Inspiré par la conférence, cet article présente une approche pour simplifier le processus de création d'opérateurs pour Kubernetes et montre comment vous pouvez créer le vôtre à l'aide d'un opérateur shell avec un minimum d'effort.

Nous présentons la vidéo avec le rapport (~ 23 minutes en anglais, beaucoup plus informatif que l'article) et l'extrait principal de celui-ci sous forme de texte. Aller!
Chez Flant, nous optimisons et automatisons constamment tout. Aujourd'hui, nous allons parler d'un autre concept passionnant. Découvrez les scripts shell natifs du cloud !
Cependant, commençons par le contexte dans lequel tout cela se passe - Kubernetes.
API et contrôleurs Kubernetes
L'API dans Kubernetes peut être représentée comme une sorte de serveur de fichiers avec des répertoires pour chaque type d'objet. Les objets (ressources) sur ce serveur sont représentés par des fichiers YAML. De plus, le serveur dispose d'une API de base pour faire trois choses:
- obtenir une ressource par son type et son nom;
- changer la ressource (dans ce cas, le serveur ne stocke que les objets "corrects" - tous mal formés ou destinés à d'autres répertoires sont supprimés);
- ( / ).
Ainsi, Kubernetes agit comme une sorte de serveur de fichiers (pour les manifestes YAML) avec trois méthodes de base (oui, en fait, il y en a d'autres, mais nous les omettons pour l'instant).

Le problème est que le serveur ne peut stocker que des informations. Pour que cela fonctionne, vous avez besoin d'un contrôleur - le deuxième concept le plus important et le plus fondamental dans le monde Kubernetes.
Il existe deux principaux types de contrôleurs. Le premier prend les informations de Kubernetes, les traite conformément à la logique imbriquée et les renvoie aux K8. Le second prend des informations de Kubernetes, mais, contrairement au premier type, change l'état de certaines ressources externes.
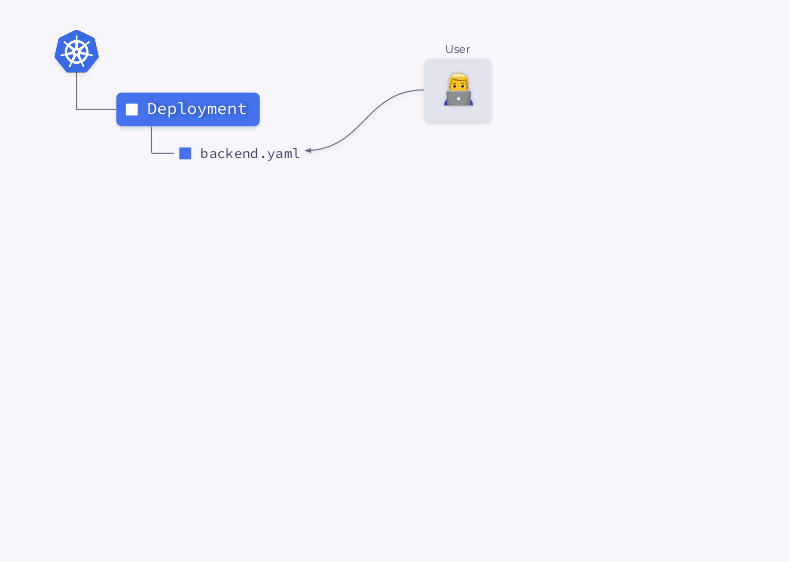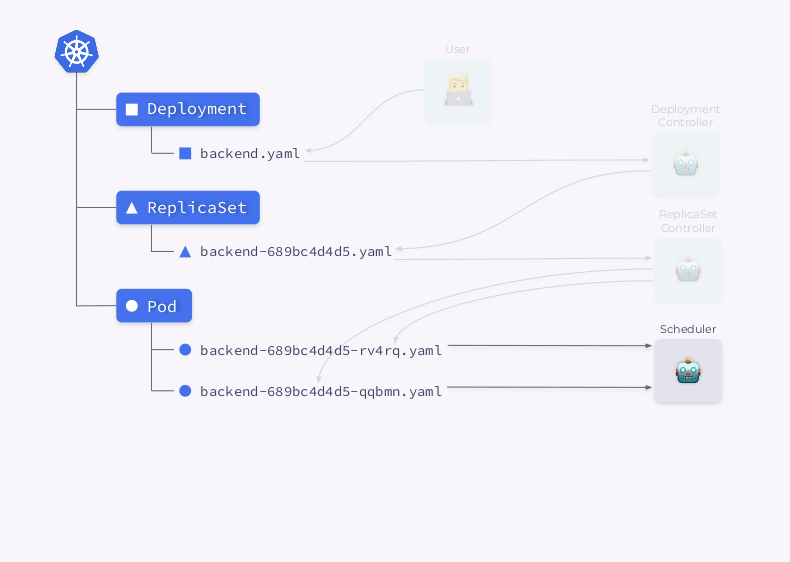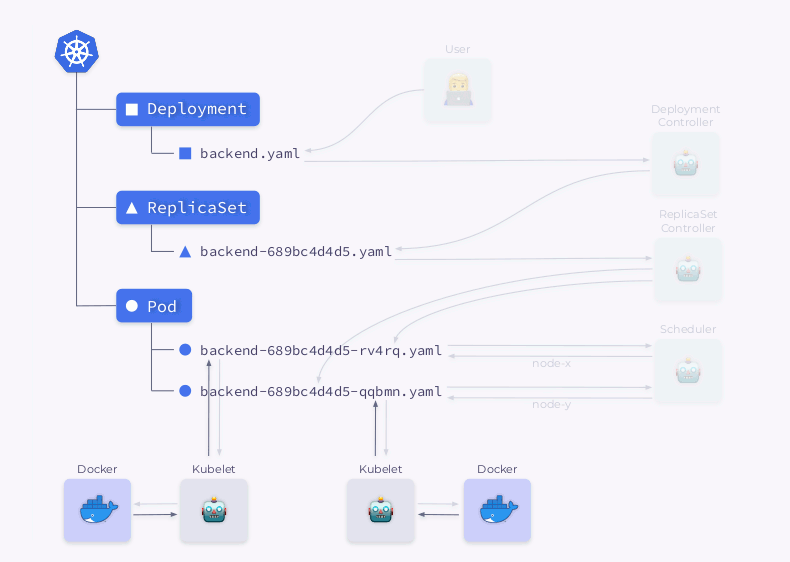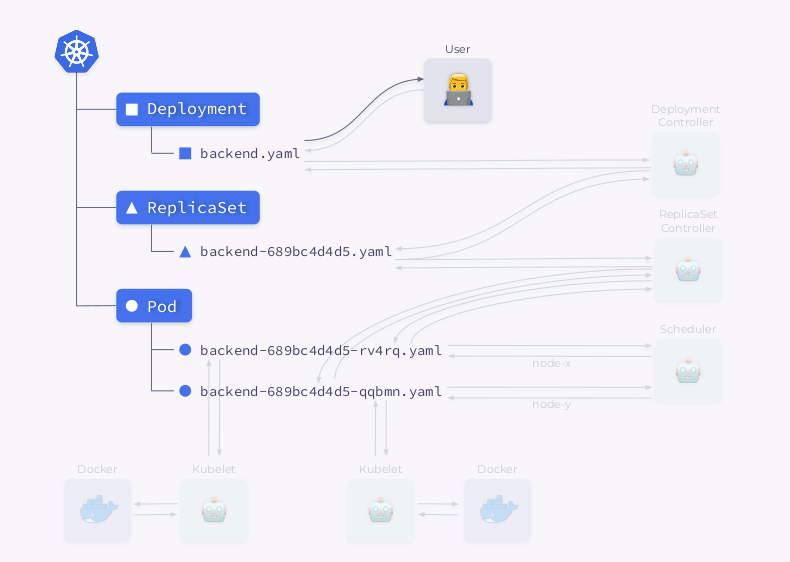
Examinons de plus près le processus de création d'un déploiement dans Kubernetes:
- Le contrôleur de déploiement (inclus dans
kube-controller-manager) reçoit des informations sur le déploiement et crée un ReplicaSet. - ReplicaSet crée deux répliques (deux pods) sur la base de ces informations, mais ces pods ne sont pas encore planifiés.
- Le planificateur planifie les pods et ajoute des informations sur les nœuds à leurs YAML.
- Les Kubelets apportent des modifications à une ressource externe (par exemple, Docker).
Ensuite, toute cette séquence est répétée dans l'ordre inverse: kubelet vérifie les conteneurs, calcule l'état du pod et le renvoie. Le contrôleur ReplicaSet obtient l'état et met à jour l'état du jeu de réplicas. La même chose se produit avec le Deployment Controller, et l'utilisateur obtient enfin un statut mis à jour (actuel).
Opérateur Shell
Il s'avère que Kubernetes est basé sur la collaboration de différents contrôleurs (les opérateurs Kubernetes sont également des contrôleurs). La question se pose, comment créer son propre opérateur avec un minimum d'effort? Et ici, l' opérateur shell développé par nous vient à la rescousse . Il permet aux administrateurs système de créer leurs propres déclarations en utilisant des méthodes familières.

Exemple simple: copier des secrets
Jetons un coup d'œil à un exemple simple.
Disons que nous avons un cluster Kubernetes. Il a un espace
defaultde noms avec du secret mysecret. En outre, il existe d'autres espaces de noms dans le cluster. Certains d'entre eux ont une étiquette spécifique attachée. Notre objectif est de copier Secret dans des espaces de noms avec une étiquette.
La tâche est compliquée par le fait que de nouveaux espaces de noms peuvent apparaître dans le cluster, et certains d'entre eux peuvent avoir cette étiquette. D'autre part, lors de la suppression d'une étiquette, Secret doit également être supprimé. En plus de tout, le secret lui-même peut également changer: dans ce cas, le nouveau secret doit être copié dans tous les espaces de noms avec des étiquettes. Si Secret est accidentellement supprimé dans un espace de noms, notre opérateur doit le restaurer immédiatement.
Maintenant que la tâche a été formulée, il est temps de commencer à l'implémenter en utilisant l'opérateur shell. Mais d'abord, il vaut la peine de dire quelques mots sur l'opérateur shell lui-même.
Comment fonctionne l'opérateur shell
Comme d'autres charges de travail dans Kubernetes, l'opérateur shell s'exécute dans son pod. Ce pod
/hookscontient des fichiers exécutables dans le répertoire . Il peut s'agir de scripts en Bash, Python, Ruby, etc. Nous appelons ces hooks exécutables .

L'opérateur Shell s'abonne aux événements Kubernetes et déclenche ces hooks en réponse aux événements dont nous avons besoin.

Comment l'opérateur shell sait-il quel hook exécuter et quand? Le fait est que chaque crochet comporte deux étapes. Au démarrage, l'opérateur shell exécute tous les hooks avec un argument
--config- c'est l'étape de configuration. Et après cela, les crochets sont lancés de la manière normale - en réponse aux événements auxquels ils sont attachés. Dans ce dernier cas, le hook reçoit le contexte de liaison) - données au format JSON, dont nous parlerons plus en détail ci-dessous.
Faire de l'opérateur dans Bash
Nous sommes maintenant prêts pour la mise en œuvre. Pour ce faire, nous devons écrire deux fonctions (au fait, nous recommandons la bibliothèque shell_lib , qui simplifie grandement l'écriture de hooks dans Bash):
- le premier est nécessaire pour l'étape de configuration - il affiche le contexte de liaison;
- le second contient la logique principale du crochet.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
La prochaine étape consiste à décider des objets dont nous avons besoin. Dans notre cas, nous devons suivre:
- source secrète des changements;
- tous les espaces de noms du cluster, afin que vous sachiez à ceux auxquels l'étiquette est attachée;
- les secrets cibles pour vous assurer qu'ils sont tous synchronisés avec le secret source.
Abonnez-vous à une source secrète
La configuration de la liaison est assez simple pour lui. Nous indiquons que nous sommes intéressés par Secret avec un nom
mysecretdans l'espace de noms default:

function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
Par conséquent, le hook s'exécutera lorsque le secret source (
src_secret) changera et recevra le contexte de liaison suivant:

Comme vous pouvez le voir, il contient le nom et l'objet entier.
Suivi des espaces de noms
Vous devez maintenant vous abonner aux espaces de noms. Pour ce faire, nous allons spécifier la configuration de liaison suivante:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Comme vous pouvez le voir, un nouveau champ nommé jqFilter est apparu dans la configuration . Comme son nom l'indique, il
jqFilterfiltre toutes les informations inutiles et crée un nouvel objet JSON avec les champs qui nous intéressent. Un hook avec cette configuration recevra le contexte de liaison suivant:
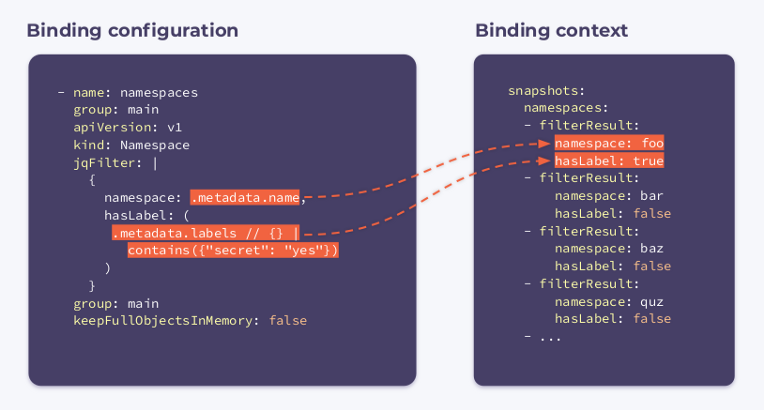
Il contient un tableau
filterResultspour chaque espace de noms du cluster. Une variable booléenne hasLabelindiquant si l'étiquette est attachée à l'espace de noms donné. Le sélecteur keepFullObjectsInMemory: falseindique qu'il n'est pas nécessaire de conserver des objets complets en mémoire.
Suivi des cibles secrètes
Nous souscrivons à tous les Secrets qui ont une annotation
managed-secret: "yes"(ce sont nos cibles dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
Dans ce cas,
jqFilterfiltre toutes les informations à l'exception de l'espace de noms et du paramètre resourceVersion. Le dernier paramètre a été passé à l'annotation lors de la création du secret: il permet de comparer les versions des secrets et de les maintenir à jour.
Un hook configuré de cette manière recevra les trois contextes de liaison décrits ci-dessus lors de son exécution. Considérez-les comme une sorte de cliché du cluster.

Sur la base de toutes ces informations, un algorithme de base peut être développé. Il itère sur tous les espaces de noms et:
- le cas
hasLabeléchéanttruepour l'espace de noms actuel:- compare le secret global avec le secret local:
- s'ils sont identiques, cela ne fait rien;
- s'ils diffèrent, exécutez
kubectl replaceoucreate;
- compare le secret global avec le secret local:
- le cas
hasLabeléchéantfalsepour l'espace de noms actuel:
- s'assure que Secret n'est pas dans l'espace de noms donné:
- si un secret local est présent, supprimez-le en utilisant
kubectl delete; - si aucun secret local n'est trouvé, il ne fait rien.
- si un secret local est présent, supprimez-le en utilisant
- s'assure que Secret n'est pas dans l'espace de noms donné:

Vous pouvez télécharger l' implémentation de l' algorithme dans Bash dans notre référentiel avec des exemples .
C'est ainsi que nous avons pu créer un contrôleur Kubernetes simple en utilisant 35 lignes de configurations YAML et à peu près la même quantité de code Bash! Le travail de l'opérateur shell est de les enchaîner.
Cependant, la copie de secrets n'est pas le seul domaine d'application de l'utilitaire. Voici quelques exemples supplémentaires pour montrer de quoi il est capable.
Exemple 1: apporter des modifications à ConfigMap
Examinons un déploiement à trois pods. Les pods utilisent ConfigMap pour stocker une configuration. Lorsque les pods ont été lancés, ConfigMap était dans un certain état (appelons-le v.1). En conséquence, tous les pods utilisent cette version particulière de ConfigMap.
Supposons maintenant que ConfigMap a changé (v.2). Cependant, les pods utiliseront l'ancienne version de ConfigMap (v.1):
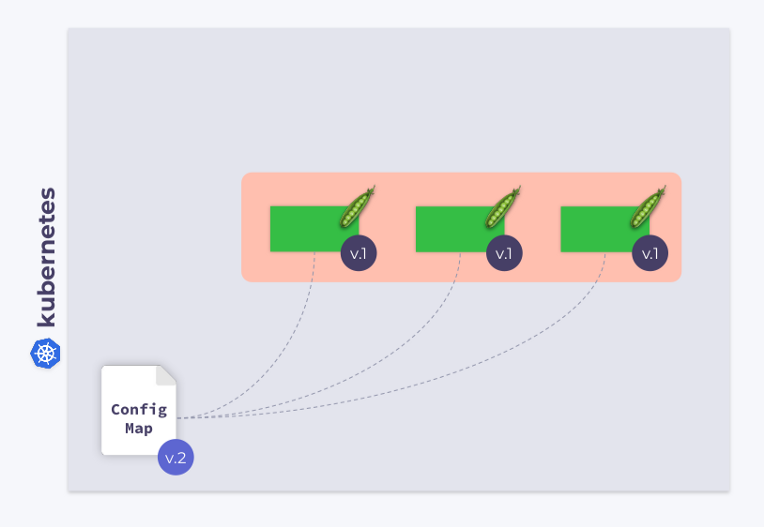
comment les faire migrer vers le nouveau ConfigMap (v.2)? La réponse est simple: utilisez un modèle. Ajoutons une annotation de somme de contrôle à la section de
templateconfiguration de déploiement:

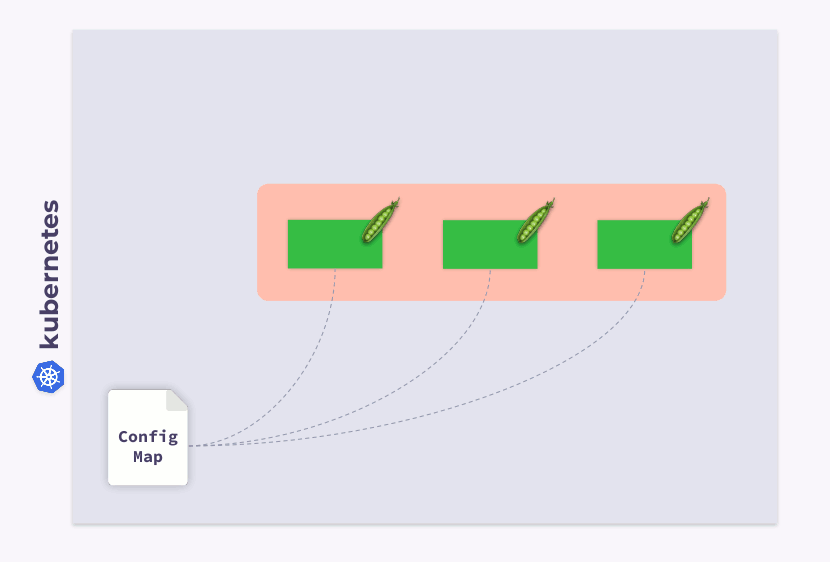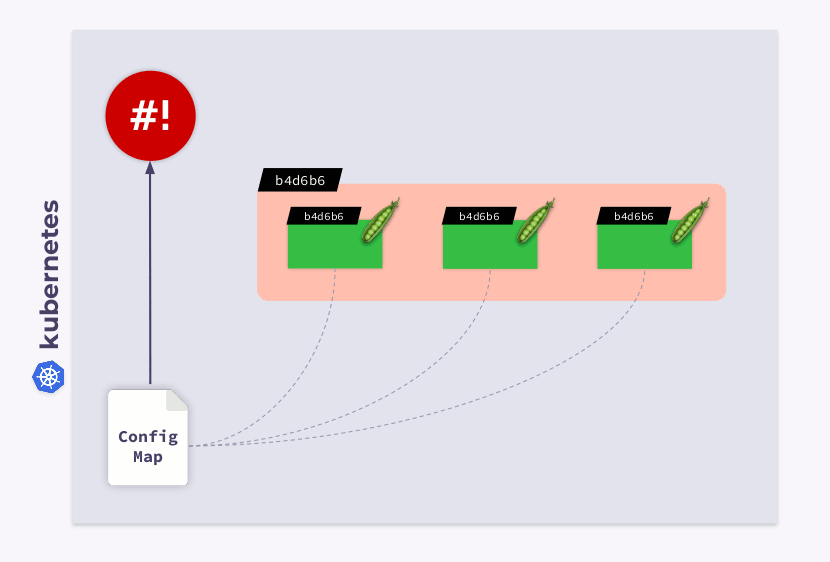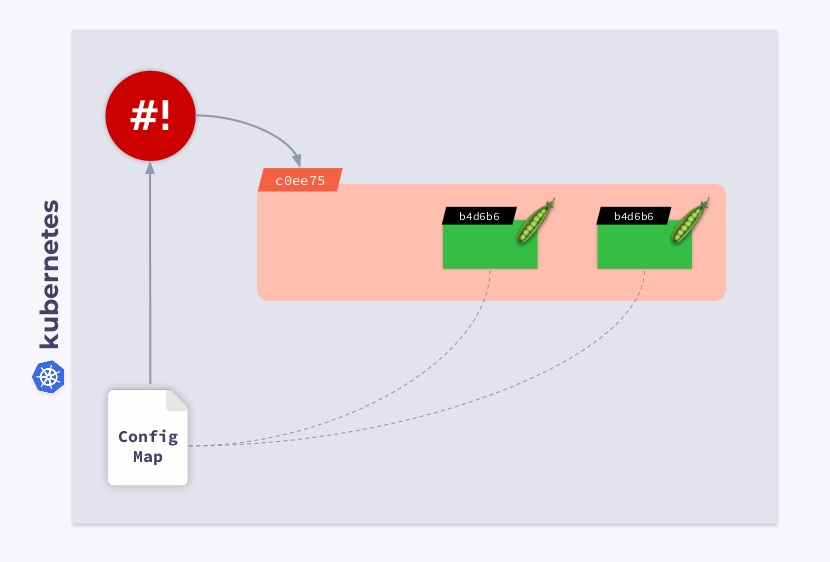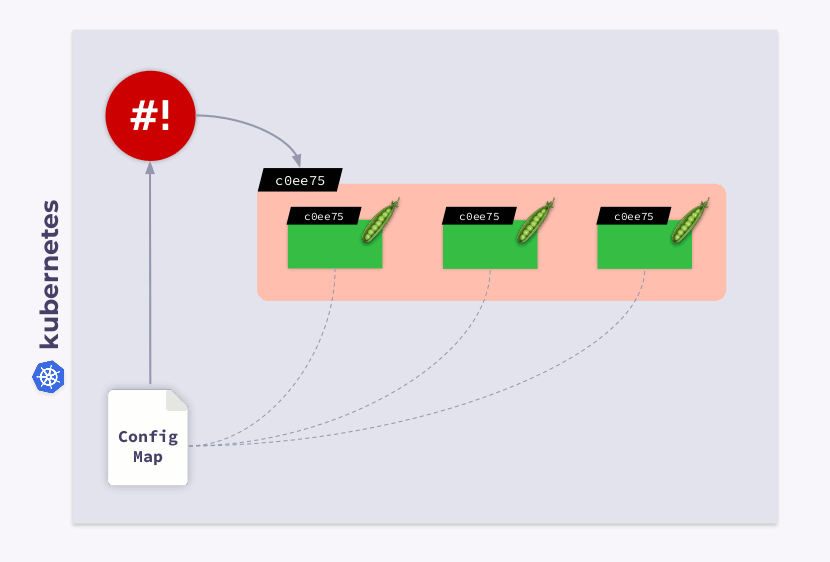
En conséquence, cette somme de contrôle sera enregistrée dans tous les pods et sera la même que dans le déploiement. Il vous suffit maintenant de mettre à jour l'annotation lorsque ConfigMap change. Et l'opérateur shell est utile dans ce cas. Tout ce que vous avez à faire est de programmer un hook qui s'abonnera à ConfigMap et mettra à jour la somme de contrôle .
Si l'utilisateur apporte des modifications au ConfigMap, l'opérateur du shell les remarquera et recalculera la somme de contrôle. Ensuite, la magie de Kubernetes entre en jeu: l'orchestrateur tuera le pod, en créera un nouveau, attendra qu'il devienne
Ready, et passera au suivant. En conséquence, le déploiement sera synchronisé et migré vers la nouvelle version de ConfigMap.
Exemple 2: Utilisation de définitions de ressources personnalisées
Comme vous le savez, Kubernetes vous permet de créer des types (sortes) d'objets personnalisés. Par exemple, vous pouvez créer un kind
MysqlDatabase. Disons que ce type a deux paramètres de métadonnées: nameetnamespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
Nous avons un cluster Kubernetes avec différents espaces de noms dans lesquels nous pouvons créer des bases de données MySQL. Dans ce cas, l'opérateur shell peut être utilisé pour suivre les ressources
MysqlDatabase, les connecter au serveur MySQL et synchroniser les états souhaités et observés du cluster.

Exemple 3: surveillance d'un réseau de cluster
Comme vous le savez, l'utilisation du ping est le moyen le plus simple de surveiller un réseau. Dans cet exemple, nous montrerons comment implémenter une telle surveillance à l'aide de l'opérateur shell.
Tout d'abord, vous devez vous abonner aux nœuds. L'opérateur shell a besoin du nom et de l'adresse IP de chaque nœud. Avec leur aide, il ping ces nœuds.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
Le paramètre
executeHookOnEvent: []empêche le lancement du hook en réponse à tout événement (c'est-à-dire en réponse à des modifications, des ajouts, des suppressions de nœuds). Cependant, il s'exécutera (et mettra à jour la liste d'hôtes) selon un calendrier - toutes les minutes, comme le champ l'indique schedule.
Maintenant, la question se pose, comment savons-nous exactement des problèmes tels que la perte de paquets? Jetons un coup d'œil au code:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Nous parcourons la liste des nœuds, obtenons leurs noms et adresses IP, pingons et envoyons les résultats à Prometheus. L'opérateur Shell peut exporter des métriques vers Prometheus , en les enregistrant dans un fichier situé selon le chemin spécifié dans la variable d'environnement
$METRICS_PATH.
C'est ainsi que vous pouvez faire un opérateur pour une surveillance simple du réseau dans un cluster.
Mécanisme de file d'attente
Cet article serait incomplet sans décrire un autre mécanisme important intégré à l'opérateur shell. Imaginez qu'il exécute un hook en réponse à un événement dans le cluster.
- Que se passe-t-il si un autre événement se produit dans le cluster en même temps ?
- L'opérateur shell démarrera-t-il une autre instance du hook?
- Mais que se passe-t-il si, par exemple, cinq événements se produisent immédiatement dans le cluster?
- L'opérateur shell les traitera-t-il en parallèle?
- Qu'en est-il des ressources consommées comme la mémoire et le processeur?
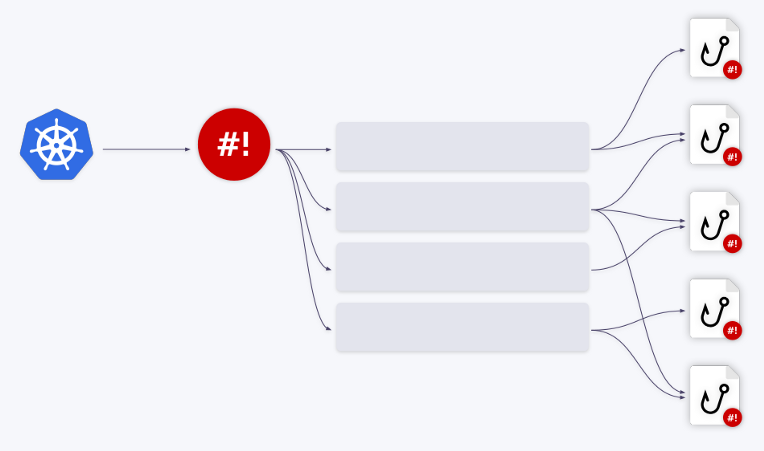
Heureusement, l'opérateur shell dispose d'un mécanisme de mise en file d'attente intégré. Tous les événements sont mis en file d'attente et traités de manière séquentielle.
Illustrons cela par des exemples. Disons que nous avons deux crochets. Le premier événement va au premier hook. Une fois son traitement terminé, la file d'attente avance. Les trois événements suivants sont redirigés vers le deuxième hook - ils sont supprimés de la file d'attente et y sont introduits dans un "lot". Autrement dit, le hook reçoit un tableau d'événements - ou plus précisément, un tableau de contextes de liaison.
En outre, ces événements peuvent être combinés en un seul grand . Le paramètre
groupdans la configuration de liaison est responsable de cela .

Vous pouvez créer n'importe quel nombre de files d'attente / hooks et leurs diverses combinaisons. Par exemple, une file d'attente peut fonctionner avec deux hooks, ou vice versa.
Tout ce que vous avez à faire est d'ajuster le champ en conséquence
queuedans la configuration de liaison. Si aucun nom de file d'attente n'est spécifié, le hook s'exécute sur la file d'attente par défaut ( default). Ce mécanisme de mise en file d'attente vous permet de résoudre complètement tous les problèmes de gestion des ressources lorsque vous travaillez avec des hooks.
Conclusion
Nous avons parlé de ce qu'est un opérateur shell, montré comment il peut être utilisé pour créer rapidement et sans effort des opérateurs Kubernetes et donné plusieurs exemples de son utilisation.
Des informations détaillées sur l'opérateur shell, ainsi qu'un guide rapide pour son utilisation, sont disponibles dans le référentiel correspondant sur GitHub . N'hésitez pas à nous contacter pour toute question: vous pouvez en discuter dans un groupe spécial Telegram (en russe) ou dans ce forum (en anglais).
Et si cela vous a plu, nous sommes toujours heureux de découvrir de nouveaux numéros / PR / stars sur GitHub, où, d'ailleurs, vous pouvez trouver d'autres projets intéressants . Parmi eux, il convient de souligner l' opérateur addon , qui est le frère aîné de l'opérateur shell... Cet utilitaire utilise des graphiques Helm pour installer des modules complémentaires, est capable de fournir des mises à jour et de surveiller divers paramètres / valeurs de graphique, contrôle le processus d'installation des graphiques et peut également les modifier en réponse aux événements du cluster.

Vidéos et diapositives
Vidéo de la performance (~ 23 minutes):
Présentation du rapport:
PS
Lisez aussi sur notre blog:
- " Création simple d'opérateurs Kubernetes avec un opérateur shell: avancement du projet en un an ";
- « Présentation de l'opérateur shell: la création d'opérateurs pour Kubernetes est devenue plus simple »;
- « Est-il facile et pratique de préparer un cluster Kubernetes? Nous annonçons addon-operator ";
- " Expansion et complément de Kubernetes" (revue et vidéo du rapport) .