Presque toutes les entreprises sont confrontées à une charge flottante: maintenant silence, puis grain. Vous n'avez pas besoin d'aller loin pour des exemples:
- le trafic de la boutique en ligne peut varier considérablement en fonction de l'heure de la journée ou de la saison;
- les services internes des entreprises peuvent être «vides» pendant des semaines, et à la veille de la remise du rapport trimestriel, leur fréquentation augmentera fortement.
Sous la coupe, parlons de la façon dont nous avons aidé nos clients à résoudre ce problème en introduisant un nouveau niveau de stockage avec des IOPS personnalisées.
Quelques mots sur les disques
Tous nos clients veulent plus ou moins une chose: obtenir une infrastructure fiable qui répond aux exigences des processus commerciaux à un bon prix. En tant que fournisseur de cloud, nous sommes donc confrontés à la tâche de créer des services et des services de manière à pouvoir trouver facilement la meilleure solution pour chaque client.
Auparavant, nous avions deux niveaux de stockage: st2 et gp2. Le chiffre «2» dans notre terminologie interne signifie une version plus récente et améliorée.
st2: Standard (HDD) - Support de disque dur SAS agréable et peu coûteux. Idéal pour les services où l'IOPS n'est pas critique, mais la bande passante est importante.
Leurs paramètres sont les suivants: temps de réponse - pas plus de 10 ms, performances des disques jusqu'à 2000 Go - 500 IOPS, de 2000 Go à 1000 IOPS, et la bande passante augmente avec chaque gigaoctet et atteint 500 Mo / s pour les mêmes 2000 Go.
gp2: Universal (SSD) - Disques SSD SAS plus chers et plus rapides. Convient aux clients dont les applications sont plus exigeantes en termes d'IOPS. Par exemple - bases de données de magasins en ligne.
Les paramètres Gp2 sont spécifiés dans le SLA. Les performances en IOPS sont calculées en volume - il y a 10 IOPS par Go. La barre supérieure est de 10 000 IOPS. Et le temps de réponse de ces disques n'est pas supérieur à 2 ms. Il s'agit d'une performance assez élevée, capable de réaliser 97% des tâches métier.
Au fil des années de travail, nous avons accumulé beaucoup de statistiques et d'expertise en relation avec les clients et avons remarqué que certains d'entre eux ne sont pas tout à fait à l'aise de choisir entre deux options d'entraînement. Par exemple, quelqu'un peut souhaiter de meilleures performances que 10 IOPS par gigaoctet. Ou une charge flottante ne permet pas de s'arrêter à l'un des types, et de payer pour être prêt pour les heures de pointe, mais la capacité périodiquement inactive n'est pas non plus une option.
Vous pouvez simuler un cas d'actualité simple. Pendant la pandémie, une entreprise a dû émettre des laissez-passer pour ses employés. Pour qu'ils puissent voyager en toute sécurité dans Moscou. Le personnel est important, deux mille personnes. Un ordre a été émis pour mettre à jour d'urgence les données personnelles dans le système CRM de l'entreprise. À peine dit que c'était fait. Plus d'un millier de personnes se sont précipitées simultanément pour mettre à jour les informations. Mais les gens économes étaient engagés dans le CRM. Peu de capacité a été allouée. Personne ne s'attendait à ce que plus de dix personnes y grimpent en même temps! Tout est tombé et n'a pas pu se relever un autre jour. Les processus commerciaux ont été perturbés, les gens sont assis chez eux et ont peur des amendes. Et s'il y avait une opportunité de «peaufiner» de manière flexible les performances des disques dans le cloud, ils augmenteraient les IOPS pendant une courte période, puis les rendraient tels quels, éliminant ou réduisant considérablement les temps d'arrêt du CRM.
D'une part, la situation est grotesque, le pourcentage de clients ayant de tels besoins n'est pas très important. Un petit fournisseur considérerait même leur existence comme une anomalie statistique et ne prendrait aucune mesure. D'autre part, l'organisation d'un nouveau niveau de stockage va nous permettre d'augmenter la flexibilité des services pour tous les clients. Cela signifie que nous devons le faire.
Si vous suivez notre blog depuis longtemps, vous vous souvenez probablement de l'article dans lequel nous avons parlé d'une série d'expériences avec Dell EMC ScaleIO (maintenant PowerFlex OS) et sa mise en œuvre dans le CROC Cloud. Quoi qu'il en soit, nous vous recommandons de vous familiariser avec celui-ci pour une compréhension générale.
En termes généraux, disons: ScaleIO (DellEMC renommé ScaleIO d'abord en VxFlex OS, et du 25 juin 2020 en PowerFlex OS) est un SDS de stockage défini par logiciel super polyvalent et fiable. La fiabilité est notre exigence n ° 0. Par conséquent, chaque nœud qui fait partie du pool de stockage est installé dans un rack séparé, ce qui élimine la possibilité de perte de données en cas de perte partielle d'alimentation dans le centre de données ou localement dans le rack.
Si un disque, un serveur ou un rack entier tombe en panne, nous aurons suffisamment de temps pour répliquer les données sur d'autres hôtes et remplacer par la suite l'élément défaillant. Si deux racks meurent à la fois, rien ne sera perdu de toute façon. Dans cette situation, le cluster passera en mode d'urgence, l'écriture et la lecture de données à partir des disques seront limitées, mais après la restauration de la connectivité avec le rack "crashé", PowerFlex OS prendra lui-même en charge le processus de reconstruction des données et de récupération du cluster. Ce processus, en passant, ne prend le plus souvent que quelques minutes.
Il s'agit bien sûr d'une situation d'urgence - les applications qui ne peuvent ni lire ni écrire "tomberont" immédiatement, mais la perte d'une si grande partie de l'infrastructure ne détruira pas les données. Même si la probabilité de défaillance de deux racks dans différentes parties de la salle des turbines est extrêmement faible, cela ne signifie pas qu'elle ne doit pas être prise en compte.
En termes de polyvalence, PowerFlex OS (anciennement ScaleIO) est également idéal pour nos exigences. En fait, il s'agit d'un constructeur, prêt à accepter n'importe quelle charge de travail et capable «d'accepter» les disques durs SATA / SAS lents, les disques SSD rapides et les disques NVME ultra-rapides. Et c'est vraiment vrai - il a été testé sur de nombreuses scènes et bancs d'essai d'équipes de développement et d'exploitation, vous pouvez assembler un cluster pratiquement à partir de
Musique de cinq à six
Jetons un coup d'œil à l'un des scénarios dans lesquels un client pourrait avoir besoin de performances flexibles avec un exemple réel. Parmi nos clients, il existe un réseau de magasins d'instruments de musique. Les techniciens de l'entreprise suivent le nombre de visiteurs qui visitent leur site chaque jour et heure. Cela se reflète même dans notre SLA: de 17h00 à 18h00, le magasin reçoit le maximum de clients, il ne devrait donc y avoir aucun travail technique ou temps d'arrêt.
La pratique de calcul standard consiste à diviser 100% de la charge sur 24 heures. Il s'avère environ 4% pour chaque heure. Pour une chaîne de magasins de musique, cette heure particulière "pèse" non pas 4, mais 10% - cela représente des dizaines de milliers de visiteurs et de clients.
En conséquence, il serait très pratique pour le client que, à cette heure "dorée", ses disques deviennent plus rapides comme par magie,
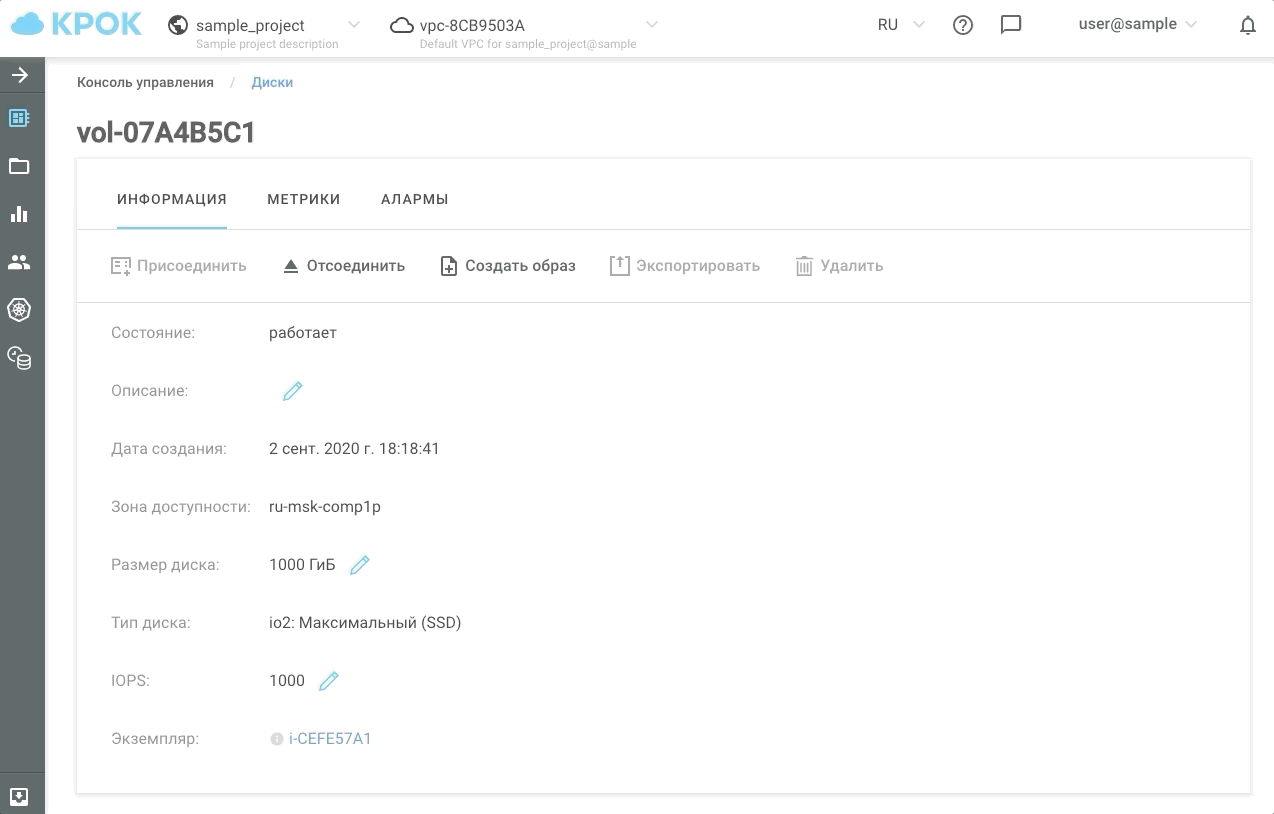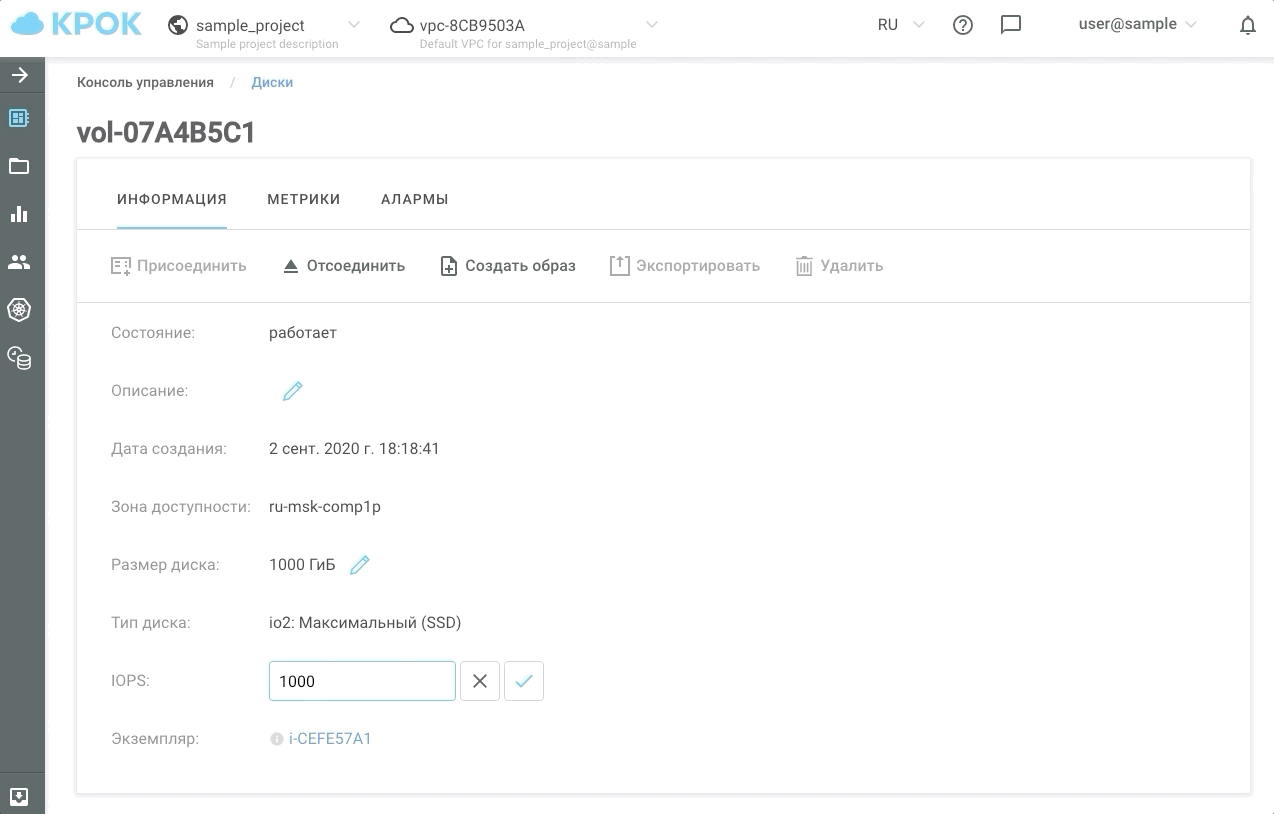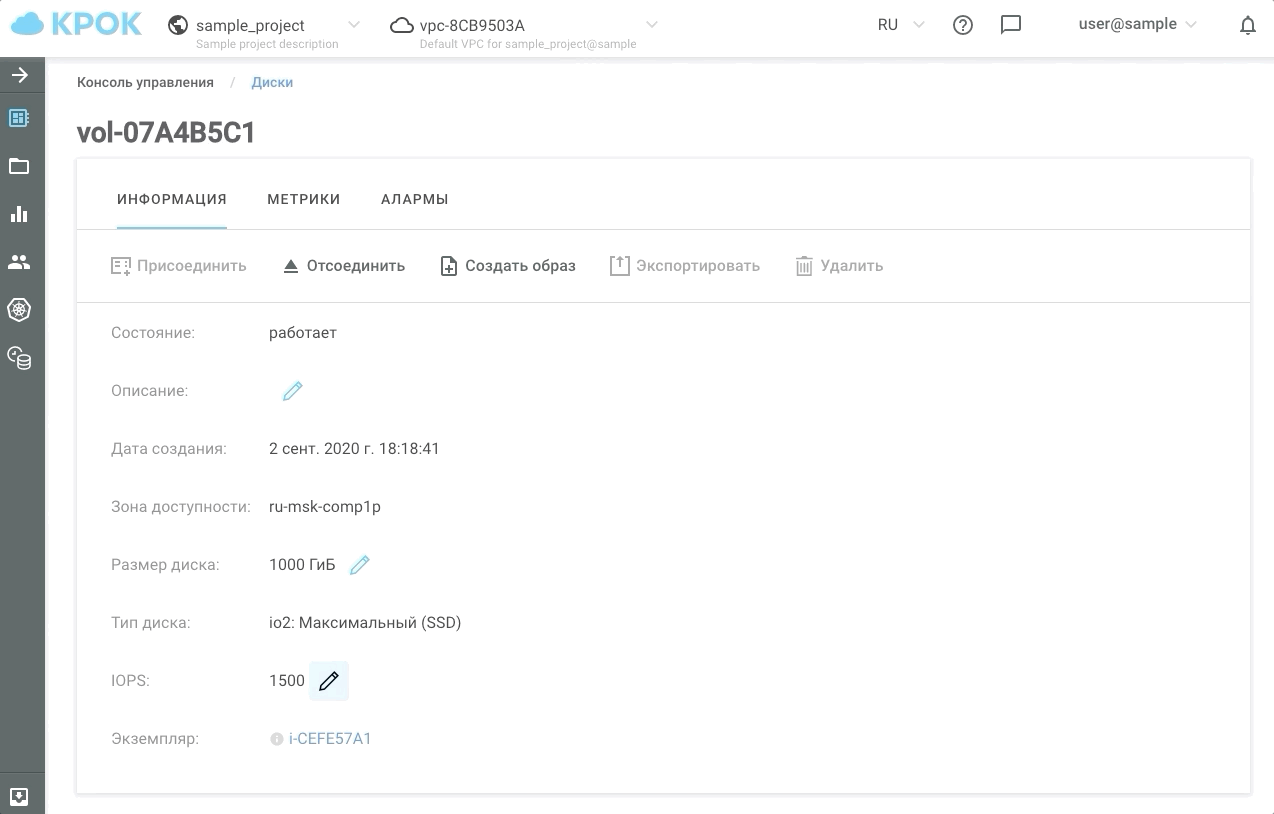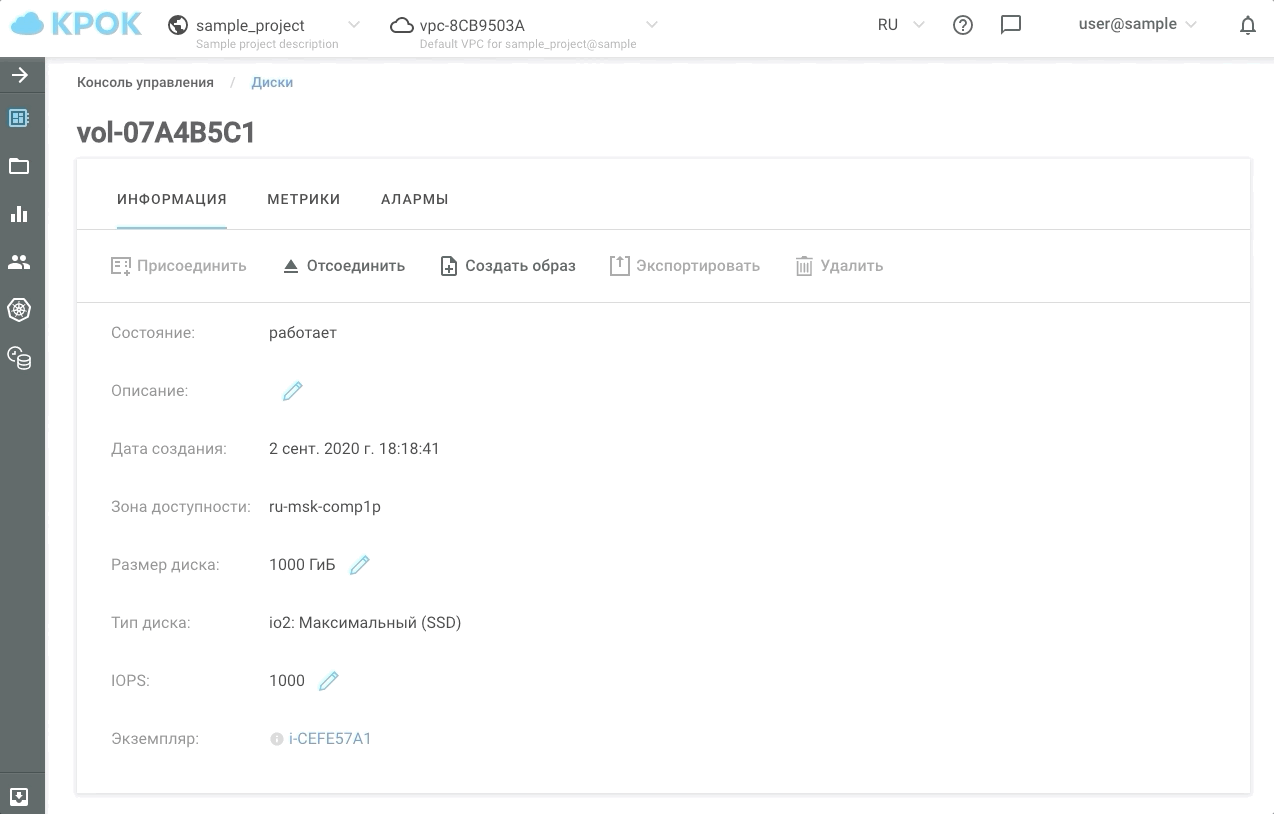
Nous avons maintenant la possibilité de donner aux clients au moins 30, au moins 50000 IOPS pendant les heures les plus chargées, et le reste du temps pour maintenir les performances au niveau habituel. Nous avons appelé ce type de stockage io2: Ultimate (SSD). Le temps de réponse des disques basés sur ce type de stockage n'est pas supérieur à 1 ms!
Et encore une fois sur la fiabilité: st2, gp2 et le nouvel io2 sont indépendants, indépendants les uns des autres pools de stockage dans un cluster PowerFlex.
Si auparavant le client a sélectionné un disque et a reçu une performance fixe, il peut maintenant le sélectionner et le configurer, performance. Quel que soit le volume. La philosophie est la suivante: vous pouvez obtenir un disque énorme et rapide auprès d'un grand nombre de fournisseurs, mais êtes-vous prêt à payer pour cela 100% du temps?
Comment gérer
Il existe deux façons de gérer les performances: à l'ancienne, via l'interface Web et à l'aide de l'API. Cela permet d'écrire des scripts simples qui "accéléreront" ou "ralentiront" les disques selon un calendrier et, par conséquent, vous feront économiser de l'argent.
Alors qu'auparavant nous pouvions prendre n'importe quelle charge demandée par le client, maintenant nous pouvons le faire au meilleur prix.
Voilà à quoi cela ressemble dans la pratique.
Augmenter l'adaptabilité de l'infrastructure cloud est une tendance pertinente et très correcte. Vous ne pouvez pas dire au client: "Prenez ce qu'il donne, ou même cela n'arrivera pas!" Il doit être en mesure de décider de quelles ressources, quand et combien il a besoin. L'avenir réside dans ces solutions flexibles et fiables.
Nous nous portons garant de nos services: tous les paramètres sont précisés dans le SLA, et vous pouvez compter sur le fait que les chiffres «papier» ne divergeront pas des chiffres réels.
Et comment vérifier votre fournisseur de cloud, nous l'avons déjà écrit dans l' article précédent .