Aujourd'hui, nous allons écrire notre propre moteur FTS. À la fin de cet article, il pourra rechercher des millions de documents en moins d'une milliseconde. Nous allons commencer par des requêtes de recherche simples telles que «Renvoyer tous les documents avec cat», puis étendre le moteur pour prendre en charge des requêtes logiques plus complexes.
Remarque: Le moteur de recherche en texte intégral le plus connu est Lucene (ainsi qu'Elasticsearch et Solr construit dessus).
Pourquoi avez-vous besoin de FTS
Avant d'écrire un code, vous pourriez demander: "Ne pourriez-vous pas simplement utiliser grep ou une boucle qui vérifie chaque document pour le mot recherché?" Oui, vous pouvez. Mais ce n'est pas toujours la meilleure idée.
Logement
Nous rechercherons des fragments d'annotations sur Wikipédia en anglais. Le dernier vidage est disponible sur dumps.wikimedia.org . À partir d'aujourd'hui, la taille du fichier après le déballage est de 913 Mo. Le fichier XML contient plus de 600 000 documents.
Exemple de document:
<title>Wikipedia: Kit-Cat Klock</title>
<url>https://en.wikipedia.org/wiki/Kit-Cat_Klock</url>
<abstract>The Kit-Cat Klock is an art deco novelty wall clock shaped like a grinning cat with cartoon eyes that swivel in time with its pendulum tail.</abstract>Téléchargement de documents
Tout d'abord, vous devez charger tous les documents de la sauvegarde à l'aide d'un package intégré très pratique
encoding/xml:
import (
"encoding/xml"
"os"
)
type document struct {
Title string `xml:"title"`
URL string `xml:"url"`
Text string `xml:"abstract"`
ID int
}
func loadDocuments(path string) ([]document, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
defer f.Close()
dec := xml.NewDecoder(f)
dump := struct {
Documents []document `xml:"doc"`
}{}
if err := dec.Decode(&dump); err != nil {
return nil, err
}
docs := dump.Documents
for i := range docs {
docs[i].ID = i
}
return docs, nil
}Chaque document se voit attribuer un identifiant unique. Par souci de simplicité, le premier document chargé se voit attribuer ID = 0, le deuxième ID = 1, et ainsi de suite.
Premier essai
Recherche de contenu
Maintenant que nous avons tous les documents chargés en mémoire, essayons de trouver ceux qui mentionnent les chats. Tout d'abord, parcourons tous les documents et vérifions-les pour une sous-chaîne
cat:
func search(docs []document, term string) []document {
var r []document
for _, doc := range docs {
if strings.Contains(doc.Text, term) {
r = append(r, doc)
}
}
return r
}Sur mon ordinateur portable, la recherche prend 103 ms - pas trop mal. Si un endroit vérifier plusieurs documents de la question, nous pouvons voir que la fonction donne satisfaction sur le mot chenille et la catégorie , mais pas au chat avec une lettre majuscule C . Ce n'est pas exactement ce que nous recherchons.
Il y a deux choses à corriger avant de continuer:
- Rendez la recherche insensible à la casse (afin que la sortie inclue également Cat ).
- Considérez les limites des mots, pas les sous-chaînes (afin qu'il n'y ait pas de mots comme chenille et communication dans la sortie ).
Rechercher avec des expressions régulières
Une solution évidente qui résout ces deux problèmes est les expressions régulières .
Dans ce cas, nous avons besoin de
(?i)\bcat\b:
(?i)signifie que l'expression régulière est insensible à la casse
\bindique la correspondance avec les limites des mots (un endroit où il y a un caractère d'un côté et non de l'autre)
Mais maintenant, la recherche a pris plus de deux secondes. Comme vous pouvez le voir, le système a commencé à ralentir même sur un corps modeste de 600 000 documents. Bien que cette approche soit facile à mettre en œuvre, elle ne s'adapte pas très bien. Au fur et à mesure que l'ensemble de données se développe, de plus en plus de documents doivent être numérisés. La complexité temporelle de cet algorithme est linéaire, c'est-à-dire que le nombre de documents à numériser est égal au nombre total de documents. Si nous avions 6 millions de documents au lieu de 600 000, la recherche prendrait 20 secondes. Nous devrons trouver quelque chose de mieux.
Index inversé
Pour accélérer les requêtes de recherche, nous prétraiterons le texte et créerons un index.
Le cœur de FTS est une structure de données appelée index inversé . Il lie chaque mot à des documents contenant ce mot.
Exemple:
documents = {
1: "a donut on a glass plate",
2: "only the donut",
3: "listen to the drum machine",
}
index = {
"a": [1],
"donut": [1, 2],
"on": [1],
"glass": [1],
"plate": [1],
"only": [2],
"the": [2, 3],
"listen": [3],
"to": [3],
"drum": [3],
"machine": [3],
}Voici un exemple réel d'index inversé. Il s'agit d'un index dans un livre où le terme est suivi des numéros de page:

Analyse de texte
Avant de commencer à créer l'index, vous devez diviser le texte source en une liste de mots (jetons) adaptés à l'indexation et à la recherche.
L'analyseur de texte se compose d'un tokenizer et de plusieurs filtres.
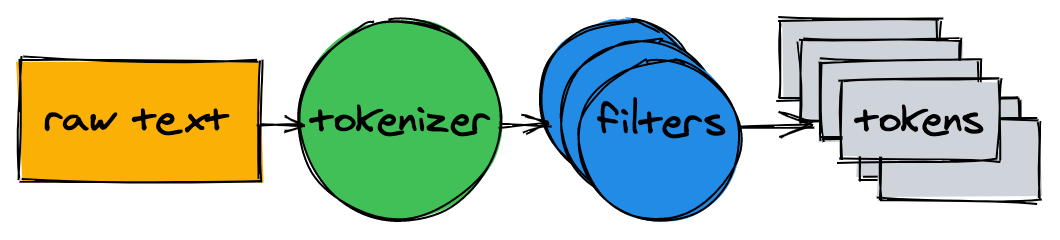
Tokenizer
Le tokenizer est la première étape de l'analyse de texte. Sa tâche est de convertir le texte en une liste de jetons. Notre implémentation divise le texte aux limites des mots et supprime les signes de ponctuation:
func tokenize(text string) []string {
return strings.FieldsFunc(text, func(r rune) bool {
// Split on any character that is not a letter or a number.
return !unicode.IsLetter(r) && !unicode.IsNumber(r)
})
}> tokenize("A donut on a glass plate. Only the donuts.")
["A", "donut", "on", "a", "glass", "plate", "Only", "the", "donuts"]Filtres
Dans la plupart des cas, il ne suffit pas de convertir du texte en une liste de jetons. Une normalisation supplémentaire sera nécessaire pour faciliter l'indexation et la recherche.
Minuscules
Pour rendre la recherche insensible à la casse, le filtre en minuscules convertit les jetons en minuscules. Les mots cAt , Cat et caT sont tous normalisés en cat . Plus tard, en faisant référence à l'index, nous normalisons également les requêtes de recherche en minuscules, de sorte que la requête de recherche cAt trouve le mot Cat .
Supprimer les mots courants
Presque tous les textes anglais contiennent des mots courants tels que a , I , The ou be . Ils sont appelés mots vides et sont présents dans presque tous les documents, ils doivent donc être supprimés.
Il n'y a pas de liste de mots vides «officielle». Éliminons le top 10 de la liste OEC . N'hésitez pas à le compléter:
var stopwords = map[string]struct{}{ // I wish Go had built-in sets.
"a": {}, "and": {}, "be": {}, "have": {}, "i": {},
"in": {}, "of": {}, "that": {}, "the": {}, "to": {},
}
func stopwordFilter(tokens []string) []string {
r := make([]string, 0, len(tokens))
for _, token := range tokens {
if _, ok := stopwords[token]; !ok {
r = append(r, token)
}
}
return r
}> stopwordFilter([]string{"a", "donut", "on", "a", "glass", "plate", "only", "the", "donuts"})
["donut", "on", "glass", "plate", "only", "donuts"]Tige
En raison des règles de grammaire, il existe différentes formes de mots dans les documents. La tige les réduit à la forme de base. Par exemple, la pêche , la pêche et le pêcheur se résument tous à la forme principale du poisson .
L'implémentation de la dérivation n'est pas une tâche triviale et n'est pas traitée dans cet article. Prenons l'un des modules existants :
import snowballeng "github.com/kljensen/snowball/english"
func stemmerFilter(tokens []string) []string {
r := make([]string, len(tokens))
for i, token := range tokens {
r[i] = snowballeng.Stem(token, false)
}
return r
}> stemmerFilter([]string{"donut", "on", "glass", "plate", "only", "donuts"})
["donut", "on", "glass", "plate", "only", "donut"]Remarque: les tiges ne fonctionnent pas toujours correctement. Par exemple, certains peuvent raccourcir la compagnie aérienne à lign .
Assemblage de l'analyseur
func analyze(text string) []string {
tokens := tokenize(text)
tokens = lowercaseFilter(tokens)
tokens = stopwordFilter(tokens)
tokens = stemmerFilter(tokens)
return tokens
}Le tokenizer et les filtres convertissent les phrases en une liste de jetons:
> analyze("A donut on a glass plate. Only the donuts.")
["donut", "on", "glass", "plate", "only", "donut"]Les jetons sont prêts pour l'indexation.
Construire un index
Revenons à l'index inversé. Il correspond à chaque mot avec les ID de document. Le type de données intégré fonctionne bien pour stocker une carte (affichage)
map. La clé sera un jeton (chaîne) et la valeur sera une liste d'identifiants de document:
type index map[string][]intLors de la construction de l'index, les documents sont analysés et leurs identifiants sont ajoutés à la carte:
func (idx index) add(docs []document) {
for _, doc := range docs {
for _, token := range analyze(doc.Text) {
ids := idx[token]
if ids != nil && ids[len(ids)-1] == doc.ID {
// Don't add same ID twice.
continue
}
idx[token] = append(ids, doc.ID)
}
}
}
func main() {
idx := make(index)
idx.add([]document{{ID: 1, Text: "A donut on a glass plate. Only the donuts."}})
idx.add([]document{{ID: 2, Text: "donut is a donut"}})
fmt.Println(idx)
}Tout fonctionne! Chaque jeton dans l'affichage fait référence aux ID des documents contenant ce jeton:
map[donut:[1 2] glass:[1] is:[2] on:[1] only:[1] plate:[1]]Demandes
Pour les requêtes sur l'index, nous appliquerons le même tokenizer et les mêmes filtres que nous avons utilisés pour l'indexation:
func (idx index) search(text string) [][]int {
var r [][]int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
r = append(r, ids)
}
}
return r
}> idx.search("Small wild cat")
[[24, 173, 303, ...], [98, 173, 765, ...], [[24, 51, 173, ...]]Et maintenant, enfin, nous pouvons trouver tous les documents qui mentionnent les chats. La recherche de 600 000 documents a pris moins d'une milliseconde (18 μs)!
Avec un index inversé, la complexité temporelle d'une requête de recherche est linéaire avec le nombre de jetons de recherche. Dans l'exemple de requête ci-dessus, en plus de l'analyse du texte d'entrée, seules trois recherches cartographiques sont effectuées.
Requêtes logiques
La demande précédente a renvoyé une liste de documents non liés pour chaque jeton. Mais nous nous attendons généralement à ce qu'une recherche de petit chat sauvage renvoie une liste de résultats contenant à la fois petit , sauvage et chat . L'étape suivante consiste à calculer l'intersection entre les listes. Ainsi, nous obtiendrons une liste de documents correspondant à tous les jetons.

Heureusement, les identifiants de notre index inversé sont insérés dans l'ordre croissant. Puisque les ID sont triés, vous pouvez calculer l'intersection entre les listes en temps linéaire. La fonction
intersectionparcourt deux listes en même temps et collecte les identifiants présents dans les deux:
func intersection(a []int, b []int) []int {
maxLen := len(a)
if len(b) > maxLen {
maxLen = len(b)
}
r := make([]int, 0, maxLen)
var i, j int
for i < len(a) && j < len(b) {
if a[i] < b[j] {
i++
} else if a[i] > b[j] {
j++
} else {
r = append(r, a[i])
i++
j++
}
}
return r
}La mise à jour
searchanalyse le texte de requête donné, recherche des jetons et calcule l'intersection donnée entre les listes d'ID:
func (idx index) search(text string) []int {
var r []int
for _, token := range analyze(text) {
if ids, ok := idx[token]; ok {
if r == nil {
r = ids
} else {
r = intersection(r, ids)
}
} else {
// Token doesn't exist.
return nil
}
}
return r
}Le vidage de Wikipédia ne contient que deux documents contenant simultanément les mots small , wild et cat :
> idx.search("Small wild cat")
130764 The wildcat is a species complex comprising two small wild cat species, the European wildcat (Felis silvestris) and the African wildcat (F. lybica).
131692 Catopuma is a genus containing two Asian small wild cat species, the Asian golden cat (C. temminckii) and the bay cat.La recherche fonctionne comme prévu!
Au fait, j'ai découvert les catopums pour la première fois , en voici un:

conclusions
Nous avons donc créé un moteur de recherche en texte intégral. Malgré sa simplicité, il peut fournir une base solide pour des projets plus avancés.
Je n'ai pas mentionné de nombreux aspects qui peuvent améliorer considérablement les performances et rendre la recherche plus pratique. Voici quelques idées d'améliorations supplémentaires:
- Ajoutez les opérateurs logiques OU et NON .
- Stocker l'index sur le disque:
- La restauration de l'index prend un certain temps à chaque redémarrage de l'application.
- Les index volumineux peuvent ne pas tenir en mémoire.
- La restauration de l'index prend un certain temps à chaque redémarrage de l'application.
- Expérimentez avec la mémoire et les formats de données optimisés pour le processeur pour stocker des ensembles d'identifiants. Jetez un œil à Roaring Bitmaps .
- Indexation de plusieurs champs du document.
- Triez les résultats par pertinence.
Tout le code source est publié sur GitHub .