
Les bases de données graphiques sont une technologie importante pour les professionnels des bases de données. J'essaie de suivre les innovations et les nouvelles technologies dans ce domaine et, après avoir travaillé avec des bases de données relationnelles et NoSQL, je constate que le rôle des bases de données de graphes se développe. Lorsque vous travaillez avec des données hiérarchiques complexes, non seulement les bases de données traditionnelles, mais également NoSQL sont inefficaces. Souvent, avec une augmentation du nombre de niveaux de liens et de la taille de la base, il y a une diminution des performances. Et à mesure que les relations deviennent plus complexes, le nombre de JOIN augmente également.
Bien sûr, il existe des solutions dans le modèle relationnel pour travailler avec des hiérarchies (par exemple, en utilisant des CTE récursifs), mais ce sont toujours des solutions de contournement. Dans le même temps, la fonctionnalité des bases de données graphiques SQL Server vous permet de traiter facilement plusieurs niveaux de la hiérarchie. Le modèle de données et les requêtes sont simplifiés et donc plus efficaces. La quantité de code est considérablement réduite.
Les bases de données graphiques sont un langage expressif pour représenter des systèmes complexes. Cette technologie est déjà largement utilisée dans l'industrie informatique dans des domaines tels que les réseaux sociaux, les systèmes anti-fraude, l'analyse des réseaux informatiques, les recommandations sociales, les recommandations de produits et de contenus.
La fonctionnalité de base de données graphique de SQL Server convient aux scénarios dans lesquels les données sont fortement interconnectées et ont des relations bien définies.
Modèle de données graphique
Un graphe est un ensemble de sommets (nœuds) et d'arêtes (relations). Les sommets représentent des entités et les arêtes représentent des liens, dont les attributs peuvent contenir des informations.
Une base de données de graphes modélise des entités sous la forme d'un graphe, tel que défini dans la théorie des graphes. Les structures de données sont des sommets et des arêtes. Les attributs sont les propriétés des sommets et des arêtes. Un lien est une connexion de sommets.
Contrairement aux autres modèles de données, dans les bases de données de graphes, les relations entre les entités sont prioritaires. Par conséquent, il n'est pas nécessaire de calculer les relations à l'aide de clés étrangères ou d'une autre manière. Vous pouvez créer des modèles de données complexes en utilisant uniquement des abstractions de sommets et d'arêtes.
Dans le monde moderne, la modélisation des relations nécessite des techniques de plus en plus sophistiquées. Pour la modélisation des relations, SQL Server 2017 offre des fonctionnalités de base de données de graphiques. Les sommets et les arêtes du graphe sont représentés comme de nouveaux types de tableaux: NODE et EDGE. Une nouvelle fonction T-SQL appelée MATCH () est utilisée pour interroger le graphique. Étant donné que cette fonctionnalité est intégrée à SQL Server 2017, elle peut être utilisée dans vos bases de données existantes sans aucune conversion.
Avantages du modèle graphique
Aujourd'hui, les entreprises et les utilisateurs sont des applications exigeantes qui traitent de plus en plus de données tout en s'attendant à des performances et une fiabilité élevées. La présentation des données sous forme de graphique offre un outil pratique pour gérer des relations complexes. Cette approche résout de nombreux problèmes et vous aide à obtenir des résultats dans un contexte donné.
Il semble qu'à l'avenir, de nombreuses applications bénéficieront de l'utilisation de bases de données de graphes.
Modélisation des données: du modèle relationnel au modèle graphique
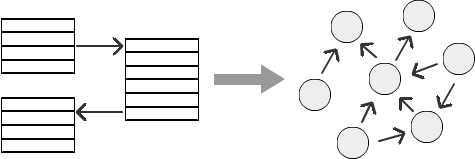
Exemple
Prenons un exemple de structure organisationnelle avec une hiérarchie d'employés: un employé rapporte à un gestionnaire, un gestionnaire rapporte à un cadre supérieur, et ainsi de suite. Cette hiérarchie peut avoir n'importe quel nombre de niveaux, selon une entreprise particulière. Mais à mesure que le nombre de niveaux augmente, le calcul des relations dans une base de données relationnelle devient de plus en plus difficile. Il est assez difficile de représenter la hiérarchie des employés, la hiérarchie dans le marketing ou les connexions aux médias sociaux. Voyons comment SQL Graph peut résoudre le problème de la gestion des différents niveaux de la hiérarchie.
Pour cet exemple, créons un modèle de données simple. Créons une table d'employés EMP avec un identifiant EMPNO et une colonne MGR, indiquant l'identifiant du manager (manager) de l'employé. Toutes les informations sur la hiérarchie sont stockées dans ce tableau et peuvent être interrogées à l'aide des colonnes EMPNO et MGR .
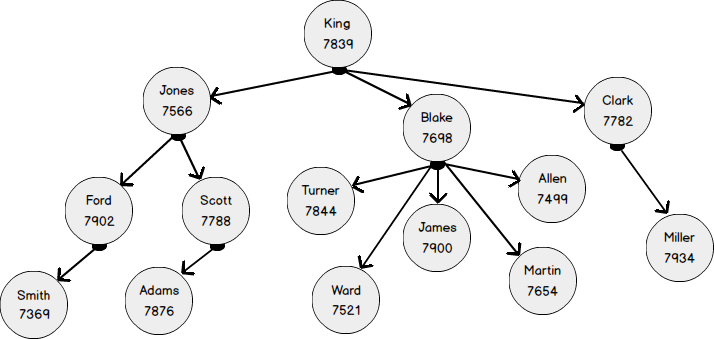
Le diagramme suivant montre le même modèle d'organigramme avec quatre niveaux d'imbrication sous une forme plus familière. Les employés sont les sommets du graphique de la table EMP . L'entité «employé» est reliée à elle-même par le lien «soumet» (ReportsTo). En termes de graphes, un lien est une arête (EDGE) qui relie les nœuds (NODE) des employés.
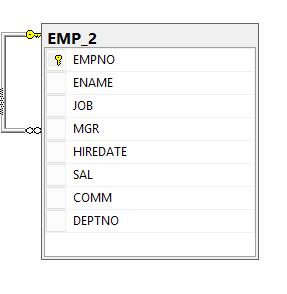
Créons une table EMP régulière et ajoutons-y les valeurs selon le diagramme ci-dessus.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)La figure ci-dessous montre les employés:
- l'employé avec EMPNO 7369 relève du 7902;
- employé avec EMPNO 7902 obéit à 7566
- employé avec EMPNO 7566 obéit 7839
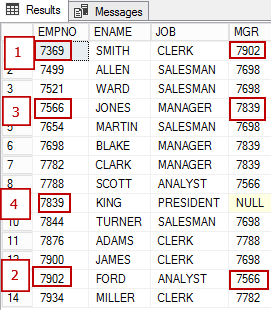
Regardons maintenant une représentation graphique des mêmes données. Le nœud EMPLOYEE possède plusieurs attributs et est associé à lui-même par la relation "obey" (EmplReportsTo). EmplReportsTo est le nom de la relation.
La table d'arêtes (EDGE) peut également contenir des attributs.
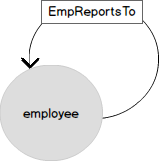
Créer la table de nœuds EmpNode
La syntaxe pour créer un nœud est assez simple: l'instruction CREATE TABLE est ajoutée avec "AS NODE" à la fin .
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Transformons maintenant les données d'un tableau régulier en un graphique. Le prochain INSERT insère les données de la table relationnelle EMP .
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp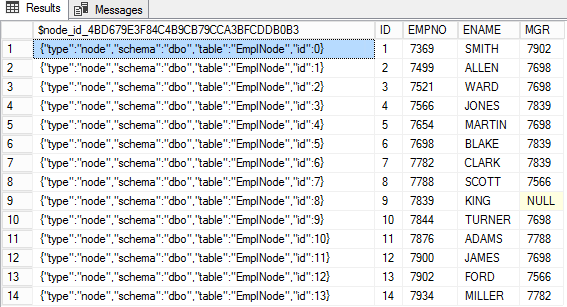
L'
$node_id_*ID de nœud est stocké dans une colonne spéciale de la table des nœuds sous la forme de JSON. Les colonnes restantes de ce tableau contiennent les attributs de nœud.
Créer des arêtes (EDGE)
La création d'une table d'arêtes est très similaire à la création d'une table de nœuds, sauf que le mot-clé "AS EDGE" est utilisé .
CREATE TABLE empReportsTo(Deptno int) AS EDGE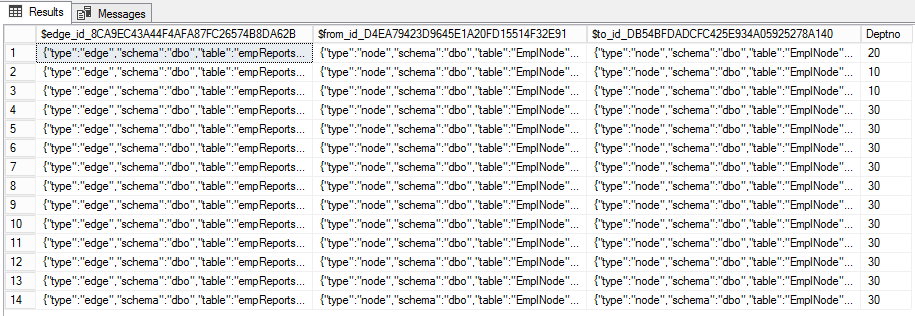
Définissons maintenant les relations entre les employés à l'aide des colonnes EMPNO et MGR . L'organigramme montre comment écrire INSERT .
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30);La table d'arêtes par défaut comporte trois colonnes. Le premier
$edge_idest l'identifiant JSON de l'arête. Les deux autres ( $from_idet $to_id) représentent les communications entre les nœuds. De plus, les nervures peuvent avoir des propriétés supplémentaires. Dans notre cas, c'est Deptno .
Vues système
Il y a
sys.tablesdeux nouvelles colonnes dans la vue système :
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%'
SSMS
Les objets liés aux graphiques se trouvent dans le dossier Tables des graphiques. L'icône de la table des nœuds est marquée d'un point, et l'icône de la table des bords est marquée par deux cercles connectés (qui ressemble un peu à des lunettes).

Expression MATCH
L'expression MATCH est tirée de CQL (Cypher Query Language). Il s'agit d'un moyen efficace d'interroger les propriétés d'un graphique. CQL commence par une expression MATCH .
Syntaxe
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasExemples
Jetons un coup d'œil à quelques exemples.
La requête ci-dessous affiche les employés auxquels Smith et son responsable relèvent.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH'
La requête suivante concerne la recherche d'employés et de gestionnaires de deuxième niveau pour Smith. Si vous supprimez la clause WHERE , le résultat affichera tous les employés.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH'
Et enfin, une demande d'employés et de managers de troisième niveau.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH'
Maintenant, changeons de direction pour obtenir les patrons de Smith.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3)
Conclusion
SQL Server 2017 s'est imposé comme une solution d'entreprise complète pour divers défis commerciaux informatiques. La première version de SQL Graph est très prometteuse. Malgré certaines limitations, il existe déjà suffisamment de fonctionnalités pour explorer les capacités des graphiques.
La fonctionnalité SQL Graph est entièrement intégrée au moteur SQL. Cependant, comme mentionné, SQL Server 2017 présente les limitations suivantes:
Aucune prise en charge du polymorphisme.
- .
- $from_id $to_id UPDATE.
- (transitive closure), CTE.
- In-Memory OLTP.
- (System-Versioned Temporal Table), .
- NODE EDGE.
- (cross-database queries).
- - (wizard) .
- GUI, Power BI.

: