Chez Lyft, nous avons décidé de déplacer notre infrastructure de serveurs vers Kubernetes, un système d'orchestration de conteneurs distribué, afin de profiter des avantages que l'automatisation a à offrir. Ils voulaient une plate-forme solide et fiable qui pourrait devenir la base d'un développement ultérieur, ainsi que réduire les coûts globaux tout en augmentant l'efficacité.
Les systèmes distribués peuvent être difficiles à comprendre et à analyser, et Kubernetes ne fait pas exception. Malgré ses nombreux avantages, nous avons identifié plusieurs goulots d'étranglement lors du passage à CronJob , un système intégré à Kubernetes pour effectuer des tâches répétitives selon un calendrier. Dans cette série en deux parties, nous discuterons des inconvénients techniques et opérationnels de Kubernetes CronJob lorsqu'il est utilisé dans un grand projet et partagerons avec vous notre expérience pour les surmonter.
Tout d'abord, je décrirai les lacunes de Kubernetes CronJobs que nous avons rencontrées lors de leur utilisation dans Lyft. Ensuite (dans la deuxième partie) - nous vous dirons comment nous avons éliminé ces lacunes dans la pile Kubernetes, une convivialité accrue et une fiabilité améliorée.
Partie 1. Introduction
À qui profiteront ces articles?
- Utilisateurs de Kubernetes CronJob.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
Aujourd'hui, notre environnement de production multi-tenant compte près de 500 tâches cron appelées plus de 1 500 fois par heure.
Les tâches récurrentes et planifiées sont largement utilisées par Lyft à diverses fins. Avant de passer à Kubernetes, ils s'exécutaient directement sur des machines Linux en utilisant le cron Unix standard. Les équipes de développement étaient responsables de la rédaction des
crontabdéfinitions et du provisionnement des instances qui les exécutaient à l'aide des pipelines Infrastructure As Code (IaC), et l'équipe d'infrastructure était responsable de leur maintenance.
Dans le cadre d'un effort plus large de conteneurisation et de migration des charges de travail vers notre propre plate-forme Kubernetes, nous avons décidé de passer à CronJob *, en remplaçant le cron Unix classique par son homologue Kubernetes. Comme beaucoup d'autres, Kubernetes a été choisi en raison de ses vastes avantages (du moins en théorie), y compris son utilisation efficace des ressources.
Imaginez une tâche périodique qui s'exécute une fois par semaine pendant 15 minutes. Dans notre ancien environnement, la machine dédiée à cette tâche serait inactive 99,85% du temps. Dans le cas de Kubernetes, les ressources de calcul (CPU, mémoire) ne sont utilisées que lors de l'appel. Le reste du temps, les capacités inutilisées peuvent être utilisées pour lancer d'autres CronJob, ou simplement réduiregrappe. Compte tenu de l'ancienne façon de gérer les tâches cron, nous gagnerions beaucoup à passer à un modèle dans lequel les emplois sont éphémères.

Limites de responsabilité des développeurs et des ingénieurs de plate-forme dans la pile Lyft
Après le passage à la plate-forme Kubernetes, les équipes de développement ont cessé d'allouer et d'exploiter leurs propres instances de calcul. L'équipe de la plateforme est désormais responsable de la maintenance et de l'exploitation des ressources de calcul et des dépendances d'exécution dans la pile Kubernetes. De plus, elle est responsable de la création elle-même des objets CronJob. Les développeurs doivent uniquement configurer le calendrier des tâches et le code de l'application.
Cependant, tout semble bon sur le papier. En pratique, nous avons identifié plusieurs goulots d'étranglement lors de la migration d'un environnement cron Unix traditionnel bien étudié vers un environnement CronJob distribué et éphémère dans Kubernetes.
* Bien que CronJob était et soit toujours (à partir de Kubernetes v1.18) en version bêta, nous l'avons trouvé assez satisfaisant pour nos besoins à l'époque et parfaitement adapté au reste de la boîte à outils d'infrastructure Kubernetes que nous avions ...
En quoi Kubernetes CronJob diffère-t-il de Cron Unix?
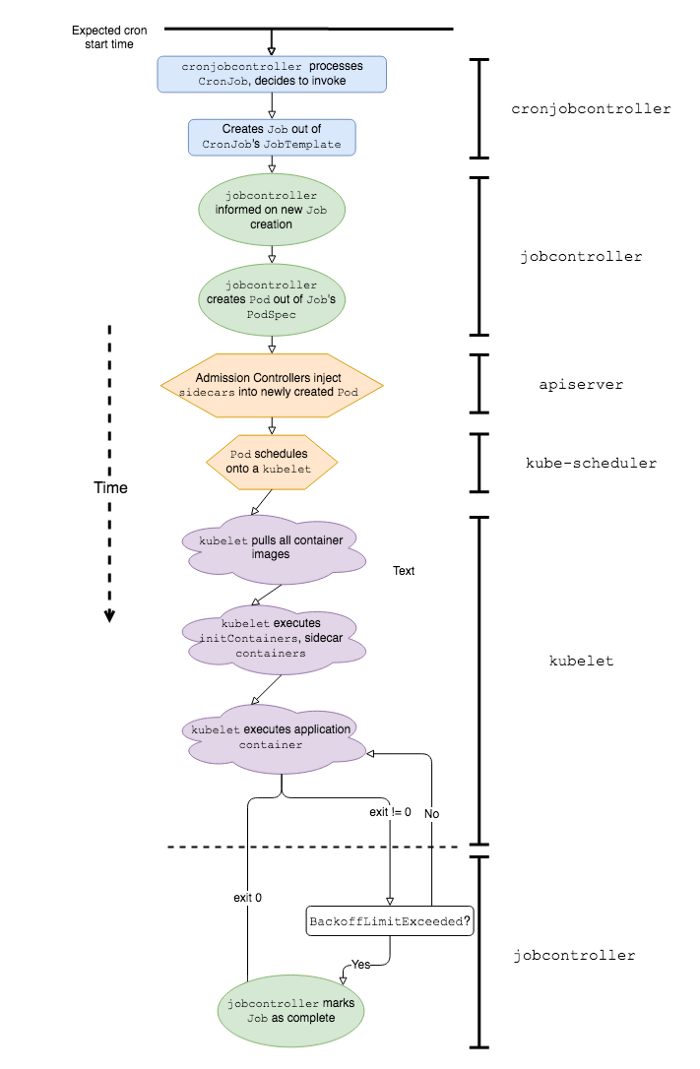
Séquence simplifiée des événements et des composants logiciels K8 impliqués dans le travail de Kubernetes CronJob
Pour mieux expliquer pourquoi travailler avec Kubernetes CronJob dans un environnement de production est associé à certaines difficultés, définissons d'abord en quoi ils diffèrent des classiques. On s'attend à ce que CronJob fonctionne de la même manière que les travaux cron sous Linux ou Unix; cependant, il existe en fait au moins quelques différences majeures dans leur comportement: la vitesse de démarrage et la gestion des plantages .
Vitesse de lancement
Le départ différé (délai de démarrage) est défini comme le temps écoulé entre le démarrage programmé cron et le début réel du code d'application. En d'autres termes, si le cron est programmé pour démarrer à 00:00:00 et que l'application démarre à 00:00:22, le délai de démarrage de ce cron particulier sera de 22 secondes.
Dans le cas des crons Unix classiques, le délai de démarrage est minime. Lorsque le moment est venu, ces commandes sont simplement exécutées. Confirmons cela avec l'exemple suivant:
# date
0 0 * * * date >> date-cron.log
Avec une configuration cron comme celle-ci, nous obtiendrons très probablement la sortie suivante dans
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
D'autre part, Kubernetes CronJob peut connaître des retards de démarrage importants car l'application est précédée d'un certain nombre d'événements. En voici quelques uns:
-
cronjobcontrollertraite et décide d'appeler le CronJob; -
cronjobcontrollercrée un Job basé sur la spécification du job CronJob; -
jobcontrollerremarque un nouveau Job et crée un Pod; - Le contrôleur d'admission insère les données du conteneur side-car dans la spécification du pod *;
-
kube-schedulerplanification d'un Pod sur kubelet; -
kubeletlance Pod (récupérant toutes les images de conteneurs); -
kubeletdémarre tous les conteneurs side-car *; -
kubeletdémarre le conteneur d'application *.
* Ces étapes sont uniques à la pile Lyft Kubernetes.
Nous avons constaté que les éléments 1, 5 et 7 apportent la contribution la plus significative à la latence une fois que nous atteignons une certaine échelle de CronJob dans l'environnement Kubernetes.
Retard causé par le travail cronjobcontroller'
Pour mieux comprendre d'où vient la latence, examinons le code source en ligne
cronjobcontroller'. Dans Kubernetes 1.18, il cronjobcontrollervérifie simplement tous les CronJob toutes les 10 secondes et exécute une logique sur chacun d'eux.
L'implémentation le
cronjobcontroller'fait de manière synchrone en effectuant au moins un appel d'API supplémentaire pour chaque CronJob. Lorsque le nombre de CronJob dépasse un certain nombre, ces appels d'API commencent à souffrir de contraintes côté client .
Le cycle d'interrogation de 10 secondes et les appels d'API côté client entraînent une augmentation significative du délai de lancement de CronJob.
Planification des pods avec crons
En raison de la nature du calendrier cron, la plupart d'entre eux s'exécutent au début de la minute (XX: YY: 00). Par exemple, le
@hourlycron (toutes les heures) s'exécute à 01:00:00, 02:00:00, etc. Dans le cas d'une plate-forme cron multi-locataire avec de nombreux crons exécutés toutes les heures, tous les quarts d'heure, toutes les 5 minutes, etc., cela conduit à des goulots d' étranglement (hotspots) lorsque plusieurs crons sont démarrés en même temps. Chez Lyft, nous avons remarqué qu'un de ces endroits est le début de l'heure (XX: 00: 00). Ces hotspots créent une charge et conduisent à une limitation supplémentaire de la fréquence des requêtes dans les composants de la couche de contrôle impliqués dans l'exécution du CronJob, tels que kube-scheduleret kube-apiserver, ce qui conduit à une augmentation notable du délai de démarrage.
En outre, si vous ne fournissez pas de puissance de calcul pour les charges de pointe (et / ou utilisez des instances de calcul du service cloud) et que vous utilisez à la place le mécanisme d'autoscaling du cluster pour mettre à l'échelle dynamiquement les nœuds, le temps nécessaire pour démarrer les nœuds ajoute une contribution supplémentaire à la latence de démarrage. pods CronJob.
Lancement de pod: conteneurs d'assistance
Une fois que le pod CronJob a été planifié avec succès
kubelet, ce dernier doit récupérer et exécuter les images de conteneur de tous les side-cars et de l'application elle-même. En raison des spécificités du lancement de conteneurs dans Lyft (les conteneurs side-car démarrent avant les conteneurs d'application), le retard dans le démarrage de tout side-car affectera inévitablement le résultat, entraînant un retard supplémentaire dans le démarrage de la tâche.
Ainsi, les retards au démarrage, avant l'exécution du code d'application requis, couplés à un grand nombre de CronJob dans un environnement multi-locataires, conduisent à des retards de démarrage notables et imprévisibles. Comme nous le verrons un peu plus tard, dans des conditions réelles un tel retard peut affecter négativement le comportement du CronJob, menaçant de rater les lancements.
Gestion des accidents de conteneur
En général, il est recommandé de garder un œil sur le travail des crons. Pour les systèmes Unix, c'est assez facile à faire. Les crones Unix interprètent la commande donnée en utilisant le shell spécifié
$SHELL, et une fois la commande terminée (réussie ou non), cet appel particulier est considéré comme terminé. Vous pouvez suivre l'exécution d'un cron sous Unix en utilisant un script simple comme celui-ci:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
Dans le cas d'Unix, cron
stat-and-logs'exécutera exactement une fois pour chaque appel cron - indépendamment de $exitcode. Par conséquent, ces métriques peuvent être utilisées pour organiser les notifications les plus simples sur les appels infructueux.
Dans le cas de Kubernetes CronJob, où les tentatives en cas d'échec sont définies par défaut, et l'échec lui-même peut être causé par diverses raisons (échec de la tâche ou échec du conteneur), la surveillance n'est pas si simple et directe.
En utilisant un script similaire dans le conteneur d'application et avec des travaux configurés pour redémarrer en cas d'échec, CronJob essaiera d'exécuter la tâche en cas d'échec, générant des métriques et des journaux dans le processus, jusqu'à ce qu'il atteigne BackoffLimit(nombre max. de tentatives). Ainsi, un développeur essayant de déterminer la cause d'un problème devra trier un grand nombre de «déchets» inutiles. De plus, l'alerte du script shell en réponse au premier échec peut également se révéler être un bruit ordinaire sur lequel il est impossible de baser d'autres actions, car le conteneur d'application peut récupérer et terminer avec succès la tâche tout seul.
Vous pouvez implémenter des alertes au niveau du Job plutôt qu'au niveau du conteneur d'application. Pour cela, des métriques de niveau API pour les échecs de tâche sont disponibles, telles que
kube_job_status_failedfrom kube-state-metrics. L'inconvénient de cette approche est que l'ingénieur en service ne prend conscience du problème qu'après que le Job a atteint le «stade d'échec final» et atteint la limite BackoffLimit, ce qui peut se produire beaucoup plus tard que le premier échec du conteneur d'application.
CronJob'
Un délai de démarrage et des cycles de redémarrage importants introduisent une latence supplémentaire qui peut empêcher Kubernetes CronJob d'être réexécuté. Dans le cas des CronJob qui sont appelés fréquemment, ou ceux dont les temps d'exécution sont nettement plus longs que le temps d'inactivité, ce délai supplémentaire peut causer des problèmes avec le prochain appel planifié. Si le CronJob a une politique
ConcurrencyPolicy: Forbidqui interdit la concurrence , le retard se traduit par des appels futurs non terminés à temps et retardés.

Un exemple de chronologie (du point de vue d'un cronjobcontroller) dans lequel beginDeadlineSeconds est dépassé pour un CronJob horaire spécifique: il saute son démarrage programmé et ne sera appelé qu'à la prochaine heure programmée
Il existe également un scénario plus désagréable (nous l'avons rencontré dans Lyft), en raison duquel CronJob peut complètement ignorer les appels, c'est à ce moment que CronJob est installé
startingDeadlineSeconds. Dans ce scénario, si le délai de démarrage dépasse startingDeadlineSeconds, le CronJob sautera complètement le démarrage.
En outre, si
ConcurrencyPolicyCronJob est défini sur Forbid, le cycle de redémarrage en cas d'échec de l'appel précédent peut également interférer avec le prochain appel CronJob.
Problèmes liés à l'utilisation de Kubernetes CronJob dans des conditions réelles
Depuis que nous avons commencé à migrer des tâches de calendrier répétitives vers Kubernetes, il a été constaté que l'utilisation du mécanisme CronJob inchangé conduit à des moments désagréables, à la fois du point de vue du développeur et du point de vue de l'équipe de la plateforme. Malheureusement, ils ont commencé à annuler les avantages et les avantages pour lesquels nous avions initialement choisi Kubernetes CronJob. Nous nous sommes vite rendu compte que ni les développeurs ni l'équipe de la plateforme n'avaient les outils nécessaires à leur disposition pour exploiter CronJob et comprendre leurs cycles de vie complexes.
Les développeurs ont essayé d'exploiter leur CronJob et de les configurer, mais en conséquence, ils nous sont venus avec beaucoup de plaintes et de questions comme celles-ci:
- Pourquoi mon cron ne fonctionne-t-il pas?
- Il semble que mon cron a cessé de fonctionner. Comment pouvez-vous confirmer qu'il fonctionne réellement?
- Je ne savais pas que cron ne fonctionnait pas et je pensais que tout allait bien.
- Comment "réparer" un cron manquant? Je ne peux pas simplement me connecter en SSH et exécuter la commande moi-même.
- Pouvez-vous dire pourquoi ce cron semble avoir manqué plusieurs courses entre X et Y?
- Nous avons X (grand nombre) crons, chacun avec ses propres notifications, et il devient assez fastidieux / difficile de tous les maintenir.
- Pod, Job, side-car - quel genre d'absurdités est-ce?
En tant qu'équipe de la plateforme , nous n'avons pas été en mesure de répondre à des questions telles que:
- Comment quantifier les performances de la plateforme cron Kubernetes?
- Comment l'activation de CronJob supplémentaires affectera-t-elle notre environnement Kubernetes?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
Le débogage des plantages de CronJob n'est pas une tâche facile. Il faut souvent de l'intuition pour comprendre où se produisent les échecs et où chercher des preuves. Parfois, ces indices sont assez difficiles à obtenir - comme, par exemple, les journaux
cronjobcontroller', qui ne sont enregistrés que si le niveau de détail élevé est activé. De plus, les traces peuvent simplement disparaître après un certain laps de temps, ce qui rend le débogage similaire au jeu "Kick a mole" (à ce sujet - environ Transl.), Par exemple, Kubernetes Events for CronJob, Jobs and Pods qui par défaut ne sont conservés qu'une heure. Aucune de ces méthodes n'est facile à utiliser, et aucune d'entre elles ne s'adapte bien en termes de support à mesure que le nombre de CronJob sur la plate-forme augmente.
De plus, parfois Kubernetesarrête d' essayer d'exécuter le CronJob s'il a manqué trop d'exécutions. Dans ce cas, il doit être redémarré manuellement. Dans la vraie vie, cela se produit beaucoup plus souvent que vous ne l'imaginez, et le besoin de résoudre manuellement le problème à chaque fois devient assez douloureux.
Ceci conclut ma plongée dans les problèmes techniques et opérationnels que nous avons rencontrés lors de l'utilisation de Kubernetes CronJob dans un projet chargé. Dans la deuxième partie, nous parlerons de la façon dont nous avons éliminé Kubernetes dans notre pile, amélioré la convivialité et amélioré la fiabilité de CronJob.
Partie 2. Introduction
Il est devenu clair que Kubernetes CronJob, inchangé, ne peut pas devenir un remplacement simple et pratique pour leurs homologues Unix. Pour transférer en toute confiance toutes nos crones vers Kubernetes, nous devions non seulement éliminer les lacunes techniques de CronJob, mais aussi en améliorer la convivialité . À savoir:
1. Écoutez les développeurs afin de comprendre les réponses aux questions sur les crones qui les inquiètent le plus. Par exemple: mon cron a-t-il démarré? Le code de l'application a-t-il été exécuté? Le lancement a-t-il réussi? Combien de temps le cron a-t-il fonctionné? (Combien de temps le code de l'application a-t-il pris?)
2. Simplifiez la maintenance de la plate-forme en rendant CronJob plus compréhensible, leur cycle de vie plus transparent et les limites de la plate-forme / application plus claires.
3. Complétez notre plate-forme avec des métriques et des alertes standard pour réduire la quantité de configuration d'alertes personnalisées et réduire le nombre de liaisons cron dupliquées que les développeurs doivent écrire et maintenir.
4. Développer des outils pour une reprise après incident et tester de nouvelles configurations CronJob.
5. Résolvez des problèmes techniques de longue date dans Kubernetes , tels qu'un bogue TooManyMissedStarts qui nécessite une intervention manuelle pour être corrigé et provoque un plantage dans un scénario de défaillance critique ( lorsque le démarrage de la ligneDeadlineSeconds n'est pas défini ) passant inaperçu.
Décision
Nous avons résolu tous ces problèmes comme suit:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

Un exemple de panel généré par la plateforme pour surveiller un CronJob spécifique
Nous avons ajouté les métriques suivantes à la pile Kubernetes (elles sont définies pour tous les CronJob dans Lyft):
1.
started.count- ce compteur est incrémenté lorsque le conteneur d'application est lancé pour la première fois lorsque le CronJob est appelé. Cela aide à répondre à la question: « Le code de l'application a-t-il été exécuté? ".
2.
{success, failure}.count- ces compteurs sont incrémentés lorsqu'un appel CronJob particulier atteint l' état terminal (c'est-à-dire que le Job a terminé son travail et n'essaye jobcontrollerplus de l'exécuter). Ils répondent à la question: « Le lancement a-t-il réussi? ".
3.
scheduling-decision.{invoke, skip}.count- ces compteursvous permettent de connaître les décisions qui sont prises cronjobcontrollerlors de l'appel de CronJob. En particulier, cela skip.countaide à répondre à la question: « Pourquoi mon cron ne fonctionne-t-il pas? ". Les étiquettes suivantes agissent comme ses paramètres reason:
-
reason = concurrencyPolicy- acronjobcontrollermanqué l'appel à CronJob, car sinon il le casseraitConcurrencyPolicy; -
reason = missedDeadline- acronjobcontrollerrefusé d'appeler CronJob, car il a manqué la fenêtre d'appel spécifiée.spec.startingDeadlineSeconds; -
reason = errorEst un paramètre commun pour toutes les autres erreurs qui se produisent lors de la tentative d'appel d'un CronJob.
4.
app-container-duration.seconds- Cette minuterie mesure la durée de vie du conteneur d'application. Cela permet de répondre à la question: « Combien de temps le code de l'application a-t-il fonctionné? ". Dans ce chronomètre, nous n'avons délibérément pas inclus le temps nécessaire à la planification des pods, au lancement des conteneurs side-car, etc., car ils sont à la charge de l'équipe de la plateforme et sont inclus dans le délai de lancement.
5.
start-delay.seconds- Cette minuterie mesure le délai de démarrage. Cette métrique, lorsqu'elle est agrégée sur la plate-forme, permet aux ingénieurs qui la maintiennent non seulement d'évaluer, de surveiller et d'ajuster les performances de la plate-forme, mais sert également de base pour déterminer les SLO pour des paramètres tels que le délai de démarrage et la fréquence de planification cron maximale.
Sur la base de ces métriques, nous avons créé des alertes par défaut. Ils informent les développeurs lorsque:
- Leur CronJob n'a pas commencé comme prévu (
rate(scheduling-decision.skip.count) > 0); - Leur CronJob a échoué (
rate(failure.count) > 0).
Les développeurs n'ont plus besoin de définir leurs propres alertes et métriques pour les crons dans Kubernetes - la plate-forme fournit leurs homologues prêts à l'emploi.
Exécuter des crons en cas de besoin
Nous l'avons adapté
kubectl create job test-job --from=cronjob/<your-cronjob>à notre outil CLI interne. Les ingénieurs de Lyft l'utilisent pour interagir avec leurs services sur Kubernetes pour appeler CronJob en cas de besoin pour:
- récupération après des plantages intermittents CronJob;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
Nous avons corrigé un bogue avec TooManyMissedStarts afin que maintenant CronJob ne «se bloque» pas après 100 départs manqués consécutifs. Ce correctif supprime non seulement la nécessité d'une intervention manuelle, mais vous permet également de suivre réellement le
startingDeadlineSeconds dépassement des délais . Merci à Vallery Lancey pour la conception et la construction de ce patch, Tom Wanielista pour son aide à la conception de l'algorithme. Nous avons ouvert un PR pour apporter ce patch à la branche principale de Kubernetes (cependant, il n'a jamais été adopté et fermé pour cause d'inactivité - environ Transl.) .
Implémentation de la surveillance cron

À quelles étapes du cycle de vie de Kubernetes CronJob nous avons ajouté des mécanismes d'exportation de métriques
Alertes qui ne dépendent pas des horaires cron
La partie la plus délicate de la mise en œuvre des notifications d'appels cron manqués est de gérer leurs horaires ( crontab.guru s'est avéré utile pour les déchiffrer ). Par exemple, considérez le calendrier suivant:
# 5
*/5 * * * *
Vous pouvez faire en sorte que le compteur de ce cron s'incrémente à chaque fois qu'il quitte (ou utiliser une liaison cron ). Ensuite, dans le système de notification, vous pouvez écrire une expression conditionnelle de la forme: "Regardez les 60 minutes précédentes et faites-moi savoir si le compteur augmente de moins de 12". Problème résolu, non?
Mais que faire si votre emploi du temps ressemble à ceci:
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
Dans ce cas, vous devrez bricoler la condition (bien que votre système ait peut-être une fonction de notification uniquement pendant les heures ouvrables?). Quoi qu'il en soit, ces exemples illustrent que la liaison des notifications aux planifications cron présente plusieurs inconvénients:
- Lorsque vous modifiez la planification, vous devez apporter des modifications à la logique de notification.
- Certaines planifications cron nécessitent des requêtes assez complexes pour être répliquées à l'aide de séries chronologiques.
- Il doit y avoir une sorte de «période d'attente» pour les crones qui ne commencent pas leur travail exactement à temps afin de minimiser les faux positifs.
L'étape 2 seule rend la génération de notifications par défaut pour toutes les crones de la plate-forme une tâche très difficile, et l'étape 3 est particulièrement pertinente pour les plates-formes distribuées comme Kubernetes CronJob, dans lesquelles le délai de lancement est un facteur important. De plus, il existe des solutions qui utilisent des « commutateurs d' homme mort », ce qui nous ramène à nouveau à la nécessité de lier l'alerte au calendrier cron, et / ou des algorithmes de détection d'anomalies qui nécessitent une formation et ne fonctionnent pas immédiatement pour de nouveaux CronJob ou des changements dans leur calendrier.
Une autre façon de regarder le problème est de vous demander: qu'est-ce que cela signifie que cron aurait dû démarrer mais qu'il ne l'a pas fait?
Dans Kubernetes, si vous oubliez les bogues dans
cronjobcontroller'ou la possibilité d'une chute dans le plan de contrôle lui-même (bien que vous devriez immédiatement le voir si vous suivez correctement l'état du cluster) - cela signifie que cronjobcontrollerle CronJob a évalué et décidé (selon le calendrier du cron) qu'il devrait être appelé, mais pour une raison quelconque pour la raison que j'ai délibérément décidé de ne pas le faire .
Sonne familier? C'est exactement ce que fait notre métrique
scheduling-decision.skip.count! Il ne nous rate(scheduling-decision.skip.count)reste plus qu'à suivre le changement pour informer l'utilisateur que son CronJob aurait dû être déclenché, mais ce n'est pas le cas.
Cette solution dissocie la planification cron de la notification elle-même, offrant plusieurs avantages:
- Vous n'avez plus besoin de reconfigurer les alertes lors de la modification des horaires.
- Il n'y a pas besoin de demandes et de conditions de temps complexes.
- Vous pouvez facilement générer des alertes par défaut pour tous les CronJob de la plateforme.
Ceci, combiné avec les autres séries chronologiques et alertes mentionnées précédemment, permet de créer une image plus complète et compréhensible de l'état du CronJob.
Implémentation d'un minuteur de départ différé
En raison de la nature complexe du cycle de vie de CronJob, nous devions réfléchir attentivement aux points spécifiques de la boîte à outils sur la pile afin de mesurer cette métrique de manière fiable et précise. En conséquence, tout se résumait à fixer deux points dans le temps:
- T1: quand cron doit être démarré (selon son planning).
- T2: lorsque le code d'application commence réellement à s'exécuter.
Dans ce cas
start delay(délai de démarrage) = 2 — 1. Pour fixer le T1 moment, nous avons inclus le code dans la logique d'appel cron dans le cronjobcontroller'. Il enregistre l'heure de début prévue comme .metadata.Annotationles objets Job qu'il cronjobcontrollercrée lorsque le CronJob est appelé. Il peut maintenant être récupéré à l'aide de n'importe quel client API à l'aide d'une requête normale GET Job.
Avec T2, tout s'est avéré plus compliqué. Comme nous devons obtenir la valeur aussi proche que possible de la valeur réelle, T2 doit coïncider avec le moment où le conteneur avec l'application est lancé pour la première fois . Si vous tirez T2 à n'importe quellorsque le conteneur est démarré (y compris les redémarrages), le fait de retarder le lancement dans ce cas inclura le temps d'exécution de l'application elle-même. Par conséquent, nous avons décidé d'attribuer un autre
.metadata.Annotationobjet Job chaque fois que nous découvrions que le conteneur d'application pour un Job donné avait d'abord reçu un statut Running. Ainsi, en substance, un verrou distribué a été créé et les futurs démarrages du conteneur d'application pour ce Job ont été ignorés (seul le moment du premier démarrage a été enregistré ).
résultats
Après avoir déployé de nouvelles fonctionnalités et corrigé des bugs, nous avons reçu de nombreux retours positifs de la part des développeurs. Désormais, les développeurs utilisent notre plateforme Kubernetes CronJob:
- ne plus avoir à s'interroger sur leurs propres outils de surveillance et alertes;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
De plus, les ingénieurs de maintenance de plateforme disposent désormais d'un nouveau paramètre ( délai de démarrage ) pour mesurer l'expérience utilisateur et les performances de la plateforme.
Enfin (et peut-être notre plus grande victoire), en rendant CronJob (et leurs états) plus transparent et traçable, nous avons considérablement simplifié le processus de débogage pour les développeurs et les ingénieurs de plateforme. Ils peuvent désormais déboguer ensemble en utilisant les mêmes données, il arrive donc souvent que les développeurs trouvent le problème par eux-mêmes et le résolvent à l'aide des outils fournis par la plateforme.
Conclusion
L'orchestration de tâches distribuées et planifiées n'est pas facile. CronJob Kubernetes n'est qu'une façon de l'organiser. Bien qu'ils soient loin d'être idéaux, les CronJob sont tout à fait capables de travailler dans des projets mondiaux, si, bien sûr, vous êtes prêt à investir du temps et des efforts pour les améliorer: augmenter l'observabilité, comprendre les causes et les spécificités des échecs, et compléter avec des outils qui le rendent plus facile à utiliser.
Remarque: il existe une proposition d'amélioration de Kubernetes (KEP) ouverte pour corriger les lacunes de CronJob et traduire leur version mise à jour en GA.
Merci à Rithu John , Scott Lau, Scarlett Perry , Julien Silland et Tom Wanielista pour leur aide dans la révision de cette série d'articles.
PS du traducteur
Lisez aussi sur notre blog: