Supposons que nous ayons un registre de documents avec lesquels les opérateurs ou les comptables de VLSI travaillent , comme ceci: Traditionnellement, dans un tel affichage, un tri direct (nouveau par le bas) ou inversé (nouveau par le haut) par date et identifiant ordinal attribué lors de la création d'un document est utilisé - ou ... J'ai déjà discuté des problèmes typiques qui se posent dans ce cas dans l'article Antipatterns PostgreSQL: Naviguer dans le registre . Mais que se passe-t-il si l'utilisateur, pour une raison quelconque, voulait "atypique" - par exemple, trier un champ "comme ça" et un autre "comme ça" -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? Mais nous ne voulons pas créer le deuxième index, car cela ralentit l'insertion et le volume supplémentaire dans la base de données.
Est-il possible de résoudre efficacement ce problème en utilisant uniquement l'index
(dt, id)?
Commençons par esquisser l'ordre de notre index:
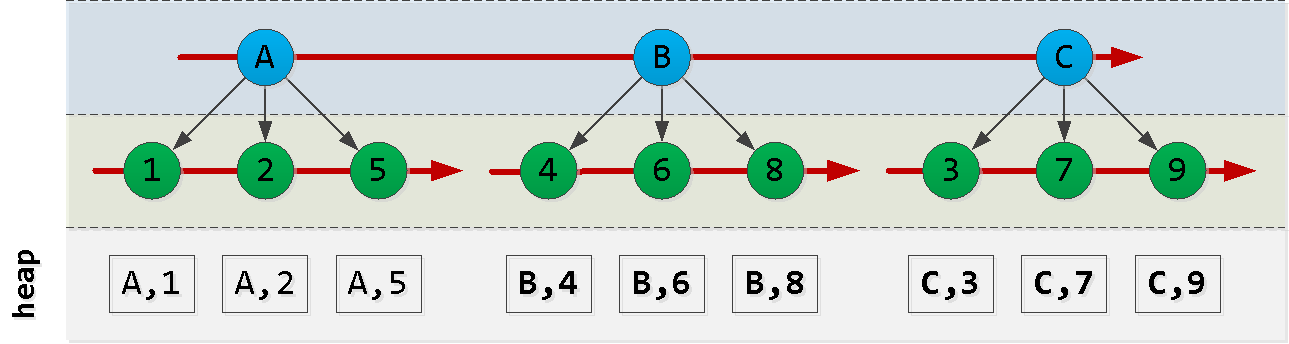
notez que l'ordre dans lequel les entrées id sont créées ne correspond pas nécessairement à l'ordre de dt, nous ne pouvons donc pas nous y fier et nous devrons inventer quelque chose.
Supposons maintenant que nous soyons au point (A, 2) et que nous voulions lire les 6 entrées "suivantes" dans le tri : Aha! Nous avons sélectionné un "morceau" du premier nœud , un autre "morceau" du dernier nœud et tous les enregistrements des nœuds entre eux ( ). Chacun de ces blocs est lu avec succès par index , malgré l'ordre pas tout à fait approprié. Essayons de construire une requête comme celle-ci:
ORDER BY dt, id DESC
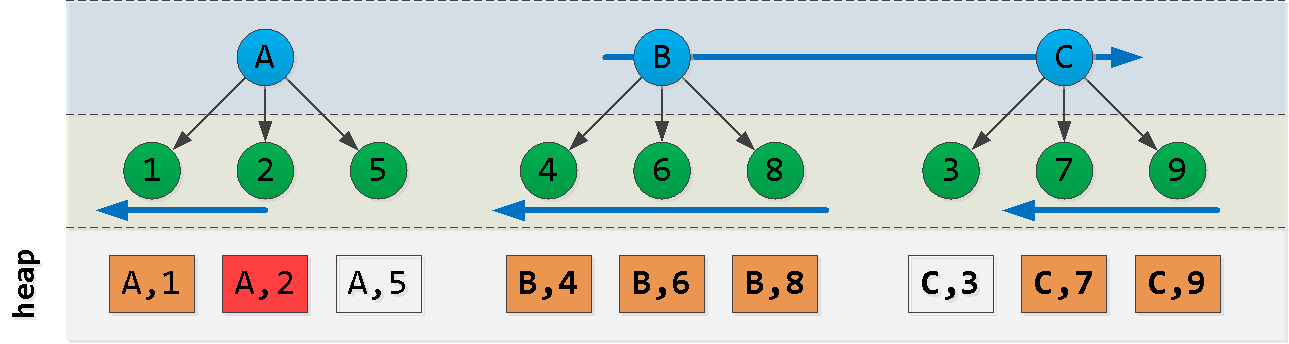
ACB(dt, id)
- nous lisons d'abord depuis le bloc A "à gauche" de l'enregistrement de départ - nous obtenons des
Nenregistrements - plus loin, nous lisons
L - N"à droite" de la valeur A - trouver dans le dernier bloc la clé maximale C
- filtrer tous les enregistrements de la sélection précédente avec cette touche et la soustraire «à droite»
Essayons maintenant de décrire dans le code et de vérifier le modèle:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);Afin de ne pas calculer le nombre d'enregistrements déjà lus et la différence entre celui-ci et le nombre cible, forçons PostgreSQL à le faire en utilisant un "hack"
UNION ALLet LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Maintenant, collectons les 100 enregistrements suivants avec un tri cible à partir de la dernière valeur connue:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Voyons ce qui s'est passé en termes de:

[regardez explic.tensor.ru]
- Donc,
A = '2019-09-07'nous lisons 3 enregistrements en utilisant la première clé . - Ils ont fini de lire 97 autres par
Bet enCraison de la frappe exacteIndex Scan. - Parmi tous les enregistrements, 18 ont été filtrés par la clé maximale
C. - Nous avons lu 23 enregistrements (au lieu de 18 recherchés
Bitmap Scan) en utilisant la clé maximale. - Tous ont été triés et coupés les 100 enregistrements cibles.
- ... et tout cela a pris moins d'une milliseconde!
La méthode, bien sûr, n'est pas universelle et avec des index sur un plus grand nombre de champs, elle se transformera en quelque chose de vraiment terrible, mais si vous voulez vraiment donner à l'utilisateur un tri «non standard» sans «réduire» la base dans
Seq Scanune grande table, vous pouvez l'utiliser avec précaution.