
Aujourd'hui, nous vous expliquerons comment nous avons développé un système de recherche de puits candidats pour la fracturation hydraulique (HF) à l'aide de l'apprentissage automatique (ci-après ML) et ce qui en est issu. Voyons pourquoi la fracturation hydraulique est nécessaire, ce que le ML a à voir avec elle et pourquoi notre expérience peut être utile non seulement pour les pétroliers.
Sous la coupe, un état détaillé du problème, une description de nos solutions informatiques, le choix des métriques, la création d'un pipeline ML, le développement d'une architecture pour la sortie d'un modèle en prod.
Nous avons écrit sur les raisons pour lesquelles la fracturation est effectuée dans nos articles précédents ici et ici .
Pourquoi l'apprentissage automatique est-il ici? D'une part, la fracturation hydraulique est moins chère que le forage, mais elle reste coûteuse et, d'autre part, il ne sera pas possible de la faire à chaque puits - il n'y aura aucun effet. Un géologue expert est à la recherche de lieux adaptés. Le nombre d'entreprises en exploitation étant élevé (des dizaines de milliers), les options sont souvent négligées et l'entreprise perd son profit potentiel. L'utilisation de l'apprentissage automatique peut accélérer considérablement l'analyse des informations. Cependant, créer un modèle ML n'est que la moitié de la bataille. Il est nécessaire de le faire fonctionner en mode constant, de le connecter au service de données, de dessiner une belle interface et de faire en sorte qu'il soit pratique pour l'utilisateur d'entrer dans l'application et de résoudre son problème en deux clics.
Abstraction faite de l'industrie pétrolière, on peut remarquer que des tâches similaires sont en train d'être résolues dans toutes les entreprises. Tout le monde souhaite:
A. Automatiser le traitement et l'analyse de grands flux de données.
B. Réduisez les coûts et ne manquez pas les avantages.
C. Rendre un tel système rapide et efficace.
Dans cet article, vous apprendrez comment nous avons implémenté un tel système, quels outils nous avons utilisés, et aussi quelles difficultés nous avons rencontrées sur le chemin épineux de l'introduction du ML dans la production. Nous sommes convaincus que notre expérience peut intéresser tous ceux qui souhaitent automatiser une routine - quel que soit le domaine d'activité.
Comment les puits sont sélectionnés pour la fracturation hydraulique de manière «traditionnelle»
Lors de la sélection des puits candidats pour la fracturation hydraulique, le pétrolier s'appuie sur sa vaste expérience et examine différents graphiques et tableaux, après quoi il prédit où effectuer la fracturation hydraulique. De manière fiable, cependant, personne ne sait ce qui se passe à une profondeur de plusieurs milliers de mètres, car il n'est pas si facile de regarder sous terre (vous pouvez en savoir plus dans l' article précédent ). L'analyse des données par des méthodes «traditionnelles» nécessite des coûts de main-d'œuvre importants, mais, malheureusement, elle ne garantit pas une prévision précise des résultats de la fracturation hydraulique (spoiler - avec ML aussi).
Si nous décrivons le processus actuel d'identification des puits candidats pour la fracturation hydraulique, il comprendra les étapes suivantes: déchargement des données de puits des systèmes d'information d'entreprise, traitement des données obtenues, réalisation d'une analyse d'experts, accord sur une solution, réalisation de la fracturation hydraulique et analyse des résultats. Ça a l'air simple, mais pas tout à fait.
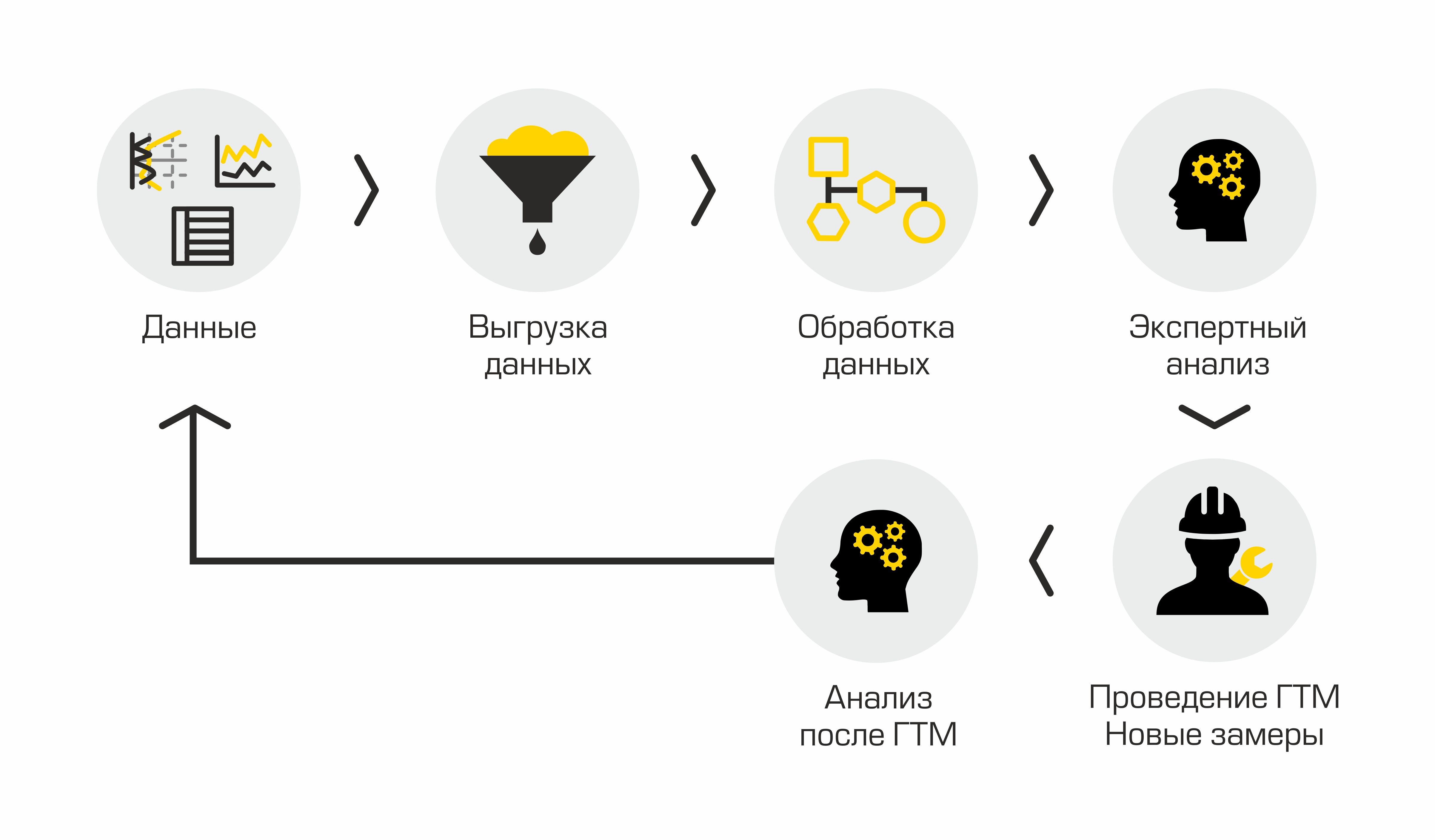
Processus actuel de sélection des puits candidats
Le principal inconvénient de cette approche «manuelle» est beaucoup de routine, les volumes augmentent, les gens commencent à se noyer dans le travail, il n'y a pas de transparence dans le processus et les méthodes.
Formulation du problème
En 2019, notre équipe d'analyse des données a dû créer un système automatisé pour la sélection de puits candidats pour la fracturation hydraulique. Pour nous, cela ressemblait à ceci - simuler l'état de tous les puits, en supposant que pour l'instant, il est nécessaire d'effectuer des opérations de fracturation hydraulique sur eux, puis de classer les puits en fonction de la plus forte augmentation de la production de pétrole et de sélectionner les puits Top-N vers lesquels la flotte ira et prendra des mesures pour augmenter la récupération de pétrole.
À l'aide de modèles ML, des indicateurs sont formés qui indiquent la faisabilité de la fracturation hydraulique à un puits spécifique: production de pétrole après la fracturation hydraulique prévue et le succès de cet événement.
Dans notre cas, le taux de production de pétrole est la quantité de pétrole produite en mètres cubes par mois. Cet indicateur est calculé sur la base de deux valeurs: débit de liquide et coupure d'eau. Les pétroliers appellent un liquide un mélange d'huile et d'eau - c'est ce mélange qui est le produit des puits. Et la coupe d'eau est la proportion de la teneur en eau dans un mélange donné. Afin de calculer le taux de production de pétrole attendu après fracturation, deux modèles de régression sont utilisés: l'un prédit le débit de fluide après fracturation, l'autre prédit la coupure d'eau. À l'aide des valeurs renvoyées par les données du modèle, les prévisions de production de pétrole sont calculées à l'aide de la formule:

Le succès de la fracturation est une variable cible binaire. Elle est déterminée à partir de la valeur réelle de l'augmentation de la production de pétrole obtenue après fracturation hydraulique. Si la croissance est supérieure à un certain seuil déterminé par un expert dans le domaine du domaine, alors la valeur de l'attribut de succès est égale à un, sinon elle est égale à zéro. Ainsi, nous formons le balisage pour résoudre le problème de classification.
Quant à la métrique ... La métrique doit provenir de l'entreprise et refléter les intérêts du client, tout cours d'apprentissage automatique nous le dit. À notre avis, c'est là que réside le principal succès ou échec d'un projet d'apprentissage automatique. Un groupe de data scientists peut améliorer la qualité du modèle aussi longtemps qu'il le souhaite, mais s'il n'augmente pas la valeur commerciale pour le client, un tel modèle est voué à l'échec. Après tout, il était important pour le client d'obtenir un candidat exact avec des prédictions «physiques» des performances du puits après fracturation hydraulique.
Pour le problème de régression, les métriques suivantes ont été choisies:

Pourquoi n'y a-t-il pas une métrique, demandez-vous - chacune reflète sa propre vérité. Pour les champs où les taux de production moyens sont élevés, MAE sera grande et MAPE sera petite. Si nous prenons un champ avec des taux de production moyens faibles, le tableau sera le contraire.
Les métriques suivantes ont été choisies pour le problème de classification:

( wiki ),
Aire sous la courbe ROC - AUC ( wiki ).
Erreurs que nous avons rencontrées
Erreur n ° 1 - pour créer un modèle universel pour tous les champs.
Après avoir analysé les ensembles de données, il est devenu clair que les données changent d'un champ à l'autre. Cela n'est pas surprenant, car les gisements ont généralement une structure géologique différente.
Notre hypothèse que si nous prenons et conduisons toutes les données disponibles pour la formation dans un modèle, alors elle révélera elle-même les régularités de la structure géologique, a échoué. Le modèle formé sur les données d'un champ particulier a montré une meilleure qualité de prédictions que le modèle, qui a été créé en utilisant des informations sur tous les champs disponibles.
Pour chaque domaine, différents algorithmes d'apprentissage automatique ont été testés et, sur la base des résultats de la validation croisée, un avec le MAPE le plus bas a été sélectionné.
Erreur n ° 2 - Manque de compréhension approfondie des données.
Si vous souhaitez créer un bon modèle d'apprentissage automatique pour un véritable processus physique, comprenez comment ce processus se déroule.
Au départ, notre équipe n'avait pas d'expert du domaine et nous avons évolué de manière chaotique. Hélas, nous n'avons pas remarqué les erreurs du modèle lors de l'analyse des prévisions, ils ont tiré des conclusions erronées en fonction des résultats.
Erreur n ° 3 - manque d'infrastructure.
Au début, nous avons téléchargé de nombreux fichiers csv différents pour différents champs et différents paramètres. À un moment donné, un nombre insoutenable de fichiers et de modèles s'est accumulé. Il est devenu impossible de reproduire les expériences déjà réalisées, les fichiers ont été perdus et la confusion s'est installée.
1. PARTIE TECHNIQUE
Aujourd'hui, notre système d'auto-sélection des candidats ressemble à ceci:
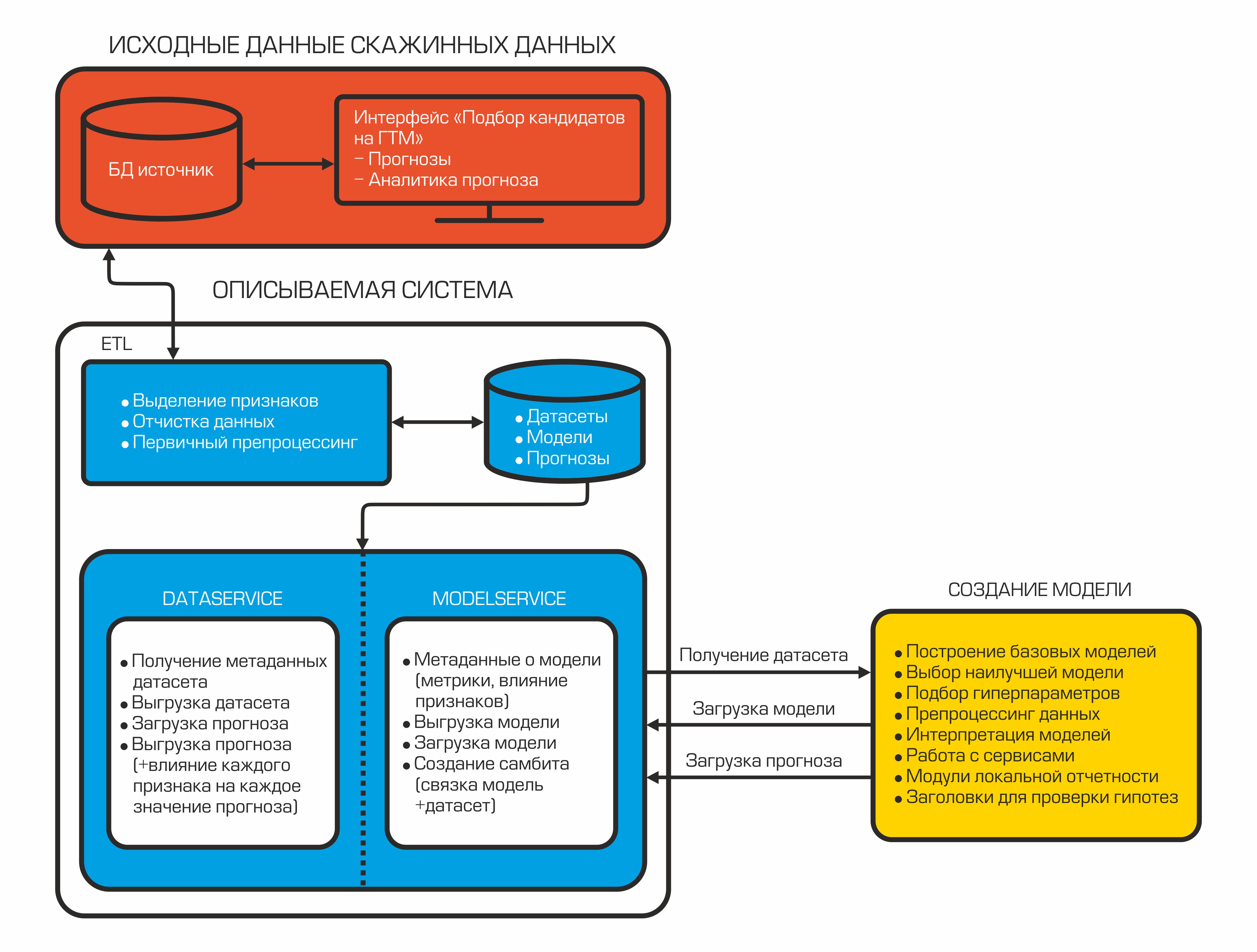
Chaque composant est un conteneur isolé qui remplit une fonction spécifique.
2.1 ETL = chargement de données
Tout commence par les données. Surtout si nous voulons construire un modèle d'apprentissage automatique. Nous avons choisi Pentaho Data Integration comme système d'intégration.

Capture d'écran de l'une des transformations
Principaux avantages:
- système gratuit;
- un grand choix de composants pour se connecter à diverses sources de données et transformer le flux de données;
- disponibilité d'une interface Web;
- la possibilité de gérer via l'API REST;
- enregistrement.
En plus de tout ce qui précède, nous avions une vaste expérience dans le développement d'intégrations pour ce produit. Pourquoi l'intégration des données est-elle nécessaire dans les projets ML? Dans les ensembles de données de préparation sont constamment nécessaires pour mettre en œuvre des calculs complexes pour fournir des données à un esprit commun « sur le chemin » pour calculer de nouveaux signes - .. moyenne, le paramètre change au fil du temps, etc.
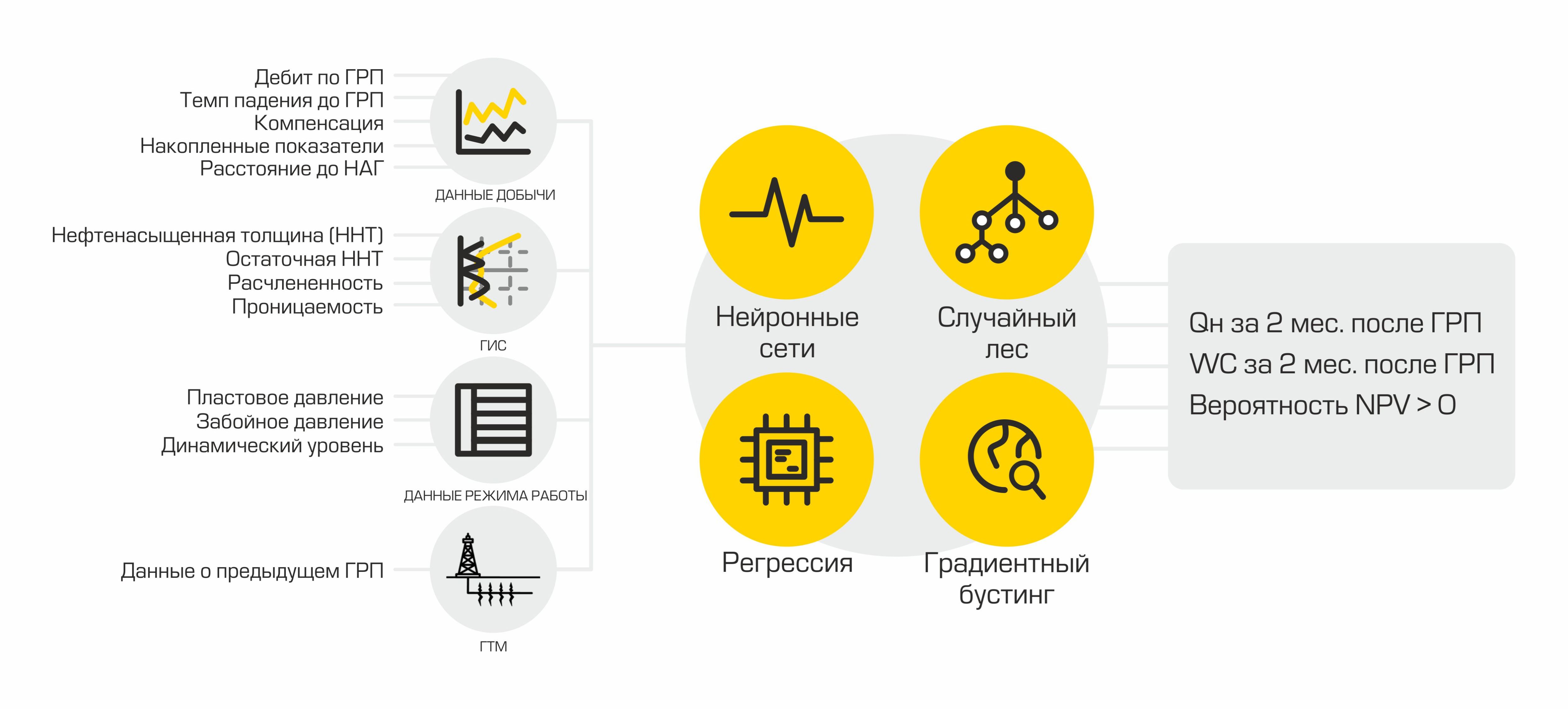
Pour chaque fracturation fait déchargé plus de 400 paramètres décrivant le travail de puits au moment de activités, l'exploitation des puits adjacents, ainsi que des informations sur la fracturation hydraulique précédemment réalisée. En outre, la transformation et le prétraitement des données ont lieu.
Nous avons choisi PostgreSQL comme référentiel pour les données traitées. Il dispose d'un large éventail de méthodes pour travailler avec json. Puisque nous stockons les ensembles de données finaux dans ce format, cela est devenu un facteur décisif.
Un projet d'apprentissage automatique est associé à un changement constant des données d'entrée en raison de l'ajout de nouvelles fonctionnalités, par conséquent, Data Vault est utilisé comme schéma de base de données (lien vers wiki). Ce schéma de conception de stockage vous permet d'ajouter rapidement de nouvelles données sur un objet et de ne pas violer l'intégrité des tables et des requêtes.
2.2 Services de données et de modèles
Après avoir peigné et calculé les indicateurs nécessaires, les données sont téléchargées dans la base de données. Ils sont stockés ici et attendent que l'interpréteur de données les prenne pour créer le modèle ML. Pour cela, il existe DataService - un service écrit en Python et utilisant le protocole gRPC. Il vous permet d'obtenir des jeux de données et leurs métadonnées (types d'entités, leur description, taille des jeux de données, etc.), charger et décharger des prévisions, gérer les paramètres de filtrage et de division par train / test. Les prévisions dans la base de données sont stockées au format json, ce qui vous permet de recevoir rapidement des données et de stocker non seulement la valeur de prévision, mais également l'influence de chaque fonctionnalité sur cette prévision particulière.
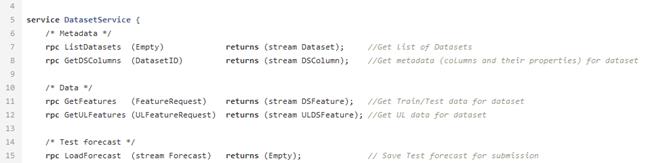
Exemple de fichier proto pour le service de données.
Lorsque le modèle est créé, il doit être enregistré - à cette fin, un ModelService est utilisé, également écrit en Python avec gRPC. Les capacités de ce service ne se limitent pas à l'enregistrement et au chargement d'un modèle. En outre, il vous permet de surveiller les métriques, l'importance des fonctionnalités et implémente également une connexion modèle + ensemble de données pour la création automatique ultérieure d'une prévision lorsque de nouvelles données apparaissent.

La structure de notre service modèle ressemble à ceci.
2.3 Modèle ML
À un certain moment, notre équipe s'est rendu compte que l'automatisation devrait également affecter la création de modèles ML. Ce besoin était motivé par la nécessité d'accélérer le processus de préparation des prévisions et de test des hypothèses. Et nous avons pris la décision de développer et d'implémenter notre propre bibliothèque AutoML dans notre pipeline.
Au départ, la possibilité d'utiliser des bibliothèques AutoML prêtes à l'emploi a été envisagée, mais les solutions existantes se sont révélées insuffisamment flexibles pour notre tâche et ne disposaient pas de toutes les fonctionnalités nécessaires à la fois (à la demande des travailleurs, nous pouvons écrire un article séparé sur notre AutoML). Nous notons seulement que le framework que nous avons développé contient des classes utilisées pour prétraiter un jeu de données, générer et sélectionner des entités. En tant que modèles d'apprentissage automatique, nous utilisons un ensemble d'algorithmes familier que nous avons utilisé avec le plus de succès auparavant: implémentations de boosting de gradient à partir de xgboost, bibliothèques catboost, une forêt aléatoire de Sklearn, un réseau de neurones entièrement connecté sur Pytorch, etc. Après l'entraînement, AutoML renvoie un pipeline sklearn qui comprend les classes mentionnées, ainsi que le modèle ML,qui a montré le meilleur résultat en validation croisée pour la métrique sélectionnée.
En plus du modèle, un rapport est formé sur l'influence de tout signe sur une prévision spécifique. Un tel rapport permet aux géologues de regarder sous le capot d'une mystérieuse boîte noire. Ainsi, AutoML reçoit l'ensemble de données balisé à l'aide du DataService et, après l'entraînement, forme le modèle final. Ensuite, nous pouvons obtenir l'estimation finale de la qualité du modèle en chargeant l'ensemble de données de test, en générant des prévisions et en calculant des mesures de qualité. La dernière étape consiste à télécharger un fichier binaire du modèle généré, sa description, les métriques vers le ModelService, tandis que les prévisions et les informations sur l'influence des fonctionnalités sont renvoyées au DataService.
Ainsi, notre modèle est placé dans un tube à essai et est prêt à être lancé en prod. À tout moment, nous pouvons l'utiliser pour générer des prévisions basées sur de nouvelles données pertinentes.
2.4 Interface
L'utilisateur final de notre produit est un géologue et il doit interagir d'une manière ou d'une autre avec le modèle ML. Le moyen le plus pratique pour lui est un module de logiciel spécialisé. Nous l'avons mis en œuvre.
Le front-end disponible pour notre utilisateur ressemble à une boutique en ligne: vous pouvez sélectionner le champ souhaité et obtenir une liste des puits les plus probables. Dans la carte de puits, l'utilisateur voit la croissance prévue après fracturation hydraulique et décide lui-même s'il souhaite l'ajouter au «panier» et l'examiner plus en détail.

Interface du module dans l'application.

Voici à quoi ressemble la carte de puits en annexe.
En plus des gains d'huile et de liquide prévus, l'utilisateur peut également découvrir quelles caractéristiques ont influencé le résultat proposé. L'importance des fonctionnalités est calculée au stade de la création d'un modèle à l'aide de la méthode shap , puis chargée dans l'interface logicielle avec le DataService.

L'application montre clairement quelles fonctionnalités étaient les plus importantes pour les prédictions de modèle.
L'utilisateur peut également regarder des analogues du puits d'intérêt. La recherche d'analogues est implémentée côté client à l'aide de l'algorithme de l' arbre Kd .
Le module affiche des puits avec des paramètres géologiques similaires.
2. COMMENT NOUS AVONS AMÉLIORÉ LE MODÈLE ML

Il semblerait que cela vaille la peine d'exécuter AutoML sur les données disponibles, et nous serons heureux. Mais il se trouve que la qualité des prévisions obtenues automatiquement ne peut être comparée aux résultats des datasinters. Le fait est que les analystes avancent et testent souvent diverses hypothèses pour améliorer les modèles. Si l'idée améliore la précision des prévisions sur des données réelles, elle est mise en œuvre dans AutoML. Ainsi, en ajoutant de nouvelles fonctionnalités, nous avons suffisamment amélioré la prévision automatique pour passer à la création de modèles et de prévisions avec une implication minimale des analystes. Voici quelques hypothèses qui ont été testées et implémentées dans notre AutoML:
1. Modification de la méthode de remplissage
Dans les tout premiers modèles, nous avons comblé presque toutes les lacunes dans les caractéristiques avec la moyenne, à l'exception des catégories catégoriques - pour eux, la signification la plus courante était utilisée. Plus tard, grâce au travail conjoint d'analystes et d'un expert, dans le domaine du domaine, il a été possible de sélectionner les valeurs les plus adaptées pour combler les lacunes de 80% des fonctionnalités. Nous avons également essayé quelques méthodes de remplissage supplémentaires en utilisant les bibliothèques sklearn et missingpy. Les meilleurs résultats ont été obtenus avec un remplissage constant et KNNImputer - jusqu'à 5% MAPE.

Résultats d'une expérience sur le comblement des lacunes avec différentes méthodes.
2. Génération de fonctionnalités
L'ajout de nouvelles fonctionnalités est un processus itératif pour nous. Pour améliorer les modèles, nous essayons d'ajouter de nouvelles fonctionnalités basées sur les recommandations d'un expert du domaine, basées sur l'expérience d'articles scientifiques et nos propres conclusions à partir des données.

Tester les hypothèses avancées par l'équipe permet d'introduire de nouvelles fonctionnalités.
L'une des premières concernait les caractéristiques identifiées sur la base du regroupement. En fait, nous avons simplement sélectionné des grappes dans l'ensemble de données en fonction de paramètres géologiques et généré des statistiques de base pour d'autres caractéristiques basées sur des grappes - cela a donné une légère augmentation de la qualité.
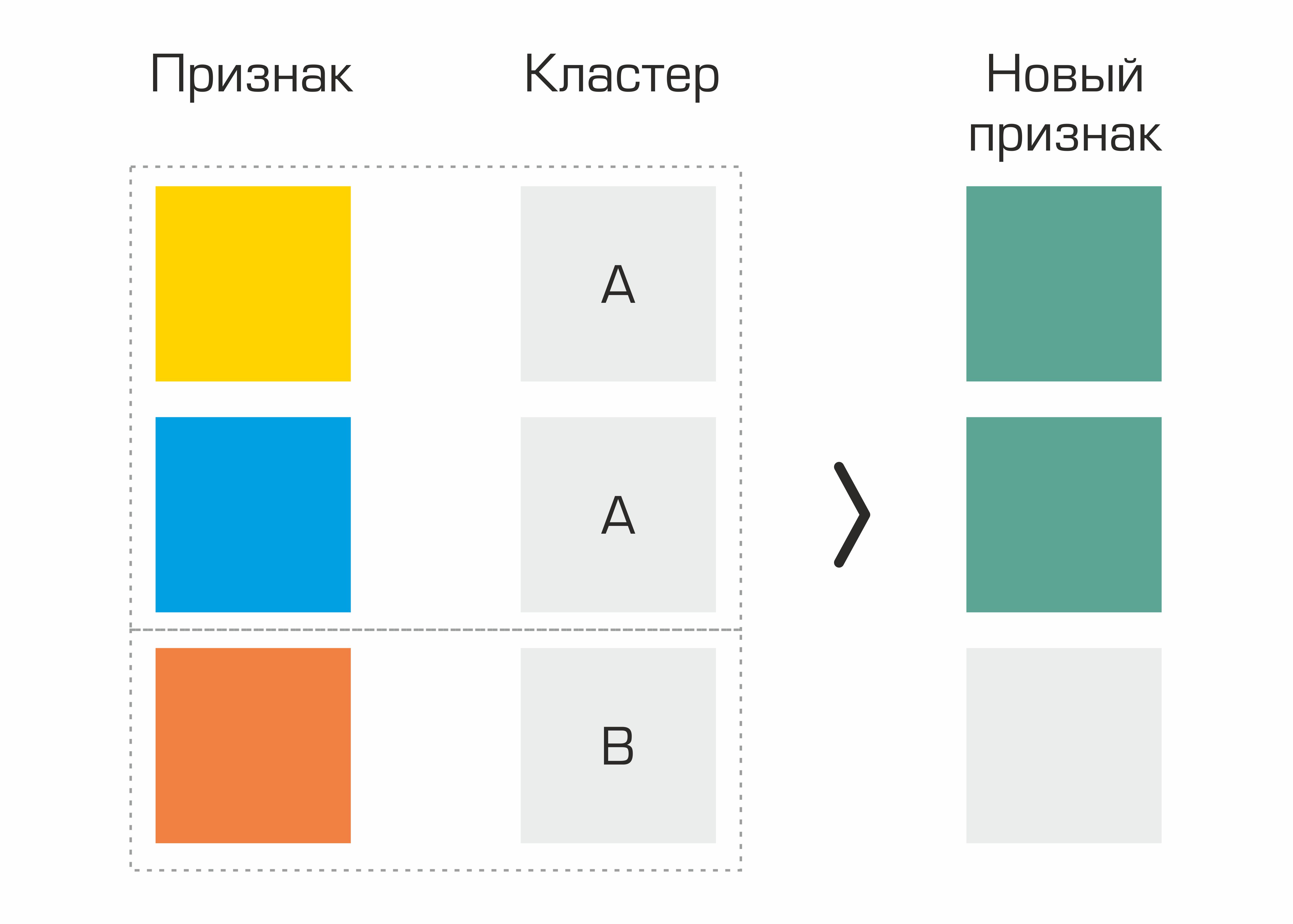
Processus de création d'une fonctionnalité basée sur la sélection de clusters.
Nous avons également ajouté les signes que nous avons inventés lors de l'immersion dans la région du domaine: la production cumulative d'huile normalisée à l'âge du puits en mois, l'injection accumulée normalisée à l'âge du puits en mois, les paramètres inclus dans la formule de Dupuis. Mais la génération de l'ensemble standard de PolynomialFeatures de sklearn ne nous a pas donné une augmentation de la qualité.
3.
Sélection des fonctionnalités Nous avons effectué plusieurs fois la sélection des fonctionnalités : à la fois manuellement avec un expert du domaine et en utilisant des méthodes de sélection de fonctionnalités standard. Après plusieurs itérations, nous avons décidé de supprimer des données certaines fonctionnalités qui n'affectent pas la cible. Ainsi, nous avons réussi à réduire la taille du jeu de données, tout en conservant la même qualité, ce qui a permis d'accélérer considérablement la création des modèles.
Et maintenant sur les métriques reçues ...
Dans l'un des champs, nous avons obtenu les indicateurs de qualité du modèle suivants:

Il convient de noter que le résultat de la fracturation hydraulique dépend également d'un certain nombre de facteurs externes non prédits. Par conséquent, nous ne pouvons pas parler de réduire MAPE à 0.
Conclusion La
sélection de puits candidats pour la fracturation hydraulique par ML est un projet ambitieux qui a réuni 7 personnes: ingénieurs de données, datascientists, experts du domaine et gestionnaires. Aujourd'hui, le projet est actuellement prêt pour le lancement et est déjà en cours de test dans plusieurs filiales de la société.
L'entreprise est ouverte à l'expérimentation, donc environ 20 puits ont été sélectionnés dans la liste et fracturés. L'écart de la prévision avec la valeur réelle du taux de production d'huile de départ (MAPE) était d'environ 10%. Et c'est un très bon résultat!
Ne soyons pas rusés: surtout au stade initial, plusieurs de nos puits proposés se sont avérés être des options inadaptées.
Écrivez des questions et des commentaires - nous essaierons d'y répondre.
Abonnez-vous à notre blog, nous avons beaucoup plus d'idées et de projets intéressants, sur lesquels nous allons certainement écrire!