- Je vais commencer par d'où viennent les cinémas en ligne.

Au cours du développement d'Internet, des services de médias OTT sont apparus, qui ont commencé à être utilisés pour transférer du contenu multimédia sur Internet, contrairement aux services de médias traditionnels, où le câble, le satellite et d'autres canaux de communication étaient utilisés.
Ces services multimédias sont basés sur OVP - une plate-forme vidéo en ligne, qui comprend un système de gestion de contenu, un lecteur Web et un CDN. Une classe distincte de ces systèmes est OTT-TV, un cinéma en ligne qui, en plus d'OVP, met en œuvre des systèmes de contrôle et de gestion pour l'accès au contenu, un système de protection des droits du contenu numérique, la gestion des abonnements, des achats et diverses mesures techniques et de produits. Et cela impose à ces systèmes des exigences accrues en termes de disponibilité et de latence.
Je parlerai du backend, qui est responsable du système de gestion de contenu, de la fonctionnalité utilisateur du cinéma en ligne et de la partie du système de gestion et de contrôle de contenu.
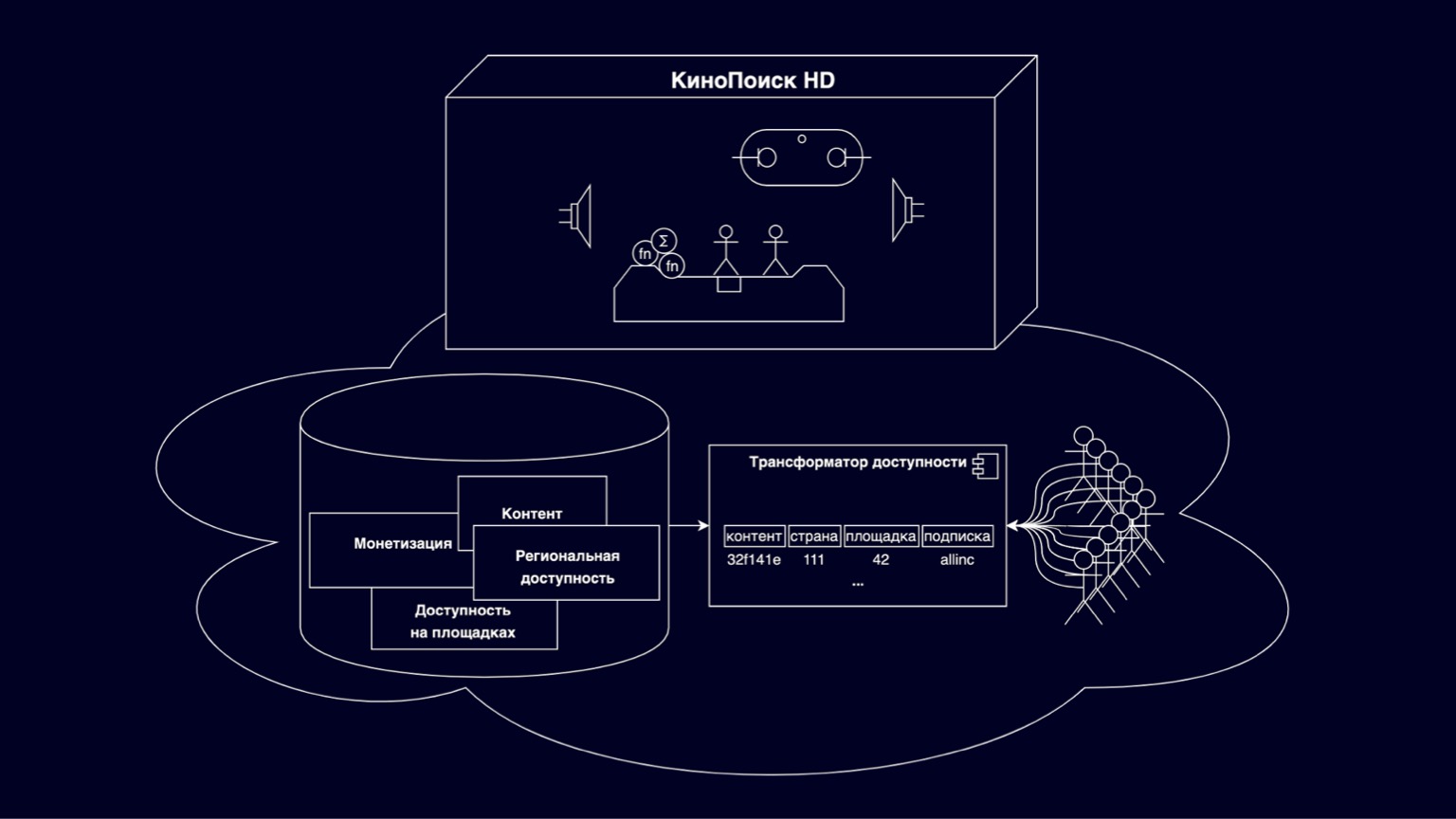
Voyons de quoi sont faits les cinémas en ligne. Dans la boîte KinoPoisk HD, toutes sortes de choses intéressantes et de modes de visualisation sont implémentés. Des milliers d'utilisateurs RPS sélectionnent le contenu disponible dans les vitrines, s'abonnent et achètent. Enregistrer la progression de la navigation, les paramètres utilisateur. Des milliers de RPS génèrent diverses métriques. Il s'agit d'un ensemble de composants assez vaste et intéressant, dont nous n'entrerons pas dans les détails aujourd'hui. Mais il convient de mentionner que, en général, ce sont de bons services et naturellement évolutifs - en raison du fait qu'ils sont partagés par les utilisateurs.
Aujourd'hui, nous allons nous concentrer sur le cloud sous la boîte. Il s'agit d'une plate-forme chargée de stocker des films, des séries, diverses restrictions des titulaires de droits d'auteur. Soutenu par les efforts de plusieurs départements. Une partie de cette plate-forme est un transformateur d'accessibilité qui répond aux questions que je peux regarder dès maintenant à cet endroit. Sans un transformateur d'accessibilité, aucun contenu n'apparaîtra littéralement sur KinoPoisk HD.
Le défi pour le transformateur est de traduire un modèle d'accessibilité flexible et en couches en un modèle efficace qui s'adapte au plus grand nombre de consommateurs de contenu possible.
Pourquoi est-il flexible et évolutif? Principalement parce qu'il inclut diverses entités qui décrivent le contenu, la monétisation, la disponibilité relationnelle et la disponibilité sur les sites. Tout cela est dans les relations révolutionnaires, a une hiérarchie complexe. Et cette flexibilité est nécessaire pour répondre aux exigences de dizaines de titulaires de droits d'auteur et à diverses options de tarification flexibles.
Par sites, nous entendons par exemple un cinéma en ligne sur le Web, un cinéma en ligne sur des appareils et d'autres services OTT partenaires qui lisent également nos contenus.
Il est clair que pour calculer efficacement la disponibilité d'un tel modèle à plusieurs niveaux, vous devez créer des jointures complexes, et de telles requêtes ne s'adaptent à aucune charge, elles sont assez complexes dans l'interprétation pour créer rapidement et clairement certaines fonctionnalités. Pour résoudre ces problèmes, un transformateur d'accessibilité a émergé, dénormalisant le modèle présenté sur la diapositive comme une clé composite, qui comprend les identifiants de contenu, les pays, les sites, les abonnements et un résidu non clé invisible qui constitue la majeure partie de la mémoire. Aujourd'hui, nous parlerons des difficultés de mise à l'échelle du transformateur d'accessibilité.
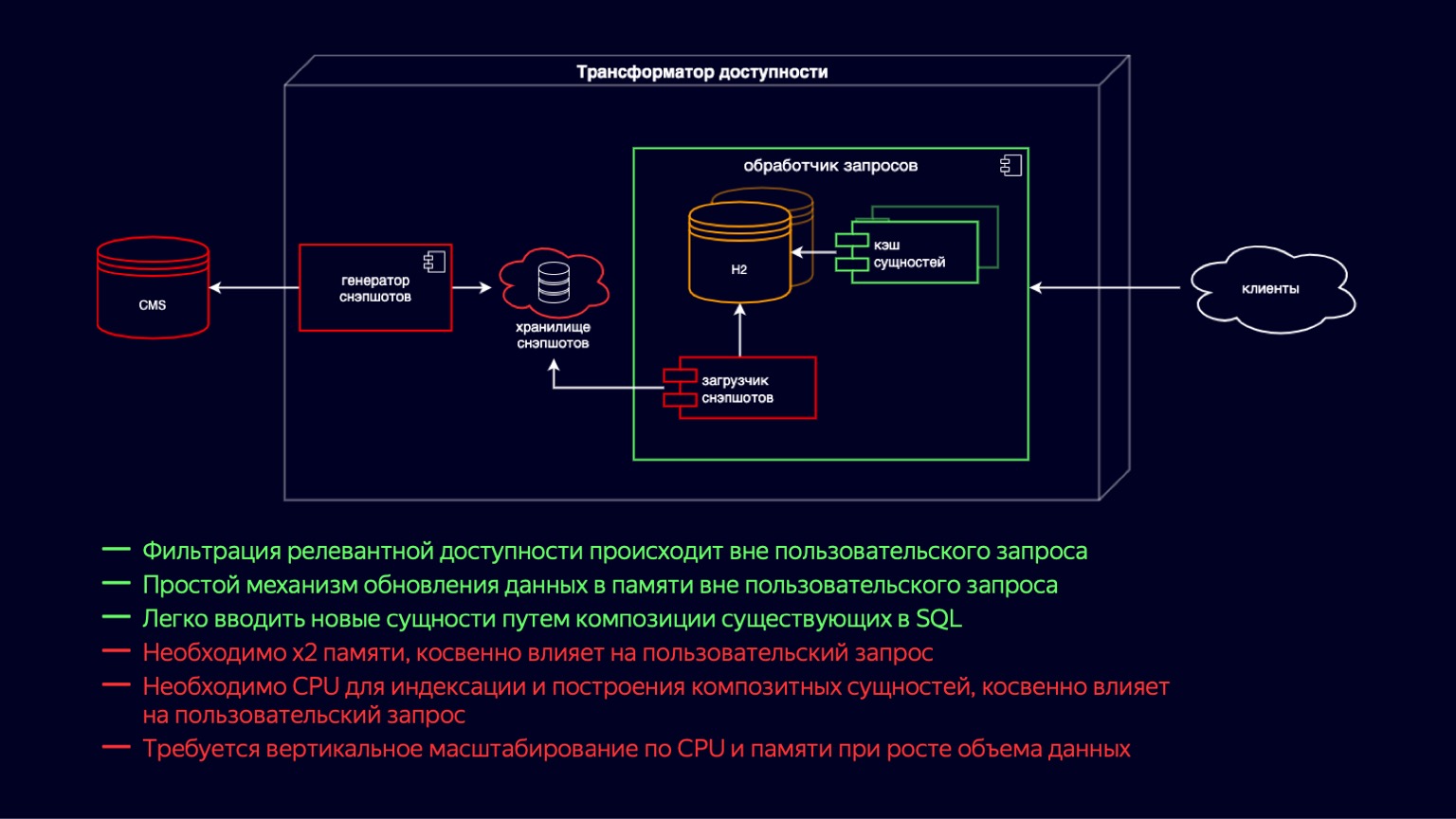
Plongeons plus profondément dans ce composant et voyons en quoi il consiste. Ici, nous voyons l'état du système juste avant le début du problème. Pendant tout ce temps, le transformateur d'accessibilité a suivi la voie du développement ultra-rapide du cinéma en ligne. Il était important de lancer rapidement de nouvelles fonctionnalités, tout d'abord pour assurer la disponibilité de dizaines de milliers de films et séries télévisées.
Si vous allez de gauche à droite, alors il y a un CMS, une base de données relationnelle dans laquelle sous la troisième forme normale et en EAVnos principales entités sont stockées. Vient ensuite le chargeur de snapshots. De plus, le générateur de snapshots, qui reçoit régulièrement les données pertinentes, les filtre, les ajoute au stockage des snapshots. Il s'agit en fait d'un vidage SQL. Plus loin dans l'instance du processeur de requêtes, le Snapshot Loader reçoit régulièrement de nouvelles données et les importe dans H2. H2 est une base de données en mémoire écrite en Java qui implémente les capacités de base d'un SGBD, c'est-à-dire qu'il existe un interpréteur de requêtes, un optimiseur de requêtes et des index.
En fait, c'est exactement le composant qui offre la flexibilité nécessaire pour créer de nouvelles fonctionnalités pour un cinéma en ligne, car vous pouvez simplement écrire des requêtes SQL et rejoindre des entités dénormalisées rapidement et facilement.
H2 est mis à jour sur un modèle de copie sur écriture. Snapshot Loader récupère une nouvelle instance de base de données et la remplit. Et puis, après le remplissage, il élimine l'ancien en utilisant le ramasse-miettes.
Simultanément avec H2, le cache d'entités est levé, qui comprend les entités composites et l'index au-dessus d'elles. Les entités composites sont essentiellement une continuation de la dénormalisation de ce qui se trouve dans H2 pour répondre aux demandes de latence plus exigeantes des clients. Les entités de cache sont mises à jour de la même manière selon le modèle de copie sur écriture, simultanément avec la génération de nouvelles instances H2.
Les principaux avantages du système: vous pouvez facilement et de manière flexible ajouter de nouvelles fonctionnalités à l'aide de jointures. Un schéma relativement simple pour mettre à jour les données par copie sur écriture. L'inconvénient est, bien sûr, que la mémoire x2 est nécessaire pour stocker et mettre à jour ces entités. Cela affecte indirectement la demande de l'utilisateur car elle est supprimée par le garbage collector.
De plus, lors de la création du cache d'entités, une ressource CPU est requise pour l'indexation. Et cela affecte également indirectement la demande de l'utilisateur, mais au détriment de la concurrence pour les ressources CPU. Ces deux points ensemble conduisent au fait qu'avec la croissance du volume de données de nos principales entités, le processeur de requêtes doit évoluer verticalement, à la fois en termes de CPU et de mémoire.
Mais le système reposait sur des dizaines de milliers de films et de séries télévisées disponibles en ligne. Ainsi, pendant longtemps, ces inconvénients étaient acceptables, ils permettaient d'exploiter le principal avantage en termes de flexibilité et de facilité d'introduction de nouvelles fonctions d'un cinéma en ligne.
Il est clair que tout cela a fonctionné jusqu'à un certain point. Imaginez que ce bus jaune soit notre transformateur d'accessibilité.

Il héberge des films et des séries reproduits par dénormalisation, c'est-à-dire qu'il y en a des dizaines de milliers. Et à l'un des arrêts, des centaines de milliers de vidéoclips et de bandes-annonces doivent être montés à bord et placés d'une manière ou d'une autre. Une fois à bord, ils vont également se multiplier en raison de la dénormalisation. Ceux qui sont à l'intérieur ont besoin de rétrécir, et ceux qui sont à l'extérieur ont besoin de sauter, de se faufiler. Vous pouvez imaginer comment cela se produit. Techniquement, à ce moment, notre capacité de mémoire sur l'instance est passée à des dizaines de gigaoctets. La création du cache et la suppression des anciennes instances à l'aide du ramasse-miettes ont nécessité plusieurs cœurs virtuels. Et comme la quantité de données a considérablement augmenté, toute cette procédure a conduit au fait qu'il faut des dizaines de minutes pour publier un nouveau contenu.
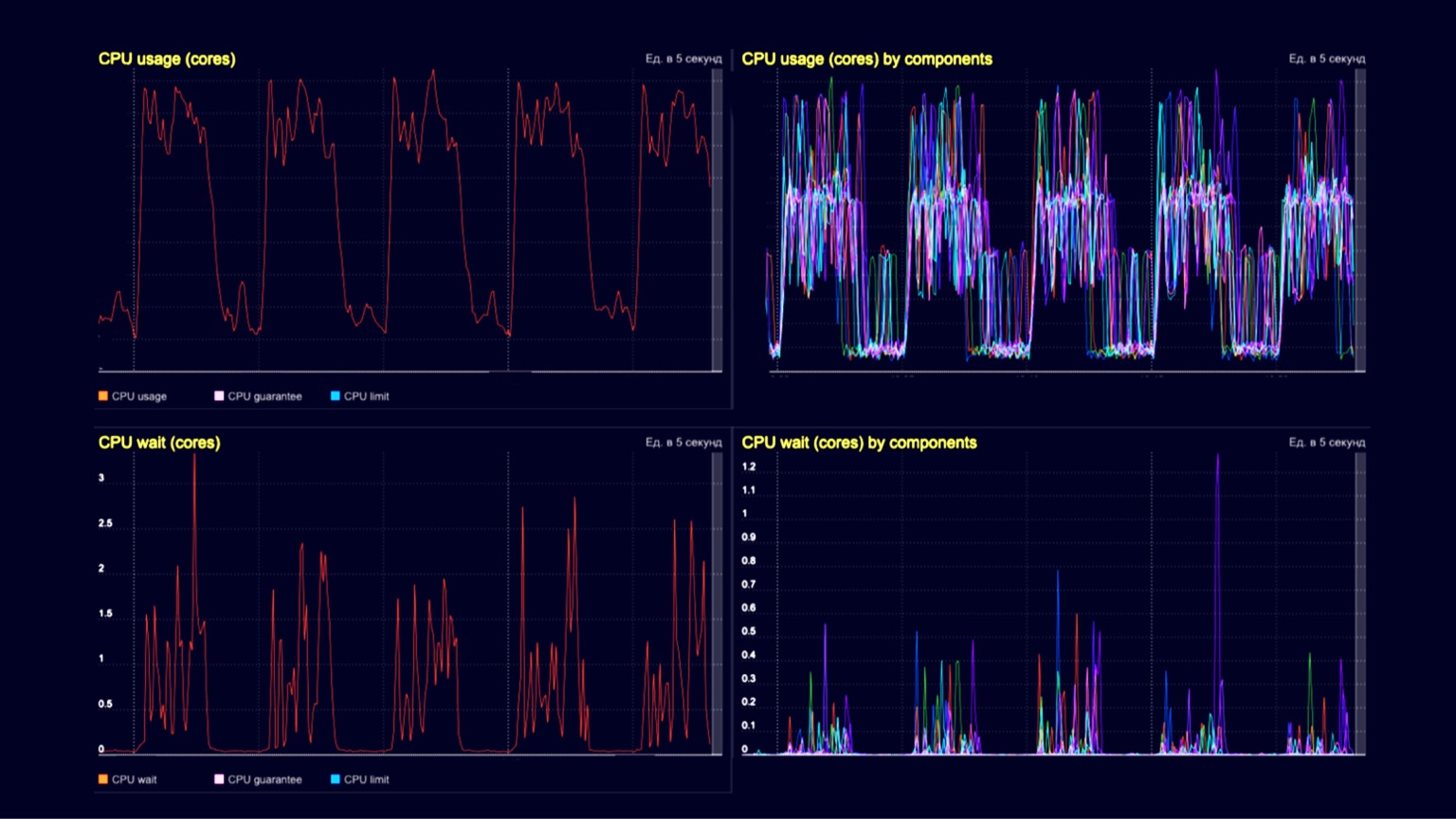
Techniquement, nous constatons une utilisation du processeur ici sur un cluster de processeurs de requêtes. Dans les dépressions - traitement des demandes des clients de l'ordre de plusieurs milliers de RPS, et dans les collines - les mêmes plusieurs milliers de RPS, plus le même chargement d'instantanés et leur élimination à l'aide d'un ramasse-miettes. Les deux graphiques du bas représentent l'attente du processeur sur le conteneur. Nous voyons qu'ils commencent également à se manifester au moment du téléchargement des instantanés et de leur élimination.
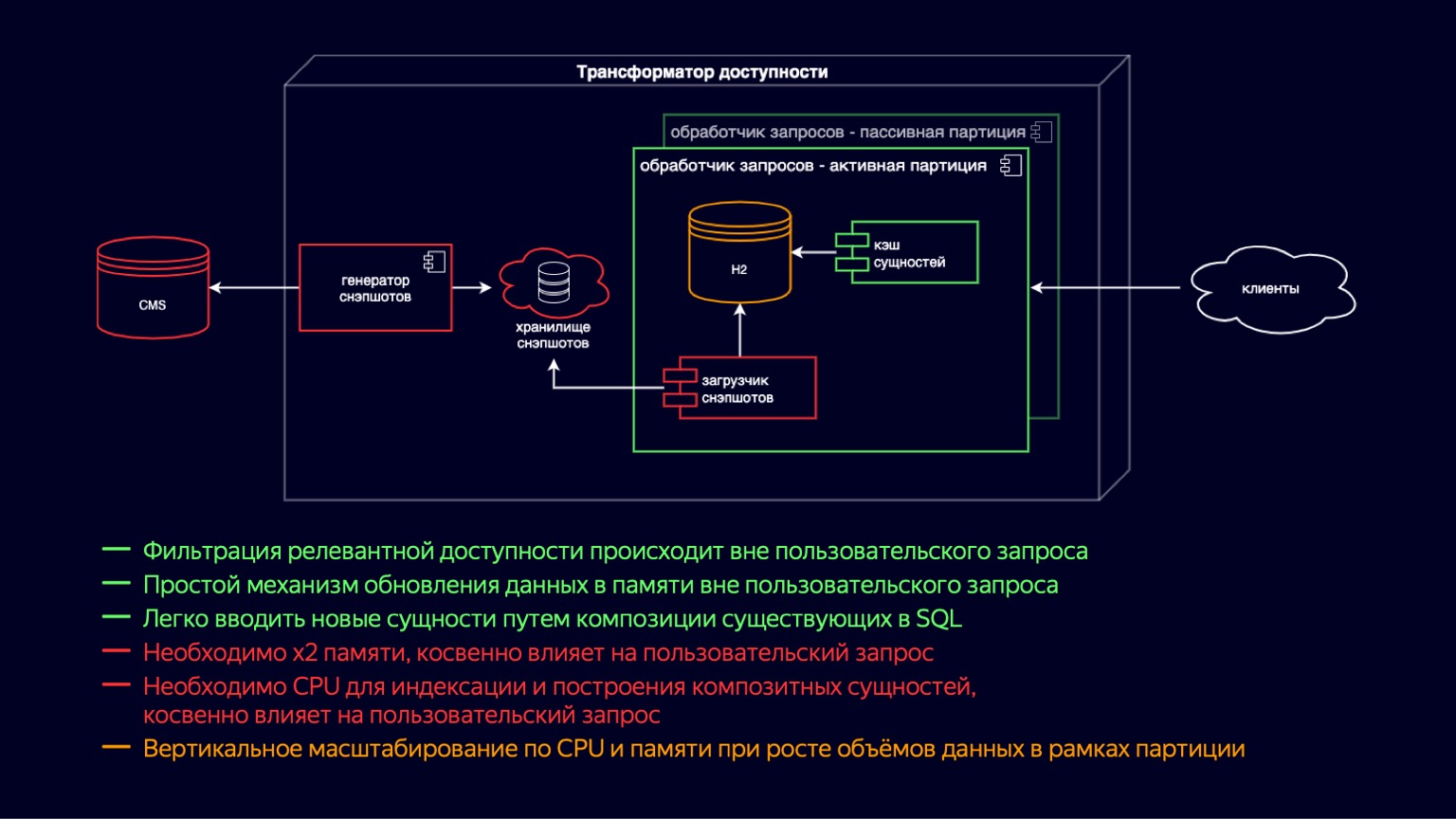
Pour accueillir ces vidéos musicales et bandes-annonces et continuer à évoluer, nous avons introduit des instances de processeur de requêtes actives et passives. En fait, il s'agit d'un transfert d'un niveau de copie sur écriture. Nous avons maintenant des instances actives et passives dans le conteneur. Le passif prépare le nouveau H2 et le cache d'entités, tandis que l'actif traite simplement les demandes des utilisateurs. Ainsi, nous avons réduit l'impact du garbage collection et de ses pauses sur le traitement des demandes des utilisateurs. Mais en même temps, comme ils vivent toujours dans le même conteneur, le chargement des instantanés et la création du cache sont toujours en concurrence pour les ressources du processeur, et l'impact sur les demandes des utilisateurs est toujours là.
Nous avons également introduit le partitionnement par site. Cela nous a permis de réduire la mémoire sur les sites où tous ces nouveaux types de contenu ne sont pas nécessaires. Par exemple, cela permettait à une salle de cinéma en ligne de ne pas télécharger de vidéoclips et de bandes-annonces et d'en réduire l'impact. Mais en même temps, pour les sites qui ont besoin de fournir tous les contenus avec accessibilité, bien sûr, rien n'a changé.
Par conséquent, les avantages et les inconvénients du système sont restés à peu près les mêmes qu'auparavant. Mais en raison du partitionnement, la mise à l'échelle verticale en termes de CPU et de mémoire a été déplacée vers les sites, ce qui a permis à certains sites de continuer à évoluer. Par rapport au schéma de publication de contenu précédent, cela n'a aucunement changé. Cela prenait généralement les mêmes dizaines de minutes, nous avons donc continué à chercher des moyens de l'optimiser.

Qu'avons-nous compris à ce moment-là? Ces requêtes de cinéma en ligne utilisent une petite partie des capacités du SGBD. L'interpréteur et l'optimiseur de requêtes ont dégénéré au fil du temps en un cache d'entités. Nous nous sommes rendu compte que la définition de l'accessibilité est largement universelle. Les requêtes diffèrent en ce que vous devez comprendre la disponibilité d'une unité de contenu ou d'une liste et ajouter des attributs supplémentaires à cette disponibilité. En général, cela peut être fait sans un SGBD à part entière.
Et deuxièmement, une partie de la clé composite est constituée par les paramètres cardinaux bas. Il existe des dizaines de pays, dans la limite de quelques centaines, des dizaines de sites et seulement quelques abonnements. Très probablement, une dénormalisation complète n'est pas requise. Ces deux résultats nous ont conduit à évoluer vers une représentation en mémoire plus compacte et moins dénormalisée, mais qui répond toujours rapidement aux demandes des utilisateurs.

Sur la diapositive, nous voyons la transition du transformateur de disponibilité v1 vers v2. Voici un schéma d'un nouveau schéma d'accessibilité, où la clé composite se résume en fait à être simplement une clé d'ID de contenu. Et l'accessibilité, physiquement ou logiquement, se résume à déterminer la disponibilité par des listes de pays, de sites et d'abonnements.
Ainsi, nous réduisons la quantité de reste invisible non clé, qui constitue la majeure partie de la mémoire, et réduisons la quantité de mémoire en même temps.
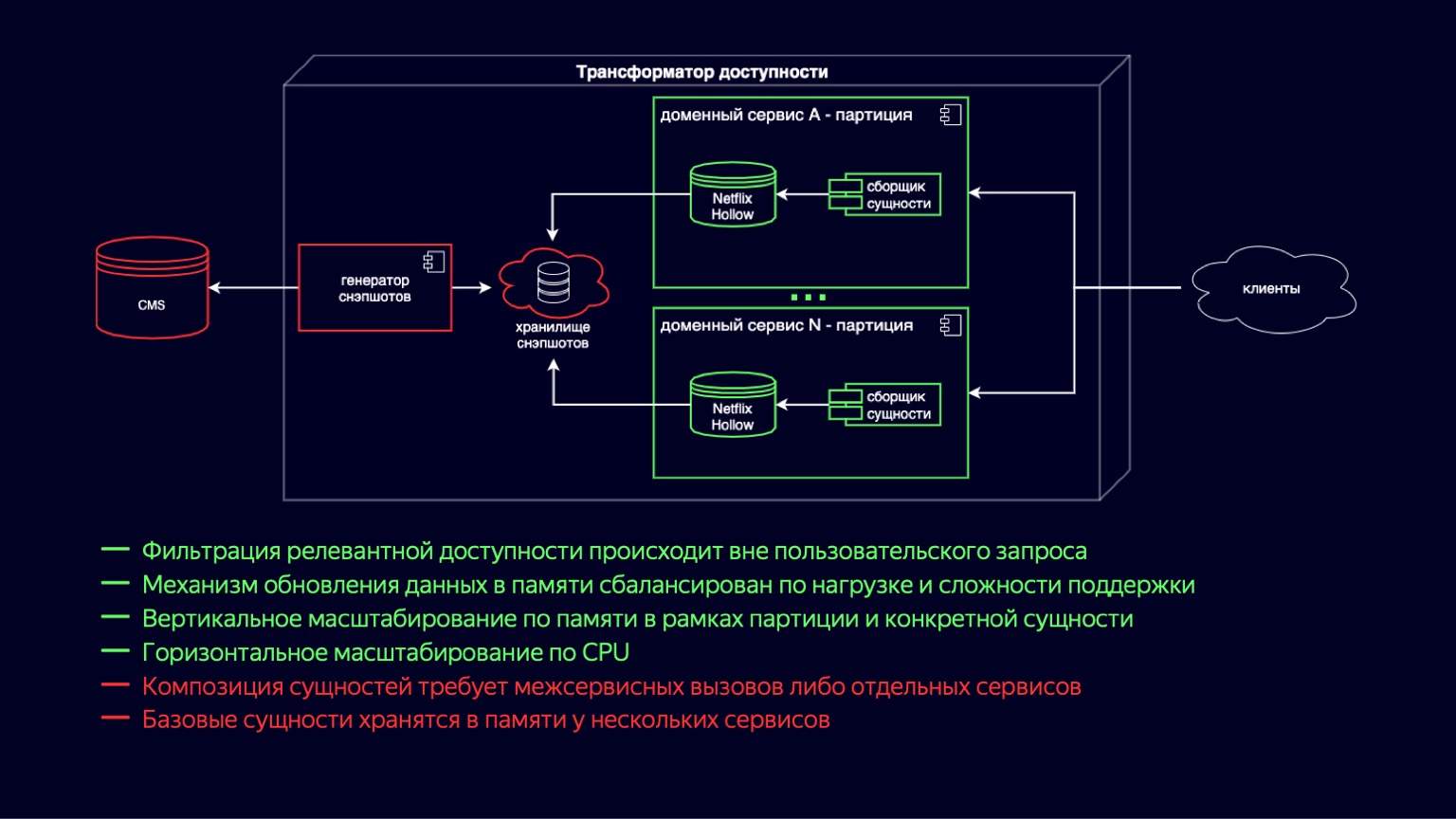
Nous voyons ici le processus de transition vers le nouveau circuit de transformateur d'accessibilité. Netflix Hollow joue le rôle de fournisseur et d'indexeur d'entités de base, sur lesquelles les services de domaine collectent à la volée un assemblage d'entités composites de différentes tailles. Cela fonctionne car les entités sous-jacentes sont toujours dénormalisées et le nombre de jointures est minimal lors de la construction. D'un autre côté, la détermination de la disponibilité se résume à des cycles simples et bon marché et ne devrait pas être difficile.
Dans le même temps, Netflix Hollow stocke et traite assez soigneusement la charge sur le processeur et le ramasse-miettes, à la fois pendant la mise à jour des données et pendant leur accès. Cela nous permet de réduire les collines que nous avons vues dans les graphiques d'utilisation du processeur et de les maintenir à un minimum acceptable. De plus, comme il implémente un schéma de livraison hybride sous la forme d'instantanés et de différences, il peut augmenter la vitesse de publication de nouveau contenu jusqu'à quelques minutes.
Il est clair que la plupart des avantages du système précédent ont été préservés. Le mécanisme de mise à jour des données en mémoire est devenu plus simple et moins coûteux en termes d'utilisation des ressources. La mise à l'échelle verticale par partitions, par sites a également été complétée par une mise à l'échelle pour une entité spécifique, elle est désormais moins chère. Et comme nous avons réduit la surcharge de mise à jour des instantanés, il y avait une mise à l'échelle vraiment horizontale sur le processeur.
L'inconvénient de ce schéma est que la composition de l'entité nécessite des appels interservices ou des services séparés. Et il y a toujours une duplication des données au niveau de l'entité de base, puisqu'elles sont maintenant stockées dans chaque service de domaine où elles sont utilisées. Mais Netflix Hollow stocke les données de manière plus compacte que H2, et H2 les stocke beaucoup plus de manière compacte que HashMap avec des objets. Donc, ce moins est certainement également considéré comme acceptable et vous permet d'envisager l'avenir avec optimisme.

Cette glissière est capable de charger même l'eau du robinet avec optimisme. Parce que la mise à l'échelle vers de nouveaux pays n'est plus un facteur multiplicateur de mémoire - pas plus que la mise à l'échelle vers de nouveaux sites. En raison du partitionnement, il est converti en mise à l'échelle horizontale.
Eh bien, faire évoluer les nouveaux utilisateurs et étendre les fonctionnalités d'un cinéma en ligne revient à une augmentation de la charge. Pour le fournir, nous sommes prêts à mettre en place autant de services légers liés au processeur que nécessaire. D'un autre côté, nous avons accumulé suffisamment de connaissances dans le domaine de l'accessibilité pour anticiper de nouveaux défis avec confiance. J'espère avoir pu partager certaines de ces connaissances avec vous. Merci de votre attention.