Dans Surf, nous avons écrit notre propre interpréteur et l'utilisons sur le client de l'application mobile - même si au départ, il semblerait que cela ait généralement peu à voir avec le développement mobile. En fait, les interprètes et les compilateurs sont des outils pour résoudre des problèmes qui peuvent être trouvés n'importe où. Par conséquent, comprendre comment cela fonctionne et être capable d'écrire le vôtre est utile.
Aujourd'hui, en utilisant l'exemple de la traduction de masques d'un format à un autre, nous nous familiariserons avec les bases de la construction d'interprètes et verrons comment utiliser des grammaires formelles, un arbre de syntaxe abstrait, des règles de traduction - y compris pour résoudre des problèmes métier.

Un peu sur les masques: ce qu'ils sont et pourquoi vous en avez besoin
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
Pourquoi ne peux-tu pas simplement prendre et décrire le masque
Les masques sont frais et confortables. Mais il y a un problème inévitable dans certaines conditions: lorsque le client a un format de masque, et que le serveur a de nombreux fournisseurs de données différents et que chacun a son propre format. Nous ne pouvons pas compter sur le fait que nous aurons le même format. Demander au serveur: "Ajustez les masques pour nous comme nous voulons" - aussi. Vous devez pouvoir vivre avec.
Le problème se pose: il existe une spécification backend, vous devez écrire un frontend - une application mobile. Vous pouvez écrire manuellement tous les masques pour l'application - et c'est une bonne option lorsqu'il n'y a qu'un seul fournisseur et qu'il y a peu de masques. Le programmeur, bien sûr, devra passer du temps pour comprendre au moins deux spécifications pour les masques: backend et front. Ensuite, il doit traduire des masques backend spécifiques en masques frontend correspondants. Cela prend aussi du temps, il y a un facteur humain - vous pouvez vous tromper. Ce n'est pas un travail facile, la traduction est difficile: certains langages de masques sont écrits principalement pour les ordinateurs, pas pour les humains.
Si soudainement le masque sur le serveur a changé ou si un nouveau masque est apparu, l'application peut tout d'abord cesser de fonctionner. Deuxièmement, le dur travail de traduction doit être refait, une nouvelle application doit être publiée, cela demande du temps, des efforts et de l'argent. La question se pose: comment minimiser le travail du programmeur? Il semble que tout cela devrait être fait par une machine, mais pour une raison quelconque, une personne le fait.
La réponse est oui, nous avons une solution. Les masques sont écrits dans la langue des ordinateurs - et c'est l'une des raisons pour lesquelles il est difficile pour une personne de travailler avec elle et de traduire d'une langue à une autre. Nous devons transférer ce travail sur l'ordinateur. Puisque le masque semble être une grammaire formelle , le moyen le plus sûr de traduire une grammaire en une autre est:
- comprendre les règles de construction de la grammaire originale,
- comprendre les règles de construction de la grammaire cible,
- écrire des règles de traduction de la grammaire source vers la cible,
- implémentez tout cela dans le code.
C'est pour cela que les compilateurs et les traducteurs sont écrits.
Examinons maintenant de plus près notre solution basée sur des grammaires formelles.
Contexte
Dans notre application, il existe de nombreux écrans différents qui sont formés selon le principe du backend: une description complète de l'écran, ainsi que des données, provient du serveur.

La plupart des écrans contiennent une variété de formulaires de saisie. Le serveur détermine quels champs se trouvent sur le formulaire et comment ils doivent être formatés. Des masques sont également utilisés pour décrire ces exigences.
Voyons comment fonctionnent les masques.
Exemples de masques dans différents formats
Comme premier exemple, prenons la même forme de saisie d'un numéro de téléphone. Le masque pour une telle forme pourrait ressembler à ceci.

D'une part, le masque lui-même ajoute des délimiteurs, des parenthèses et interdit la saisie de caractères incorrects. D'autre part, le même masque extrait des informations utiles de l'entrée formatée à envoyer au serveur.
La partie appelée constante est surlignée en rouge. Ce sont des symboles qui apparaîtront automatiquement - l'utilisateur ne doit pas les saisir:

Vient ensuite la partie dynamique - elle est toujours entre crochets:

Plus loin dans le texte, j'appellerai cette expression "expression dynamique" - ou DW en abrégé
Voici l'expression par laquelle nous formaterons notre entrée: Les

pièces responsables du contenu de la partie dynamique sont surlignées en rouge.
\\ d - n'importe quel chiffre.
+ - répétition régulière: répéter au moins une fois.
$ {3} est un symbole de méta-information qui spécifie le nombre de répétitions. Dans ce cas, il devrait y avoir trois caractères.
Ensuite, l'expression \\ d + $ {3} signifie qu'il doit y avoir trois chiffres.
Dans ce format de masques, il ne peut y avoir qu'un seul répéteur à l'intérieur de la partie dynamique:

Cette limitation est apparue pour une raison - maintenant je vais vous expliquer pourquoi.
Disons que nous avons un DV, dans lequel la taille est codée en dur: 4 éléments. Et on lui donne 2 éléments avec un répéteur: `<! ^ \\ d + \\ v + $ {4}>`. Les combinaisons suivantes relèvent d'un tel DV:
- 1abc
- 12ab
- 123a
Il s'avère qu'un tel DV ne nous donne pas une réponse sans ambiguïté, à quoi s'attendre à la place du deuxième caractère: un chiffre ou une lettre.
Prenez le masque, ajoutez-le avec l'entrée utilisateur. Nous obtenons le numéro de téléphone formaté:

sur le client, le format des masques peut être différent. Par exemple, dans le masque de saisie bibliothèque de Redmadrobot, le masque pour le numéro de téléphone

ressemble comme ceci: Il semble plus agréable et plus facile à comprendre.
Il s'avère que le masque pour le serveur et le masque pour le client sont écrits différemment, mais ils font la même chose.

Reformulons le problème: comment combiner des masques de différents formats
Nous devons combiner ces masques les uns avec les autres - ou d'une manière ou d'une autre obtenir le second de l'un.
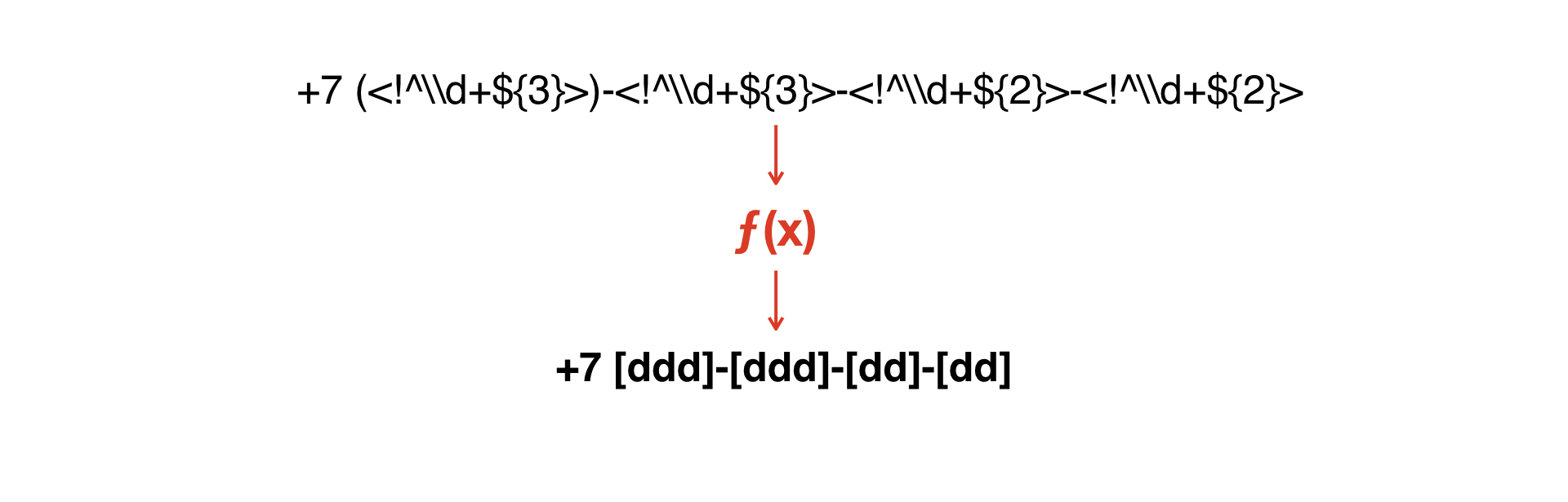
Nous devons créer une fonction qui convertirait un masque en un second.
Et ici l'idée est venue d'écrire un interpréteur très simple qui permettrait d'obtenir une deuxième grammaire à partir d'une grammaire.
Depuis que nous sommes arrivés à l'interprète, parlons de grammaires.
Comment l'analyse est effectuée
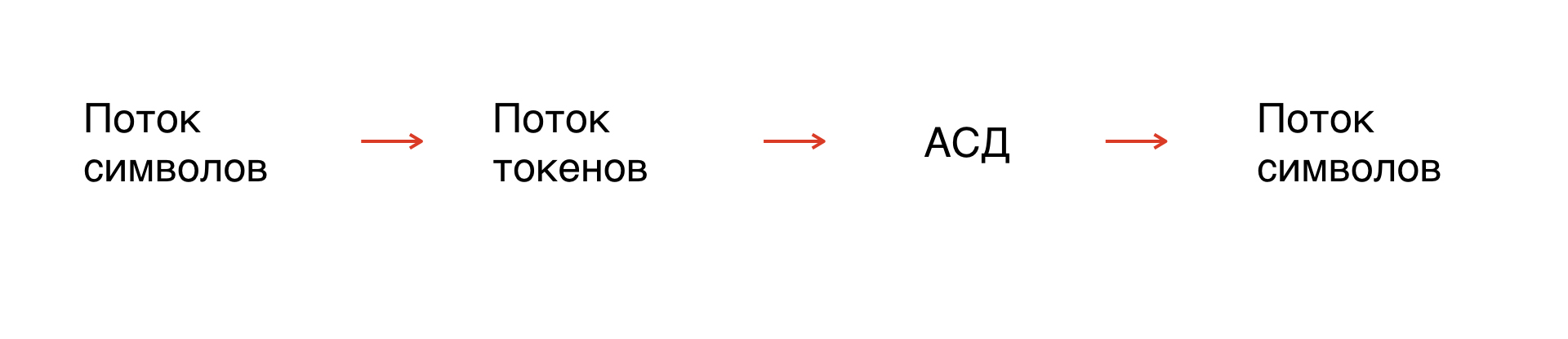
Premièrement, nous avons un flux de personnages - notre masque. En fait, c'est la chaîne sur laquelle nous opérons. Mais comme les symboles ne sont pas formalisés, vous devez formaliser la chaîne: la décomposer en éléments qui seront compréhensibles par l'interpréteur.
Ce processus s'appelle la tokenisation: un flux de symboles se transforme en un flux de jetons. Le nombre de jetons est limité, ils sont formalisés, ils peuvent donc être analysés.
De plus, sur la base des règles de grammaire, nous construisons une arborescence de syntaxe abstraite le long du flux de jetons. De l'arbre, nous obtenons un flux de symboles dans la grammaire dont nous avons besoin.
Il y a une expression. Nous le regardons et voyons que nous avons une constante, dont j'ai parlé ci-dessus: nous

représentons toutes les constantes comme un jeton CS, dont l'argument est la constante elle-même:

Le prochain type de jetons est le début du DW:

De plus, tous ces jetons seront interprétés comme des caractères spéciaux. Dans notre exemple, il n'y en a pas beaucoup, dans les vrais masques, il peut y en avoir beaucoup plus.

Ensuite, nous avons un répéteur.
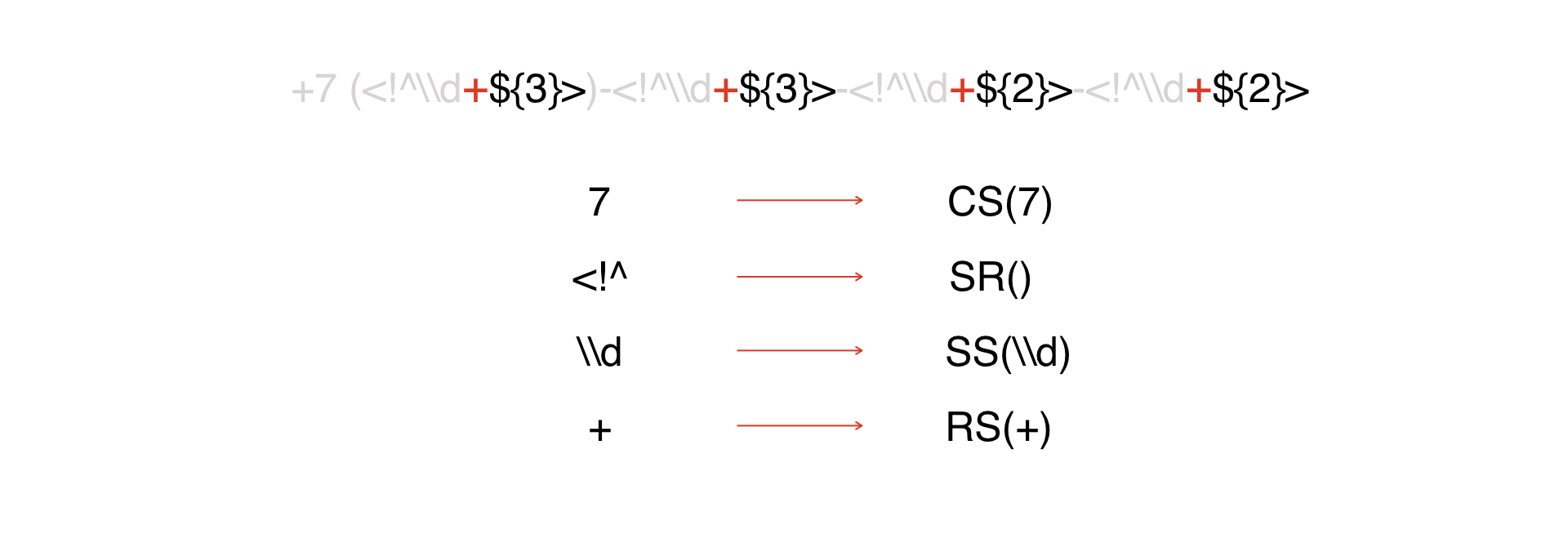
Ensuite - quelques caractères considérés comme des métadonnées. Nous tricherons et leur présenterons un jeton, car c'est plus facile comme ça.

Fin de l'Extrême-Orient. Ainsi, nous avons tout décomposé en jetons.

Un exemple de tokenisation d'un masque pour un numéro de téléphone
Pour voir comment, en principe, le processus de tokenisation se déroule et comment l'interpréteur fonctionnera, nous prenons un masque pour un numéro de téléphone et le transformons en un flux de jetons.

Tout d'abord, le symbole +. Convertir en constante +. Ensuite, nous faisons la même chose pour le 7 et pour tous les autres symboles. Nous obtenons un tableau de jetons. Ce n'est pas encore une structure - nous analyserons plus en détail ce tableau.
Lexer et bâtiment ASD
Maintenant, la partie délicate est le lexer.

Sur la gauche, une légende est décrite - des caractères spéciaux qui sont utilisés pour décrire les règles lexicales. Sur la droite se trouvent les règles elles-mêmes.
La symbolRule décrit un symbole. Si cette règle s'applique, si elle est vraie, cela signifie que nous avons rencontré soit un caractère spécial, soit un caractère constant. On peut dire que c'est une fonction.
Vient ensuite repeaterRule. Cette règle décrit une situation où un personnage est rencontré, suivi d'un jeton de répéteur.
Ensuite, tout se ressemble. Si c'est LW, alors c'est soit un symbole soit un répéteur. Dans notre cas, cette règle est plus large. Et à la fin, il doit y avoir un jeton avec des métadonnées.
La dernière règle est maskRule. Ceci est une séquence de symboles et DV.
Maintenant, construisonsun arbre de syntaxe abstraite (AST) à partir d'un tableau de jetons.
Voici une liste de jetons. Le premier nœud de l'arbre est le nœud racine, à partir duquel nous allons commencer à construire. Cela n'a aucun sens, il faut juste une racine.

Nous avons le premier jeton +, donc nous ajoutons simplement un nœud enfant, et c'est tout.

Nous faisons la même chose avec tous les autres symboles constants, mais ensuite c'est plus compliqué. Nous sommes tombés sur un token DV.

Ce n'est pas seulement un site régulier - nous savons qu'il doit avoir une sorte de contenu.

Le nœud de contenu n'est qu'un nœud technique vers lequel nous pouvons naviguer à l'avenir. Il a ses propres nœuds enfants et quel nœud aura-t-il ensuite? Le jeton suivant dans notre flux est un caractère spécial. Sera-ce un nœud enfant?

En fait, dans ce cas, non. Nous aurons un répéteur comme nœud enfant.

Pourquoi? Parce qu'il est plus pratique de travailler le bois à l'avenir. Disons que nous voulons analyser cet arbre et en construire une sorte de grammaire. Lors de l'analyse d'un arbre, nous examinons les types de nœuds. Si nous avons un nœud CS, nous l'analysons dans le même nœud CS, mais pour une grammaire différente. Par convention, nous parcourons les sommets de l'arbre et exécutons une sorte de logique.
La logique dépend du type de nœud - ou du type de jeton qui se trouve dans le nœud. Pour l'analyse, il est beaucoup plus pratique de comprendre immédiatement quel jeton est devant vous: composite, comme un répéteur, ou simple, comme CS. Ceci est nécessaire pour qu'il n'y ait pas de doubles interprétations ou de recherches constantes pour les nœuds enfants.
Cela serait particulièrement visible sur les groupes de caractères: par exemple, [abcde]. Dans ce cas, évidemment, il doit y avoir une sorte de nœud GROUP parent qui aura une liste de nœuds enfants CS (a) CS (b), etc.
Revenez au jeton avec les métadonnées. Ce n'est pas inclus dans le contenu, c'est sur le côté.

Ceci est nécessaire pour faciliter le travail avec l'arborescence, afin que nous ne considérions pas ce nœud comme un contenu - car en fait il ne lui appartient pas.
Le DV s'est terminé, et nous ne le considérons pas comme une sorte de nœud: c'était un jeton qui peut maintenant être jeté. Nous ne le transformerons pas en nœud d'arbre.
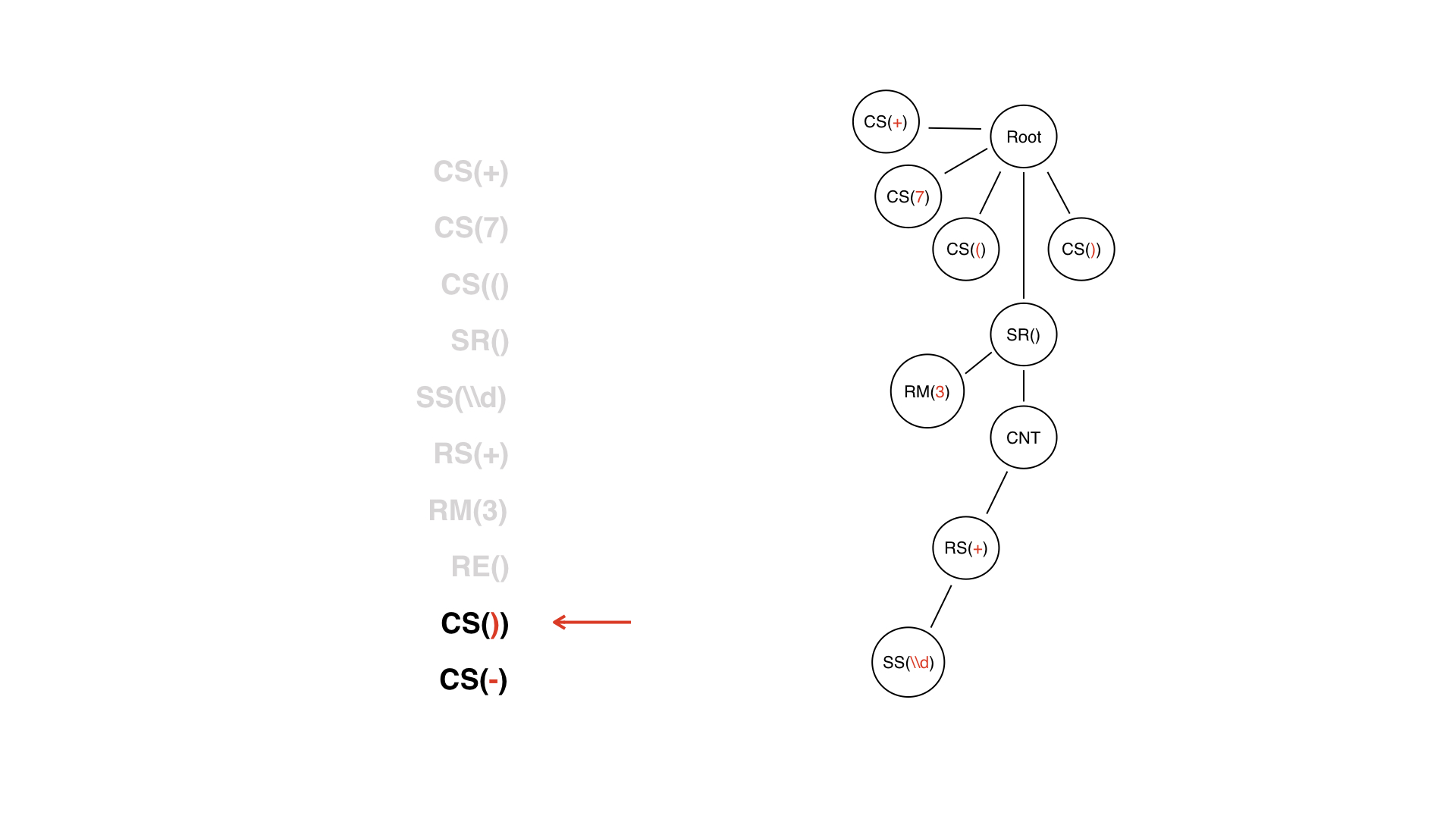
Nous avons déjà un sous-arbre, dont la racine est le nœud SR - c'est-à-dire la partie très dynamique. Le jeton de fin LW nous aide beaucoup dans le processus de création de l'arborescence - nous pouvons comprendre quand le sous-arbre pour LW est terminé. Mais ce jeton n'a aucune valeur pour la logique: en regardant un arbre ligne par ligne, on comprend déjà quand le DW se terminera, car il est en quelque sorte fermé par le nœud SR.
De plus - juste des symboles constants ordinaires.

Nous avons un arbre. Passons maintenant en revue cet arbre en profondeur et construisons sur sa base une autre grammaire: vous devez entrer dans un nœud, voir de quel type de nœud il s'agit et générer un élément d'une autre grammaire à partir de ce nœud.
Syntaxe de la bibliothèque InputMask de Redmadrobot
Regardons la syntaxe de la bibliothèque Redmadrobot.

Voici la même expression. +7 est une constante qui sera ajoutée automatiquement. À l'intérieur des accolades, le DV est décrit - la partie dynamique. À l'intérieur du DV, il y a un caractère spécial d. Redmadrobot a cette notation par défaut qui désigne un chiffre.
Voici à quoi ressemble la notation:

La notation se compose de trois parties:
- caractère est le caractère que nous utiliserons pour écrire le masque. En quoi consiste l'alphabet de masque. Par exemple, d.
- characterSet - quels caractères tapés par l'utilisateur correspondent à cette notation. Par exemple, 0, 1, 2, 3, 4 et ainsi de suite.
- isOptional - si l'utilisateur doit entrer l'un des caractères characterSet ou ne rien entrer.
Regardez, nous allons maintenant avoir un tel masque.

- Le caractère "b" a une notation numérique spéciale et n'est pas facultatif.
- Le caractère "c" a une notation différente - CharacterSet est différent. Ce n'est pas non plus facultatif.
- Et le caractère "C" est le même que "c", mais il est facultatif. Ceci est nécessaire pour que, dans le masque, nous regardions les métadonnées et voyions qu'il n'y a pas de limite stricte, mais faible.
Si vous devez écrire une règle alors qu'il peut y avoir de un à dix caractères, un caractère ne sera pas facultatif. Et neuf caractères seront facultatifs. Autrement dit, dans la notation de l'exemple, ils seront écrits en majuscules. En conséquence, cette règle ressemblera à ceci: [cCCCCCCCCC]
Exemple: conversion du masque de numéro de téléphone du format backend au format InputMask
Voici l'arbre que nous avons obtenu à la dernière étape. Nous devons marcher dessus. La première chose à laquelle nous arrivons est la racine.

Plus loin de la racine, nous nous trouvons dans le symbole constant + - nous générons immédiatement +. Sur la droite, un masque est écrit au format InputMask.

Le caractère suivant est compréhensible - juste 7, suivi d'une parenthèse ouverte.
Ensuite, un morceau de la partie dynamique est généré, mais il n'est pas encore rempli.

Nous entrons, nous avons du contenu, c'est un nœud technique. Nous n'écrivons rien nulle part.

Ici, nous avons un répéteur, nous n'écrivons rien non plus, car il n'y a pas de symbole de ce type dans le masque. Une telle règle ne peut être écrite.

Enfin, nous arrivons à une sorte de symbole de contenu.
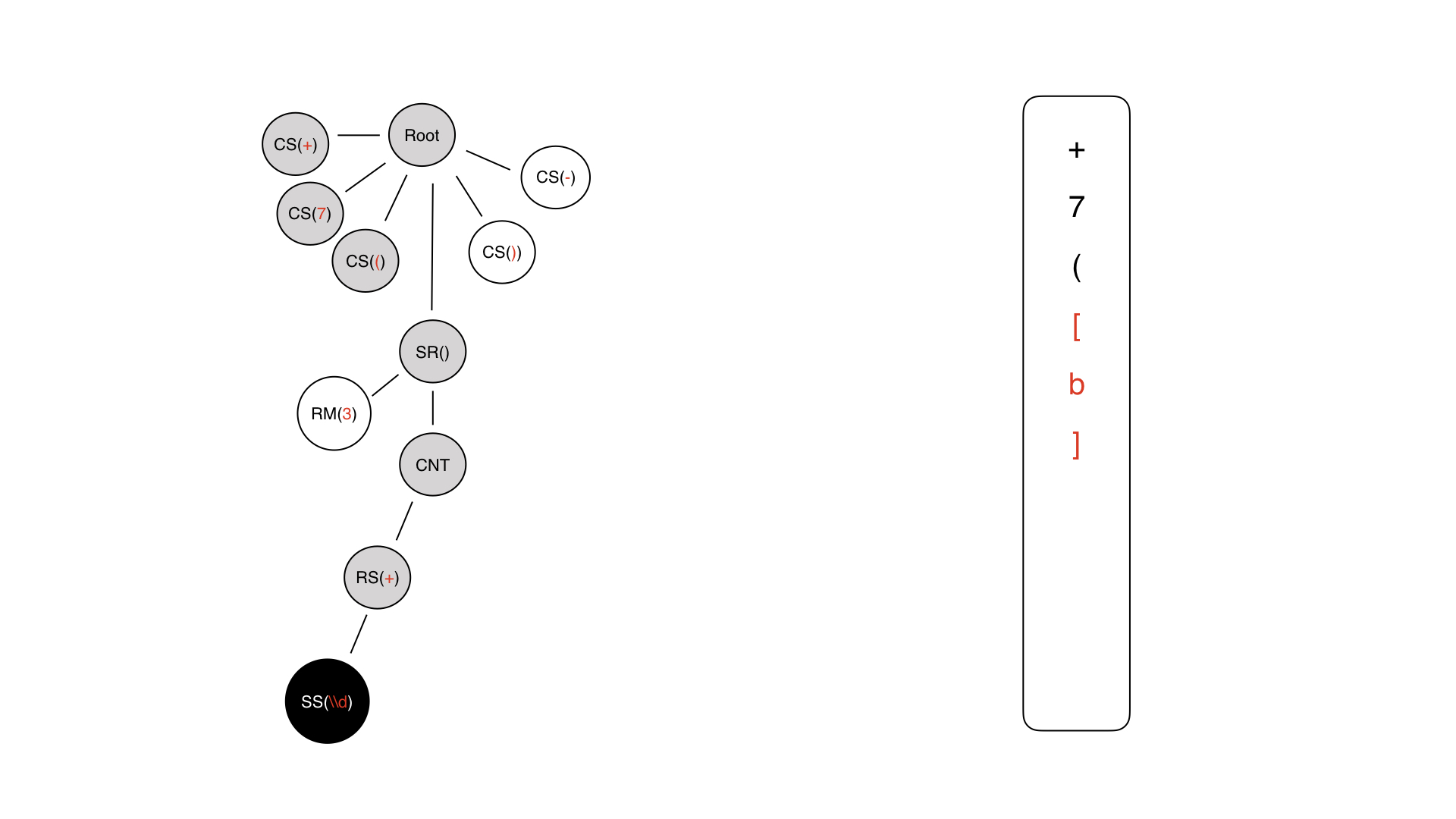
Le symbole de contenu peut être un symbole constant ou un symbole spécial. Dans ce cas, une charge spéciale est utilisée, car elle seule porte une sorte de charge sémantique pour l'entrée.
Nous l'avons donc écrit, nous revenons et partons juste pour les méta-informations.

Voyons que nous avions un répéteur là-bas et ici nous en avons 3 - une limite stricte. Par conséquent, nous le répétons trois fois et nous obtenons une pièce tellement dynamique. Ensuite, nous ajoutons nos symboles constants.

En conséquence, nous obtenons un masque qui ressemble à un masque au format robot.
En pratique, nous avons pris une grammaire et en avons généré une autre.
Règles de génération de grammaire côté client à partir du côté serveur
Maintenant, un peu sur les règles de génération. C'est important.
Il peut y avoir de tels cas difficiles: à l'intérieur de la partie dynamique, il y a plusieurs pièces différentes de DW. À l'intérieur des accolades: c'est la même chose que dans DV - l'un des nombreux. Voyons comment l'interprète gérera cette situation.

Vient d'abord le jeu de caractères, et nous devons le convertir en une sorte de notation en termes de InputMask. Pourquoi? Parce que c'est une sorte de jeu limité de caractères que nous devons faire correspondre. Nous devons combiner l'entrée utilisateur et le caractère, et par conséquent, nous aurons une notation spécifique écrite ici.
Ensuite, nous avons le caractère \\ d.
Suivant - DV avec une taille facultative.

Il s'avère que le premier est un personnage b. Il aura un jeu de caractères contenant abcd.
De plus, il est clair qu'il y aura déjà un symbole différent, car vous ne le corrigerez pas autrement, ou vous le corrigerez de manière incorrecte. Et puis cette expression se transforme en quelque chose comme ça.
La dernière partie doit contenir au moins un symbole. Désignons cette exigence par d. Mais aussi l'utilisateur peut entrer deux caractères supplémentaires, puis ils sont désignés comme DD.
Mettre tous ensemble.

Voici un exemple des jeux de caractères générés. On peut voir que b correspond au jeu de caractères abcd, pour les chiffres - le jeu de caractères prédéfini correspondant. Pour d et D, le jeu de caractères correspondant contient 12vf.
Résultat
Nous avons appris à convertir automatiquement une grammaire en une autre: désormais les masques selon les spécifications du serveur fonctionnent dans notre application.
Une autre fonctionnalité que nous avons obtenue gratuitement est la possibilité d'effectuer une analyse statique du masque qui nous est parvenu. Autrement dit, nous pouvons comprendre quel type de clavier est nécessaire pour ce masque et quel est le nombre maximum de caractères dans ce masque. Et c'est encore plus cool, car maintenant nous ne montrons pas le même clavier tout le temps pour chaque élément de formulaire - nous montrons le clavier requis sous l'élément de formulaire requis. Et nous pouvons également définir conditionnellement exactement qu'un champ est un champ d'entrée de téléphone.
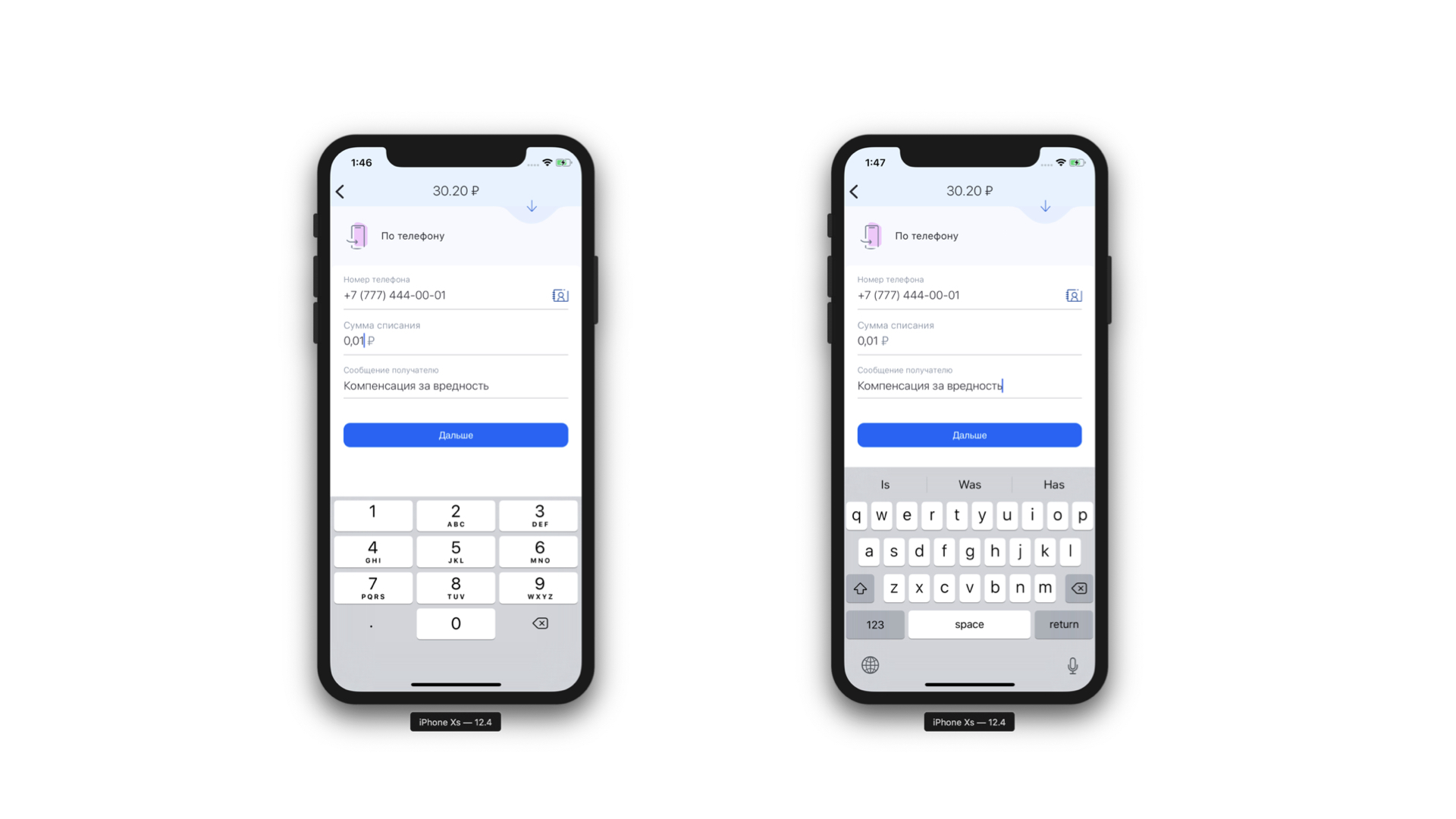
À gauche: en haut du champ de saisie du téléphone, il y a une icône (en fait un bouton) qui enverra l'utilisateur à la liste de contacts. À droite: exemple de clavier pour un message texte normal.
Bibliothèque de travail pour la traduction de masques
Vous pouvez voir comment nous avons mis en œuvre l'approche ci-dessus. La bibliothèque est située sur Github .
Exemples de traduction de différents masques
C'est le premier masque que nous avons examiné au tout début. Il est interprété dans cette représentation RedMadRobot.

Et ceci est le deuxième masque - juste un masque de saisie pour quelque chose. Il est converti en une telle représentation.
