introduction
Cet article est une compilation d' un autre article . Dans ce document, j'ai l'intention de me concentrer sur les outils de travail avec le Big data axés sur l'analyse des données.
Donc, disons que vous avez accepté les données brutes, les avez traitées et qu'elles sont maintenant prêtes pour une utilisation ultérieure.
Il existe de nombreux outils utilisés pour manipuler les données, chacun ayant ses propres avantages et inconvénients. La plupart d'entre eux sont orientés OLAP, mais certains sont également optimisés OLTP. Certains d'entre eux utilisent des formats standards et se concentrent uniquement sur l'exécution des requêtes, d'autres utilisent leur propre format ou stockage pour transférer les données traitées vers la source afin d'améliorer les performances. Certains sont optimisés pour stocker des données à l'aide de certains schémas, tels que des étoiles ou des flocons de neige, mais d'autres sont plus flexibles. En résumé, nous avons les oppositions suivantes:
- Entrepôt de données et lac
- Hadoop vs stockage hors ligne
- OLAP contre OLTP
- Moteur de requête et mécanismes OLAP
Nous examinerons également les outils de traitement des données avec la possibilité d'exécuter des requêtes.
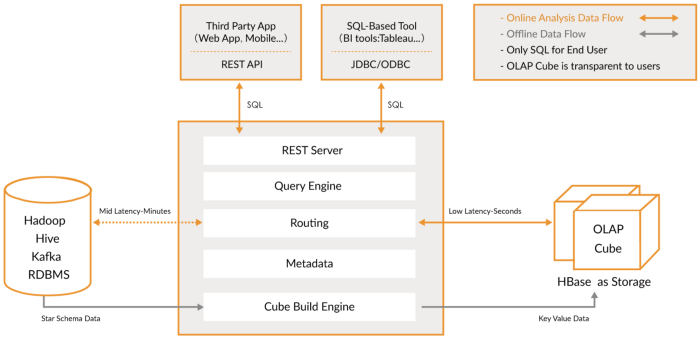
Outils de traitement de données
La plupart des outils mentionnés peuvent se connecter à un serveur de métadonnées comme Hive et exécuter des requêtes, créer des vues, etc. Ceci est souvent utilisé pour créer des niveaux de rapport supplémentaires (améliorés).
Spark SQL fournit un moyen de mélanger de manière transparente des requêtes SQL avec des programmes Spark, afin que vous puissiez mélanger l'API DataFrame avec SQL. Il dispose d'une intégration Hive et d'une connexion JDBC ou ODBC standard, ce qui vous permet de connecter Tableau, Looker ou tout autre outil de BI à vos données via Spark.

Apache Flinkfournit également l'API SQL. Le support SQL de Flink est basé sur Apache Calcite, qui implémente le standard SQL. Il s'intègre également à Hive via HiveCatalog. Par exemple, les utilisateurs peuvent stocker leurs tables Kafka ou ElasticSearch dans Hive Metastore à l'aide de HiveCatalog et les réutiliser ultérieurement dans les requêtes SQL.
Kafka fournit également des fonctionnalités SQL. En général, la plupart des outils de traitement de données fournissent des interfaces SQL.
Outils de requête
Ce type d'outil est axé sur une requête unifiée vers différentes sources de données dans différents formats. L'idée est d'acheminer les requêtes vers votre lac de données à l'aide de SQL comme s'il s'agissait d'une base de données relationnelle régulière, bien qu'elle présente certaines limitations. Certains de ces outils peuvent également interroger des bases de données NoSQL et bien plus encore. Ces outils fournissent une interface JDBC à des outils externes tels que Tableau ou Looker pour se connecter en toute sécurité à votre lac de données. Les outils de requête sont l'option la plus lente, mais offrent la plus grande flexibilité.
Apache Pig: l'un des premiers outils aux côtés de Hive. Possède son propre langage autre que SQL. Une caractéristique distinctive des programmes créés par Pig est que leur structure se prête à une parallélisation importante, qui, à son tour, leur permet de traiter de très grands ensembles de données. Pour cette raison, il n'est toujours pas obsolète par rapport aux systèmes SQL modernes.
Presto: Une plateforme open source de Facebook. Il s'agit d'un moteur de requête SQL distribué permettant d'effectuer des requêtes analytiques interactives sur des sources de données de toute taille. Presto vous permet d'interroger des données où qu'elles se trouvent, y compris Hive, Cassandra, des bases de données relationnelles et des systèmes de fichiers. Il peut interroger de grands ensembles de données en quelques secondes. Presto est indépendant de Hadoop, mais s'intègre à la plupart de ses outils, en particulier Hive, pour exécuter des requêtes SQL.
Forage Apache: Fournit un moteur de requête SQL sans schéma pour Hadoop, NoSQL et même le stockage dans le cloud. Cela ne dépend pas de Hadoop, mais il a de nombreuses intégrations avec des outils d'écosystème comme Hive. Une seule requête peut combiner les données de plusieurs stockages, en effectuant des optimisations spécifiques à chacun d'entre eux. C'est très bien car permet aux analystes de traiter toutes les données comme un tableau, même s'ils lisent réellement le fichier. Drill prend entièrement en charge le SQL standard. Les utilisateurs métier, les analystes et les data scientists peuvent utiliser des outils de Business Intelligence standard tels que Tableau, Qlik et Excel pour interagir avec des magasins de données non relationnelles à l'aide des pilotes Drill JDBC et ODBC. Outre,Les développeurs peuvent utiliser la simple exploration de l'API REST dans leurs applications personnalisées pour créer de superbes visualisations.
Bases de données OLTP
Bien que Hadoop soit optimisé pour OLAP, il existe toujours des situations dans lesquelles vous souhaitez exécuter des requêtes OLTP sur une application interactive.
HBase a des propriétés ACID très limitées de par sa conception car il a été conçu pour évoluer et ne fournit pas de capacités ACID prêtes à l'emploi, mais il peut être utilisé pour certains scénarios OLTP.
Apache Phoenix est construit sur HBase et fournit un moyen d'effectuer des requêtes OTLP dans l'écosystème Hadoop. Apache Phoenix est entièrement intégré à d'autres produits Hadoop tels que Spark, Hive, Pig, Flume et Map Reduce. Il peut également stocker des métadonnées, prendre en charge la création de tables et les modifications de version incrémentielles à l'aide de commandes DDL. Cela fonctionne assez rapidement, plus rapidement que d'utiliser Drill ou autre
mécanisme de requêtes.
Vous pouvez utiliser n'importe quelle base de données à grande échelle en dehors de l'écosystème Hadoop comme Cassandra, YugaByteDB, ScyllaDB pour OTLP.
Enfin, il est très courant que les bases de données rapides de tout type, telles que MongoDB ou MySQL, aient un sous-ensemble de données plus lent, généralement le plus récent. Les mécanismes de requête mentionnés ci-dessus peuvent combiner des données entre un stockage lent et rapide dans une seule requête.
Indexation distribuée
Ces outils fournissent des moyens de stocker et de récupérer des données textuelles non structurées, et ils vivent en dehors de l'écosystème Hadoop car ils nécessitent des structures spéciales pour stocker les données. L'idée est d'utiliser un index inversé pour effectuer des recherches rapides. En plus de la recherche de texte, cette technologie peut être utilisée à diverses fins, telles que le stockage de journaux, d'événements, etc. Il existe deux options principales:
Solr: Il s'agit d'une plate-forme de recherche d'entreprise open source populaire et très rapide, basée sur Apache Lucene. Solr est un outil robuste, évolutif et résilient, fournissant une indexation distribuée, une réplication et des requêtes à charge équilibrée, un basculement et une restauration automatiques, un provisionnement centralisé, etc. C'est idéal pour la recherche de texte, mais ses cas d'utilisation sont limités par rapport à ElasticSearch.
ElasticSearch: Il s'agit également d'un index distribué très populaire, mais qui est devenu un écosystème à part entière qui couvre de nombreux cas d'utilisation tels que l'APM, la recherche, le stockage de texte, l'analyse, les tableaux de bord, l'apprentissage automatique, etc. C'est certainement un outil à avoir dans votre boîte à outils pour DevOps ou pour le pipeline de données car il est très polyvalent. Il peut également stocker et rechercher des vidéos et des images.
ElasticSearchpeut être utilisé comme couche de stockage rapide pour votre lac de données pour une fonctionnalité de recherche avancée. Si vous stockez vos données dans une grande base de données de valeurs-clés comme HBase ou Cassandra, qui offrent des capacités de recherche très limitées en raison d'un manque de connexions, vous pouvez placer ElasticSearch devant eux pour exécuter des requêtes, renvoyer des ID, puis effectuez une recherche rapide dans votre base de données.
Il peut également être utilisé pour l'analyse. Vous pouvez exporter vos données, les indexer, puis les interroger à l'aide de KibanaEn créant des tableaux de bord, des rapports et plus encore, vous pouvez ajouter des histogrammes, des agrégations complexes et même exécuter des algorithmes d'apprentissage automatique en plus de vos données. L'écosystème ElasticSearch est énorme et mérite d'être exploré.
Bases de données OLAP
Ici, nous examinons les bases de données qui peuvent également fournir un magasin de métadonnées pour les schémas de requête. Par rapport aux systèmes d'exécution de requêtes, ces outils fournissent également le stockage de données et peuvent être appliqués à des schémas de stockage spécifiques (schéma en étoile). Ces outils utilisent la syntaxe SQL. Spark ou d'autres plates-formes peuvent interagir avec eux.
Ruche Apache: Nous avons déjà discuté de Hive en tant que référentiel de schémas central pour Spark et d'autres outils afin qu'ils puissent utiliser SQL, mais Hive peut également stocker des données afin que vous puissiez les utiliser comme référentiel. Il peut accéder à HDFS ou HBase. À la demande de Hive, il utilise Apache Tez, Apache Spark ou MapReduce, étant beaucoup plus rapide que Tez ou Spark. Il dispose également d'un langage procédural appelé HPL-SQL. Hive est un magasin de métadonnées extrêmement populaire pour Spark SQL.
Apache Impala: Il s'agit d'une base de données analytique native pour Hadoop que vous pouvez utiliser pour stocker des données et les interroger efficacement. Elle peut se connecter à Hive pour obtenir des métadonnées à l'aide d'Hcatalog. Impala fournit une faible latence et une haute concurrence pour les requêtes de business intelligence et d'analyse dans Hadoop (qui n'est pas fournie par les plates-formes packagées telles qu'Apache Hive). Impala évolue également de manière linéaire, même dans les environnements multi-utilisateurs, ce qui est une meilleure alternative aux requêtes que Hive. Impala est intégré à la sécurité propriétaire Hadoop et Kerberos pour l'authentification, ce qui vous permet de gérer en toute sécurité l'accès aux données. Il utilise HBase et HDFS pour le stockage des données.

Apache Tajo: Ceci est un autre entrepôt de données pour Hadoop. Tajo est conçu pour effectuer des requêtes ad hoc avec une latence et une évolutivité faibles, une agrégation en ligne et ETL pour de grands ensembles de données stockés dans HDFS et d'autres sources de données. Il prend en charge l'intégration avec Hive Metastore pour accéder aux schémas courants. Il a également de nombreuses optimisations de requêtes, il est évolutif, tolérant aux pannes et fournit une interface JDBC.
Apache Kylin: Il s'agit d'un nouvel entrepôt de données analytiques distribué. Kylin est extrêmement rapide, il peut donc être utilisé pour compléter d'autres bases de données comme Hive pour des cas d'utilisation où les performances sont essentielles, comme les tableaux de bord ou les rapports interactifs. C'est probablement le meilleur entrepôt de données OLAP, mais difficile à utiliser. Un autre problème est que plus d'espace de stockage est nécessaire en raison de l'étirement élevé. L'idée est que si les moteurs de requête ou Hive ne sont pas assez rapides, vous pouvez créer un «Cube» dans Kylin, qui est une table multidimensionnelle optimisée OLAP avec des
valeurs que vous pouvez interroger à partir de tableaux de bord ou de rapports interactifs. Il peut créer des cubes directement à partir de Spark et même presque en temps réel à partir de Kafka.
Outils OLAP
Dans cette catégorie, j'inclus des moteurs plus récents, qui sont des évolutions des bases de données OLAP précédentes, qui fournissent plus de fonctionnalités, créant une plate-forme d'analyse complète. En fait, ils sont un hybride des deux catégories précédentes qui ajoutent une indexation à vos bases de données OLAP. Ils vivent en dehors de la plate-forme Hadoop mais sont étroitement intégrés. Dans ce cas, vous ignorez généralement l'étape de traitement et utilisez ces outils directement.
Ils essaient de résoudre le problème de l'interrogation des données en temps réel et des données historiques de manière uniforme, afin que vous puissiez immédiatement interroger les données en temps réel dès qu'elles sont disponibles, ainsi que les données historiques à faible latence afin que vous puissiez créer des applications et des tableaux de bord interactifs. Ces outils permettent, dans de nombreux cas, d'interroger des données brutes avec peu ou pas de transformation de style ELT, mais avec des performances élevées, meilleures que les bases de données OLAP conventionnelles.
Ce qu'ils ont en commun, c'est qu'ils fournissent une vue unifiée des données, de l'ingestion de données en direct et par lots, de l'indexation distribuée, du format de données natif, de la prise en charge SQL, de l'interface JDBC, de la prise en charge des données chaudes et froides, des intégrations multiples et du stockage des métadonnées.
Apache Druid: Il s'agit du moteur OLAP en temps réel le plus connu. Il se concentre sur les données de séries chronologiques, mais peut être utilisé pour toutes les données. Il utilise son propre format en colonnes qui peut compresser beaucoup les données, et il possède de nombreuses optimisations intégrées telles que les index inversés, le codage de texte, les données à réduction automatique, etc. Les données sont chargées en temps réel à l'aide de Tranquility ou Kafka, qui ont une latence très faible, sont stockées en mémoire dans un format de chaîne optimisé en écriture, mais dès qu'elles arrivent, elles sont disponibles pour l'interrogation, tout comme les données téléchargées précédemment. Le processus d'arrière-plan est chargé de déplacer les données de manière asynchrone vers un système de stockage profond tel que HDFS. Lorsque les données sont déplacées vers un stockage en profondeur, elles sont divisées en petits morceaux,séparés dans le temps, appelés segments, qui sont bien optimisés pour les requêtes à faible latence. Ce segment a un horodatage pour plusieurs dimensions que vous pouvez utiliser pour filtrer et agréger, ainsi que des métriques, qui sont des états précalculés. En réception en rafale, les données sont enregistrées directement dans des segments. Apache Druid prend en charge la déglutition push and pull, l'intégration avec Hive, Spark et même NiFi. Il peut utiliser le magasin de métadonnées Hive et prend en charge les requêtes SQL Hive, qui sont ensuite converties en requêtes JSON utilisées par Druid. L'intégration Hive prend en charge JDBC, vous pouvez donc brancher n'importe quel outil de BI. Il possède également son propre référentiel de métadonnées, généralement MySQL est utilisé pour cela.Il peut accepter d'énormes quantités de données et évoluer très bien. Le principal problème est qu'il comporte de nombreux composants et qu'il est difficile à gérer et à déployer.
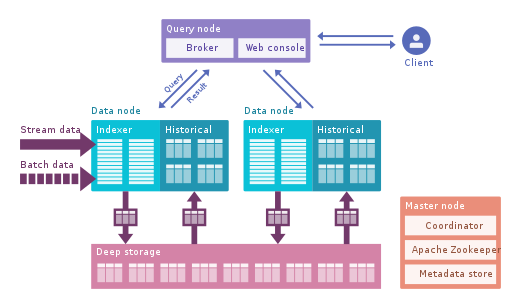
Apache Pinot : Il s'agit d'une nouvelle alternative à Druid open source de LinkedIn. Comparé à Druid, il offre une latence plus faible grâce à l'index Startree, qui effectue un pré-calcul partiel, il peut donc être utilisé pour des applications centrées sur l'utilisateur (il a été utilisé pour obtenir des flux LinkedIn). Il utilise un index trié au lieu d'un index inversé, ce qui est plus rapide. Il a une architecture de plugin extensible et a également de nombreuses intégrations, mais ne prend pas en charge Hive. Il intègre également le traitement par lots et en temps réel, fournit un chargement rapide, un index intelligent et stocke les données dans des segments. Il est plus facile et plus rapide à déployer par rapport à Druid, mais semble un peu immature pour le moment.
ClickHouse: écrit en C ++, ce moteur offre des performances incroyables pour les requêtes OLAP, en particulier pour les agrégats. C'est comme une base de données relationnelle, vous pouvez donc modéliser les données facilement. Il est très simple à mettre en place et possède de nombreuses intégrations.
Lisez cet article qui compare les 3 moteurs en détail.
Commencez petit en examinant vos données avant de prendre une décision. Ces nouveaux mécanismes sont très puissants, mais difficiles à utiliser. Si vous pouvez attendre des heures, utilisez le traitement par lots et une base de données comme Hive ou Tajo; puis utilisez Kylin pour accélérer les requêtes OLAP et les rendre plus interactives. Si cela ne suffit pas et que vous avez besoin encore moins de latence et de données en temps réel, pensez aux moteurs OLAP. Druid est plus adapté à l'analyse en temps réel. Kaileen se concentre davantage sur les cas OLAP. Druid a une bonne intégration avec Kafka en streaming en direct. Kylin reçoit des données de Hive ou Kafka par lots, bien qu'une réception en direct soit prévue.
Enfin, Greenplum Est un autre moteur OLAP, plus axé sur l'intelligence artificielle.
Visualisation de données
Il existe plusieurs outils commerciaux de visualisation tels que Qlik, Looker ou Tableau.
Si vous préférez Open Source, regardez vers SuperSet. C'est un excellent outil qui prend en charge tous les outils que nous avons mentionnés, a un excellent éditeur et est vraiment rapide, il utilise SQLAlchemy pour fournir un support pour de nombreuses bases de données.
D'autres outils intéressants sont Metabase ou Falcon .
Conclusion
Il existe un large éventail d'outils qui peuvent être utilisés pour manipuler les données, des moteurs de requête flexibles comme Presto aux stockages haute performance comme Kylin. Il n'y a pas de solution universelle, je vous conseille de rechercher les données et de commencer petit. Les moteurs de requêtes sont un bon point de départ en raison de leur flexibilité. Ensuite, pour différents cas d'utilisation, vous devrez peut-être ajouter des outils supplémentaires pour atteindre le niveau de service souhaité.
Portez une attention particulière aux nouveaux outils comme Druid ou Pinot, qui offrent un moyen facile d'analyser d'énormes quantités de données avec une latence très faible, réduisant ainsi l'écart entre OLTP et OLAP en termes de performances. Vous pourriez être tenté de penser au traitement, au pré-calcul des agrégats, etc., mais pensez à ces outils si vous souhaitez simplifier votre travail.