
En avril 2020, Citizenlab a signalé un cryptage assez faible pour Zoom et a déclaré que Zoom utilisait le codec audio SILK. Malheureusement, l'article ne contenait pas les données initiales pour le confirmer et me donner l'occasion d'y faire référence à l'avenir. Cependant, grâce à Natalie Silvanovich de Google Project Zeroet à l'outil de traçage Frida, j'ai pu obtenir un vidage de quelques cadres SILK bruts. Leur analyse m'a inspiré à jeter un regard sur la façon dont WebRTC gère l'audio. En ce qui concerne la qualité des appels perçus en général, c'est la qualité audio qui affecte le plus, car nous avons tendance à remarquer même les petits problèmes. Dix secondes d'analyse suffisent pour se lancer dans une véritable aventure - à la recherche d'options pour améliorer la qualité sonore fournie par WebRTC.
J'ai traité avec le client Zoom natif en 2017 (avant le post DataChannel ) et j'ai remarqué que ses packages audio étaient parfois très volumineux par rapport aux packages de solutions basés sur WebRTC:

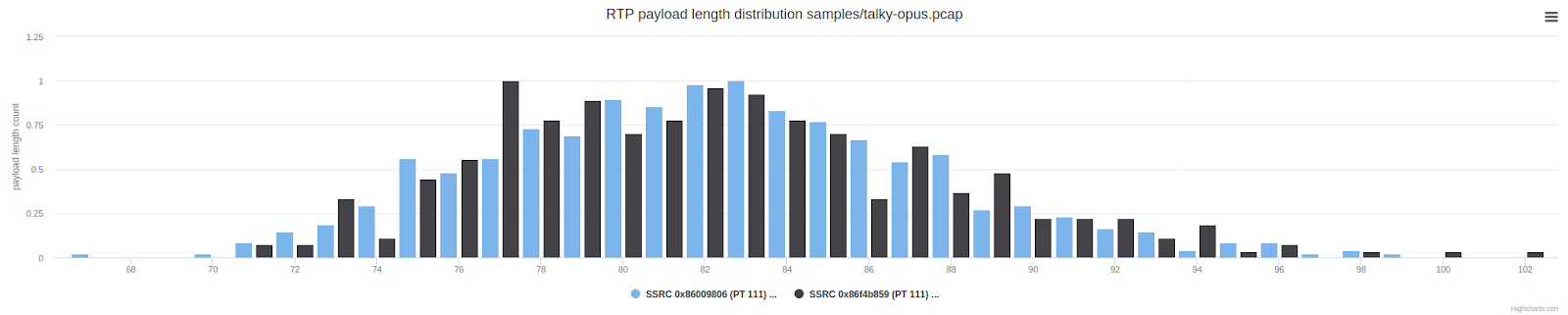
Le graphique ci-dessus montre le nombre de paquets avec une longueur de charge utile UDP spécifique. Les paquets entre 150 et 300 octets sont inhabituels par rapport à un appel WebRTC typique. Ils sont beaucoup plus longs que les paquets que nous recevons habituellement d'Opus. Nous soupçonnions qu'il y avait un contrôle d'erreur avant (FEC) ou une redondance, mais sans accès aux trames non chiffrées, il était difficile de tirer plus de conclusions ou de faire quelque chose.
Les trames SILK non chiffrées dans le nouveau vidage ont montré une distribution très similaire. Après avoir converti les cadres en fichier, puis lu un court message (merci à Giacomo Vacca pour un article de blog très utiledécrivant les étapes nécessaires) Je suis retourné à Wireshark et j'ai regardé les paquets. Voici un exemple de trois packages que j'ai trouvés particulièrement intéressants:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaefLe paquet 9 contient deux paquets précédents, le paquet 8 - 1 paquet précédent. Cette redondance est causée par l'utilisation du format LBRR - Low Bit-Rate Redundancy, qui a été montré par une étude approfondie du décodeur SILK (on peut le trouver dans le projet Internet fourni par l'équipe Skype , ou dans le référentiel sur GitHub ):

Zoom utilise SKP_SILK_LBRR_VER1 mais avec deux packages de secours. Si chaque paquet UDP contient non seulement la trame audio actuelle, mais également les deux précédents, il sera robuste même si vous perdez deux des trois paquets. Alors peut-être que la clé de la qualité du son Zoom est la recette secrète Skype de grand-mère?
Opus FEC
Comment puis-je réaliser la même chose avec WebRTC? La prochaine étape évidente était de considérer l'Opus FEC.
Le LBRR (Low Rate Reservation) de SILK se trouve également dans Opus (rappelez-vous qu'Opus est un codec hybride qui utilise SILK pour l'extrémité inférieure de la plage de débit). Cependant, Opus SILK est très différent du SILK original, dont le code source a été découvert par Skype, tout comme la partie de LBRR qui est utilisée en mode de contrôle des erreurs.
Dans Opus, le contrôle d'erreur n'est pas simplement ajouté après la trame audio d'origine, il la précède et est encodé dans le train binaire. Nous avons essayé d'ajouter notre propre contrôle d'erreur à l'aide de l' API Insertable Streams , mais cela nécessitait un transcodage complet pour insérer les informations dans le train de bits avant le paquet réel.
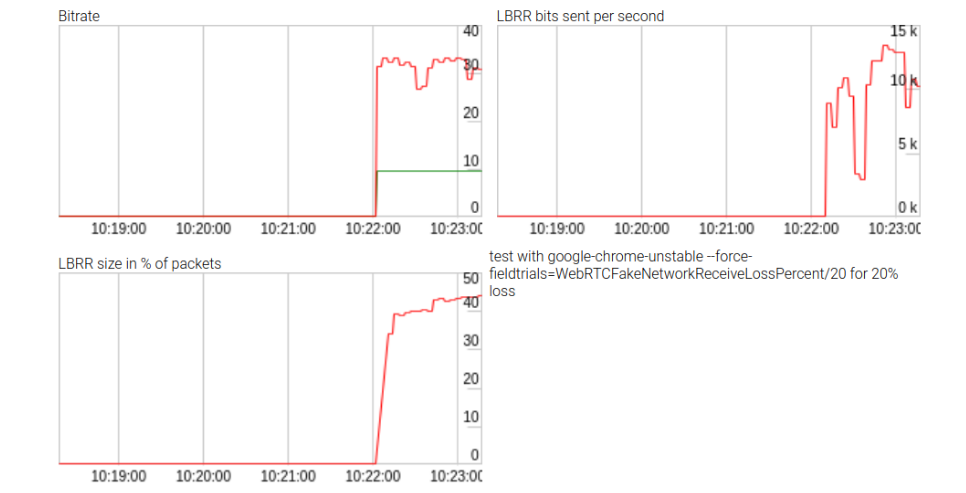
Bien que les efforts aient été infructueux, ils ont généré des statistiques sur l'impact du LBRR, qui sont illustrées dans la figure ci-dessus. LBRR utilise des débits binaires allant jusqu'à 10 kbps (ou les deux tiers du débit de données) pour une perte de paquets élevée. Le référentiel est disponible ici . Ces statistiques ne sont pas affichées lors de l'appel de l'
getStats() API WebRTC , les résultats étaient donc assez intéressants.
Le besoin de transcodage n'est pas le seul problème avec l'Opus FEC. Il s'est avéré que ses paramètres dans WebRTC sont quelque peu inutiles:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
La soustraction du débit binaire FEC du débit binaire maximal cible n'a aucun sens - FEC réduit activement le débit binaire du flux principal. Un flux à débit binaire inférieur se traduit généralement par une qualité inférieure. S'il n'y a pas de perte de paquet qui peut être corrigée avec FEC, alors FEC ne fera que dégrader la qualité, pas l'améliorer. Pourquoi ça arrive? La théorie principale est que la congestion est l'une des raisons de la perte de paquets. Si vous rencontrez une congestion, vous ne voudrez pas envoyer plus de données car cela ne fera qu'aggraver le problème. Cependant, comme le décrit Emil Ivov dans son excellent discours sur KrankyGeek 2017, la congestion n'est pas toujours la cause de la perte de paquets. De plus, cette approche ignore également les flux vidéo associés. La stratégie FEC basée sur la congestion pour Opus audio n'a pas beaucoup de sens lorsque vous envoyez des centaines de kilobits de vidéo avec un flux Opus de 50 kbps relativement petit. Peut-être que dans le futur, nous verrons quelques changements dans libopus, mais pour l'instant j'aimerais essayer de le désactiver, car il est actuellement activé dans WebRTC par défaut .
Nous concluons que cela ne nous convient pas ...
ROUGE
Si nous voulons une vraie redondance, RTP a une solution appelée RTP Payload for Redundant Audio Data, ou RED. C'est assez ancien, la RFC 2198 a été écrite en 1997 . La solution permet de placer plusieurs charges utiles RTP avec des horodatages différents dans le même paquet RTP à un coût relativement faible.
Utiliser RED pour mettre une ou deux trames audio redondantes dans chaque paquet donnerait beaucoup plus de robustesse à la perte de paquets que l'Opus FEC. Mais cela n'est possible qu'en doublant ou triplant le débit audio de 30 kbps à 60 ou 90 kbps (avec 10 kbps supplémentaires pour l'en-tête). Par rapport à plus de 1 mégabit de données vidéo par seconde, ce n'est pas si mal.
La bibliothèque WebRTC comprenait un deuxième encodeur et décodeur pour RED, qui est désormais redondant! Malgré les tentatives de suppression du code audio RED inutilisé , j'ai pu appliquer cet encodeur avec relativement peu d'effort. L'historique complet de la solution est disponible dans le système de suivi des bogues WebRTC.
Et il est disponible en tant qu'essai qui est inclus lorsque Chrome démarre avec les indicateurs suivants:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/Ensuite, RED peut être activé via la négociation SDP; il s'affichera comme ceci:
a=rtpmap:someid red/48000/2Il n'est pas activé par défaut car il existe des environnements où l'utilisation d'une bande passante supplémentaire n'est pas une bonne idée. Pour utiliser RED, changez l'ordre des codecs afin qu'il vienne avant le codec Opus. Cela peut être fait en utilisant l'API
RTCRtpTransceiver.setCodecPreferencescomme indiqué ici . Évidemment, une autre alternative consiste à modifier manuellement le SDP. Le format SDP pourrait également fournir un moyen de configurer le niveau maximal de redondance, mais la sémantique offre-réponse RFC 2198 n'était pas tout à fait claire, j'ai donc décidé de reporter cela pendant un certain temps.
Vous pouvez montrer comment tout cela fonctionne en l'exécutant dans un exemple audio . Voici à quoi ressemble la première version avec un seul package de sauvegarde:
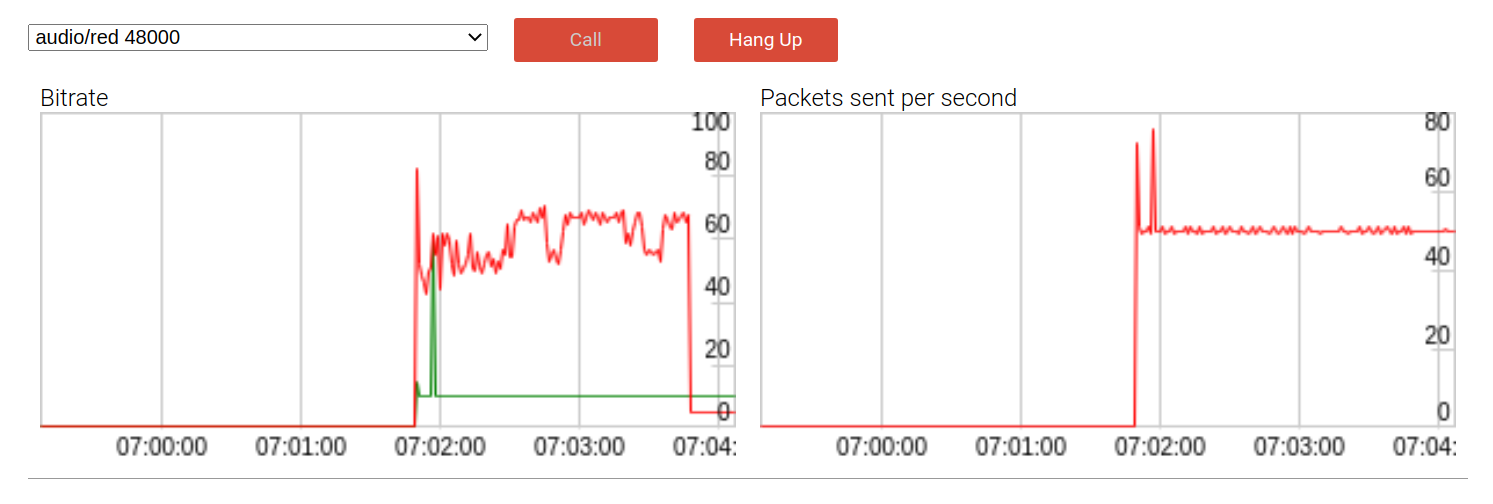
Par défaut, le débit binaire de la charge utile (ligne rouge) est presque deux fois plus élevé que sans redondance, à près de 60 kbps. DTX (Discontinuous Transfer) est un mécanisme de conservation de la bande passante qui envoie des paquets uniquement lorsque la voix est détectée. Comme prévu, lors de l'utilisation de DTX, l'effet du débit binaire s'adoucit quelque peu, comme on le voit à la fin de l'appel.
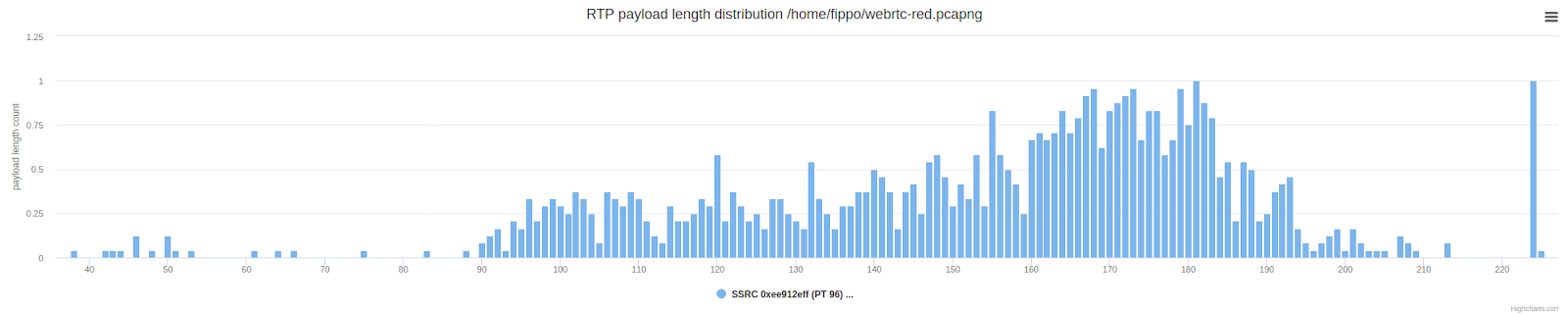
La vérification de la longueur des paquets montre le résultat attendu: les paquets sont, en moyenne, deux fois plus longs (plus grands) que la distribution normale de la longueur de la charge utile indiquée ci-dessous.
C'est encore légèrement différent de ce que fait Zoom, où nous avons vu des réservations fractionnaires. Revisitons le graphique de longueur de paquet Zoom montré précédemment pour voir une comparaison:
Ajout de la prise en charge de la détection d'activité vocale (VAD)
L'Opus FEC envoie des données de sauvegarde uniquement s'il y a une activité vocale dans le paquet. La même chose devrait être appliquée à la mise en œuvre RED. Pour cela, le codeur Opus doit être changé pour afficher les informations VAD correctes , qui sont définies au niveau SILK. Avec ce paramètre, le débit binaire atteint 60 kbps uniquement en présence de parole (comparé à 60 kbps constants):

et le "spectre" ressemble plus à ce que nous avons vu avec Zoom:

Le changement pour y parvenir n'est pas encore apparu.
Trouver la bonne distance
La distance est le nombre de paquets de sauvegarde, c'est-à-dire le nombre de paquets précédents dans le paquet actuel. En cherchant à trouver la bonne distance, nous avons constaté que si le ROUGE à la distance 1 est froid, alors le ROUGE à la distance 2 est encore plus frais. Notre estimation de laboratoire a simulé une perte aléatoire de paquets de 60%. Dans cet environnement, Opus + RED a produit un excellent son, tandis que l'Opus sans RED a été bien pire. L'API WebRTC getStats () offre une capacité très utile pour mesurer cela en comparant le pourcentage d'échantillons cachés obtenus en divisant dissimulésSamples par totalSamplesReceived .
Sur la page des échantillons audio, ces données sont facilement récupérées à l'aide de cet extrait de code JavaScript collé dans la console:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})J'ai effectué quelques tests de perte de paquets en utilisant un indicateur pas très connu mais très utile
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/À 20% de perte de paquets et FEC activé par défaut, il n'y avait pas beaucoup de différence de qualité audio, mais il y avait une légère différence de métrique:
| scénario | pourcentage de perte |
|---|---|
| sans rouge | dix-huit% |
| pas de rouge, FEC désactivé | 20% |
| rouge avec distance 1 | 4% |
| rouge avec distance 2 | 0,7% |
Sans RED ou FEC, la métrique correspond presque à la perte de paquets demandée. Il y a un effet de FEC, mais il est petit.
Sans RED, à 60% de perte, la qualité sonore est devenue plutôt médiocre, un peu métallique, et les mots difficiles à comprendre:
| scénario | pourcentage de perte |
|---|---|
| sans rouge | 60% |
| rouge avec distance 1 | 32% |
| rouge avec distance 2 | dix-huit% |
Il y avait des artefacts audibles à RED avec une distance = 1, mais un son presque parfait à la distance 2 (qui est la quantité de redondance actuellement utilisée).
On a le sentiment que le cerveau humain peut résister à un certain niveau de silence qui se produit de manière irrégulière. (Et Google Duo semble utiliser un algorithme d'apprentissage automatique pour combler le silence.)
Mesurer les performances dans le monde réel
Nous espérons que l'inclusion de RED dans Opus améliorera la qualité du son, même si dans certains cas cela peut l'aggraver. Emil Ivov s'est porté volontaire pour effectuer quelques tests d'écoute en utilisant la méthode POLQA-MOS. Cela a déjà été fait pour Opus, nous avons donc une base de comparaison.
Si les tests initiaux montrent des résultats prometteurs, nous effectuerons une expérience à grande échelle sur l'analyse principale de Jitsi Meet en utilisant les métriques de pourcentage de perte que nous avons utilisées ci-dessus.
Notez que pour les serveurs multimédia et les SFU, l'activation de RED est un peu plus difficile car le serveur peut avoir besoin de gérer le relais RED pour sélectionner des clients, comme si tous les clients ne supportaient pas les conférences RED. De plus, certains clients peuvent être sur un canal à bande passante limitée où RED n'est pas requis. Si le point de terminaison ne prend pas en charge RED, la SFU peut supprimer le codage inutile et envoyer Opus sans wrapper. De même, il peut implémenter RED lui-même et l'utiliser lors de la soumission de paquets d'un point d'extrémité transmettant Opus à un point d'extrémité prenant en charge RED.
Un grand merci à Jitsi / 8 × 8 Inc pour le parrainage de cette aventure passionnante et aux gens de Google qui ont analysé et fourni des commentaires sur les changements nécessaires.
Et sans Natalie Silvanovich, je me serais assis en regardant les octets cryptés!