
Beaucoup de gens pensent qu'il suffit de porter l'application sur Kubernetes (soit en utilisant Helm soit manuellement) et il y aura du bonheur. Mais ce n'est pas si simple.
L'équipe de Mail.ru Cloud Solutions atraduit un article de Julian Guindi, ingénieur DevOps. Il parle des écueils auxquels son entreprise a été confrontée dans le processus de migration afin que vous ne marchiez pas sur le même râteau.
Première étape: configurer les demandes de pod et les limites
Commençons par configurer un environnement propre dans lequel nos pods fonctionneront. Kubernetes est idéal pour la planification des pods et la gestion des états d'échec. Mais il s'est avéré que le planificateur ne peut parfois pas placer un pod s'il est difficile d'estimer la quantité de ressources dont il a besoin pour fonctionner correctement. C'est là qu'interviennent les demandes de ressources et les limites. Il y a eu beaucoup de débats sur la meilleure approche pour fixer les demandes et les limites. Parfois, il semble que ce soit vraiment plus de l'art que de la science. Voici notre approche.
Les demandes de pod sont la valeur principale utilisée par le planificateur pour un placement optimal des pod.
Kubernetes: , . , PodFitsResources , .
Nous utilisons les demandes d'application afin de pouvoir estimer à partir d'elles le nombre de ressources dont l' application a réellement besoin pour un fonctionnement normal. Cela permettra au planificateur de placer les nœuds de manière réaliste. Au départ, nous voulions configurer des requêtes avec une marge pour nous assurer qu'il y avait suffisamment de ressources pour chaque pod, mais nous avons remarqué que le temps de planification augmentait considérablement et que certains pods n'étaient jamais entièrement planifiés, comme s'il n'y avait aucune demande de ressources pour eux.
Dans ce cas, l'ordonnanceur «pressait» souvent les pods et ne pouvait pas les replanifier car le plan de contrôle n'avait aucune idée de la quantité de ressources dont l'application aurait besoin, ce qui est un composant clé de l'algorithme d'ordonnancement.
Limites de podEst une limitation plus claire pour le pod. Il représente la quantité maximale de ressources que le cluster allouera au conteneur.
Encore une fois, à partir de la documentation officielle : si une limite de mémoire de 4 Gio est définie pour un conteneur, alors kubelet (et le runtime du conteneur) le forcera. Le runtime empêche le conteneur d'utiliser plus que la limite de ressources spécifiée. Par exemple, lorsqu'un processus dans un conteneur tente d'utiliser plus que la quantité de mémoire autorisée, le noyau quitte le processus avec une erreur "mémoire insuffisante" (MOO).
Un conteneur peut toujours utiliser plus de ressources que spécifié dans une demande de ressource, mais ne peut jamais en utiliser plus que spécifié dans une limite. Cette valeur est difficile à définir correctement, mais elle est très importante.
Dans l'idéal, nous voulons que les besoins en ressources du foyer changent tout au long du cycle de vie du processus sans interférer avec les autres processus du système - c'est l'objectif de fixer des limites.
Malheureusement, je ne peux pas donner d'instructions spécifiques sur les valeurs à définir, mais nous adhérons nous-mêmes aux règles suivantes:
- À l'aide d'un outil de test de charge, nous simulons le trafic de base et surveillons l'utilisation des ressources du pod (mémoire et processeur).
- ( 5 ) . , , Go.
Notez que des contraintes de ressources plus élevées rendent la planification plus difficile car le pod a besoin d'un nœud cible avec suffisamment de ressources disponibles.
Imaginez une situation où vous avez un serveur Web léger avec une contrainte de ressources très élevée comme 4 Go de mémoire. Ce processus devra probablement être mis à l'échelle horizontalement et chaque nouveau module devra être planifié sur un nœud avec au moins 4 Go de mémoire disponible. Si aucun nœud de ce type n'existe, le cluster doit introduire un nouveau nœud pour traiter ce pod, ce qui peut prendre un certain temps. Il est important de garder la différence entre les demandes de ressources et les limites aussi petite que possible pour assurer une mise à l'échelle rapide et fluide.
Deuxième étape: configurer les tests de vivacité et de préparation
C'est un autre sujet subtil qui est fréquemment discuté dans la communauté Kubernetes. Il est important d'avoir une bonne compréhension des tests de vivacité et de préparation car ils fournissent un mécanisme permettant au logiciel de fonctionner correctement et de minimiser les temps d'arrêt. Cependant, ils peuvent sérieusement affecter les performances de votre application s'ils ne sont pas configurés correctement. Vous trouverez ci-dessous un résumé de ce que sont les deux échantillons.
Liveness montre si le conteneur est en cours d'exécution. En cas d'échec, le kubelet tue le conteneur et une politique de redémarrage est activée pour lui. Si le conteneur n'est pas équipé d'une sonde Liveness, l'état par défaut sera réussi - comme indiqué dans la documentation Kubernetes .
Les sondes Liveness doivent être bon marché, c'est-à-dire ne pas consommer beaucoup de ressources, car elles s'exécutent fréquemment et doivent informer Kubernetes que l'application est en cours d'exécution.
Le paramétrer pour qu'il s'exécute toutes les secondes ajoutera 1 requête par seconde, sachez donc que des ressources supplémentaires seront nécessaires pour gérer ce trafic.
Dans notre entreprise, les tests de vie valident les principaux composants d'une application, même si les données (par exemple, d'une base de données distante ou d'un cache) ne sont pas entièrement disponibles.
Nous avons configuré un point de terminaison «santé» dans les applications qui renvoie simplement un code de réponse de 200. Cela indique que le processus est opérationnel et qu'il est capable de traiter les demandes (mais pas encore le trafic).
Test de préparationindique si le conteneur est prêt à traiter les demandes. Si la sonde de disponibilité échoue, le contrôleur de point de terminaison supprime l'adresse IP du pod des points de terminaison de tous les services correspondant au pod. Ceci est également indiqué dans la documentation de Kubernetes.
Les sondes de préparation consomment plus de ressources, car elles doivent aller au backend de manière à indiquer que l'application est prête à accepter les demandes.
Il y a beaucoup de controverse dans la communauté quant à savoir s'il faut accéder directement à la base de données. Compte tenu de la surcharge (les contrôles sont effectués fréquemment, mais peuvent être ajustés), nous avons décidé que pour certaines applications, la disponibilité à servir le trafic n'est comptabilisée qu'après vérification du retour des enregistrements depuis la base de données. Des sondes de disponibilité bien conçues garantissaient une plus grande disponibilité et éliminaient les temps d'arrêt pendant le déploiement.
Si vous décidez d'interroger la base de données pour vérifier que votre application est prête, assurez-vous qu'elle est aussi bon marché que possible. Prenons une requête comme celle-ci:
SELECT small_item FROM table LIMIT 1Voici un exemple de la façon dont nous configurons ces deux valeurs dans Kubernetes:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Certaines options de configuration supplémentaires peuvent être ajoutées:
initialDelaySeconds- combien de secondes s'écouleront entre le début du récipient et le début du début des échantillons.periodSeconds— .timeoutSeconds— , . -.failureThreshold— , .successThreshold— , ( , ).
:
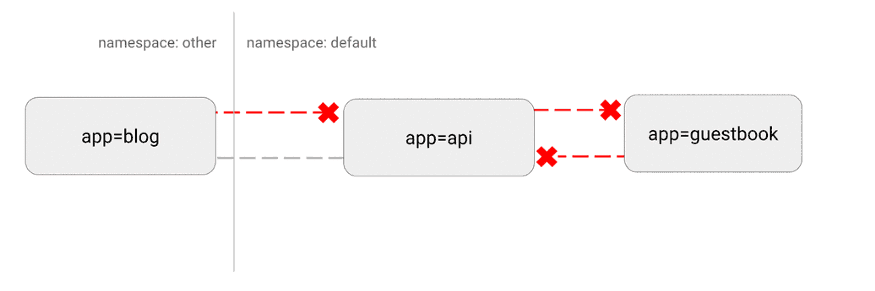
Kubernetes a une topographie de réseau "plate", par défaut, tous les pods interagissent directement les uns avec les autres. Dans certains cas, cela n'est pas souhaitable.
Un problème de sécurité potentiel est qu'un attaquant pourrait utiliser une seule application vulnérable pour envoyer du trafic à tous les pods du réseau. Comme dans de nombreux domaines de sécurité, le principe du moindre privilège s'applique. Idéalement, les stratégies réseau devraient indiquer explicitement les connexions entre les pods autorisées et celles qui ne le sont pas.
Par exemple, ce qui suit est une stratégie simple qui refuse tout le trafic entrant pour un espace de noms spécifique:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualisation de cette configuration:
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Plus de détails ici .
Étape 4: comportement personnalisé avec les hooks et les conteneurs init
L'un de nos principaux objectifs était de fournir des déploiements sur Kubernetes sans temps d'arrêt pour les développeurs. Ceci est difficile car il existe de nombreuses options pour arrêter les applications et libérer les ressources utilisées.
Des difficultés particulières sont survenues avec Nginx . Nous avons remarqué que lorsque ces pods étaient déployés séquentiellement, les connexions actives étaient abandonnées avant la réussite.
Après des recherches approfondies sur Internet, il s'est avéré que Kubernetes n'attend pas que les connexions Nginx s'épuisent avant d'arrêter le pod. À l'aide d'un hook pré-stop, nous avons implémenté la fonctionnalité suivante et nous avons complètement éliminé les temps d'arrêt:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
Et ici
nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Un autre paradigme extrêmement utile est l'utilisation de conteneurs init pour gérer le lancement d'applications spécifiques. Cela est particulièrement utile si vous disposez d'un processus de migration de base de données gourmand en ressources qui doit être démarré avant d'exécuter l'application. Vous pouvez également spécifier une limite de ressources plus élevée pour ce processus sans définir une telle limite pour l'application principale.
Un autre schéma courant consiste à accéder aux secrets dans le conteneur d'initialisation, qui fournit ces informations d'identification au module principal, ce qui empêche l'accès non autorisé aux secrets à partir du module d'application principal lui-même.
, : init- , . , .
:
Enfin, parlons d'une technique plus avancée.
Kubernetes est une plate-forme extrêmement flexible qui vous permet d'exécuter des charges de travail comme bon vous semble. Nous avons un certain nombre d'applications très efficaces et gourmandes en ressources. Grâce à des tests de charge approfondis, nous avons constaté que l'une des applications avait du mal à gérer la charge de trafic attendue lorsque les valeurs par défaut de Kubernetes sont en vigueur.
Cependant, Kubernetes vous permet d'exécuter un conteneur privilégié qui ne modifie les paramètres du noyau que pour un pod spécifique. Voici ce que nous avons utilisé pour modifier le nombre maximum de connexions ouvertes:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Il s'agit d'une technique plus avancée et souvent inutile. Mais si votre application a du mal à faire face à une charge importante, vous pouvez essayer d'ajuster certains de ces paramètres. Plus de détails sur ce processus et la définition de diverses valeurs - comme toujours dans la documentation officielle .
finalement
Bien que Kubernetes puisse sembler une solution prête à l'emploi, il existe plusieurs étapes clés à suivre pour que vos applications fonctionnent correctement.
Tout au long de votre migration vers Kubernetes, il est important de suivre un «cycle de test de charge»: exécutez l'application, testez-la sous charge, observez les métriques et le comportement de mise à l'échelle, ajustez la configuration en fonction de ces données, puis répétez le cycle.
Estimez de manière réaliste le trafic attendu et essayez d'aller au-delà pour voir quels composants cassent en premier. Avec cette approche itérative, seules quelques-unes de ces recommandations peuvent être suffisantes pour réussir. Ou, une personnalisation plus approfondie peut être nécessaire.
Posez-vous toujours ces questions:
- ?
- ? ? ?
- ? , ?
- ? ? ?
- ? - , ?
Kubernetes fournit une plate-forme incroyable qui permet aux meilleures pratiques de déployer des milliers de services sur un cluster. Cependant, toutes les applications sont différentes. Parfois, la mise en œuvre demande un peu plus de travail.
Heureusement, Kubernetes fournit la personnalisation nécessaire pour atteindre tous les objectifs techniques. En utilisant une combinaison de demandes et de limites de ressources, de sondes de vivacité et de préparation, de conteneurs d'initialisation, de stratégies réseau et de réglage personnalisé du noyau, vous pouvez obtenir des performances élevées avec une tolérance aux pannes et une évolutivité rapide.
Quoi d'autre à lire: