales métriques critiques, ce qui est visuellement très indicatif en cas de problème.
De cette façon, nous pouvons voir la corrélation entre les nouvelles versions et les problèmes émergents. L'idée principale est de comprendre comment le système fonctionne sur toutes les couches, de localiser rapidement le problème et de le résoudre tout aussi rapidement. En effet, il arrive souvent que le plus de temps soit passé non pas à résoudre le problème, mais à en trouver la cause.
Et dans cette direction à l'avenir, nous voulons nous concentrer sur la proactivité. Idéalement, je voudrais connaître à l'avance un problème imminent, et non après coup, afin de traiter de sa prévention, pas d'une solution. Parfois, de fausses alarmes du système de surveillance se produisent, à la fois en raison d'une erreur humaine et en raison de changements dans l'application. Et nous y travaillons, débogage, et avant toute manipulation sur le système de surveillance, avertissons les utilisateurs qui l'utilisent avec nous à ce sujet. , ou effectuez ces événements dans la fenêtre technique.
Ainsi, le système a été lancé et fonctionne avec succès depuis le début du printemps ... et montre un bénéfice très réel. Bien sûr, ce n'est pas sa version finale, nous allons introduire de nombreuses autres fonctionnalités utiles. Mais à l'heure actuelle, avec autant d'intégrations et d'applications, l'automatisation de la surveillance est vraiment indispensable.
Si vous surveillez également de grands projets avec un nombre important d'intégrations, écrivez dans les commentaires la solution miracle que vous avez trouvée pour cela.