
Nous sommes de retour sur les ondes et continuons la série de notes Data Scientist, et aujourd'hui je présente ma liste de contrôle complètement subjective pour choisir un modèle d'apprentissage automatique.
Ce sont les 10 principales propriétés du problème et juste des points (sans ordre en eux), du point de vue desquels je commence à choisir un modèle et, en général, à modéliser une tâche d'analyse de données.
Il n'est pas du tout nécessaire que vous ayez la même chose - tout est subjectif ici, mais je partage mon expérience de la vie.
Quel est notre objectif en général? Interprétabilité et précision - spectre

Source
Peut-être que la question la plus importante à laquelle un Data Scientist est confronté avant de commencer la modélisation est:
Qu'est-ce qu'une tâche métier?
Ou de la recherche, si nous parlons de l'académie, etc.
Par exemple, nous avons besoin d'analyses basées sur un modèle de données, ou vice versa, nous ne nous intéressons qu'aux prédictions qualitatives de la probabilité qu'un e-mail soit du spam.
L'équilibre classique que j'ai vu est le spectre entre l'interprétabilité de la méthode et sa précision (comme dans le graphique ci-dessus).
Mais en fait, vous devez non seulement piloter Catboost / Xgboost / Random Forest et choisir un modèle, mais aussi comprendre ce que l'entreprise veut, quelles données nous avons et comment elles seront appliquées.
Dans ma pratique, cela établira immédiatement un point sur le spectre de l'interprétabilité et de la précision (quoi que cela signifie ici). Et sur cette base, on peut déjà penser à des méthodes de modélisation du problème.
Le type de tâche elle-même
De plus, une fois que nous avons compris ce que l'entreprise veut - nous devons comprendre à quel type mathématique de problèmes d'apprentissage automatique le nôtre appartient, par exemple.
- Analyse exploratoire - analyse pure des données disponibles et coller un bâton
- Clustering - collectez les données en groupes en fonction de certains attributs communs
- Régression - vous devez renvoyer un résultat entier ou il y a une probabilité d'un événement
- Classification - vous devez renvoyer une étiquette de classe
- Multi-label - vous devez renvoyer une ou plusieurs étiquettes de classe pour chaque entrée
Exemples de
données: il existe deux classes et un jeu d'enregistrements sans étiquette:

Et vous devez créer un modèle qui marquera ces mêmes données:

Ou, en option, il n'y a pas d'étiquettes et vous devez sélectionner des groupes:

Comme ici:
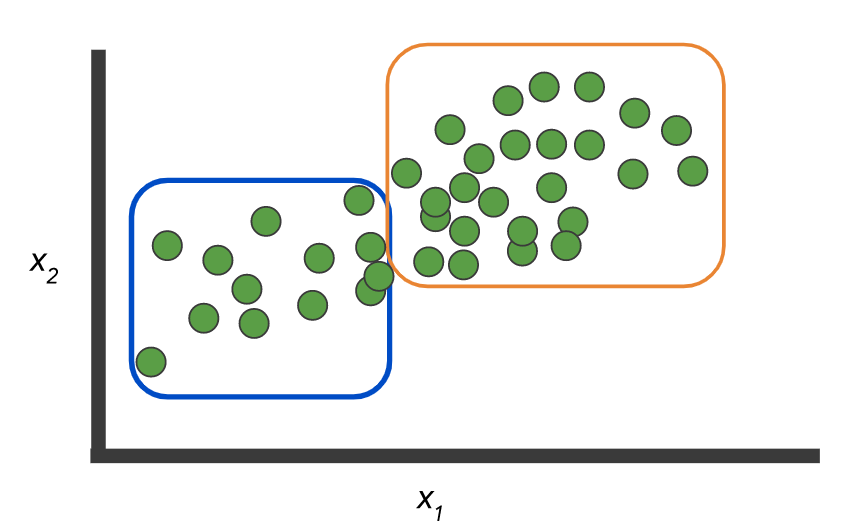
Photos d'ici .
Mais l'exemple lui-même illustre la différence entre les deux concepts: classification, lorsque N> 2 classes - multi classe vs. multi label
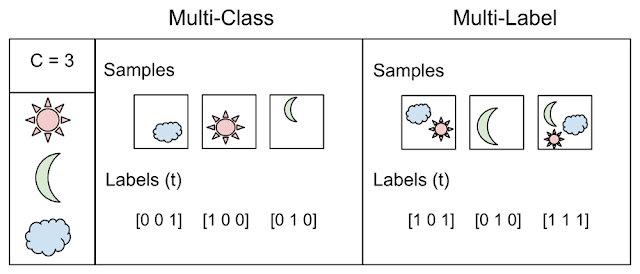
Tiré d'ici
Vous serez surpris, mais très souvent, ce point vaut également la peine d'être abordé directement avec l'entreprise - cela peut vraiment vous faire gagner beaucoup de temps et d'efforts. N'hésitez pas à dessiner des images et à donner des exemples simples (mais pas trop simplistes).
Précision et comment elle est déterminée
Je vais commencer par un exemple simple, si vous êtes une banque et que vous émettez un prêt, alors sur un prêt infructueux, nous perdons cinq fois plus que ce que nous obtenons sur un prêt réussi.
La question de la mesure de la qualité du travail est donc primordiale! Ou imaginez que vous ayez un déséquilibre significatif dans les données, classe A = 10% et classe B = 90%, alors un classificateur qui renvoie simplement B est toujours précis à 90%! Ce n'est probablement pas ce que vous vouliez voir lors de l'entraînement du modèle.
Par conséquent, il est essentiel de définir une métrique de notation du modèle comprenant:
- classe de poids - comme dans l'exemple ci-dessus, un mauvais crédit est de 5 et un bon crédit est de 1
- matrice des coûts - il est possible de confondre risque faible et risque moyen - cela n'a pas d'importance, mais risque faible et risque élevé est déjà un problème
- La métrique devrait-elle refléter l'équilibre? comme ROC AUC
- Comptons-nous généralement les probabilités ou les étiquettes de classe sont-elles droites?
- Ou peut-être que la classe est généralement «une» et que nous avons des règles de précision / rappel et d'autres règles du jeu?
En général, le choix d'une métrique est déterminé par la tâche et sa formulation - et c'est pour ceux qui définissent cette tâche (généralement les gens d'affaires) que tous ces détails doivent être clarifiés et clarifiés, sinon il y aura des coutures à la sortie.
Analyse post modèle
Il est souvent nécessaire de mener des analyses basées sur le modèle lui-même. Par exemple, quelle est la contribution des différentes fonctionnalités au résultat original: en règle générale, la plupart des méthodes peuvent produire quelque chose de similaire à ceci:
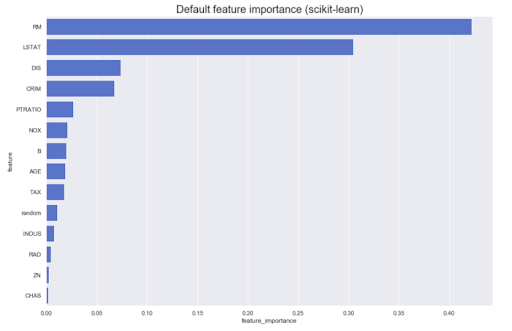
Cependant, que se passe-t-il si nous avons besoin de connaître la direction - de grandes valeurs de l'attribut A augmentent l'appartenance à la classe Z, ou vice versa? Appelons-les l'importance des caractéristiques dirigées - elles peuvent être obtenues à partir de certains modèles, par exemple, linéaires (par le biais de coefficients sur des données normalisées).
Pour un certain nombre de modèles basés sur des arbres et des boosters - par exemple, la méthode SHapley Additive exPlanations convient.
SHAP
C'est l'une des méthodes d'analyse de modèle qui vous permet de regarder sous le capot du modèle.
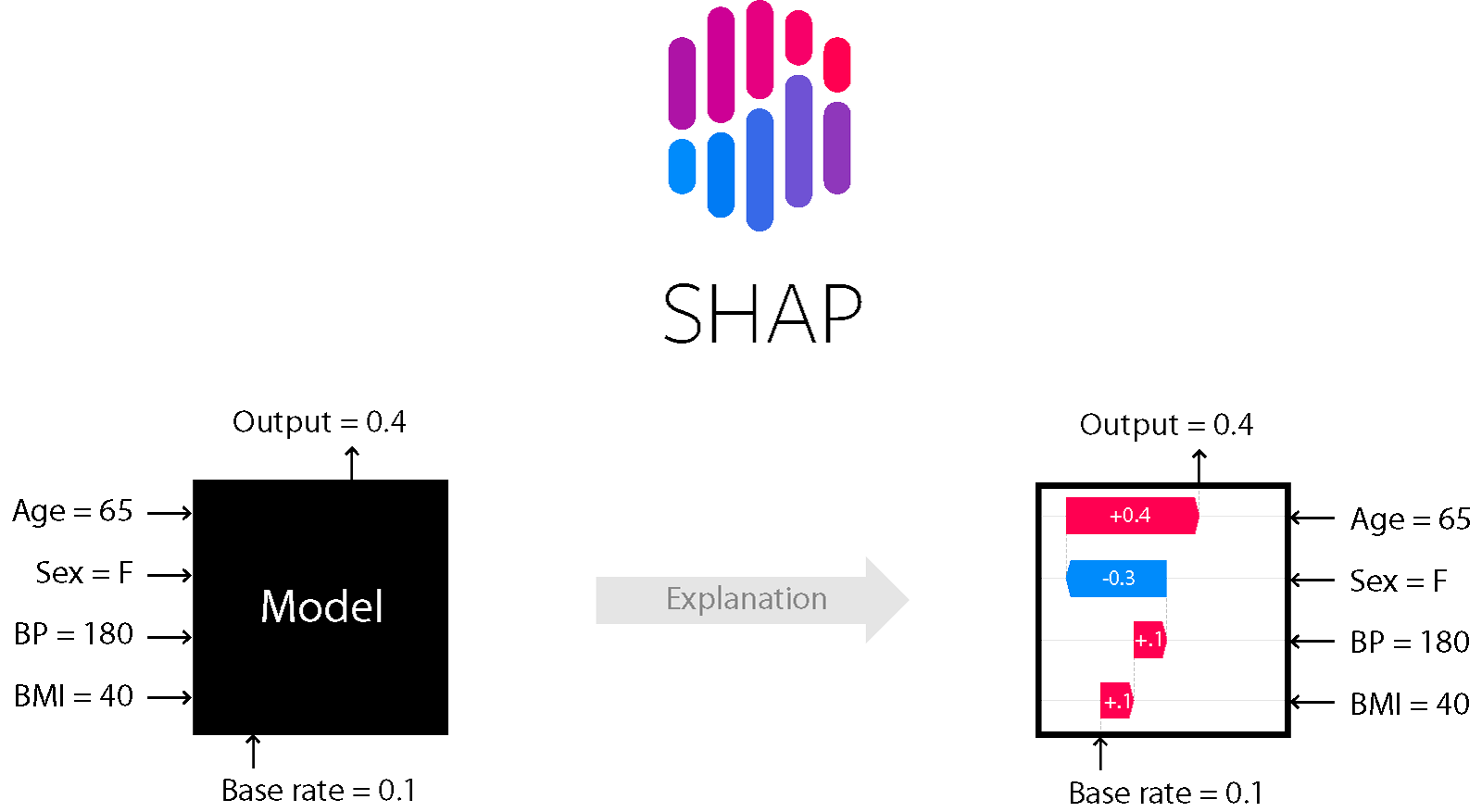
Il vous permet d'évaluer la direction de l'effet:

De plus, pour les arbres (et les méthodes basées sur eux), il est exact. En savoir plus ici .
Niveau de bruit - stabilité, dépendance linéaire, détection des valeurs aberrantes, etc.
La résistance au bruit et à toutes ces joies de la vie est un sujet distinct et vous devez analyser soigneusement le niveau de bruit, ainsi que sélectionner les méthodes appropriées. Si vous êtes sûr qu'il y aura des valeurs aberrantes dans les données, vous devez les nettoyer avec une haute qualité et appliquer des méthodes antibruit (biais élevé, régularisation, etc.).
En outre, les signes peuvent être colinéaires et des signes sans signification peuvent être présents - différents modèles réagissent différemment à cela. Voici un exemple du jeu de données classique German Credit Data (UCI) et de trois modèles d'apprentissage simples (relativement):
- Classificateur de régression de crête: régression classique avec le régulariseur de Tikhonov
- Arbres de décision
- CatBoost de Yandex
Régression Ridge
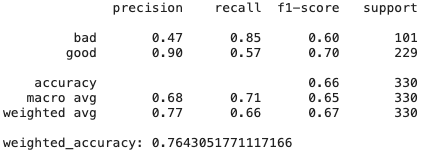
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Arbres de décision
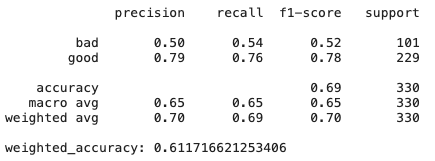
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Comme nous pouvons le voir, simplement le modèle de régression de crête, qui a un biais et une régularisation élevés, montre des résultats encore meilleurs que CatBoost - il existe de nombreuses fonctionnalités qui ne sont pas très utiles et colinéaires, donc les méthodes qui y résistent donnent de bons résultats.
En savoir plus sur DT - et si vous modifiez un peu l'ensemble de données? L'importance des fonctionnalités peut varier car les arbres de décision sont généralement des méthodes sensibles, même au brassage des données.
Conclusion: parfois plus facile est meilleur et plus efficace.
Évolutivité
Avez-vous vraiment besoin de Spark ou de réseaux de neurones avec des milliards de paramètres?
Tout d'abord, vous devez évaluer raisonnablement la quantité de données, nous avons déjà vu l'utilisation massive d'étincelle sur des tâches qui s'intègrent facilement dans la mémoire d'une machine.
Spark complique le débogage, ajoute des frais généraux et complique le développement - vous ne devriez pas l'utiliser là où vous n'en avez pas besoin. Classiques .
Deuxièmement, bien sûr, vous devez évaluer la complexité du modèle et le relier à la tâche. Si vos concurrents affichent d'excellents résultats et qu'ils ont RandomForest en cours d'exécution, il peut être utile de réfléchir à deux fois si vous avez besoin d'un réseau de neurones avec des milliards de paramètres.
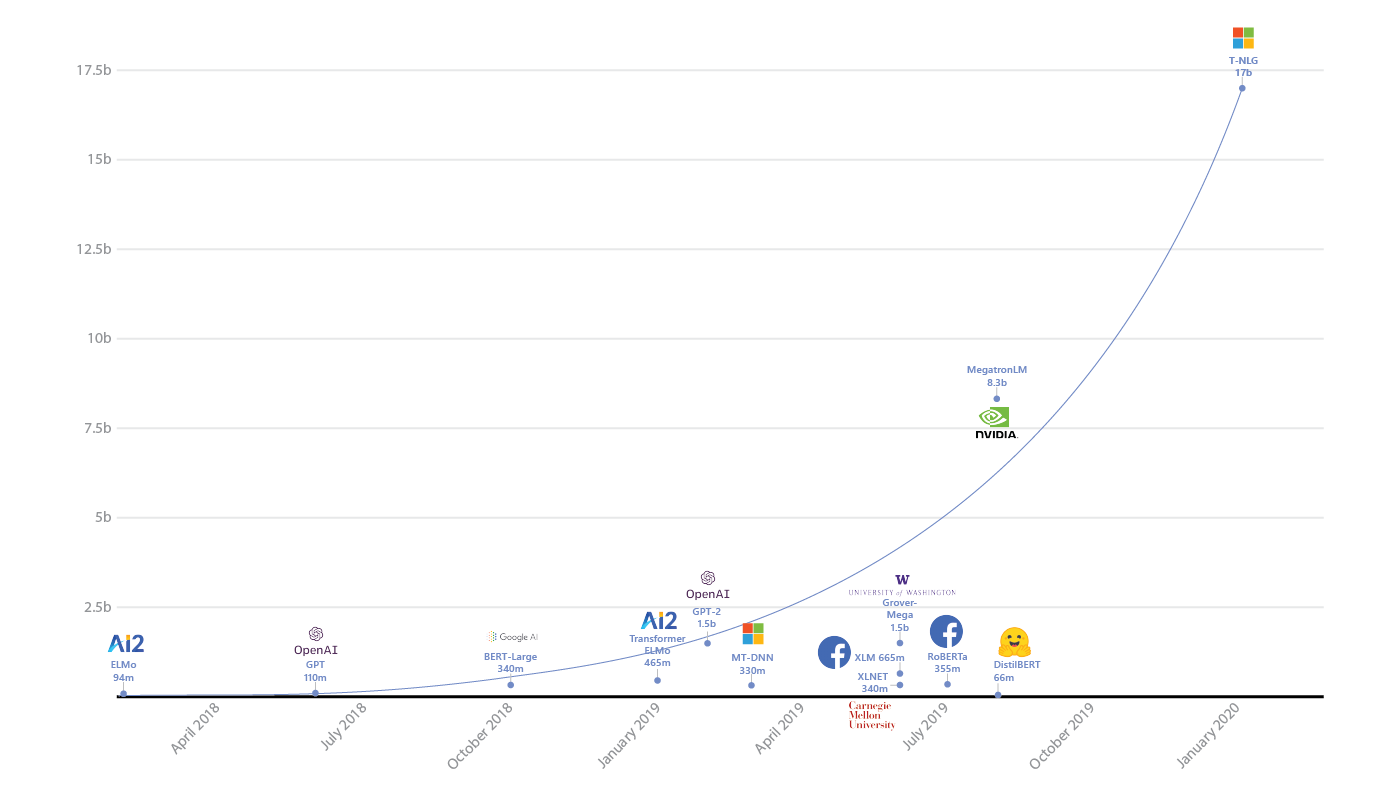
Et bien sûr, vous devez tenir compte du fait que si vous avez vraiment des données volumineuses, le modèle devrait être capable de travailler dessus - comment apprendre à partir de lots, ou avoir une sorte de mécanismes d'apprentissage distribués (et ainsi de suite). Et au même endroit, ne perdez pas trop de vitesse avec une augmentation de la quantité de données. Par exemple, nous savons que les méthodes du noyau nécessitent un carré de mémoire pour les calculs dans un double espace - si vous prévoyez une augmentation de 10 fois la taille des données, vous devriez réfléchir à deux fois pour savoir si vous tenez compte des ressources disponibles.
Disponibilité de modèles prêts à l'emploi
Un autre détail important est la recherche de modèles déjà entraînés qui peuvent être pré-entraînés, idéal si:
- Il n'y a pas beaucoup de données, mais elles sont très spécifiques à notre tâche - par exemple, des textes médicaux.
- Le sujet en général est relativement populaire - par exemple, mettre en évidence des sujets de texte - de nombreux travaux en PNL.
- Votre approche permet, en principe, un pré-apprentissage - comme par exemple avec certains types de réseaux de neurones.
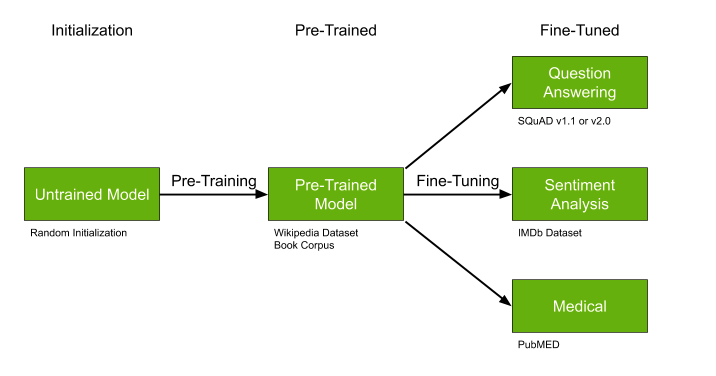
Les modèles pré-entraînés comme GPT-2 et BERT peuvent considérablement simplifier la solution de votre problème, et s'il existe des modèles déjà entraînés, je vous recommande vivement de ne pas passer et d'utiliser cette chance.
Interactions de caractéristiques et modèles linéaires
Certains modèles fonctionnent mieux lorsqu'il n'y a pas d'interactions complexes entre les entités - par exemple, toute la classe des modèles linéaires - Modèles additifs généralisés. Il existe une extension de ces modèles pour le cas de l'interaction de deux fonctionnalités appelées GA2M - Modèles additifs généralisés avec interactions par paires.
En règle générale, ces modèles donnent de bons résultats sur de telles données, sont parfaitement régularisés, interprétables et robustes au bruit. Par conséquent, il vaut vraiment la peine d'y prêter attention.
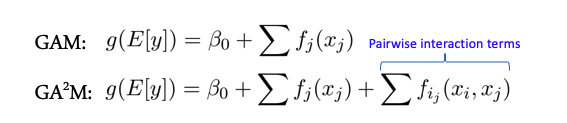
Cependant, si les signes interagissent activement en groupes de plus de 2, ces méthodes ne montrent plus d'aussi bons résultats.
Prise en charge des packages et des modèles
De nombreux algorithmes et modèles d'articles sympas se présentent sous la forme d'un module ou d'un package pour python, R, etc. Cela vaut vraiment la peine de réfléchir à deux fois avant d'utiliser et de s'appuyer sur une telle solution sur le long terme (je dis cela, en tant que personne qui a écrit de nombreux articles sur le ML avec un tel code). La probabilité que dans un an il n'y ait aucun soutien est très élevée, car l'auteur a très probablement besoin maintenant de s'engager dans d'autres projets, il n'y a pas de temps et aucune incitation à investir dans le développement du module ou du référentiel.
À cet égard, les bibliothèques à la scikit learn sont bonnes précisément parce qu'elles ont en fait un groupe de passionnés garanti et si quelque chose est sérieusement cassé, tôt ou tard, ils seront réparés.
Biais et équité
Parallèlement à la prise de décision automatique, les personnes insatisfaites de ces décisions prennent vie - imaginez que nous ayons une sorte de système de classement pour les demandes de bourse ou de recherche dans une université. Notre université sera inhabituelle - il n'y a que deux groupes d'étudiants: les historiens et les mathématiciens. Si tout à coup le système, sur la base de ses données et de sa logique, a soudainement distribué toutes les subventions aux historiens et ne les a accordées à aucun mathématicien, cela ne peut pas offenser les mathématiciens. Ils appelleront un tel système biaisé. Désormais, seuls les paresseux n'en parlent pas, et les entreprises et les gens se poursuivent.
Conventionnellement, imaginez un modèle simplifié qui compte simplement les citations des articles et laisse les historiens se citer activement - la moyenne est de 100 citations, mais il n'y a pas de mathématiques, ils ont une moyenne de 20 - et ils écrivent peu du tout, alors le système reconnaît tous les historiens comme «bons» car le taux de citations est élevé 100> 60 (moyenne), et les mathématiciens, comme «mauvais» car ils ont tous un taux de citation bien inférieur à la moyenne 20 <60. Un tel système peut difficilement sembler adéquat à quelqu'un.
Les classiques présentent désormais la logique de la prise de décision et des modèles de formation qui combattent une telle approche biaisée. Ainsi, pour chaque décision, vous avez une explication (conditionnelle) pourquoi elle a été prise et comment vous avez réellement fait un effort pour vous assurer que le modèle ne faisait pas de conneries (ELI5 GDPR).

En savoir plus sur Google ici, ou dans l'article ici .
En général, de nombreuses entreprises ont commencé de telles activités, en particulier à la lumière de la publication du RGPD - de telles mesures et contrôles peuvent aider à éviter des problèmes à l'avenir.
Si un sujet intéresse plus que d'autres - écrivez dans les commentaires, nous irons plus loin. (DFS)!
