
Avec la transition vers l'auto-isolement en mars de cette année, nous, comme de nombreuses entreprises, avons mis en ligne tous nos événements d'épicerie. Eh bien, vous vous souvenez de cette merveilleuse image sur les webinaires avec des singes. Au cours des six derniers mois, uniquement sur le thème des centres de données, dont mon équipe est responsable, nous avons accumulé environ 25 webinaires enregistrés de 2 heures, 50 heures de vidéo au total. Le problème qui s'est soulevé en pleine croissance est de savoir comment comprendre dans quelle vidéo chercher des réponses à certaines questions. Le catalogue, les balises, une courte description sont bons, eh bien, on a finalement trouvé qu'il y avait 4 vidéos de deux heures sur le sujet, et puis quoi? Regarder en rembobinage? Est-ce possible d'une manière ou d'une autre? Et si vous agissez de manière à la mode et essayez de visser l'IA?
Spoiler pour les impatients : je n'ai pas pu trouver un système miracle complet ou l'assembler sur mon genou, et puis il n'y aurait aucun intérêt à cet article. Mais à la suite de plusieurs jours (ou plutôt des soirées) de recherche, j'ai obtenu un MVP fonctionnel, dont je veux vous parler. Le but de l'article est d'examiner le niveau d'intérêt pour la question, d'obtenir des conseils de personnes bien informées et peut-être de trouver quelqu'un d'autre qui a le même problème.
Ce que je veux faire
À première vue, tout semblait simple: vous prenez une vidéo, vous la faites passer par le réseau neuronal, obtenez un texte, puis recherchez un fragment dans le texte qui décrit le sujet d'intérêt. Il serait encore plus pratique de rechercher toutes les vidéos du catalogue à la fois. En fait, il a été inventé pour télécharger des transcriptions du texte avec les vidéos pendant longtemps, Youtube et la plupart des plates-formes éducatives peuvent le faire, même s'il est clair que les gens éditent ces textes. Vous pouvez scanner rapidement le texte avec vos yeux et comprendre s'il y a une réponse à la question souhaitée. Probablement, à partir d'une fonctionnalité pratique, il ne serait pas mal de pouvoir pousser le lieu d'intérêt dans le texte et d'écouter ce que le conférencier y dit et y montre, ce n'est pas non plus difficile s'il y a un balisage des mots dans le temps, où ils sont dans le texte. Eh bien, je rêvais - parlons des pistes de développement possibles à la fin,et maintenant essayons simplement d'implémenter la chaîne le plus efficacement possible
fichier vidéo -> fragment de texte -> recherche de texte flou .
Au début, je pensais que, puisque tout est si simple et que ce cas est discuté dans toutes les conférences sur l'IA depuis déjà 4 ans, de tels systèmes devraient exister tout faits. Quelques heures de recherche et de lecture d'articles ont montré que ce n'était pas le cas. La vidéo est principalement utilisée pour rechercher des visages, des voitures et d'autres objets visuels (masques / casques) et de l'audio - chansons, pistes, ainsi que le ton / l'intonation de l'orateur, dans le cadre de solutions pour les centres d'appels. Il était possible de ne trouver que cette mention du système Deepgram . Mais elle, malheureusement, ne prend pas en charge la langue russe. De plus, Microsoft a des fonctionnalités très similaires dans Streams , mais je n'ai trouvé nulle part de mention de la prise en charge de la langue russe, apparemment, ce n'est pas là non plus.
D'accord, réinventons. Je ne suis pas un programmeur professionnel (et d'ailleurs j'accepterai volontiers les critiques constructives sur le code), mais de temps en temps j'écris quelque chose «pour moi». Les réseaux neuronaux capables de convertir la parole en texte sont appelés (surprise surprise), parole en texte . Si vous pouvez trouver un service de synthèse vocale public, vous pouvez l'utiliser pour «numériser» la parole dans tous les webinaires, puis effectuer une recherche floue dans le texte - une tâche plus facile. J'avoue qu'au début je ne pensais pas «monter dans le cloud», je voulais tout collecter localement, mais après avoir lu cet article sur Habré, j'ai décidé que la reconnaissance vocale se faisait vraiment mieux dans le cloud.
Recherche de services cloud pour la synthèse vocale
La recherche de services capables de faire de la synthèse vocale a montré qu'il existe de nombreux systèmes de ce type, y compris ceux développés en Russie, il existe également des fournisseurs mondiaux de cloud comme Google , Amazon , MS Azure parmi eux . Les descriptions de plusieurs services, y compris ceux en langue russe , sont ici . En général, les 20 premières lignes des résultats des moteurs de recherche seront uniques. Mais il y a un autre hic - je voudrais lancer ce système en production à l'avenir, c'est un coût, et je travaille pour Cisco, qui a globalement des contrats avec les principaux clouds. Donc, à partir de la liste entière, j'ai décidé de ne considérer qu'eux pour l'instant.
Donc ma liste a été réduite à Google , Amazon , Azure ,IBM Watson (les liens vers les titres sont les mêmes que dans le tableau ci-dessous). Tous les services ont des API via lesquelles ils peuvent être utilisés. Après avoir analysé le reste des possibilités, j'ai compilé un petit tableau:

IBM Watson a quitté la course à ce stade, puisque tous les enregistrements que j'ai en russe, il a été décidé de tester le reste des fournisseurs dans un court extrait du webinaire. J'ai configuré des comptes dans AWS et Azure. Pour l'avenir, je dirai que Microsoft s'est avéré être un dur à cuire en termes de création de compte. J'ai travaillé à partir d'un réseau d'entreprise qui "atterrit" sur Internet quelque part à Amsterdam, pendant le processus d'inscription, on m'a demandé à deux reprises si j'étais sûr que mon adresse était la Russie, après quoi le système a affiché un message indiquant que le compte était en blocage administratif "en attente de clarification" ... Au bout de 5 jours, alors que j'écrivais cet article, la situation n'a pas changé, donc je n'ai pas encore pu tester Azure, ce qui est dommage! Je comprends - la sécurité, mais cela ne m'a pas encore permis d'essayer le service. J'essaierai de le faire plus tard, lorsque la situation sera résolue.
Par ailleurs, je voudrais tester une telle fonction dans Yandex.Cloud, leur reconnaissance de la parole russe, en théorie, devrait être la meilleure. Mais, malheureusement, sur la page d'accès de test du service, il n'y a que la possibilité de "dire" le texte, le téléchargement du fichier n'est pas fourni. Donc, nous reporterons ensemble avec Azure en second lieu.
Donc, il y a Google et Amazon, testons-le bientôt! Avant d'écrire un code, vous pouvez tout vérifier et tout comparer à la main, les deux fournisseurs, en plus de l'API, disposent d'une interface administrative. Pour le test, j'ai d'abord préparé un fragment de 10 minutes de nature générale, si possible, avec un minimum de terminologie spécialisée. Mais il s'est avéré que Google prend en charge un fragment allant jusqu'à 1 minute en mode test, j'ai donc utilisé ce fragment de 57 secondes pour comparer les services .
Sur la base des résultats du travail, les deux services émettent le texte reconnu, vous pouvez comparer les résultats de leur travail à une minute d'intervalle.
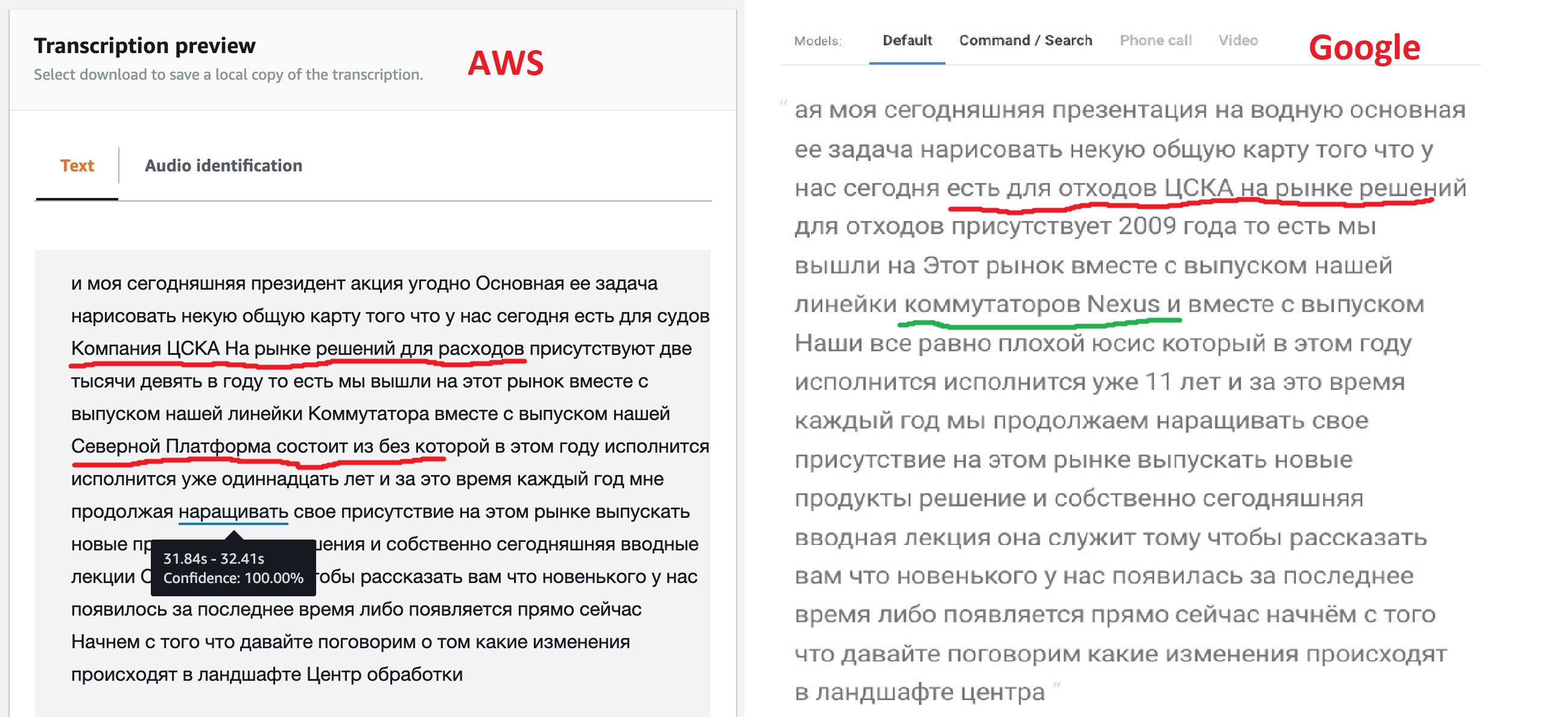
Le résultat, franchement, n'est pas comme prévu, mais ce n'est pas pour rien que les modèles offrent différentes options pour leur personnalisation. Comme on peut le voir, le moteur Google "out of the box" a reconnu plus clairement la plupart du texte, il a également réussi à voir les noms de certains produits, mais pas tous. Cela suggère que leur modèle permet un texte multilingue. Amazon (plus tard, cela a été confirmé) n'a pas une telle opportunité - ils ont dit russe, ce qui signifie que nous allons chanter: "Kin babe lom" et point!
Mais la possibilité de se faire taguer JSON qu'Amazon fournit m'a semblé très intéressante. Après tout, cela permettra à l'avenir d'implémenter une transition directe vers la partie du fichier où le fragment souhaité a été trouvé. Peut-être que Google a également une telle fonction, car tous les réseaux de neurones de reconnaissance vocale fonctionnent de cette façon, mais une recherche rapide dans la documentation n'a pas réussi à trouver cette fonctionnalité.

En regardant ce JSON, vous pouvez voir qu'il se compose de trois sections: le texte traduit (transcription), un tableau de mots (éléments) et un ensemble de segments (segments). Pour un tableau de mots et de segments pour chaque élément, ses heures de début et de fin sont indiquées, ainsi que la confiance du réseau neuronal (confiance) qu'il l'a correctement reconnu.
Enseigner à un réseau neuronal pour comprendre les centres de données
Donc, à la fin de cette étape, j'ai décidé de choisir Amazon Transcribe pour d'autres expériences et d'essayer de mettre en place un modèle d'apprentissage. Et si vous ne parvenez pas à obtenir une reconnaissance stable, faites affaire avec Google. Des tests supplémentaires ont été réalisés sur un fragment de 10 minutes.
AWS Transcribe a deux possibilités pour régler ce que le réseau neuronal reconnaît et quelques fonctionnalités supplémentaires pour le post-traitement du texte:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
J'ai donc décidé de faire mon propre mot pour le texte. Évidemment, il inclura des mots tels que «réseau, serveurs, profils, centre de données, appareil, contrôleur, infrastructure». Après 2-3 tests, mon vocabulaire est passé à 60 mots. Ce dictionnaire doit être créé dans un fichier texte ordinaire, un mot par ligne, le tout en majuscules. Il existe également une option plus complexe ( décrite ici ) avec la possibilité de spécifier comment le mot est prononcé, mais au stade initial, j'ai décidé de le faire avec une liste simple.
Avant d'utiliser un dictionnaire, vous devez le créer. Dans l'onglet Vocabulaire personnalisé d' Amazon Transcribe, cliquez sur Créer un vocabulaire , chargez le texte de notre fichier, spécifiez la langue russe, répondez au reste des questions et le processus de création d'un dictionnaire commence. Une fois qu'il est sortiLe traitement devient prêt - le dictionnaire peut être utilisé.
La question demeure: comment reconnaître les termes «anglais»? Permettez-moi de vous rappeler que le dictionnaire ne prend en charge qu'une seule langue. Au début, j'ai pensé créer un dictionnaire séparé avec des termes anglais et y passer le même texte. Lorsque des termes comme Cisco , VLAN , UCS sont détectésetc. c taux de probabilité 100% - prenez-les pour le fragment de temps donné. Mais je dirai tout de suite - cela n’a pas fonctionné, l’analyseur de langue anglaise n’a pas reconnu plus de la moitié des termes du texte. Après réflexion, j'ai décidé que c'était logique, puisque nous prononçons tous ces termes avec un «accent russe», même les anglo-américains ne nous comprennent pas la première fois. Cela a incité l'idée d'ajouter simplement ces termes au dictionnaire russe selon le principe «tel qu'il est entendu, donc il est écrit». Cisco , usies , eisiai , vilan , viikslan - après tout, nous le disons en toute honnêteté lorsque nous communiquons entre nous. Cela a augmenté le dictionnaire de quelques dizaines de mots, mais pour l'avenir, cela a amélioré la qualité de la reconnaissance d'un ordre de grandeur!
Comme le dit le dicton, "une bonne pensée vient après" , le premier dictionnaire a déjà été créé, j'ai donc décidé d'en créer un autre, en y ajoutant toutes les abréviations et en comparant ce qui se passe.
Reconnaissance à partir d'un dictionnaire est tout aussi facile, dans le Transcrire le service sur le travail de transcription onglet, sélectionnez Créer tâche , spécifiez la langue russe, et ne pas oublier de préciser le dictionnaire nous avons besoin. Une autre action utile - vous pouvez demander au réseau de neurones de nous donner plusieurs résultats de recherche alternatifs, l'élément Résultats alternatifs - Oui , j'ai défini 3 options alternatives. Plus tard, lorsque je ferai des recherches de texte flou, cela me sera utile.
Diffuser un texte de 10 minutes prend 4 à 5 minutes, pour ne pas perdre de temps, j'ai décidé d'écrire un petit outil qui faciliterait le processus de comparaison des résultats. J'afficherai le texte final du fichier JSON dans le navigateur, soulignant simultanément la «fiabilité» de la détection des mots individuels par le réseau neuronal (le même paramètre de confiance ). J'ai trois options pour le texte résultant: la traduction par défaut, un dictionnaire sans termes et un dictionnaire avec des termes. Laissez les trois textes être affichés simultanément dans trois colonnes. Je souligne les mots avec une fiabilité supérieure à 95% en vert, de 95% à 70% en jaune, inférieure à 70% en rouge. Le code compilé à la hâte de la page HTML résultante est ci-dessous, les fichiers JSON doivent être dans le même répertoire que le fichier. Les noms de fichiers sont spécifiés dans les variables FILENAME1, etc.
Code de page HTML pour afficher les résultats
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Je télécharge les fichiers asrOutput.json pour les trois tâches, je les renomme comme écrit dans le script HTML, et voici ce qui se passe.

On voit clairement que l'ajout de termes en russe a permis au réseau neuronal de reconnaître plus précisément des termes spécifiques - " profil de service ", etc. Et l'ajout de la transcription russe dans la deuxième étape a transformé le CSKA en cisco . Le texte est encore assez "sale", mais pour ma tâche de recherche de contexte, il devrait déjà convenir. Au fur et à mesure que de nouveaux webinaires sont ajoutés et lus, le vocabulaire s'élargira progressivement, c'est un processus de maintien d'un tel système qu'il ne faut pas oublier.
Recherche floue dans le texte reconnu
Il existe probablement une douzaine d'approches pour résoudre le problème de la recherche floue, pour la plupart basées sur un petit ensemble d'algorithmes mathématiques, comme par exemple la distance de Levenshtein. bon article à ce sujet , un de plus et un de plus . Mais je voulais trouver quelque chose de prêt, comme lancé et fonctionne.
A partir de solutions prêtes à l'emploi pour la recherche de documents locaux, après un peu de recherche, j'ai trouvé un projet SPHINX relativement ancien , aussi la possibilité de recherche en texte intégral, semble-t-il, est dans PostgreSQL, il est écrit à ce sujet ICI . Mais la plupart des documents, y compris en russe, ont été trouvés sur Elasticsearch . Après avoir lu de bons guides de démarrage et d'installation commeCet article ou cette leçon , en voici une autre , ainsi que la documentation et le manuel de l'API pour Python , j'ai décidé de l'utiliser.
Pour toutes les expériences locales, j'utilise Docker depuis longtemps et je recommande vivement à tous ceux qui, pour une raison quelconque, ne l'ont pas encore compris, de le faire. En fait, j'essaye de n'exécuter rien d'autre que des environnements de développement, des navigateurs et des "visualiseurs" dans le système d'exploitation local. Outre l'absence de problèmes de compatibilité, etc. cela vous permet d'essayer rapidement un nouveau produit et de voir s'il fonctionne bien.
Nous téléchargeons le conteneur avec Elasticsearch et l'exécutons avec deux commandes:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
Après le démarrage du conteneur,
http://localhost:9200l'interface élastique apparaît à l'adresse , elle est accessible via un navigateur ou l'API REST d'un outil POSTMAN. Mais j'ai trouvé un plugin Chrome pratique .
Voici à quoi ressemble la fenêtre du plugin avec l' exemple de chatons drôles décrit dans l'un des guides ci-dessus .
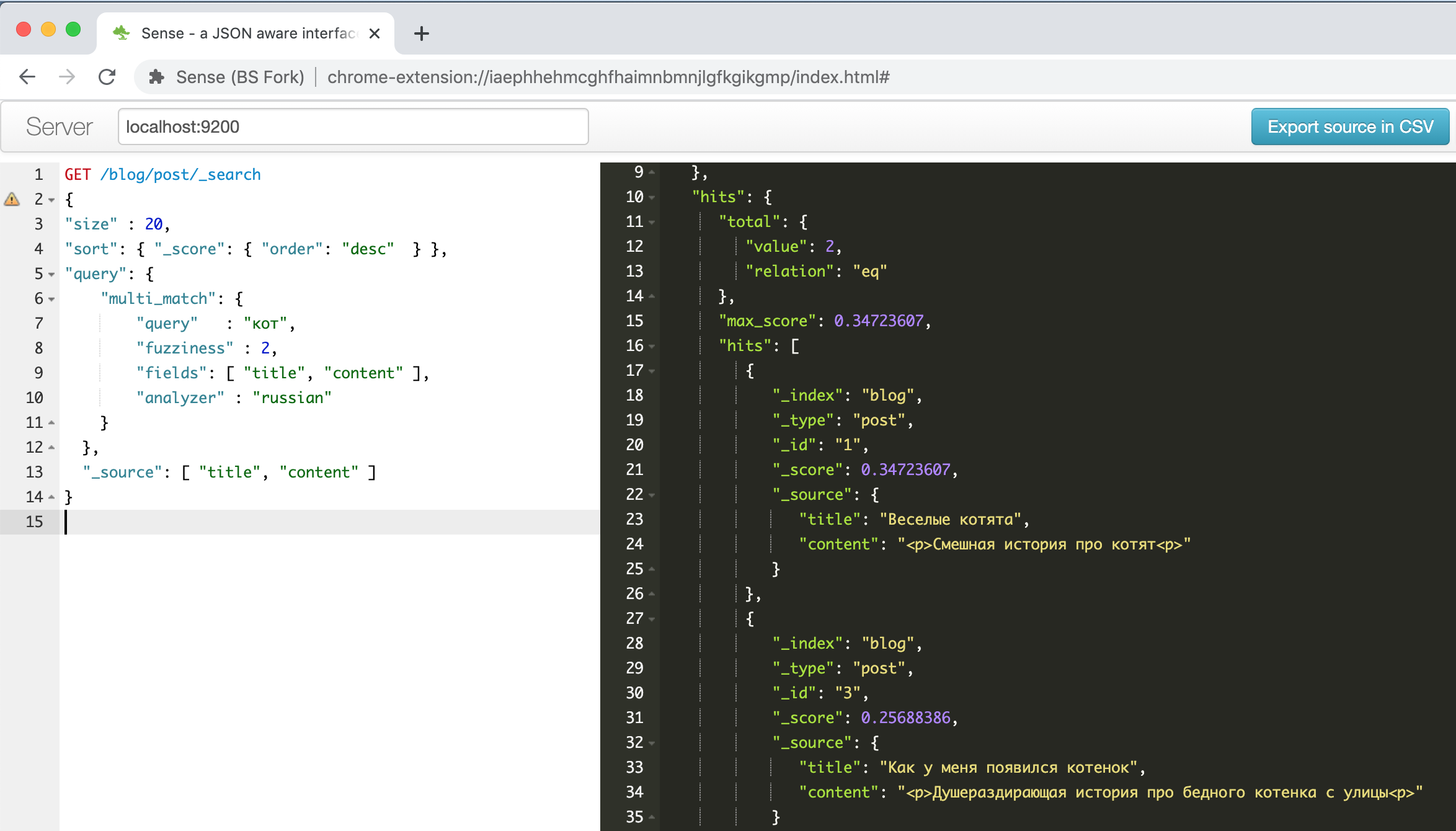
Sur la gauche se trouve une demande - à droite une réponse, la saisie semi-automatique, la coloration syntaxique, la mise en forme automatique - que faut-il d'autre pour être productif! De plus, ce plugin peut reconnaître le format de ligne de commande CURL dans le texte collé à partir du presse-papiers et le formater correctement, par exemple, essayez de coller la ligne
" curl -X GET $ ES_URL " et voyez ce qui se passe. Une chose pratique, en général.
Quoi et comment vais-je stocker et rechercher?Elasticsearch prend tous les documents au format JSON et les stocke dans des structures appelées index. Il peut y avoir autant d'index différents que vous le souhaitez, mais un index peut contenir des données et des documents homogènes, avec une structure de champs similaire et la même approche de recherche.
Pour étudier les possibilités de recherche floue, j'ai décidé de télécharger et de rechercher la section phrase (segments) du fichier de transcription obtenu à l'étape précédente. Dans la section segments du fichier JSON, les données sont stockées au format suivant:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
Je veux augmenter la probabilité d'une recherche réussie, donc je téléchargerai toutes les options alternatives dans la base de données pour la recherche, puis parmi les fragments trouvés, je choisirai celui avec la confiance totale la plus élevée.
Pour reformater et charger un document JSON dans Elasticsearch, j'utilise un petit script Python, la logique du script est la suivante:
- Tout d'abord, nous passons en revue tous les éléments de la section segments et toutes les options de transcription alternatives
- Pour chaque option de transcription, nous considérons sa confiance de reconnaissance totale, je prends simplement la moyenne arithmétique pour les mots individuels, bien que, probablement, à l'avenir, cela doive être abordé plus attentivement
- Pour chaque option de transcription alternative, chargez un enregistrement du formulaire dans Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Script Python qui charge les enregistrements d'un fichier JSON dans Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Si vous n'avez pas Python, ne vous découragez pas, Docker nous aidera à nouveau. J'utilise généralement un conteneur avec un notebook Jupyter - vous pouvez vous y connecter avec un navigateur ordinaire et faire tout ce que vous devez faire, la seule chose à laquelle vous devez penser à enregistrer les résultats, car lorsque le conteneur est détruit, toutes les informations sont perdues. Si vous n'avez jamais travaillé avec cet outil auparavant, alors voici un bon article pour les débutants , en passant, vous pouvez sauter en toute sécurité la section sur l'installation.Nous
démarrons un conteneur avec un notebook Python avec la commande:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
Et nous nous y connectons avec n'importe quel navigateur à l'adresse que nous voyons à l'écran après le lancement réussi du script, c'est
http://127.0.0.1:8888avec la clé de sécurité spécifiée.
Nous créons un nouveau bloc-notes, dans la première cellule, nous écrivons:
!pip install elasticsearch
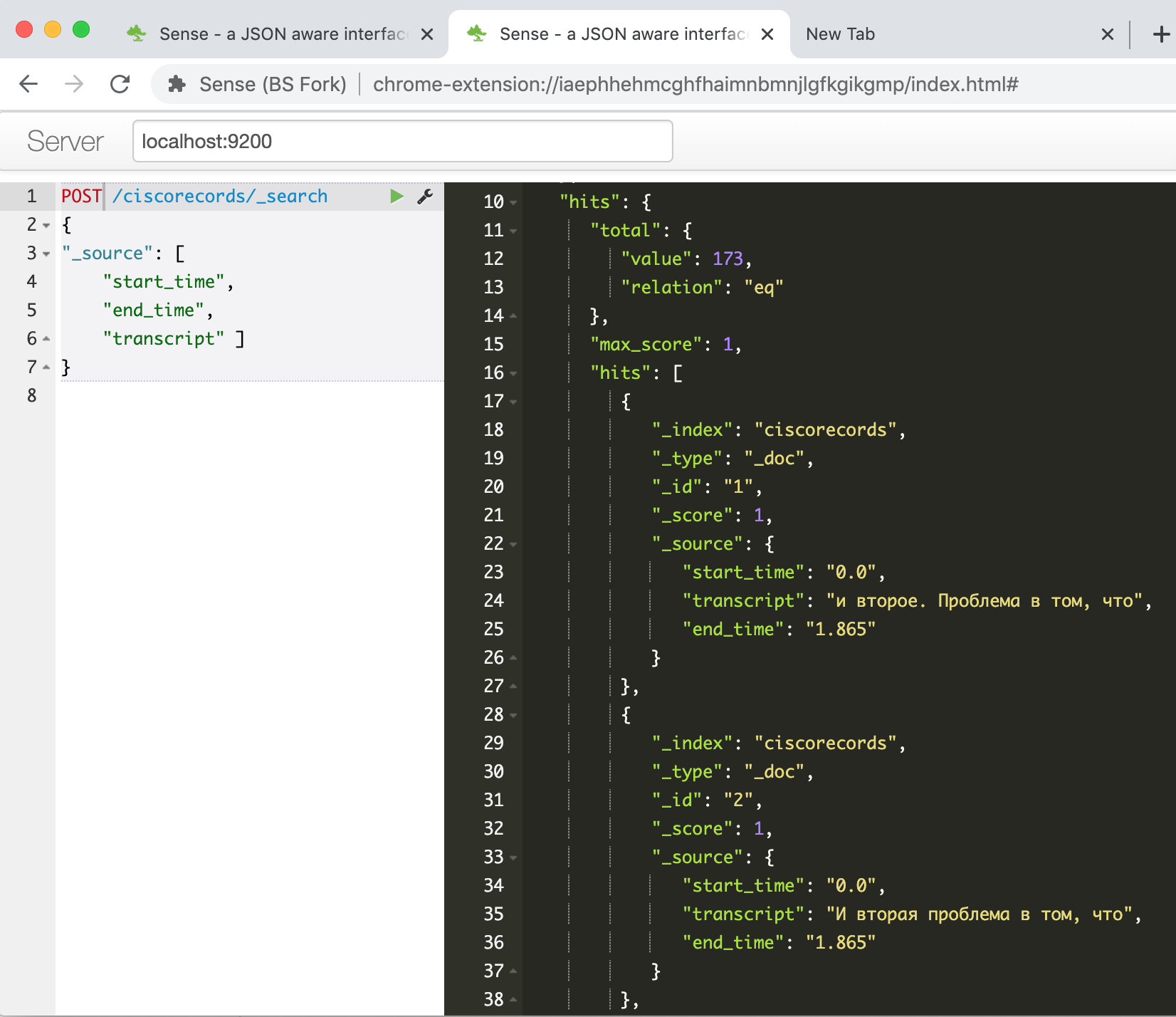
Exécutez, attendez que le package pour travailler avec ES via l'API soit installé, copiez notre script dans la deuxième cellule et exécutez-le. Après son travail, si tout réussit, nous pouvons vérifier dans la console Elasticsearch que nos données ont bien été chargées. Nous entrons dans la commande
GET /ciscorecords/_searchet voyons nos enregistrements chargés dans la fenêtre de réponse, un total de 173 pièces, comme le champ hits.total.value nous l'indique .
Il est maintenant temps d'essayer la recherche floue - c'est de cela qu'il s'agissait. Par exemple, pour rechercher l'expression «cœur du réseau du centre de données», vous devez donner la commande suivante:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
Nous obtenons jusqu'à 47 résultats!

Pas étonnant, car la plupart d'entre eux sont des variantes différentes du même fragment. Écrivons un autre script pour sélectionner dans chaque segment un enregistrement avec la valeur de confiance la plus élevée.
Script Python pour interroger la base de données Elasticsearch
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Exemple de sortie:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
Nous voyons que les résultats sont devenus beaucoup plus petits, et maintenant nous pouvons les visualiser et sélectionner celui qui nous intéresse le plus.
De plus, étant donné que nous avons l'heure de début et de fin du fragment vidéo, nous pouvons créer une page avec un lecteur vidéo et la «rembobiner» par programmation vers le fragment d'intérêt.
Mais je mettrai cette tâche dans un article séparé s'il y a un intérêt pour d'autres publications sur ce sujet.
Au lieu d'une conclusion
Ainsi, dans le cadre de cet article, j'ai montré comment j'ai résolu le problème de la construction d'un système de recherche textuelle à l'aide d'un outil vidéo avec des enregistrements de webinaires sur des sujets techniques. Le résultat est ce que l'on appelle habituellement MVP, c'est-à-dire l'algorithme de travail minimum qui vous permet d'obtenir un résultat et prouve que le résultat est, en principe, réalisable avec les technologies existantes.
Il y a encore un long chemin à parcourir vers le produit final, à partir d'idées pouvant être mises en œuvre dans un futur proche:
- Vissez le lecteur vidéo pour pouvoir écouter, visualiser le fragment trouvé
- Pensez à la possibilité de modifier du texte, alors que vous pouvez laisser un ancrage au texte des mots reconnus à 100%, ne modifiez que les fragments où la qualité de reconnaissance «s'affaiblit»
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
Si vous avez des questions / commentaires, je serai heureux d'y répondre, et je serai également heureux d'entendre toutes les suggestions pour améliorer ou simplifier le processus dans son ensemble. C'est mon premier article technique pour Habr, j'espère vraiment qu'il s'est avéré utile et intéressant.
Bonne chance à tous dans votre recherche créative, et que la Force soit avec vous!