 Bonjour les Habitants! Le livre Site Reliability Engineering a suscité une discussion animée. Qu'est-ce qui est opérationnel aujourd'hui et pourquoi les questions de fiabilité sont-elles si fondamentales? Désormais, les ingénieurs de Google à l'origine de ce livre à succès proposent de passer de la théorie à la pratique - le classeur de fiabilité du site montre comment les principes et les pratiques SRE se traduisent dans votre production L'expertise de Google est complétée par des cas d'utilisateurs de Google Cloud Platform. Des représentants d'Evernote, du Home Depot, du New York Times et d'autres entreprises décrivent leur expérience de combat, racontent les pratiques qu'ils ont adoptées et celles qui ne l'ont pas été. Ce livre vous aidera à adapter SRE aux réalités de votre propre pratique, quelle que soit la taille de votre entreprise. Vous allez apprendre à:
Bonjour les Habitants! Le livre Site Reliability Engineering a suscité une discussion animée. Qu'est-ce qui est opérationnel aujourd'hui et pourquoi les questions de fiabilité sont-elles si fondamentales? Désormais, les ingénieurs de Google à l'origine de ce livre à succès proposent de passer de la théorie à la pratique - le classeur de fiabilité du site montre comment les principes et les pratiques SRE se traduisent dans votre production L'expertise de Google est complétée par des cas d'utilisateurs de Google Cloud Platform. Des représentants d'Evernote, du Home Depot, du New York Times et d'autres entreprises décrivent leur expérience de combat, racontent les pratiques qu'ils ont adoptées et celles qui ne l'ont pas été. Ce livre vous aidera à adapter SRE aux réalités de votre propre pratique, quelle que soit la taille de votre entreprise. Vous allez apprendre à:
- Assurer la fiabilité des services dans les clouds et les environnements que vous ne maîtrisez pas totalement;
- appliquer diverses méthodes de création, de lancement et de surveillance des services, en se concentrant sur le SLO;
- transformer les équipes administratives en ingénieurs SRE;
- mettre en œuvre des méthodes de démarrage de SRE à partir de zéro et basées sur les systèmes existants. Betsy Beyer, Neil Richard Murphy, David Renzin, Kent Kawahara et Stephen Thorne sont tous impliqués pour assurer la fiabilité des systèmes Google.
Gestion du système de surveillance
Votre système de surveillance est tout aussi important que tout autre service que vous utilisez. Par conséquent, la surveillance doit être traitée avec la plus grande prudence.
Traitez votre configuration comme du code Traiter la
configuration de votre système comme du code et la stocker dans un système de contrôle de version est une pratique courante, avec des options telles que le stockage de l'historique des modifications, la liaison des modifications spécifiques au système de gestion des tâches, les restaurations simplifiées, l'analyse de code statique pour les erreurs, et procédures d'inspection de code forcé.
Nous vous recommandons également fortement de traiter la configuration de surveillance comme du code (pour plus d'informations sur la configuration, voir le chapitre 14). Un système de surveillance qui prend en charge la personnalisation en utilisant des descriptions bien formées des objectifs et des fonctions, plutôt que des systèmes fournissant uniquement des interfaces Web ou des API de type CRUD (http://bit.ly/1G4WdV1). Cette approche de configuration est standard pour de nombreux binaires open source qui ne lisent qu'un fichier de configuration. Certaines solutions tierces telles que grafanalib (http://bit.ly/2so5Wrx) prennent en charge cette approche pour les composants qui sont traditionnellement personnalisables à l'aide de l'interface utilisateur.
Encouragez la cohérence
Les grandes entreprises avec plusieurs équipes de projet qui utilisent la surveillance doivent trouver un équilibre délicat: d'une part, une approche centralisée garantit la cohérence, mais d'autre part, les équipes individuelles peuvent souhaiter avoir un contrôle complet sur le fonctionnement de leur configuration.
La bonne décision dépend du type de votre organisation. Au fil du temps, l'approche de Google a évolué pour rassembler toutes les meilleures pratiques dans une plate-forme unique qui fonctionne comme un service centralisé. C'est une bonne décision pour nous, et il y a plusieurs raisons à cela. Une infrastructure commune permet aux ingénieurs de passer d'une équipe à une autre plus rapidement et plus facilement et facilite la collaboration lors du débogage. De plus, il existe un service de tableau de bord centralisé où les tableaux de bord de chaque équipe sont ouverts et accessibles. Si vous comprenez bien les informations fournies par l'autre équipe, vous pouvez rapidement résoudre vos propres problèmes et ceux des autres équipes.
Dans la mesure du possible, gardez la couverture de surveillance de base aussi simple que possible. Si tous vos services exportent un ensemble cohérent de lignes de base, vous pouvez collecter automatiquement ces métriques dans l'ensemble de votre organisation et fournir un ensemble cohérent de tableaux de bord. Cette approche signifie qu'il existe une surveillance de base pour tout nouveau composant que vous lancez automatiquement. De cette façon, de nombreuses équipes de votre entreprise - pas même les équipes d'ingénierie - pourront utiliser les données de surveillance.
Préférez les liens faibles Les
exigences de l'entreprise changent et votre système de production sera différent dans un an. Tout comme les services que vous contrôlez, votre système de surveillance doit se développer et évoluer dans le temps, en passant par divers problèmes typiques.
Nous recommandons que le couplage entre les composants de votre système de commande ne soit pas très fort. Vous devez disposer d'interfaces fiables pour configurer chaque composant et transférer les données de surveillance. Différents composants devraient être responsables de la collecte, du stockage, de l'alerte et de la visualisation de vos données de surveillance. Des interfaces stables facilitent le remplacement d'un composant particulier par l'alternative la plus appropriée.
Dans le monde open source, la décomposition des fonctionnalités en composants séparés devient populaire. Il y a dix ans, des systèmes de surveillance tels que Zabbix (https://www.zabbix.com/) combinaient toutes les fonctions en un seul composant. La conception moderne implique généralement de séparer la collecte et l'exécution des règles (à l'aide de solutions telles que le serveur Prometheus (https://prometheus.io/)), le stockage de séries chronologiques à long terme (InfluxDB, www.influxdata.com ), l'agrégation d'alertes ( Alertmanager, bit.ly/2soB22b ) et la création de tableaux de bord (Grafana, grafana.com ).
Au moment d'écrire ces lignes, il existe au moins deux standards ouverts populaires qui vous permettent d'équiper le logiciel des outils nécessaires et de fournir des métriques:
- statsd — , Etsy, ;
- Prometheus — , . Prometheus OpenMetrics (https://openmetrics.io/).
Un système de tableau de bord distinct utilisant plusieurs sources de données fournit une vue centralisée et unifiée de votre service. Google a récemment expérimenté cet avantage dans la pratique: notre système de surveillance hérité (Borgmon1) regroupait des tableaux de bord dans la même configuration que les règles d'alerte. Lors du passage à un nouveau système (Monarch, youtu.be/LlvJdK1xsl4 ), nous avons décidé de déplacer les tableaux de bord vers un service séparé (Viceroy, bit.ly/2sqRwad ). Viceroy n'était pas un composant Borgmon ou Monarch, donc Monarch avait moins d'exigences fonctionnelles. Étant donné que les utilisateurs peuvent utiliser Viceroy pour afficher des graphiques basés sur les données des deux systèmes de surveillance, ils ont pu progressivement migrer de Borgmon vers Monarch.
Mesures significatives Le
chapitre 5 explique comment utiliser les mesures de qualité de service (SLI) pour suivre et signaler les menaces à votre budget. Les métriques SLI sont les premières métriques à vérifier lorsque des alertes sont déclenchées en fonction des objectifs de qualité de service (SLO). Ces mesures devraient apparaître sur le tableau de bord de votre service, idéalement sur la page d'accueil.
Lors de l'enquête sur la cause première d'une violation de SLO, vous n'obtiendrez probablement pas suffisamment d'informations des panneaux SLO. Ces panneaux montrent qu'il y a des violations, mais il est peu probable que vous connaissiez les raisons qui les ont conduites. Quelles autres données doivent être affichées sur le tableau de bord?
Nous pensons que les directives suivantes sont utiles lors de la mise en œuvre des métriques: Ces métriques doivent fournir une surveillance significative qui vous permet d'étudier les problèmes de production et de fournir un large éventail d'informations sur vos services.
Modifications intentionnelles
Lors du diagnostic des alertes liées aux SLO, vous devez être en mesure de passer des mesures d'alerte qui vous informent des problèmes qui affectent les utilisateurs, aux mesures qui vous alertent sur la cause première de ces problèmes. De telles raisons pourraient être des changements délibérés récents de votre service. Ajoutez une surveillance qui vous informe de tout changement de production. Pour détecter le fait que des modifications ont été apportées, nous vous recommandons ce qui suit:
- surveiller la version d'un fichier binaire;
- , ;
- , .
Si l'un de ces composants n'est pas versionné, vous devez savoir quand le composant a été assemblé ou emballé pour la dernière fois.
Lorsque vous essayez de corréler les problèmes de service émergents avec un déploiement, il est beaucoup plus facile de consulter un graphique ou un panneau référencé dans une alerte que de parcourir les journaux CI / CD après coup.
Dépendances
Même si votre service n'a pas changé, n'importe laquelle de ses dépendances peut changer. Par conséquent, vous devez également garder une trace des réponses provenant de dépendances directes.
Il est judicieux d'exporter la taille de la demande et de la réponse en octets, les temps de réponse et les codes de réponse pour chaque dépendance. Lorsque vous choisissez une métrique pour un graphique, gardez ces quatre signaux en or à l'esprit (voir la section«Les quatre signaux d'or», chapitre 6 de l'ingénierie de la fiabilité des sites ).
Vous pouvez utiliser des étiquettes supplémentaires dans les métriques pour les séparer par code de réponse, nom de méthode RPC (appel de procédure distante) et nom du service appelé.
Idéalement, au lieu de demander à chaque bibliothèque cliente RPC d'exporter ces étiquettes, vous pouvez utiliser une fois la bibliothèque cliente RPC de niveau inférieur à cet effet. Cela offre plus de cohérence et vous permet de surveiller facilement les nouvelles dépendances.
Il existe des dépendances qui offrent une API très limitée, où toutes les fonctionnalités sont disponibles via une seule méthode RPC appelée Get, Query ou tout aussi peu informative, et la commande réelle est spécifiée comme arguments de cette méthode. L'approche en un seul point des outils dans la bibliothèque cliente ne fonctionne pas pour ce type de dépendance: vous verrez beaucoup de variabilité dans la latence et un certain pourcentage d'erreurs qui peuvent ou non indiquer qu'une partie de ce "trouble" L'API est complètement tombée. Si cette dépendance est critique, une bonne surveillance peut être mise en œuvre des manières suivantes.
- Exportez des métriques individuelles conçues spécifiquement pour cette dépendance, où les demandes seront décompressées pour obtenir un signal valide.
- Demandez aux propriétaires de la dépendance de la réécrire pour exporter une API étendue qui prend en charge la séparation des fonctions entre les services et méthodes RPC individuels.
Niveau de charge
Il est conseillé de contrôler et de suivre l'utilisation de toutes les ressources avec lesquelles le service fonctionne. Certaines ressources ont des limites strictes que vous ne pouvez pas dépasser. Par exemple, la taille de la RAM, le disque dur alloué à votre application ou le quota de CPU. D'autres ressources, telles que les descripteurs de fichiers ouverts, les threads actifs dans les pools de threads, les délais d'attente de la file d'attente ou la quantité de journaux écrits, peuvent ne pas avoir de limite claire, mais doivent tout de même être gérées.
Selon le langage de programmation que vous utilisez, vous devez garder une trace de certaines ressources supplémentaires:
- en Java, la taille du tas et de la métaspace (http://bit.ly/2J9g3Ha), ainsi que des métriques plus spécifiques en fonction du type de garbage collection utilisé;
- en Go, le nombre de goroutines.
Les langages de programmation eux-mêmes fournissent divers supports pour garder une trace de ces ressources.
En plus de vous alerter des événements importants, comme décrit au chapitre 5, vous pouvez également configurer des alertes qui sont déclenchées lorsque certaines ressources approchent de l'épuisement critique. Ceci est utile, par exemple, dans les situations suivantes:
- lorsque la ressource a une limite stricte;
- lorsqu'une dégradation des performances se produit lorsque le seuil d'utilisation est dépassé.
La surveillance est essentielle pour toutes les ressources, même celles qui sont bien gérées par le service. Ces mesures sont essentielles lors de la planification des ressources et des capacités.
État du trafic émis
Il est recommandé d'ajouter des métriques ou des étiquettes de métriques sur le tableau de bord qui vous permettront de briser le trafic émis par code d'état (si les métriques utilisées par votre service à des fins SLI ne contiennent pas ces informations) Voici quelques lignes directrices.
- Gardez une trace de tous les codes de réponse pour le trafic HTTP, même ceux qui, en raison d'un possible comportement incorrect du client, ne justifient pas l'émission d'alertes.
- Si vous appliquez une limite de temps ou des limites de quota à vos utilisateurs, gardez une trace du nombre de demandes refusées en raison d'un manque de quota.
Les graphiques de ces données peuvent vous aider à déterminer quand le taux d'erreur change sensiblement lors d'un changement de production.
Implémentation de métriques cibles
Chaque métrique doit servir son objectif. Ne soyez pas tenté d'exporter plusieurs métriques simplement parce qu'elles sont faciles à générer. Pensez plutôt à la manière dont ils seront utilisés. L'architecture des métriques (ou son absence) a des implications. Idéalement, les valeurs métriques utilisées pour alerter ne changent brusquement que lorsqu'un problème survient dans le système, mais en fonctionnement normal, elles restent inchangées. D'un autre côté, ces exigences ne sont pas imposées aux métriques de débogage - elles devraient donner une idée de ce qui se passe lorsqu'une alerte est déclenchée. De bonnes mesures de débogage indiqueront les parties potentiellement problématiques du système. Lors de l'écriture d'un post-mortem, réfléchissez aux mesures supplémentaires qui vous permettraient de diagnostiquer le problème plus rapidement.
Test de la logique d'alerte
Dans un monde idéal, le code de surveillance et d'alerte devrait suivre les mêmes normes de test que le code de développement. Il n'existe actuellement aucun système largement accepté qui vous permettrait de mettre en œuvre un tel concept. L'un des premiers signes est la fonctionnalité de test unitaire de règles nouvellement ajoutée à Prometheus.
Chez Google, nous testons nos systèmes de surveillance et d'alerte à l'aide d'un langage spécifique au domaine qui nous permet de créer des séries chronologiques synthétiques. Nous vérifions ensuite les valeurs de la série chronologique dérivée ou clarifions si une alerte spécifique a été déclenchée et porte l'étiquette requise.
La surveillance et l'émission d'alertes sont souvent un processus en plusieurs étapes, de sorte que plusieurs familles de tests unitaires sont nécessaires.
Bien que ce domaine reste largement sous-développé, si vous souhaitez mettre en œuvre des tests de surveillance à un moment donné, nous vous recommandons une approche à trois niveaux, comme le montre la figure 1. 4.1.
- Fichiers binaires. Assurez-vous que les variables de métrique exportées changent de valeur comme prévu dans certaines conditions.
- Infrastructure de surveillance. Assurez-vous que les règles sont suivies et que les conditions spécifiques sont les alertes attendues.
- Gestionnaire d'alertes. Vérifiez que les alertes générées sont acheminées vers une destination prédéfinie en fonction des valeurs d'étiquette.
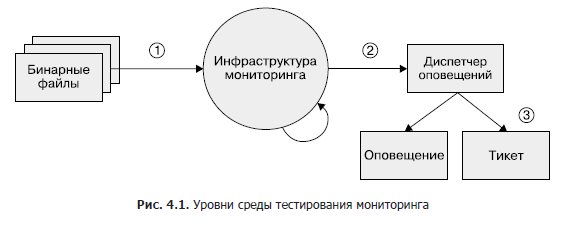
Si vous ne pouvez pas tester votre système de surveillance avec des outils synthétiques, ou si une étape n'est pas du tout testable, envisagez de créer un système de production qui exporte les métriques connues telles que les requêtes et les erreurs. Vous pouvez utiliser ce système pour vérifier les séries chronologiques et les alertes. Il est probable que vos règles d'alerte ne se déclenchent pas pendant des mois ou des années après leur configuration, et vous devez vous assurer que lorsque la métrique dépasse un certain seuil, les alertes restent significatives et transmises aux ingénieurs prévus.
Résumé du chapitre
Étant donné que les ingénieurs SR doivent être responsables de la fiabilité des systèmes de production, ces spécialistes doivent souvent avoir une compréhension approfondie du système de surveillance et de ses fonctions et travailler en étroite collaboration avec lui. Sans ces données, les SRE peuvent ne pas savoir où chercher et comment identifier un comportement anormal du système ou comment trouver les informations dont ils ont besoin en cas d'urgence.
Nous espérons qu'en rappelant les fonctions du système de surveillance qui nous sont utiles de notre point de vue et en justifiant notre choix, nous pourrons vous aider à évaluer comment votre système de surveillance répond à vos besoins. En outre, nous vous aiderons à explorer certaines des fonctionnalités supplémentaires que vous pouvez utiliser et à examiner les modifications que vous souhaitez probablement apporter. Vous trouverez probablement utile de combiner des sources de métriques et des journaux dans votre stratégie de surveillance. Le bon mélange de métriques et de journaux dépend fortement du contexte.
Assurez-vous de collecter des métriques qui servent un objectif spécifique. Il s'agit d'objectifs tels que l'amélioration de la planification de la bande passante, le débogage ou le signalement des problèmes qui surviennent.
Lorsque vous avez une surveillance, elle doit être visuelle et utile. Pour ce faire, nous vous recommandons de tester ses paramètres. Un bon système de suivi porte ses fruits. Une planification préalable approfondie des solutions à utiliser pour couvrir au mieux vos besoins spécifiques, ainsi que des améliorations itératives continues du système de surveillance, est un investissement qui sera payant.
»Plus de détails sur le livre peuvent être trouvés sur le site de la maison d'édition
» Table des matières
» Extrait
Pour Habitants une réduction de 25% sur le coupon - Google
Lors du paiement de la version papier du livre, un e-book est envoyé à l'e-mail.