
salut!
Je m'appelle Nikita et je supervise le développement de plusieurs projets chez DomClick. Aujourd'hui, je veux continuer le thème des "images drôles" dans le monde de RabbitMQ. Dans son article, Alexey Kazakov considérait un outil aussi puissant que les files d'attente différées et différentes implémentations de la stratégie Retry. Aujourd'hui, nous allons parler de la manière d'utiliser RabbitMQ pour planifier des tâches périodiques.
Pourquoi avons-nous besoin de créer notre propre vélo et pourquoi avons-nous abandonné Celery et d'autres outils de gestion des tâches? Le fait est qu'ils ne correspondaient pas à nos tâches et exigences de tolérance aux pannes, qui sont assez strictes dans notre entreprise.
Lors du passage à Docker et Kubernetes, de nombreux développeurs sont confrontés aux problèmes d'organisation des tâches périodiques, les couronnes sont lancées avec un tambourin et le contrôle du processus laisse beaucoup à désirer. Et puis il y a des problèmes avec les pics de charge pendant la journée.
Ma tâche était de mettre en œuvre dans le projet un système fiable de traitement des tâches périodiques, tout en étant facilement évolutif et tolérant aux pannes. Notre projet est en Python, il était donc logique de voir à quel point Celery nous convient. C'est un bon outil, mais avec lui, nous avons souvent rencontré des problèmes de fiabilité, d'évolutivité et de version transparente. Un pod - un groupe de processus. Lors de la mise à l'échelle de Celery, vous devez augmenter les ressources d'un pod, car il n'y a pas de synchronisation entre les pods, ce qui signifie l'arrêt du traitement des tâches, bien que temporairement. Et si les tâches sont également à long terme, alors vous avez déjà deviné à quel point c'est difficile à gérer. Le deuxième inconvénient évident: hors de la boîte, il n'y a pas de support pour l'asynchronie, et pour nous c'est important, car les tâches contiennent principalement des opérations d'E / S, et Celery fonctionne sur des threads.
À cette époque (2018), nous n'avons pas trouvé d'outil prêt à l'emploi approprié et avons commencé à développer le nôtre. En prenant comme base la fonctionnalité d'exécution différée des tâches et l'échange de lettres mortes, nous avons décidé de créer un système de traitement des tâches périodiques. Le concept ressemblait à ceci:
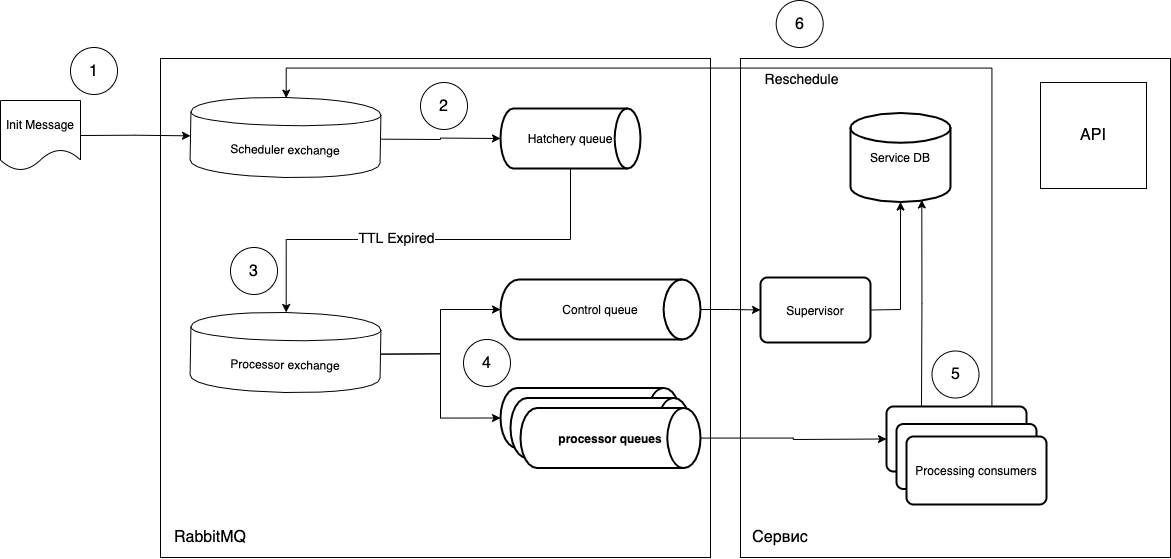
je vais essayer d'expliquer quoi.
- Les tâches sont envoyées sous la forme d'un message à l'échange Scheduler.
- Le
routing_keylogiciel entre dans la file d'attente requise de l'écloserie, qui a un paramètremessage_ttl, ainsi que la connexion avec l'échange de processeur en tant qu'échange de lettre d'opération. La file d'attente "maturation" n'est pas associée au type de tâches, elle ne joue que le rôle de "timer", c'est-à-dire que vous pouvez créer autant de files d'attente que vous avez besoin de périodes et gérerrouting_key. - Étant donné que la file d'attente n'a pas d'écouteurs, les messages, après avoir «mûri» dans la file d'attente, vont à l'échange du processeur.
- Ensuite, le consommateur gratuit (consommateur de traitement) prend le message et l'exécute. Après exécution, le cycle est répété si nécessaire.
Quel est l'avantage d'un tel système?
- L'exécution par phases, c'est-à-dire qu'une nouvelle tâche ne sera pas traitée si la précédente n'est pas terminée.
- Un seul auditeur (consommateur), c'est-à-dire que vous pouvez créer à la fois des travailleurs universels et des travailleurs spécialisés. Mise à l'échelle en augmentant simplement le nombre de pods nécessaires.
- Déployez de nouvelles tâches sans perturber le travail des tâches actuelles. Il suffit de mettre à jour en douceur les pods d'écoute et d'envoyer le message approprié à la file d'attente. Autrement dit, vous pouvez générer des pods avec un nouveau code, qui traitera les nouveaux messages, et les processus actuels survivront dans les anciens pods. Cela nous donne une mise à jour transparente.
- Vous pouvez utiliser du code asynchrone et n'importe quelle infrastructure, tout en étant indépendant de la pile.
- Vous pouvez contrôler l'exécution des tâches au niveau natif
ack/rejectet également obtenir une file d'attente facultative supplémentaire (file d'attente de contrôle) qui peut suivre le cycle de vie des tâches.
Le circuit était en fait assez simple, nous avons rapidement créé un prototype fonctionnel. Et le code est magnifique. Il suffit de marquer la fonction de rappel avec un simple décorateur qui contrôle le cycle de vie du message.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Nous utilisons maintenant ce schéma pour n'effectuer que des tâches séquentielles périodiques, mais il peut également être utilisé lorsqu'il est important de commencer à exécuter une tâche à un moment précis, sans déplacer le temps vers l'exécution elle-même. Pour ce faire, replanifiez simplement la tâche une fois que le message atteint le superviseur.
Certes, cette approche entraîne des frais généraux supplémentaires. Vous devez comprendre qu'en cas d'erreur, le message retournera dans la file d'attente, un autre travailleur le récupérera et commencera immédiatement à l'exécuter. Par conséquent, vous devez séparer la gestion des erreurs en fonction du degré de criticité et réfléchir à l'avance à ce qu'il faut faire avec le message en cas de telle ou telle erreur.
Options possibles:
- L'erreur se corrigera d'elle-même (par exemple, il s'agit d'une erreur système): envoyer
noacket répéter la gestion des erreurs. - Erreur de logique métier: vous devez interrompre le cycle - envoyer
ack. - L'erreur du point 1 se répète trop souvent: nous empoisonnons
rejectet signalons les développeurs. Il y a des options ici. Vous pouvez créer une file d'attente de lettres de transaction pour les messages à déposer afin de renvoyer le message après l'analyse, ou vous pouvez utiliser la technique de nouvelle tentative (spécifiezmessage_ttl).
Exemple de décorateur:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Ce programme travaille avec nous depuis six mois, il est assez fiable et ne nécessite pratiquement aucune attention. Le plantage de l'application ne rompt pas le planificateur et ne retarde que légèrement l'exécution des tâches.
Il n'y a pas d'avantages sans inconvénients. Ce schéma présente également une vulnérabilité critique. Si quelque chose est arrivé à RabbitMQ et que les messages ont disparu, vous devez alors regarder manuellement ce qui a été perdu et redémarrer la boucle. Mais c'est une situation extrêmement improbable dans laquelle vous devrez penser à ce service en dernier :)
PS Si le sujet de la planification des tâches périodiques vous semble intéressant, alors dans le prochain article, je vous expliquerai plus en détail comment nous automatisons la création de files d'attente, ainsi que Supervisor.
Liens: