
Dans cet article, je vais vous expliquer:
- quel genre de bête est ce flux d'air, de quels composants il se compose et comment ils interagissent les uns avec les autres
- à propos des principales entités d'Airflow: des pipelines appelés DAG, Operator et quelques autres choses
- comment réussir son développement sur Airflow
- comment nous avons implémenté la génération de pipelines et la soi-disant «écriture déclarative de pipelines»
- sur les avantages et les inconvénients de l'utilisation d'Airflow
Qu'est-ce que Airflow
Airflow est une plateforme de création, de surveillance et d'orchestration de pipelines. Ce projet open source, écrit en Python, a été créé en 2014 chez Airbnb. En 2016, Airflow est passé sous l'aile de l'Apache Software Foundation, est passé par un incubateur et est devenu début 2019 un projet Apache de haut niveau.
Dans le monde du traitement des données, certains l'appellent un outil ETL, mais il ne s'agit pas exactement d'ETL au sens classique, comme Pentaho, Informatica PowerCenter, Talend et d'autres comme eux. Airflow est un orchestrateur, «cron on batteries»: il ne fait pas lui-même le gros travail de transfert et de traitement des données, mais indique aux autres systèmes et frameworks ce qu'il faut faire et surveille l'état d'exécution. Nous l'utilisons principalement pour exécuter des requêtes dans des travaux Hive ou Spark.
Divulgacher
Airflow, worker ( ), . , , .
La gamme de tâches résolues à l'aide d'Airflow ne se limite pas à l'exécution de quelque chose dans un cluster Hadoop. Il peut exécuter du code Python, exécuter des commandes Bash, héberger des conteneurs et des pods Docker dans Kubernetes, exécuter des requêtes sur votre base de données préférée, etc.
Architecture du flux d'air
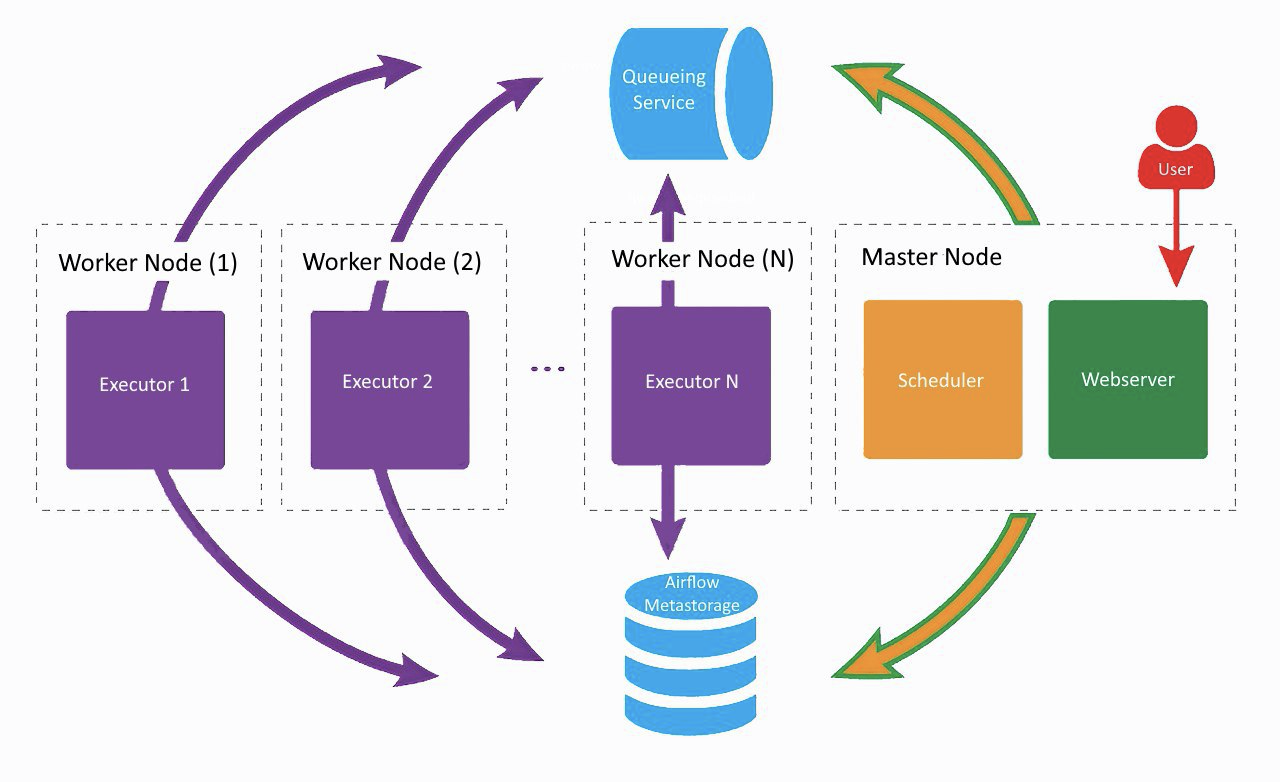
C'est à peu près à quoi ressemble notre configuration actuelle Airflow, seul Lamoda utilise deux ouvriers. Sur une machine séparée, le serveur Web et le planificateur tournent, les travailleurs soufflent sur les voisins. L'un a été créé pour les tâches régulières, le second a été adapté pour exécuter la formation des modèles ML à l'aide de Vowpal Wabbit. Tous les composants communiquent entre eux via une file d'attente de tâches et une base de métadonnées.
À l'aube du développement d'Airflow dans l'entreprise, tous les composants (à l'exception de la base de données) fonctionnaient sur la même machine, mais à un moment donné, cela a conduit à un manque de ressources sur le serveur et à des retards dans le fonctionnement du planificateur. Par conséquent, nous avons décidé de distribuer les services sur différents serveurs et sommes arrivés à l'architecture montrée dans l'image ci-dessus.
Composants de flux d'air
Webserver
Webserver est une interface Web montrant ce qui se passe avec le pipeline. Cette page est
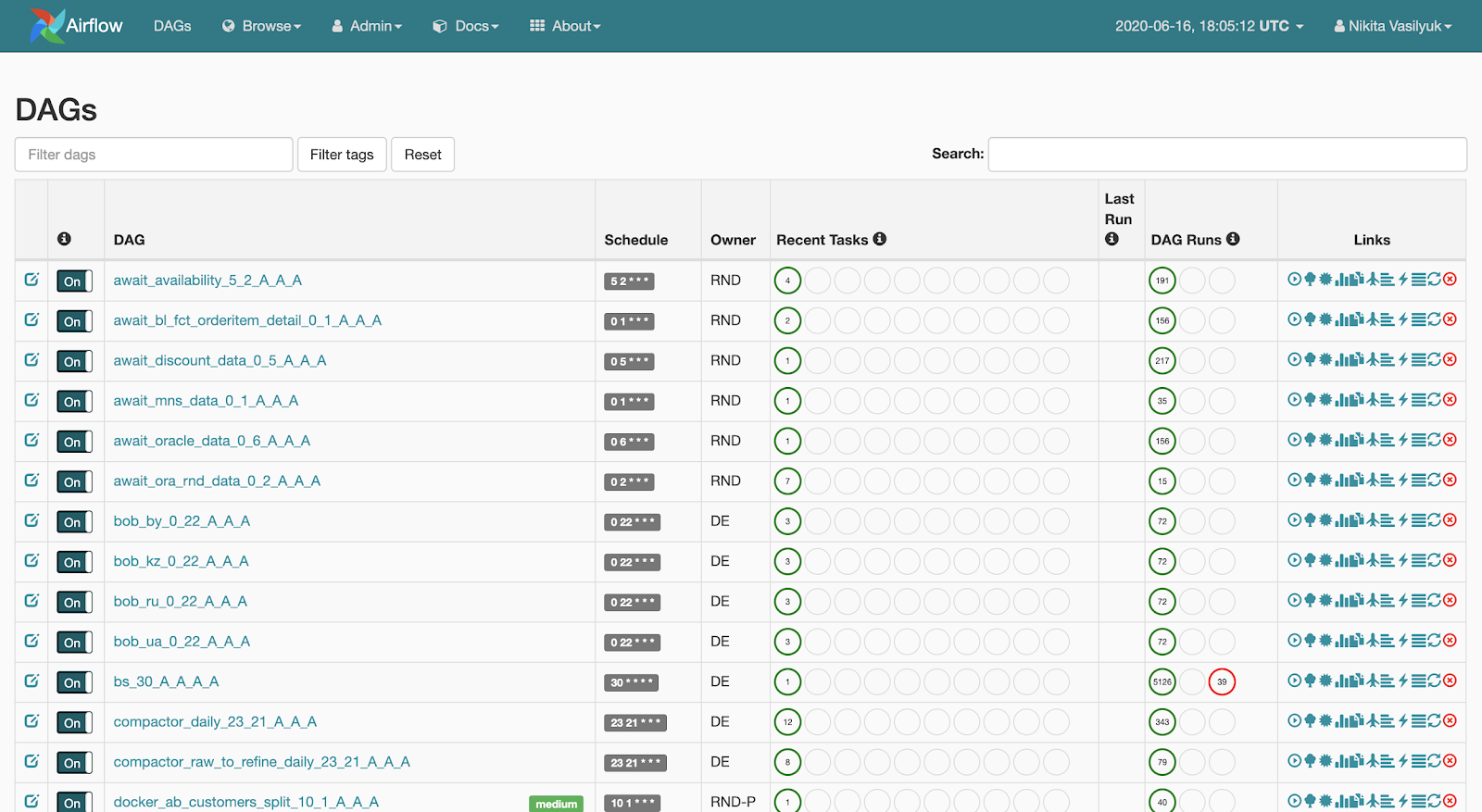
visible par l' utilisateur: Le serveur web permet de visualiser la liste des pipelines disponibles. De brèves statistiques de lancements sont affichées à côté de chaque pipeline. Il existe également plusieurs boutons qui forcent le pipeline à démarrer ou à afficher des informations détaillées: statistiques de lancement, code source du pipeline, sa visualisation sous forme de graphique ou de tableau, une liste de tâches et l'historique de leurs lancements.
Si nous cliquons sur le pipeline, nous tomberons dans le menu Affichage graphique. Les tâches et les liens entre eux sont affichés ici.
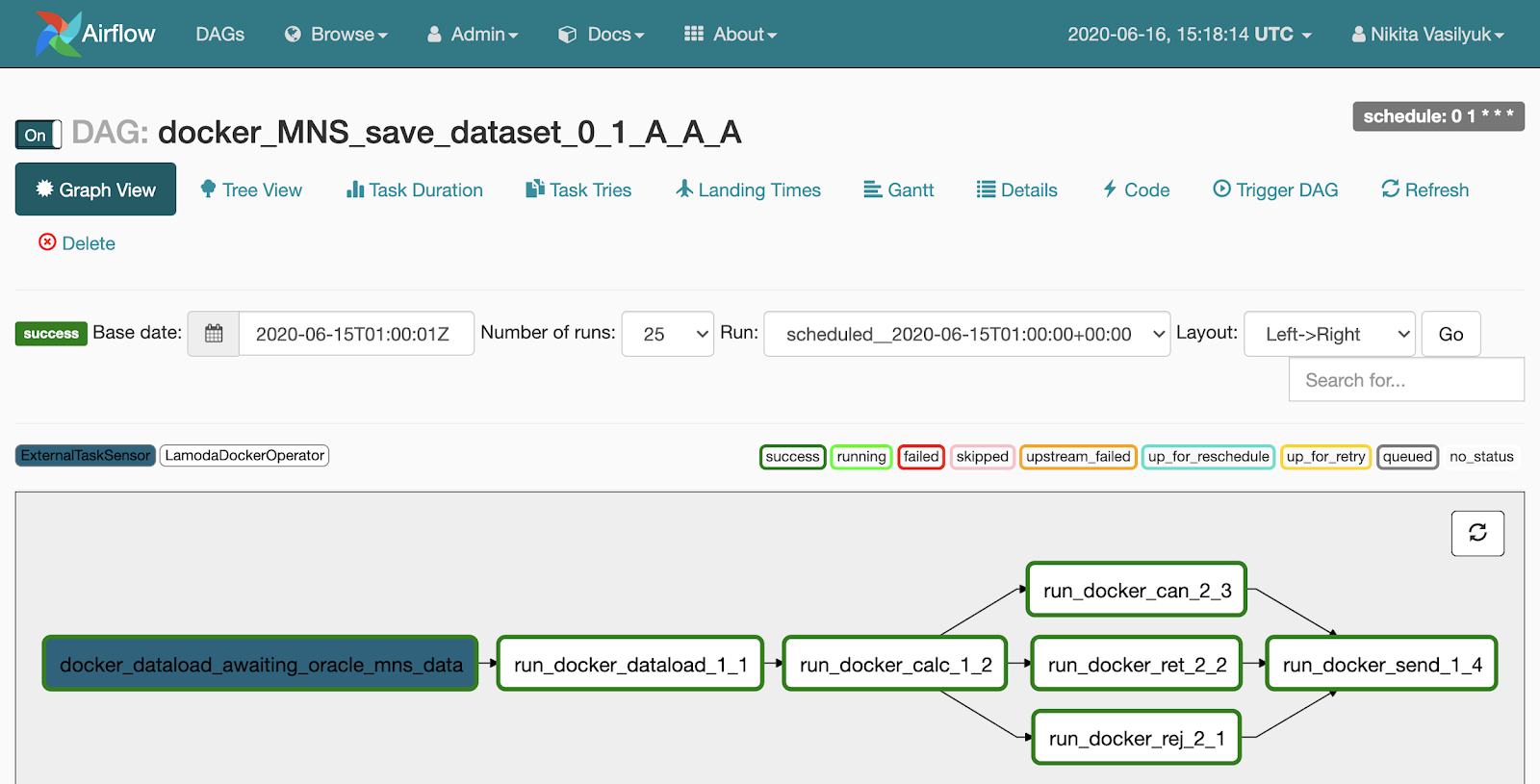
Il y a un menu arborescent à côté de la vue graphique. Il a été créé pour redémarrer les tâches, afficher les statistiques et les journaux. La vue arborescente du graphique est affichée sur le côté gauche, en face se trouve un tableau avec l'historique du lancement de la tâche.
Chaque ligne de cette table effrayante est une tâche, chaque colonne est un début du pipeline. À leur intersection, il y a un carré avec le lancement d'une tâche spécifique pour une date précise. Si vous cliquez dessus, un menu apparaît dans lequel vous pouvez afficher les informations détaillées et les journaux de cette tâche, la démarrer ou la redémarrer, et également la marquer comme réussie ou non.

Scheduler - comme son nom l'indique, lance des pipelines le moment venu. Il s'agit d'un processus Python qui va périodiquement dans le répertoire avec les pipelines, extrait leur état actuel à partir de là, vérifie l'état et le démarre. En général, le Scheduler est le plus intéressant et en même temps le goulot d'étranglement de l'architecture Airflow.
- La première mise en garde est qu'une seule instance de Scheduler peut être exécutée à la fois. Cela signifie que le mode Haute disponibilité n'est actuellement pas possible (les développeurs prévoient d'ajouter Scheduler HA à Airflow version 2.0).
- : , - . , - , .
Jusqu'à un certain temps, le délai est réglé par les paramètres du fichier de configuration Airflow, mais le délai de lancement persiste. Il en découle qu'Airflow ne concerne pas le traitement de données en temps réel. Si vous agissez par inadvertance et spécifiez un intervalle de lancement trop fréquent (une fois toutes les deux minutes), vous pouvez obtenir un retard dans votre pipeline. L'expérience montre qu'une fois toutes les 5 minutes, c'est déjà assez souvent, et certains ne recommandent pas d'exécuter le pipeline toutes les 10 minutes. Nous avons quelques pipelines qui démarrent toutes les 10 minutes, ils sont assez simples et jusqu'à présent, ils n'ont posé aucun problème.
Worker
Worker est l'endroit où notre code s'exécute et les tâches sont effectuées. Airflow prend en charge plusieurs exécuteurs:
- Le premier, le plus simple, est le SequentialExecutor. Il lance séquentiellement les tâches entrantes et met en pause le planificateur pendant la durée de leur exécution.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Entités Apache Airflow
Pipeline, ou DAG
L'essence la plus importante d'Airflow est le DAG, alias un pipeline, alias un graphe acyclique dirigé. Pour clarifier comment le cuisiner et pourquoi vous en avez besoin, je vais analyser un petit exemple.
Disons qu'un analyste est venu nous voir et nous a demandé de remplir des données dans un certain tableau une fois par jour. Il a préparé toutes les informations: quoi obtenir d'où, quand commencer, avec quel SLA. Voici un exemple de la façon dont nous pourrions décrire notre pipeline.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
Le dag_id contient le nom unique du pipeline. Ensuite, nous utilisons schedule_interval pour spécifier la fréquence à laquelle il doit s'exécuter.
Point très important: comme Airflow a été développé par une société internationale, il ne fonctionne qu'en UTC. Pour le moment, il n'y a pas de moyen sensé de faire fonctionner Airflow dans un fuseau horaire différent, vous devez donc constamment vous souvenir de la différence entre notre fuseau horaire et UTC. Dans la version 1.10.10, il est devenu possible de changer le fuseau horaire dans l'interface utilisateur, mais cela ne s'applique qu'à l'interface Web, les pipelines fonctionneront toujours en UTC.
Le paramètre default_args est un dictionnaire qui décrit les arguments par défaut pour toutes les tâches de ce pipeline. Les noms de la plupart des paramètres se décrivent bien, je ne m'attarderai pas sur eux.
Opérateur
Un opérateur est une classe Python qui décrit les actions à effectuer dans notre tâche quotidienne afin de ravir l'analyste.
Nous pouvons utiliser HiveOperator, qui, curieusement, est conçu pour envoyer des demandes d'exécution à Hive. Pour démarrer l'opérateur, vous devez spécifier le nom de la tâche, le pipeline, l'ID de la connexion à Hive et la requête en cours d'exécution.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
Il y a un morceau de modèle Jinja dans la requête que nous transmettons au constructeur de l'opérateur. Jinja est une bibliothèque de modèles Python.
Chaque lancement de pipeline stocke des informations sur la date de lancement. Il réside dans une variable appelée date_exécution. {{ds}} est une macro qui prendra en execution_date uniquement la date au format% Y-% m-% d. À un certain moment avant de démarrer l'opérateur, Airflow rendra une chaîne de requête, y substituera la date requise et enverra une demande d'exécution.
ds n'est pas la seule macro, il y en a environ 20 (une liste de toutes les macros disponibles) . Ils incluent différents formats de date et quelques fonctions pour travailler avec des dates - ajouter ou soustraire quelques jours.
Quand je me suis familiarisé avec Airflow, je n'ai pas compris pourquoi toutes sortes de macros sont nécessaires, alors que vous pouvez simplement insérer un appel datetime.now () là-bas et profiter de la vie. Mais dans certains cas, cela peut grandement ruiner notre vie et celle de l'analyste. Par exemple, si nous voulons recalculer quelque chose pour une date dans le passé, Airflow y substituera non pas la date de début du pipeline, mais l'heure d'exécution réelle. Et dans certains cas, nous pouvons ne pas obtenir ce à quoi nous nous attendons.
Par exemple, si nous voulons redémarrer le pipeline pour mardi dernier, lorsque vous utilisez datetime.now (), nous recalculerons en fait le pipeline pour aujourd'hui, et non pour la date requise. De plus, les données d'aujourd'hui ne sont peut-être même pas prêtes à ce stade.
Après avoir terminé avec succès la demande, nous pouvons envoyer une notification à Slack concernant le chargement des données. Ensuite, nous commandons Airflow, dans quel ordre commencer les tâches. Grâce à la surcharge de l'opérateur dans Airflow, je peux facilement utiliser l'opérateur >> pour spécifier l'ordre des étapes dans le pipeline. Dans mon exemple, nous disons que nous allons commencer par exécuter la requête, puis envoyer une notification à slack.
Idempotence
Il est impossible de parler d'Airflow sans mentionner l'idempotence. Au cas où, permettez-moi de vous rappeler: l'idempotence est une propriété d'un objet, lorsque vous réappliquez une opération à un objet, retournez toujours le même résultat.
Dans le contexte d'Airflow, cela signifie que si aujourd'hui est vendredi et que nous redémarrons la tâche mardi dernier, la tâche commencera comme si elle était mardi dernier, et rien d'autre. Autrement dit, le lancement ou le redémarrage d'une tâche pour une date antérieure ne doit en aucun cas dépendre du moment où cette tâche est réellement lancée. L'idempotence est implémentée à l'aide de la variable execution_date susmentionnée.
Airflow a été développé comme un outil pour résoudre les tâches de traitement de données. Dans ce monde, nous traitons généralement une grande quantité de données uniquement lorsqu'elles sont prêtes, c'est-à-dire le lendemain. Et les créateurs d'Airflow ont à l'origine présenté un tel concept dans leurs produits.
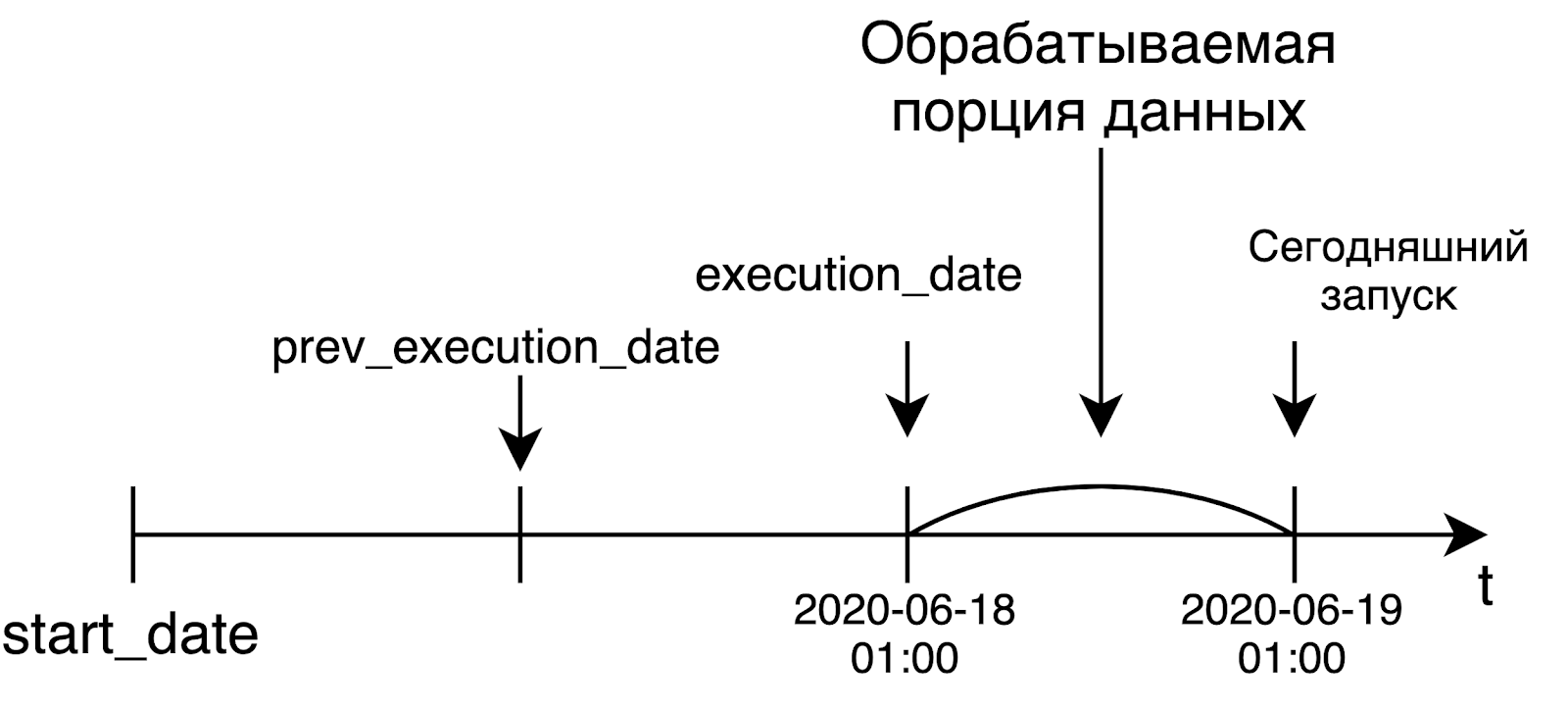
Lorsque nous lançons un pipeline quotidien, nous voudrons probablement traiter les données d'hier. C'est pourquoi execution_date sera égal à la bordure gauche de l'intervalle pour lequel nous traitons les données. Par exemple, le lancement d'aujourd'hui, qui a débuté à 1 h UTC, recevra la date d'hier sous la forme execution_date. Dans le cas d'un pipeline horaire, la situation est la même: pour démarrer le pipeline à 6 heures du matin, l'heure en execution_date sera égale à 5 heures du matin. Cette idée n'est pas très évidente au début, mais néanmoins, elle est très significative et importante.
Opérateurs Airflow les plus courants
Dans Airflow, il n'y a pas que des opérateurs qui vont à Hive et envoient quelque chose à slack. En fait, il y a des tonnes d'opérateurs là-bas. Dans l'article, j'ai fait ressortir les plus populaires et les plus utiles.
- BashOpetator et PythonOperator. Tout est clair avec eux: ils envoient respectivement une commande bash et une fonction python pour exécution.
- Il existe une grande variété d'opérateurs pour envoyer des requêtes à diverses bases de données. Postgres standard, MySQL, Oracle, Hive, Presto sont pris en charge. Si pour une raison quelconque il n'y a pas d'opérateur pour votre base de données préférée, vous pouvez utiliser un JdbcOperator plus général ou écrire le vôtre, Airflow le permet.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

En outre, vous pouvez voir comment la durée des tâches a changé au cours de la journée. Dans notre cas, il s'agit du processus de transfert de données de Kafka vers Hive avec vérification de la qualité des données. De plus, vous pouvez suivre le moment où la tâche a pris plus de temps que d'habitude pour une raison quelconque.

Comment réussir le développement du flux d'air
Voici quelques conseils pour vous aider à éviter de vous faire tirer dessus lors de l'utilisation d'Airflow:
- Il est utile de conserver chaque pipeline (ou générateur de pipeline, plus d'informations ci-dessous) dans un fichier séparé. Je sais immédiatement dans quel fichier je dois aller pour voir le pipeline ou le générateur requis.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Depuis le début de l'utilisation d'Airflow, nous avons séparé les configurations du pipeline du code. Au départ, cela était dû aux particularités du schéma de déploiement, mais progressivement cette approche a pris racine. Et maintenant, nous utilisons des configurations partout où il y a un soupçon de passe-partout. Surtout pour nous, cela concerne les jobs Spark que nous exécutons depuis Docker. De là est née l'histoire avec l'écriture déclarative des pipelines.
L'approche est que nous avons un répertoire avec des configs. Chaque fichier de configuration contient un ou plusieurs pipelines avec leur description: comment ils doivent fonctionner, quand commencer, quelles tâches y sont et dans quel ordre ils doivent être exécutés.
Je vais montrer à quoi ressemble le code pour appeler notre générateur de pipeline. A l'entrée, il reçoit un répertoire avec des configs, un préfixe et une classe qui se chargera de remplir le pipeline de tâches. Sous le capot, le générateur va dans le répertoire spécifié, y trouve les fichiers de configuration, crée des tâches dans ces fichiers pour chaque pipeline et les lie.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
Voici à quoi ressemble un fichier de configuration typique. Pour décrire les configurations, nous utilisons le format HOCON , qui est un sur-ensemble de JSON. Il prend en charge les importations d'autres fichiers HOCON et peut faire référence aux valeurs d'autres variables.
Dans la configuration au niveau du pipeline (bloc d'attribution), vous pouvez spécifier de nombreux paramètres, mais les plus importants sont name, start_date et schedule_interval.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Ici, vous pouvez spécifier la concurrence - combien de tâches seront exécutées simultanément en une seule exécution. Récemment, nous avons ajouté un bloc avec une brève description de démarque du pipeline ici. Ensuite, il ira avec le reste des informations sur le pipeline à Confluence (nous avons implémenté l'envoi en utilisant Foliant ). Cela s'est avéré super pratique: de cette façon, nous gagnons du temps pour les développeurs creusés pour créer des pages dans Confluence.
Vient ensuite la partie responsable de la formation des tâches. Tout d'abord, dans le bloc de connexions, nous indiquons à partir de quelle connexion dans Airflow nous devons prendre les paramètres de connexion à une source externe - dans l'exemple, il s'agit de notre DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Toutes les informations nécessaires telles que l'utilisateur, le mot de passe, l'URL, etc. seront transmises au conteneur Docker en tant que variables d'environnement. Dans le bloc Conteneurs, nous indiquons les tâches que nous allons lancer. À l'intérieur se trouvent le nom de l'image, une liste des connexions utilisées et une liste des variables d'environnement.
Vous remarquerez peut-être que les modèles Jinja apparaissent dans les valeurs de certaines variables d'environnement. Pour spécifier une file d'attente dans YARN, nous utilisons la syntaxe standard Airflow pour récupérer les valeurs des variables. Pour indiquer la date de lancement, nous utilisons la macro {{ds_nodash}}, qui représente la date de leur execution_date sans tirets. La configuration contient 3 autres tâches similaires, elles sont masquées pour plus de clarté.
Ensuite, à l'aide de tâches, nous indiquons comment ces tâches seront lancées. Vous remarquerez qu'ils sont répertoriés sous forme de liste dans une liste. Cela signifie que les 4 de ces tâches s'exécuteront en parallèle les unes avec les autres.
Et une dernière chose: nous spécifions de quels pipelines de base dépend notre DAG actuel. Des chiffres et des lettres étranges à la fin des noms des points de base sont le calendrier que nous intégrons dans le nom du pipeline. Ainsi, notre pipeline ne commencera à se remplir qu'une fois que les points de base et les tâches qui y sont spécifiées seront terminés.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Texte complet du fichier de configuration
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
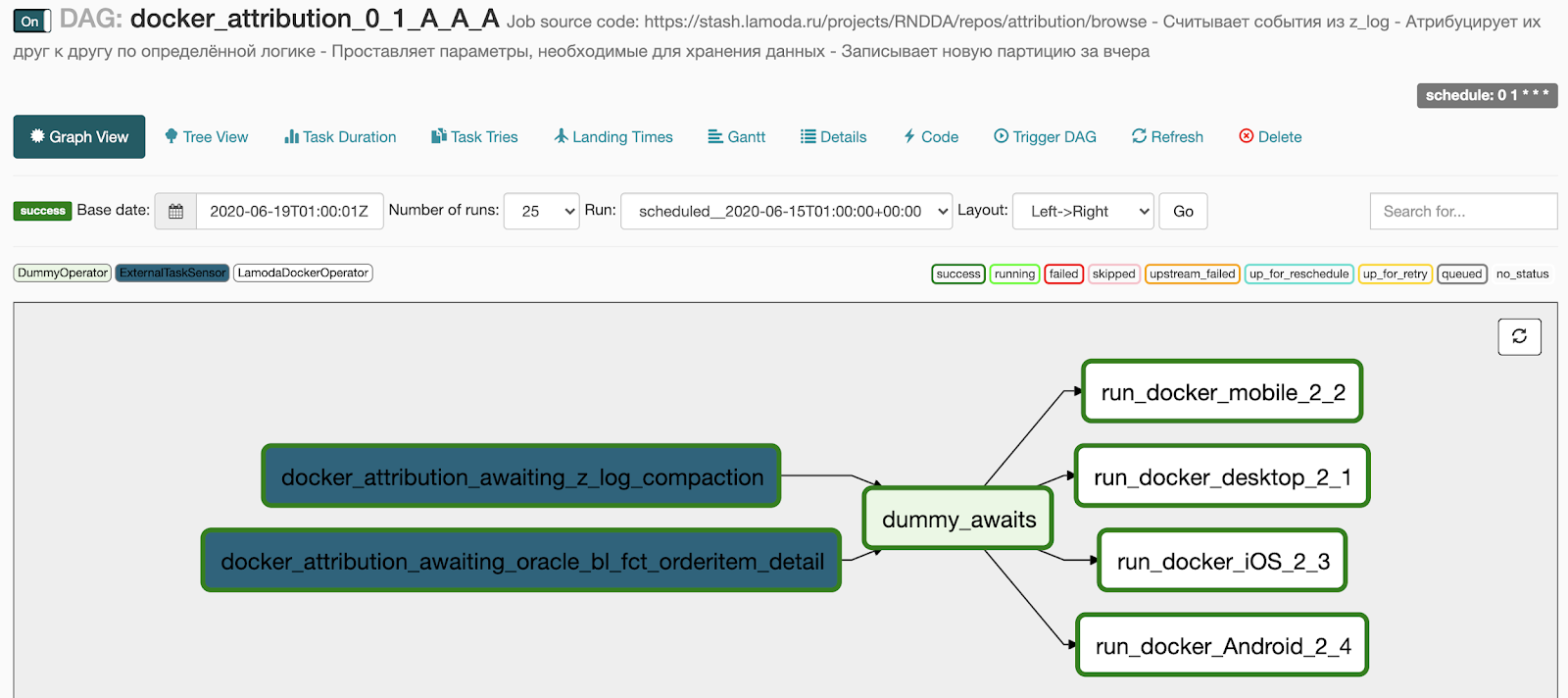
Voici ce que nous obtenons après génération:
- 2 points dans le bloc d'attente transformés en deux capteurs qui attendent l'exécution du pipeline de base,
- Les 4 tâches que nous avons spécifiées dans le bloc docker se sont transformées en 4 tâches en cours d'exécution en parallèle,
- nous avons ajouté un DummyOperator entre les deux blocs d'opérateurs afin qu'il n'y ait pas de réseau de connexions entre les tâches.
Que voulons-nous faire ensuite
Tout d'abord, créez un environnement de fonctionnalités complet. Nous avons maintenant un stand de développement pour tester tous nos pipelines. Et avant de tester, vous devez vous assurer que le paysage de développement est maintenant libre.
Récemment, notre équipe s'est agrandie et le nombre de candidats a augmenté. Nous avons trouvé une solution temporaire au problème et maintenant nous le faisons savoir dans Slack quand nous prenons dev. Cela fonctionne, mais c'est toujours un goulot d'étranglement dans le développement et les tests.
Une option consiste à passer à Kubernetes. Par exemple, lors de la création d'une demande d'extraction dans master, vous pouvez créer un espace de noms distinct dans Kubernetes, où déployer Airflow, déployer du code, puis disperser des variables, des connexions. Après le déploiement, le développeur viendra sur l'instance Airflow nouvellement créée et testera ses pipelines. Nous avons quelques bases sur ce sujet, mais nos mains ne sont pas arrivées au cluster de combat Kubernetes, où nous pourrions tout exécuter.
La deuxième option pour implémenter l'environnement Feature consiste à organiser un référentiel avec une branche de développement commune, où le code des développeurs est fusionné et automatiquement déployé dans le paysage de développement. Maintenant, nous recherchons activement ce schéma.
Nous voulons également essayer d'implémenter des plugins - des choses pour étendre les fonctionnalités de l'interface Web. L'objectif principal de la mise en œuvre des plugins est de créer un diagramme de Gantt au niveau de l'ensemble du flux d'air, c'est-à-dire au niveau de tous les pipelines, ainsi que de créer un graphique de dépendance entre différents pipelines.
Pourquoi nous avons choisi Airflow
- Tout d'abord, il s'agit de Python, où, à l'aide de deux boucles et de quelques conditions, vous pouvez créer un pipeline élégant et fonctionnant correctement. Et il n'aura pas besoin d'être décrit dans un énorme morceau de XML. De plus, presque tout l'écosystème Python et tout son zoo de bibliothèques sont disponibles prêts à l'emploi et peuvent être utilisés à votre guise.
- L'absence de XML simplifie grandement la révision du code. Nous avons écrit le code et les configurations du pipeline, et tout est parfait, tout fonctionne. En fait, vous pouvez faire glisser en XML ou tout autre format de configuration, mais c'est déjà une question de goût.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.