Cet article est une traduction de l'un des articles de neptune.ai et met en évidence les outils d'apprentissage en profondeur les plus intéressants présentés lors de la conférence sur l' apprentissage automatique de l' ICLR 2020.

Où l'apprentissage profond avancé est-il créé et discuté?
L'un des principaux lieux de discussion sur le Deep Learning est ICLR - la principale conférence sur le Deep Learning, qui a eu lieu du 27 au 30 avril 2020. Avec plus de 5 500 participants et près de 700 présentations et conférences, c'est un grand succès pour un événement entièrement en ligne. Vous pouvez trouver des informations complètes sur la conférence ici , ici ou ici .
Les réunions sociales virtuelles ont été l'un des temps forts de l'ICLR 2020. Les organisateurs ont décidé de lancer un projet intitulé «Outils et pratiques open source dans la recherche DL de pointe». Le sujet a été choisi en raison du fait que la boîte à outils correspondante est une partie inévitable du travail d'un chercheur en apprentissage profond. Les progrès dans ce domaine ont conduit à la prolifération de grands écosystèmes (TensorFlow , PyTorch , MXNet), ainsi que des outils ciblés plus petits qui répondent aux besoins spécifiques des chercheurs.
Le but de l'événement mentionné était de rencontrer les créateurs et les utilisateurs d'outils open source, ainsi que de partager des expériences et des impressions au sein de la communauté Deep Learning. Au total, plus de 100 personnes ont été réunies, dont les principaux inspirateurs et porteurs de projet, auxquels nous avons accordé de courtes périodes pour présenter leur travail. Les participants et les organisateurs ont été surpris par la grande variété et la créativité des outils et bibliothèques présentés.
Cet article contient des projets lumineux présentés à partir d'une scène virtuelle.
Outils et bibliothèques
Voici huit outils qui ont été présentés à l'ICLR avec un aperçu détaillé des capacités.
Chaque section présente des réponses à un certain nombre de points de manière très succincte:
- Quel problème l'outil / la bibliothèque résout-il?
- Comment exécuter ou créer un cas d'utilisation minimal?
- Ressources externes pour une plongée plus approfondie dans la bibliothèque / l'outil.
- Profil des représentants du projet au cas où il y aurait une volonté de les contacter.
Vous pouvez accéder à une section spécifique ci-dessous ou simplement les parcourir un par un. Bonne lecture!
AmpliGraph
Sujet: Modèles d'intégration basés sur des graphes de connaissances.
Langage de programmation: Python
Par: Luca Costabello
Twitter | LinkedIn | GitHub | Les graphiques de connaissances de site Web
sont un outil polyvalent pour représenter des systèmes complexes. Qu'il s'agisse d'un réseau social, d'un ensemble de données bioinformatiques ou de données d'achat au détail, la modélisation des connaissances sous forme de graphique permet aux organisations d'identifier des connexions importantes qui seraient autrement négligées.
Révéler les relations entre les données nécessite des modèles d'apprentissage automatique spéciaux spécialement conçus pour travailler avec des graphiques.
AmpliGraphEst un ensemble de modèles d'apprentissage automatique sous licence par Apache2 pour extraire des incorporations à partir de graphes de connaissances. Ces modèles codent les nœuds et les arêtes du graphique sous forme vectorielle et les combinent pour prédire les faits manquants. Les incorporations de graphes sont utilisées dans des tâches telles que le haut du graphe de connaissances, la découverte de connaissances, le clustering basé sur des liens, etc.
AmpliGraph abaisse la barrière à l'entrée pour le sujet d'intégration de graphes pour les chercheurs en mettant ces modèles à la disposition des utilisateurs inexpérimentés. Tirant parti de l'API open source, le projet soutient une communauté de passionnés utilisant des graphiques dans l'apprentissage automatique. Le projet vous permet d'apprendre à créer et à visualiser des incorporations à partir de graphiques de connaissances basés sur des données du monde réel et à les utiliser dans les tâches d'apprentissage automatique ultérieures.
Pour commencer, vous trouverez ci-dessous un morceau de code minimal qui entraîne un modèle sur l'un des ensembles de données de référence et prédit les liens manquants:


AmpliGraph a été développé à l'origine chez Accenture Labs Dublin , où il est utilisé dans divers projets industriels.
Automunge
Plateforme de préparation de données tabulaires
Langage de programmation: Python
Publié par Nicholas Teague
Twitter | LinkedIn | GitHub | Site Web
AutomungeEst une bibliothèque Python pour aider à préparer des données tabulaires à utiliser dans l'apprentissage automatique. Grâce à la boîte à outils du package, de simples transformations pour la génération de fonctionnalités sont possibles pour normaliser, encoder et combler les lacunes. Les transformations sont appliquées au sous-échantillon d'apprentissage, puis appliquées de la même manière aux données du sous-échantillon de test. Les conversions peuvent être effectuées automatiquement, attribuées à partir d'une bibliothèque interne ou configurées de manière flexible par l'utilisateur. Les options de population incluent un «remplissage basé sur l'apprentissage automatique», dans lequel les modèles sont entraînés pour prédire les informations manquantes pour chaque colonne de données.
En termes simples:
automunge (.) Prépare les données tabulaires pour une utilisation dans l'apprentissage automatique,
postmunge (.)les données supplémentaires sont traitées séquentiellement et avec une grande efficacité.
Automunge est disponible pour l'installation via pip:

Après l'installation, importez simplement la bibliothèque dans Jupyter Notebook pour l'initialisation:

Pour traiter automatiquement les données d'un échantillon d'apprentissage avec des paramètres par défaut, il suffit d'utiliser la commande:

De plus, pour le traitement ultérieur des données du sous-échantillon de test, il suffit d'exécuter une commande à l'aide du dictionnaire postprocess_dict obtenu en appelant automunge (.) Ci-dessus:

Les paramètres assigncat et assigninfill de l'appel automunge (.) Peuvent être utilisés pour définir les détails de conversion et les types de données pour combler les lacunes. Par exemple, un ensemble de données avec les colonnes 'column1' et 'column2' peut être mis à l'échelle en fonction des valeurs minimales et maximales ('mnmx') avec ML-padding pour column1 et one-hot encoding ('text') avec padding basé sur la valeur la plus courante pour column2. Les données d'autres colonnes non spécifiées explicitement seront traitées automatiquement.

Site Web Ressources et Liens | GitHub | Brève présentation
DynaML
Apprentissage automatique pour le
langage de programmation Scala : Scala
Publié par: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML est une boîte à outils de recherche et d'apprentissage automatique basée sur Scala. Il vise à fournir à l'utilisateur un environnement de bout en bout qui peut aider à:
- développement / prototypage de modèles,
- travailler avec des pipelines encombrants et complexes,
- visualisation des données et des résultats,
- réutilisation du code sous forme de scripts et de notebooks.
DynaML exploite les atouts du langage et de l'écosystème Scala pour créer un environnement qui offre performances et flexibilité. Il est basé sur d'excellents projets tels que Ammonite scala, Tensorflow-Scala et la bibliothèque de calcul numérique hautes performances Breeze .
Le composant clé de DynaML est le REPL / shell, qui a la coloration syntaxique et un système avancé de saisie semi-automatique.
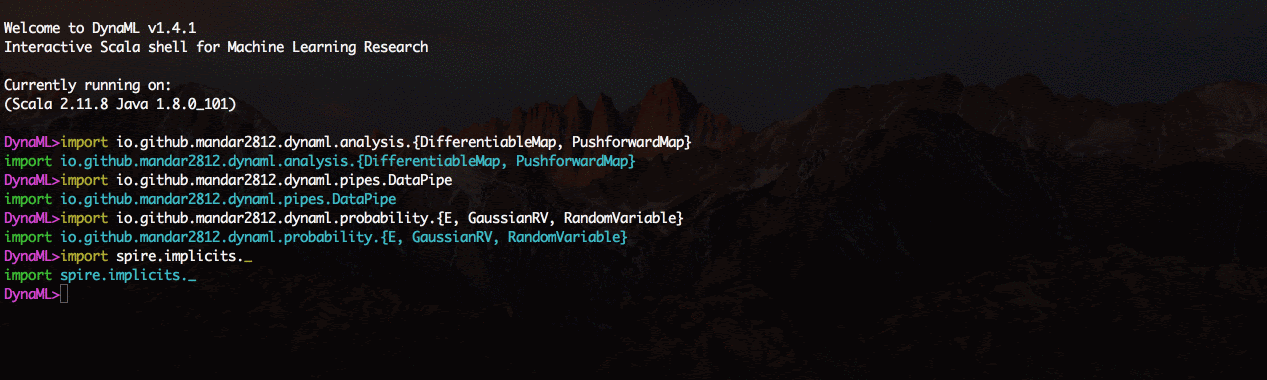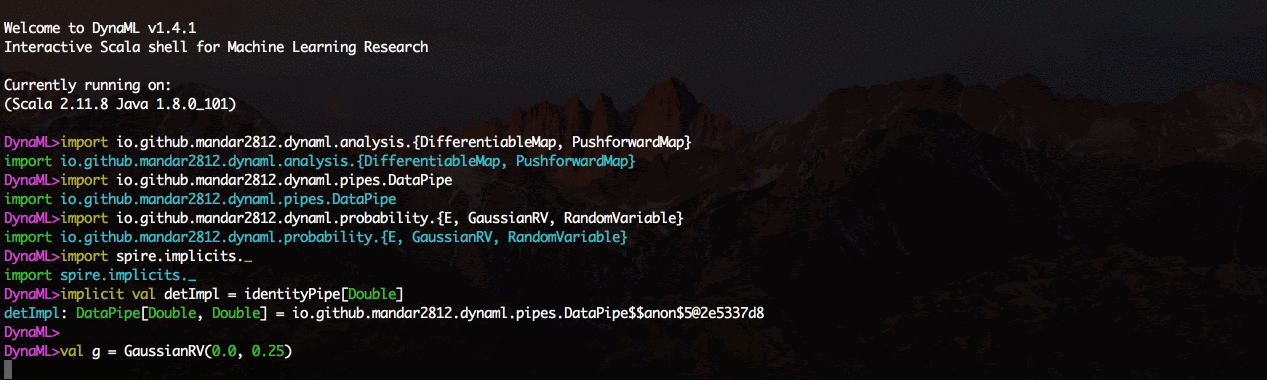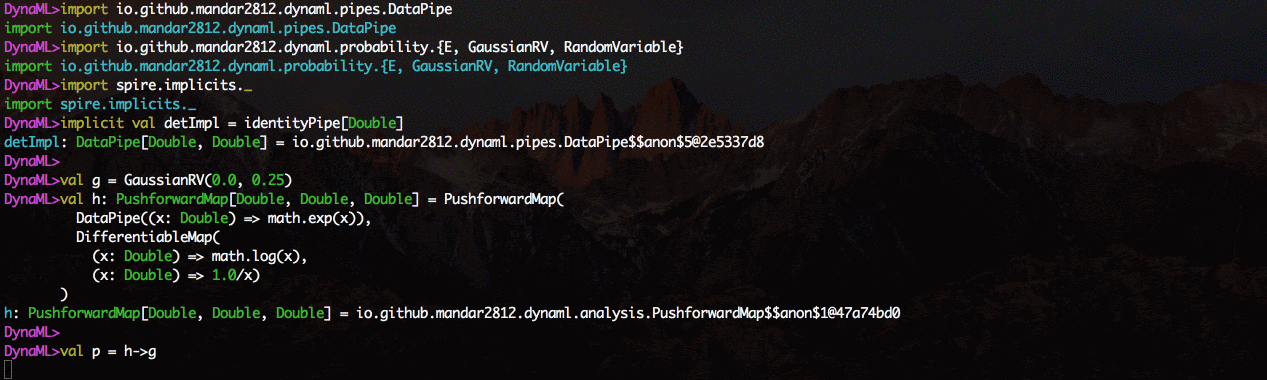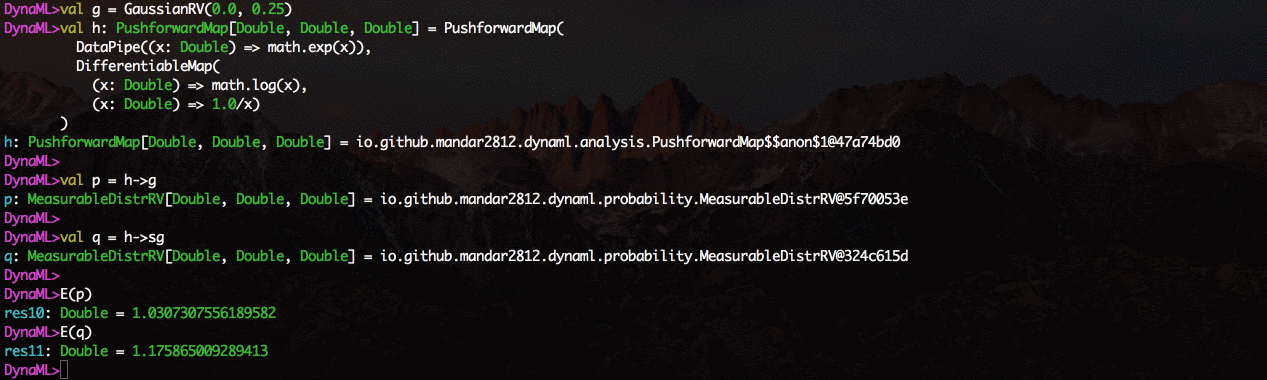
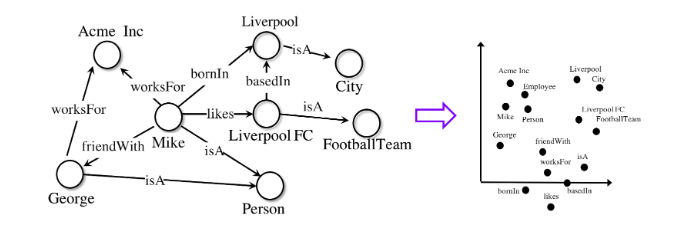
L'environnement est livré avec un support pour la visualisation 2D et 3D, les résultats peuvent être affichés directement à partir du shell de commande.

Le module de canaux de données facilite la création de pipelines de traitement de données de manière modulaire et conviviale. Créez des fonctions, encapsulez-les à l'aide du constructeur DataPipe et construisez des blocs fonctionnels à l'aide de l'opérateur>.
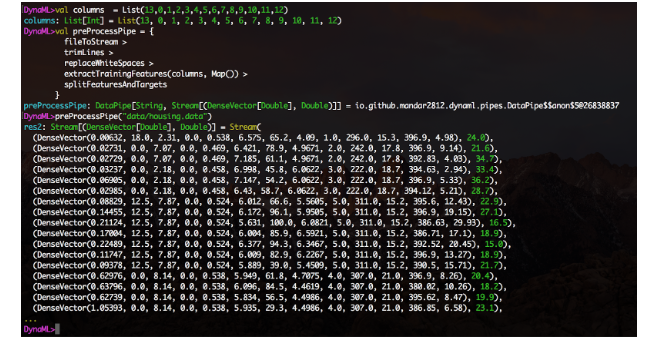
Une fonctionnalité expérimentale d'intégration de notebooks Jupyter est également disponible, et le répertoire notebooks du référentiel contient plusieurs exemples d'utilisation du noyau DynaML-Scala Jupyter.

Le Guide de l'utilisateur contient des références et une documentation complètes pour vous aider à maîtriser et à tirer le meilleur parti de l'environnement DynaML.
Voici quelques applications intéressantes qui mettent en évidence les points forts de DynaML:
- des réseaux de neurones inspirés par la physique pour résoudre l'équation de Burger et le système Fokker-Planck ,
- Formation en Deep Learning,
- Modèles de processus gaussiens pour la prévision de séries chronologiques autorégressives.
Ressources et liens
GitHub | Manuel d'utilisation
Hydre
Gestionnaire de configuration et de paramètres
Langage de programmation: Python
Publié par Omry Yadan
Twitter | GitHub
Développé par Facebook AI, Hydra est une plateforme Python qui simplifie le développement d'applications de recherche en offrant la possibilité de créer et de remplacer des configurations à l'aide de fichiers de configuration et de la ligne de commande. La plate-forme prend également en charge l'expansion automatique des paramètres, l'exécution à distance et en parallèle via des plug-ins, la gestion automatique du répertoire de travail et la suggestion dynamique d'options de complément en appuyant sur la touche TAB.
L'utilisation d'Hydra rend également votre code plus portable dans une variété d'environnements d'apprentissage automatique. Vous permet de basculer entre les postes de travail personnels, les clusters publics et privés sans changer votre code. Ce qui précède est réalisé grâce à une architecture modulaire.
Exemple de base
Cet exemple utilise une configuration de base de données, mais vous pouvez facilement la remplacer par des modèles, des ensembles de données ou tout ce dont vous avez besoin.
config.yaml:

my_app.py:

Vous pouvez remplacer n'importe quoi dans la configuration à partir de la ligne de commande:

Exemple de composition:
vous souhaiterez peut-être basculer entre deux configurations de base de données différentes.
Créez cette structure de répertoires:

config.yaml:
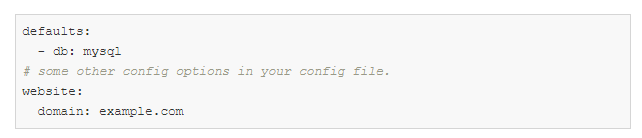
defaults est une directive spéciale qui dit à Hydra d'utiliser db / mysql.yaml lors de la composition d'un objet de configuration.
Vous pouvez maintenant choisir la configuration de base de données à utiliser, ainsi que remplacer les valeurs des paramètres à partir de la ligne de commande:

Consultez le tutoriel pour en savoir plus.
De plus, de nouvelles fonctionnalités intéressantes arrivent bientôt:
- configurations fortement typées (fichiers de configuration structurés),
- optimisation des hyperparamètres à l'aide des plugins Axe et Nevergrad,
- lancer AWS à l'aide du plug-in Ray launcher,
- lancement parallèle local via le plugin joblib et bien plus encore.
Larq
Langage de
programmation Binarized Neural Networks : Python
Publié par: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq est un écosystème de packages Python open source pour la création, la formation et le déploiement de réseaux de neurones binarisés (BNN). Les BNN sont des modèles d'apprentissage en profondeur dans lesquels les activations et les pondérations ne sont pas codées en utilisant 32, 16 ou 8 bits, mais en utilisant seulement 1 bit. Cela peut considérablement accélérer le temps d'inférence et réduire la consommation d'énergie, ce qui rend le BNN idéal pour les applications mobiles et périphériques.
L'écosystème open source Larq comprend trois composants principaux.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
Les auteurs du projet créent constamment des modèles plus rapides et étendent l'écosystème Larq à de nouvelles plates-formes matérielles et à des applications d'apprentissage en profondeur. Par exemple, des travaux sont actuellement en cours pour intégrer la quantification 8 bits de bout en bout afin de pouvoir former et déployer des combinaisons de réseaux binaires et 8 bits à l'aide de Larq. Site Web
Ressources et Liens | GitHub larq / larq | GitHub larq / zoo | GitHub larq / compute-engine | Manuels | Blog | Twitter
McKernel
Méthodes du noyau dans le
langage de programmation en temps linéaire logarithmique : C / C ++
Publié par: J. de Curtó i Díaz
Twitter | Site Web
La première bibliothèque C ++ open source fournissant à la fois une approximation aléatoire des méthodes du noyau et un cadre d'apprentissage profond à part entière.
McKernel propose quatre utilisations différentes.
- Code Hadamard open source autonome et ultra-rapide. À utiliser dans des domaines tels que la compression, le cryptage ou l'informatique quantique.
- Techniques nucléaires extrêmement rapides. Peut être utilisé partout où les méthodes SVM (méthode de vecteur de support: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) sont supérieurs au Deep Learning. Par exemple, certaines applications de robotique et certains cas d'utilisation de l'apprentissage automatique dans les soins de santé et dans d'autres domaines incluent l'apprentissage fédéré et la sélection de canaux.
- L'intégration du Deep Learning et des méthodes nucléaires permet le développement d'une architecture Deep Learning dans une direction a priori anthropomorphique / mathématique.
- Cadre de recherche Deep Learning pour résoudre un certain nombre de questions ouvertes en apprentissage automatique.
L'équation décrivant tous les calculs ressemble à ceci:

Ici, les auteurs, en tant que pionniers, ont utilisé le formalisme pour expliquer l'utilisation de symptômes aléatoires comme méthodes d' apprentissage profond et les techniques nucléaires . La base théorique est basée sur quatre géants: Gauss, Wiener, Fourier et Kalman. Les fondations en ont été posées par Rahimi et Rekht (NIPS 2007) et Le et al. (ICML 2013).
Cibler l'utilisateur type
Les principaux publics de McKernel sont des chercheurs et des praticiens dans les domaines de la robotique, de l'apprentissage automatique pour la santé, du traitement du signal et des communications qui ont besoin d'une mise en œuvre efficace et rapide en C ++. Dans ce cas, la plupart des bibliothèques Deep Learning ne remplissent pas les conditions données, car elles sont principalement basées sur des implémentations Python de haut niveau. En outre, le public peut être des représentants de la communauté plus large de l'apprentissage automatique et du Deep Learning, qui cherchent à améliorer l'architecture des réseaux de neurones à l'aide de méthodes nucléaires.
Un exemple visuel super simple pour exécuter une bibliothèque sans perdre de temps ressemble à ceci:

Et après?
Apprentissage de bout en bout, apprentissage auto-supervisé, méta-apprentissage, intégration avec des stratégies évolutives, réduction significative de l'espace de recherche avec NAS, ...
Ressources et liens
GitHub | Présentation complète
Moteur de formation SCCH
Routines d'automatisation pour le
langage de programmation Deep Learning : Python
Publié par: Natalya Shepeleva
Twitter | LinkedIn | Site Web
Développer un pipeline typique de Deep Learning est assez standard: prétraitement des données, conception / mise en œuvre de tâches, formation de modèles et évaluation des résultats. Néanmoins, de projet en projet, son utilisation nécessite la participation d'un ingénieur à chaque étape du développement, ce qui conduit à la répétition des mêmes actions, à la duplication de code et, au final, à des erreurs.
L'objectif du moteur de formation SCCH est d'unifier et d'automatiser le processus de développement Deep Learning pour les deux frameworks les plus populaires PyTorch et TensorFlow. L'architecture à entrée unique minimise le temps de développement et protège contre les bogues.
Pour qui?
L'architecture flexible du moteur de formation SCCH comporte deux niveaux d'expérience utilisateur.
Principale. À ce niveau, l'utilisateur doit fournir des données pour l'entraînement et écrire les paramètres d'apprentissage du modèle dans le fichier de configuration. Après cela, tous les processus, y compris le traitement des données, la formation des modèles et la validation des résultats, seront effectués automatiquement. Le résultat sera un modèle formé dans l'un des principaux cadres.
Avancée.Grâce au concept de composants modulaires, l'utilisateur peut modifier les modules en fonction de ses besoins, en déployant ses propres modèles et en utilisant diverses fonctions de perte et métriques de qualité. Cette architecture modulaire vous permet d'ajouter des fonctionnalités supplémentaires sans interférer avec le fonctionnement du pipeline principal.
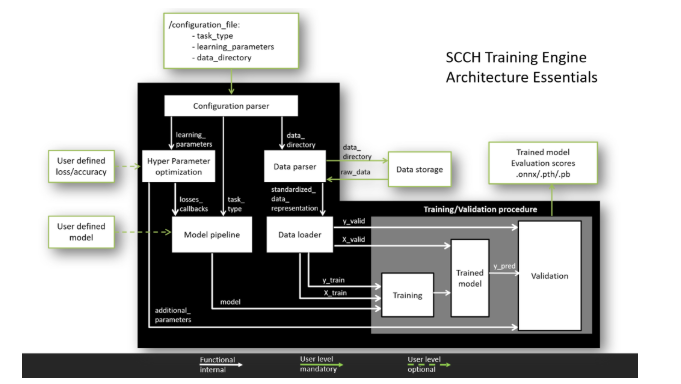
Que peut-il faire?
Capacités actuelles:
- travailler avec TensorFlow et PyTorch,
- un pipeline standardisé d'analyse des données de différents formats,
- un pipeline standardisé pour la formation des modèles et la validation des résultats,
- prise en charge des tâches de classification, de segmentation et de détection,
- support de validation croisée.
Fonctionnalités en cours de développement:
- recherche d'hyperparamètres de modèle optimaux,
- chargement de poids de modèle et formation à partir d'un point de contrôle spécifique,
- Prise en charge de l'architecture GAN.
Comment ça fonctionne?
Pour voir le moteur d'entraînement SCCH dans toute sa splendeur, vous devez suivre deux étapes.
- Copiez simplement le référentiel et installez les packages requis à l'aide de la commande: pip install requirements.txt.
- Exécutez python main.py pour voir une étude de cas MNIST avec traitement et formation sur un modèle LeNet-5.
Toutes les informations sur la création d'un fichier de configuration et l'utilisation des fonctionnalités avancées se trouvent sur la page GitHub .
Version stable avec les fonctionnalités principales: prévue pour fin mai 2020.
Ressources et liens
GitHub | Site Internet
Tokenizers
Text tokenizers
Langage de programmation: Rust avec l'API Python
Publié par: Anthony Mua
Twitter | LinkedIn | GitHub
huggingface / tokenizers fournit un accès aux tokenizers les plus modernes, en mettant l'accent sur les performances et l'utilisation polyvalente. Tokenizers vous permet de former et d'utiliser des tokenizers sans effort. Les Tokenizers peuvent vous aider, que vous soyez un érudit ou un praticien dans le domaine de la PNL.
Principales caractéristiques
- Vitesse extrême: la tokenisation ne devrait pas être un goulot d'étranglement dans votre pipeline et vous n'avez pas besoin de prétraiter vos données. Grâce à l'implémentation native de Rust, la tokenisation de gigaoctets de texte ne prend que quelques secondes.
- Offsets / Alignment: fournit un contrôle de décalage même lors du traitement de texte avec des procédures de normalisation complexes. Cela facilite l'extraction de texte pour des tâches telles que NER ou la réponse à des questions.
- Prétraitement: prend en charge tout prétraitement nécessaire avant d'alimenter des données dans votre modèle de langage (troncature, remplissage, ajout de jetons spéciaux, etc.).
- Facilité d'apprentissage: entraînez n'importe quel tokenizer sur un nouveau châssis. Par exemple, apprendre un tokenizer pour BERT dans une nouvelle langue n'a jamais été aussi simple.
- Multi-langues: un bundle avec plusieurs langues. Vous pouvez commencer à l'utiliser dès maintenant avec Python, Node.js ou Rust. Le travail dans ce sens continue!
Exemple:

Etc:
- sérialisation en un seul fichier et chargement en une seule ligne pour tout tokenizer,
- Prise en charge d'Unigram.
Hugging Face voit leur mission comme aider à promouvoir et démocratiser la PNL.
Ressources et liens
GitHub huggingface / transformers | GitHub huggingface / tokenizers | Twitter
Conclusion
En conclusion, il convient de noter qu'il existe un grand nombre de bibliothèques utiles pour le Deep Learning et l'apprentissage automatique en général, et il n'y a aucun moyen de les décrire toutes dans un seul article. Certains des projets décrits ci-dessus seront utiles dans des cas spécifiques, certains sont déjà bien connus et certains projets merveilleux, malheureusement, n'ont pas été inclus dans l'article. Chez CleverDATA,
nous nous efforçons de nous tenir au courant des nouveaux outils et des bibliothèques utiles, et d'appliquer activement de nouvelles approches dans notre travail lié à l'utilisation du Deep Learning et du Machine Learning. Pour ma part, je voudrais attirer l'attention des lecteurs sur ces deux bibliothèques qui ne sont pas incluses dans l'article principal, mais qui aident de manière significative à travailler avec les réseaux de neurones: Catalyst (https://catalyst-team.com ) et Albumentation ( https://albumentations.ai/ ).
Je suis sûr que chaque spécialiste en exercice a ses propres outils et bibliothèques préférés, y compris ceux qui sont peu connus d'un large public. S'il vous semble que des outils utiles dans votre travail ont été inutilement négligés, écrivez-les dans les commentaires: même les mentionner dans la discussion aidera les projets prometteurs à attirer de nouveaux adeptes, et l'augmentation de la popularité, à son tour, conduit à une amélioration des fonctionnalités et au développement d'eux-mêmes. bibliothèques.
Merci de votre attention et j'espère que l'ensemble de bibliothèques présenté vous sera utile dans votre travail!