L'histoire décrite n'est pas un fantasme, mais une description collective de quelques événements en 2020. Dans les grandes entreprises, un plan de reprise après sinistre (DRP) est toujours à portée de main pour ce cas. Dans les entreprises, les spécialistes de la continuité des affaires en sont responsables. Mais dans les moyennes et petites entreprises, la solution à ces problèmes incombe au service informatique. Vous devez comprendre vous-même la logique métier, comprendre ce qui peut tomber et où, trouver une protection et la mettre en œuvre.
C'est formidable si le professionnel de l'informatique parvient à négocier avec l'entreprise et à discuter du besoin de protection. Mais j'ai vu plus d'une fois comment l'entreprise a économisé sur une solution de reprise après sinistre (DR), car elle la considérait comme redondante. Lorsqu'un accident s'est produit, une longue reprise menaçait de pertes et l'entreprise n'était pas prête. Vous pouvez répéter autant que vous le souhaitez: «Mais je vous l'ai dit» - le service informatique devra encore restaurer les services.

Du point de vue d'un architecte, je vais vous dire comment éviter cette situation. Dans la première partie de l'article, je montrerai le travail préparatoire: comment discuter de trois questions avec le client pour le choix des outils de protection:
- Que protégeons-nous?
- De quoi protégeons-nous?
- À quel point protégeons-nous?
Dans la deuxième partie, nous parlerons des options pour répondre à la question: avec quoi défendre. Je vais donner des exemples de cas de la manière dont différents clients construisent leur protection.
Ce que nous protégeons: clarifier les fonctions métier critiques
Il est préférable de commencer la préparation en discutant du plan d'urgence avec le client professionnel. La principale difficulté ici est de trouver une langue commune. Le client ne se soucie généralement pas du fonctionnement de la solution informatique. Il se soucie de savoir si le service peut exécuter des fonctions commerciales et gagner de l'argent. Par exemple: si le site fonctionne et que le système de paiement «ment», il n'y a pas de reçus des clients, et les «extrêmes» sont toujours des informaticiens.
Un professionnel de l'informatique peut avoir des difficultés à négocier pour plusieurs raisons:
- Le service informatique n'a pas pleinement conscience du rôle du système d'information dans l'entreprise. Par exemple, s'il n'y a pas de description disponible des processus métier ou de modèle commercial transparent.
- Tout le processus ne dépend pas du service informatique. Par exemple, lorsque certains travaux sont effectués par des sous-traitants et que les informaticiens n'ont aucune influence directe sur eux.
Je structurerais la conversation comme ceci:
- Nous expliquons aux entreprises que les accidents arrivent à tout le monde et que le rétablissement prend du temps. Le mieux est de montrer la situation, comment elle se produit et quelles sont les conséquences possibles.
- Nous montrons que tout ne dépend pas du service informatique, mais vous êtes prêt à aider avec un plan d'action dans votre domaine de responsabilité.
- Nous demandons au client professionnel de répondre: si une apocalypse se produit, quel processus doit être restauré en premier? Qui y participe et comment?
L'entreprise a besoin d'une réponse simple, par exemple: il est nécessaire que le centre d'appels continue à enregistrer les applications 24 heures sur 24, 7 jours sur 7.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- Nous découvrons les points de défaillance possibles: les nœuds du système dont dépend la performance du service. Séparément, nous marquons les nœuds pris en charge par d'autres entreprises: opérateurs de télécommunications, fournisseurs d'hébergement, centres de données, etc. Avec cela, vous pouvez revenir au client professionnel pour l'étape suivante.
De quoi nous protégeons-nous: les risques
Ensuite, nous découvrons auprès du client professionnel les risques contre lesquels nous nous protégeons en premier lieu. Nous diviserons conditionnellement tous les risques en deux groupes:
- perte de temps due à une interruption de service;
- perte de données due à un impact physique, à des facteurs humains, etc.
Les entreprises ont peur de perdre à la fois des données et du temps - tout cela entraîne une perte d'argent. Encore une fois, nous posons des questions sur chaque groupe de risque:
- Pour ce processus, pouvons-nous estimer la valeur de la perte de données et du temps perdu?
- Quelles données ne pouvons-nous pas perdre?
- Où ne pouvons-nous pas autoriser les temps d'arrêt?
- Quels événements sont les plus probables et les plus menaçants pour nous?
Après discussion, nous comprendrons comment prioriser les points de défaillance.
Notre force de protection: RPO et RTO
Lorsque les points critiques de défaillance sont compris, nous calculons les métriques RTO et RPO.
Permettez-moi de vous rappeler que le RTO (objectif de temps de récupération) est le temps autorisé entre le moment de l'accident et la récupération complète du service. En langage professionnel, c'est le temps d'arrêt acceptable. Si nous savons combien d'argent le processus a rapporté, nous pouvons calculer les pertes de chaque minute d'arrêt et calculer la perte admissible.
RPO (objectif de point de récupération) est un point de récupération de données valide. Il détermine le temps pendant lequel nous pouvons perdre des données. D'un point de vue commercial, la perte de données peut entraîner, par exemple, des amendes. Ces pertes peuvent également être converties en argent.
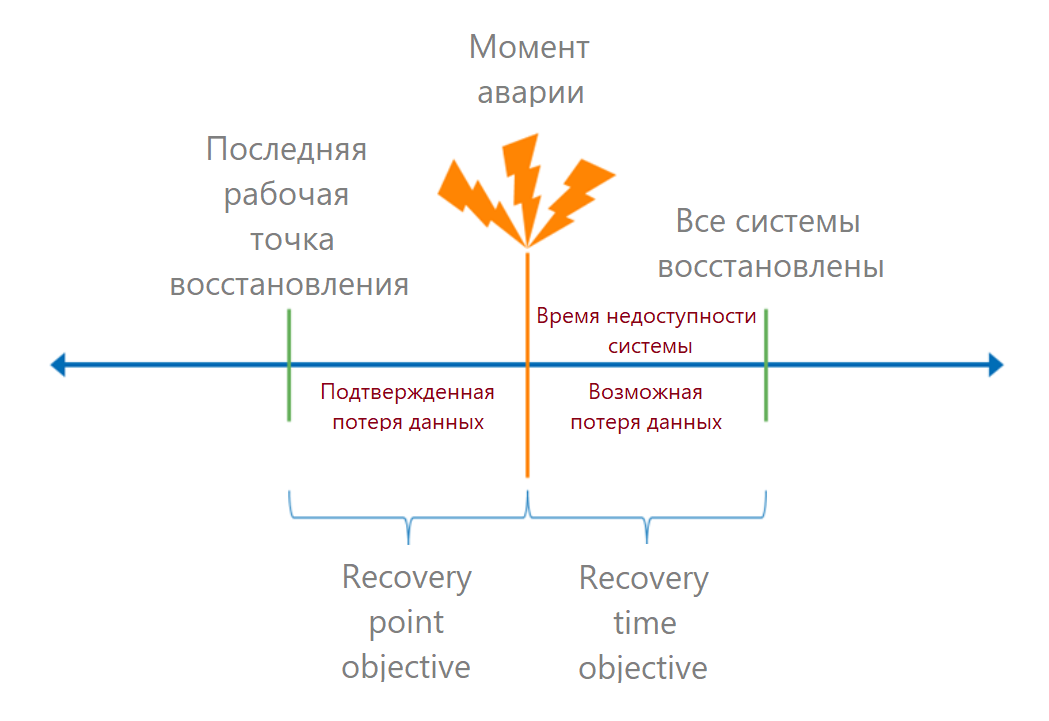
Le temps de récupération doit être calculé pour l'utilisateur final: combien de temps il faudra pour se connecter au système. Nous ajoutons donc d'abord les temps de récupération de tous les maillons de la chaîne. Ici, ils font souvent une erreur: ils prennent le RTO du fournisseur du SLA et oublient les autres termes.
Regardons un exemple spécifique. L'utilisateur entre 1C, le système s'ouvre avec une erreur de base de données. Il contacte l'administrateur système. La base est dans le cloud, l'administrateur système signale le problème au fournisseur de services. Disons que toutes les communications prennent 15 minutes. Dans le cloud, une base de données de cette taille sera restaurée à partir d'une sauvegarde en une heure, par conséquent, le RTO du côté du fournisseur de services prendra une heure. Mais ce n'est pas la date limite finale, car 15 minutes ont été ajoutées à l'utilisateur pour détecter le problème.Ces calculs montreront à l'entreprise de quels facteurs externes dépend la période de récupération. Par exemple, si le bureau est inondé, vous devez d'abord détecter la fuite et la réparer. Cela prendra du temps qui ne dépendra pas des TI.
Ensuite, l'administrateur système doit vérifier que la base de données est correcte, la connecter à 1C et démarrer les services. Cela prend une heure supplémentaire, ce qui signifie que le RTO du côté administrateur est déjà de 2 heures 15 minutes. L'utilisateur a besoin de 15 minutes supplémentaires: connectez-vous, vérifiez que les transactions nécessaires sont apparues. 2 heures 30 minutes est le temps de récupération total du service dans cet exemple.
Comment nous protégeons: choisir des outils pour différents risques
Après avoir discuté de tous les points, le client comprend déjà le coût de l'accident pour l'entreprise. Vous pouvez maintenant sélectionner des outils et discuter du budget. Je montrerai par des exemples de cas clients quels outils nous proposons pour différentes tâches.
Commençons par le premier groupe de risques: les pertes dues aux interruptions de service. Les solutions pour cette tâche devraient fournir un bon RTO.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
Toutes les solutions envisagées offrent une haute disponibilité, mais ne vous évitent pas de perdre des données en raison d'un virus de cryptage ou d'une erreur accidentelle d'un employé. Dans ce cas, nous avons besoin de sauvegardes qui fournissent le RPO requis.
5. N'oubliez pas les sauvegardes
Tout le monde sait que vous devez effectuer des sauvegardes, même si vous disposez de la solution de reprise après sinistre la plus cool. Je vais donc rappeler brièvement quelques points.
À proprement parler, la sauvegarde n'est pas DR. Et c'est pourquoi:
- Cela prend du temps. Si les données sont mesurées en téraoctets, la récupération prendra plus d'une heure. Vous devez restaurer, attribuer un réseau, vérifier ce qui s'allume, voir que les données sont en ordre. Vous ne pouvez donc obtenir un bon RTO que s'il y a peu de données.
- Les données peuvent ne pas être récupérées la première fois et vous devez prévoir du temps pour une seconde action. Par exemple, il y a des moments où nous ne savons pas exactement quand les données ont été perdues. Disons que la perte a été constatée à 15 heures et que des copies sont faites toutes les heures. À partir de 15h00, nous surveillons tous les points de récupération: 14h00, 13h00, etc. Si le système est critique, nous essayons de minimiser l'âge du point de restauration. Mais si les données nécessaires n'ont pas été trouvées dans la nouvelle sauvegarde, nous passons au point suivant - c'est du temps supplémentaire.
Cela étant dit, le calendrier de sauvegarde peut fournir le RPO requis . Pour les sauvegardes, il est important de prévoir une géo-redondance en cas de problème avec le site principal. Il est recommandé de conserver certaines des sauvegardes séparément.
Le plan de reprise après sinistre final doit inclure au moins 2 outils:
- L'une des options 1 à 4, qui protégera les systèmes des plantages et des plantages.
- Sauvegarde pour protéger les données contre la perte.
Il convient également de prévoir un canal de communication de secours en cas de panne du principal fournisseur Internet. Et voila! - Le DR sur les salaires minimums est déjà prêt.