
PostgreSQL a déjà fait ses preuves - il fonctionne très bien, est utilisé par les entreprises numériques à la mode comme Alibaba et TripAdvisor, et le manque de redevances en fait une alternative tentante aux monstres comme MS SQL ou Oracle DB. Mais dès que nous commençons à penser à PostgreSQL dans le paysage d'entreprise, nous nous heurtons immédiatement à des exigences strictes: «Mais qu'en est-il de la tolérance aux pannes de configuration? résistance aux catastrophes? où est le suivi complet? qu'en est-il des sauvegardes automatisées? qu'en est-il des bibliothèques de bandes, à la fois pour le stockage direct et secondaire? "
D'une part, PostgreSQL ne dispose pas de fonctions de sauvegarde intégrées, comme les SGBD «adultes» comme RMAN, Oracle DB ou SAP Database Backup. D'autre part, les fournisseurs de systèmes de sauvegarde d'entreprise (Veeam, Veritas, Commvault), bien qu'ils prennent en charge PostgreSQL, ne fonctionnent en fait qu'avec une certaine configuration (généralement autonome) et avec un ensemble de restrictions diverses.
Les systèmes de sauvegarde spécialement conçus pour PostgreSQL, tels que Barman, Wal-g, pg_probackup, sont extrêmement populaires dans les petites installations PostgreSQL ou là où de lourdes sauvegardes d'autres éléments du paysage informatique ne sont pas nécessaires. Par exemple, en plus de PostgreSQL, l'infrastructure peut avoir des serveurs physiques et virtuels, OpenShift, Oracle, MariaDB, Cassandra, etc. Tout cela doit être soutenu par un outil commun. Mettre une solution distincte exclusivement pour PostgreSQL est une mauvaise idée: les données seront copiées quelque part sur le disque, puis elles devront être supprimées sur bande. Cette duplication de la sauvegarde augmente le temps de sauvegarde et, plus critique encore, la récupération.
Dans une solution d'entreprise, une installation est sauvegardée avec un certain nombre de nœuds dans un cluster dédié. Dans le même temps, par exemple, Commvault ne peut fonctionner qu'avec un cluster à deux nœuds, dans lequel le primaire et le secondaire sont affectés de manière rigide à certains nœuds. Et il est logique de sauvegarder uniquement avec Primary, car la sauvegarde avec Secondary a ses limites. En raison des particularités du SGBD, un dump n'est pas créé sur Secondaire, et donc seule la possibilité d'une sauvegarde de fichier demeure.
Pour atténuer les risques de temps d'arrêt, la création d'un système tolérant aux pannes crée une configuration de clustering en direct et le primaire peut migrer progressivement entre différents serveurs. Par exemple, le logiciel Patroni lui-même lance Primary sur un nœud de cluster sélectionné au hasard. SRK n'a aucun moyen de suivre cela dès la sortie de la boîte, et si la configuration change, les processus sont interrompus. Autrement dit, l'introduction d'un contrôle externe empêche la SRK de fonctionner efficacement, car le serveur de contrôle ne comprend tout simplement pas où et quelles données doivent être copiées.
Un autre problème est l'implémentation de sauvegarde dans Postgres. C'est possible via dump, et cela fonctionne sur de petites bases. Mais dans les grandes bases de données, le vidage prend beaucoup de temps, nécessite beaucoup de ressources et peut entraîner une défaillance de l'instance de base de données.
La sauvegarde de fichiers corrige la situation, mais sur de grandes bases de données, elle est lente car elle fonctionne en mode monothread. En outre, les fournisseurs ont un certain nombre de restrictions supplémentaires. Soit vous ne pouvez pas utiliser les sauvegardes de fichiers et de vidage en même temps, soit la déduplication n'est pas prise en charge. Les problèmes sont nombreux et le plus souvent, il est plus facile de choisir un SGBD coûteux mais éprouvé au lieu de Postgres.
Nulle part où se retirer! Derrière les développeurs de Moscou !
Cependant, récemment, notre équipe a été confrontée à un défi difficile: dans le projet de création d'AIS OSAGO 2.0, où nous avons réalisé l'infrastructure informatique, les développeurs du nouveau système ont choisi PostgreSQL.
Il est beaucoup plus facile pour les grands développeurs de logiciels d'utiliser des solutions open source «à la mode». Facebook dispose de suffisamment de spécialistes pour soutenir le travail de ce SGBD. Et dans le cas du PCA, toutes les tâches du «deuxième jour» sont tombées sur nos épaules. Nous devions fournir une tolérance aux pannes, assembler un cluster et, bien sûr, établir une sauvegarde. La logique des actions était la suivante:
- Apprenez à SRK à effectuer une sauvegarde à partir du nœud principal du cluster. Pour ce faire, le SRK doit le trouver, ce qui signifie qu'il a besoin d'être intégré à l'une ou l'autre solution pour gérer le cluster PostgreSQL. Dans le cas de PCA, le logiciel Patroni a été utilisé pour cela.
- Décidez du type de sauvegarde en fonction de la quantité de données et des exigences de récupération. Par exemple, lorsqu'il est nécessaire de restaurer des pages de manière granulaire, utilisez un vidage et si les bases de données sont volumineuses et qu'une restauration granulaire n'est pas requise, travaillez au niveau du fichier.
- Attachez la fonction de sauvegarde en bloc à la solution pour créer une sauvegarde multithread.
Dans le même temps, nous avons d'abord cherché à créer un système efficace et simple sans cerclage monstrueux de composants supplémentaires. Moins il y a de béquilles, moins la charge de travail du personnel est faible et moins le risque de défaillance du SCI est faible. Nous avons immédiatement exclu les approches utilisant Veeam et RMAN, car un ensemble de deux solutions laisse déjà entrevoir le manque de fiabilité du système.
Un peu de magie pour une entreprise
Nous devions donc garantir une sauvegarde fiable pour 10 clusters de 3 nœuds chacun, tandis que la même infrastructure est mise en miroir dans le centre de données de sauvegarde. Les centres de données du plan PostgreSQL fonctionnent sur le principe actif-passif. Le nombre total de bases de données était de 50 To. Tout SRC au niveau de l'entreprise peut facilement gérer cela. Mais la nuance est qu'au départ, Postgres n'a pas de crochet pour une compatibilité complète et profonde avec les systèmes de sauvegarde. Par conséquent, nous avons dû chercher une solution qui avait initialement le maximum de fonctionnalités en conjonction avec PostgreSQL, et affiner le système.
Nous avons mené 3 «hackathons» internes - nous avons examiné plus de cinquante développements, les avons testés, apporté des changements en lien avec nos hypothèses, et les avons testés à nouveau. Après avoir analysé les options disponibles, nous avons choisi Commvault. Hors de la boîte, ce produit pouvait fonctionner avec l'installation PostgreSQL en cluster la plus simple, et son architecture ouverte a fait naître l'espoir (qui s'est réalisé) pour un raffinement et une intégration réussis. Commvault peut également sauvegarder les journaux PostgreSQL. Par exemple, Veritas NetBackup dans la partie PostgreSQL ne peut effectuer que des sauvegardes complètes.
En savoir plus sur l'architecture. Les serveurs de gestion Commvault ont été installés dans chacun des deux centres de données dans une configuration CommServ HA. Le système est mis en miroir, géré via une console unique et, du point de vue HA, il répond à toutes les exigences de l'entreprise.
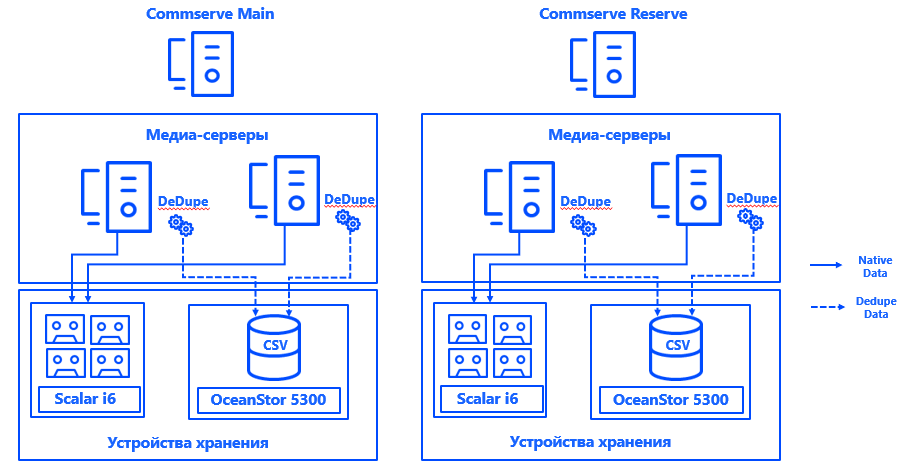
Nous avons également lancé deux serveurs de médias physiques dans chaque centre de données, auxquels nous avons connecté des baies de disques et des bibliothèques de bandes dédiées spécifiquement aux sauvegardes via un SAN via Fibre Channel. Des bases de déduplication étendues garantissaient la résilience des serveurs de médias, et la connexion de chaque serveur à chaque CSV garantissait un fonctionnement continu en cas de défaillance d'un composant. L'architecture du système permet à la sauvegarde de continuer même si l'un des centres de données tombe en panne.
Patroni définit un nœud principal pour chaque cluster. Il peut s'agir de n'importe quel nœud libre du centre de données - mais uniquement dans le principal. Dans la sauvegarde, tous les nœuds sont secondaires.
Afin que Commvault comprenne quel nœud de cluster est principal, nous avons intégré le système (grâce à l'architecture ouverte de la solution) avec Postgres. Pour ce faire, un script a été créé qui signale l'emplacement actuel du nœud principal au serveur de gestion Commvault.
En général, le processus ressemble à ceci:
Patroni choisit Primaire → Keepalived fait apparaître le cluster IP et exécute le script → L'agent Commvault sur le nœud de cluster sélectionné reçoit une notification indiquant qu'il s'agit de Primaire → Commvault reconfigure automatiquement la sauvegarde dans le pseudo-client.
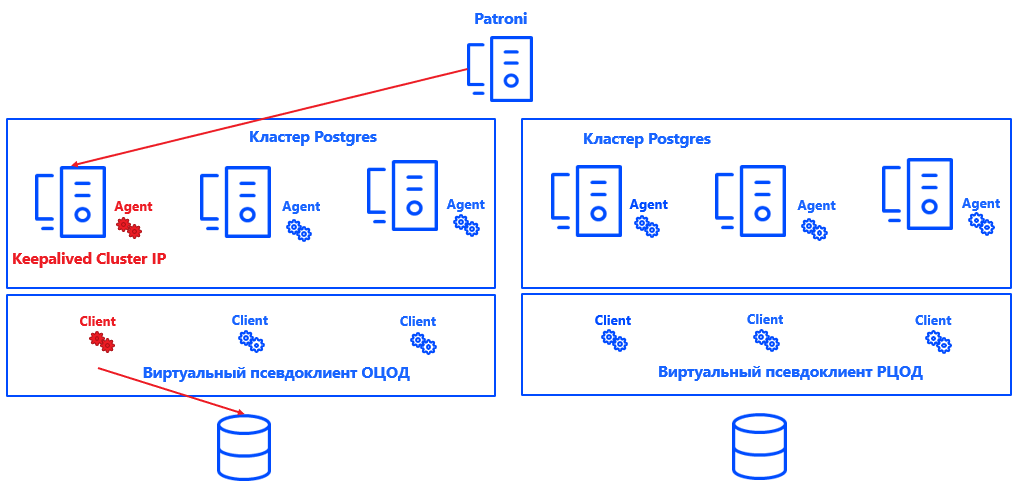
L'avantage de cette approche est que la solution n'affecte ni la cohérence, ni l'exactitude des journaux, ni la récupération de l'instance Postgres. Il est également facilement évolutif, car il n'est plus nécessaire de réparer les nœuds primaire et secondaire pour Commvault. Il suffit que le système comprenne où se trouve le primaire et le nombre de nœuds peut être augmenté à presque n'importe quelle valeur.
La solution ne prétend pas être idéale et a ses propres nuances. Commvault ne peut sauvegarder qu'une instance entière, pas des bases de données individuelles. Par conséquent, une instance distincte a été créée pour chaque base de données. Les vrais clients sont combinés en pseudo-clients virtuels. Chaque pseudo-client Commvault est un cluster UNIX. Il ajoute les nœuds de cluster sur lesquels l'agent Commvault pour Postgres est installé. Par conséquent, tous les nœuds virtuels du pseudo-client sont sauvegardés en une seule instance.
Au sein de chaque pseudo-client, le nœud actif du cluster est indiqué. C'est ce que définit notre solution d'intégration pour Commvault. Le principe de son fonctionnement est assez simple: si une IP de cluster monte sur un nœud, le script définit le paramètre "nœud actif" dans le binaire de l'agent Commvault - en fait, le script définit "1" dans la partie requise de la mémoire. L'agent envoie ces données à CommServe et Commvault effectue une sauvegarde à partir du nœud souhaité. De plus, l'exactitude de la configuration est vérifiée au niveau du script, ce qui permet d'éviter les erreurs lors du démarrage de la sauvegarde.
Dans le même temps, de grandes bases de données sont sauvegardées en bloc dans plusieurs threads, répondant aux exigences du RPO et des fenêtres de sauvegarde. La charge sur le système est insignifiante: les copies complètes ne se produisent pas si souvent, les autres jours, seuls les journaux sont collectés, en outre, pendant les périodes de faible charge.
En passant, nous avons appliqué des politiques distinctes pour la sauvegarde des journaux archivés PostgreSQL - ils sont stockés selon des règles différentes, copiés selon une planification différente, et la déduplication n'est pas activée pour eux, car ces journaux contiennent des données uniques.
Pour garantir la cohérence de l'ensemble de l'infrastructure informatique, des clients de fichier Commvault distincts sont installés sur chacun des nœuds du cluster. Ils excluent les fichiers Postgres des sauvegardes et sont destinés uniquement aux sauvegardes du système d'exploitation et des applications. Cette partie des données a également sa propre politique et sa propre période de stockage.

Désormais, le SRK n'affecte pas les services productifs, mais si la situation change, il sera possible d'activer le système de limitation de charge dans Commvault.
Est-ce bien? Bien!
Ainsi, nous avons non seulement une sauvegarde fonctionnelle, mais également entièrement automatisée pour une installation PostgreSQL en cluster, qui répond à toutes les exigences des appels d'entreprise.
Les paramètres RPO et RTO à 1 heure et 2 heures se chevauchent avec une marge, ce qui signifie que le système les égalera même avec une augmentation significative du volume de données stockées. Malgré de nombreux doutes, PostgreSQL et l'environnement d'entreprise sont tout à fait compatibles. Et maintenant, nous savons de notre propre expérience qu'une sauvegarde pour un tel SGBD est possible dans une grande variété de configurations.
Bien sûr, en cours de route, nous avons dû porter sept paires de bottes en fer, surmonter un certain nombre de difficultés, marcher sur quelques râteaux et corriger un certain nombre d'erreurs. Mais maintenant, l'approche a déjà été testée et peut être utilisée pour implémenter l'Open Source au lieu d'un SGBD propriétaire dans un environnement d'entreprise difficile.
Avez-vous essayé PostgreSQL dans un environnement d'entreprise?
Auteurs:
Oleg Lavrenov, ingénieur de conception des systèmes de stockage de données Jet Infosystems
Dmitry Erykin, ingénieur de conception de systèmes informatiques Jet Infosystems