introduction
Une fuite de mémoire est généralement appelée une situation où la quantité de mémoire occupée dans le tas augmente pendant le fonctionnement à long terme de l'application et ne diminue pas après l'arrêt du garbage collector. Comme vous le savez, la mémoire jvm est divisée en tas et pile. La pile stocke les valeurs des variables de types simples et des références aux objets dans le contexte du flux, et le tas stocke les objets eux-mêmes. Le tas contient également un espace appelé Metaspace, qui stocke des données sur les classes chargées et les données liées aux classes elles-mêmes, et non à leurs instances, en particulier les valeurs des variables statiques. Le Garbage Collector (ci-après GC), lancé périodiquement par la machine java, trouve dans le tas des objets qui ne sont plus référencés et libère la mémoire occupée par ces objets. Les algorithmes de travail GC sont différents et complexes, en particulier,la prochaine fois que le GC démarre, il n'examine pas le tas entier à chaque fois pour trouver des objets inutilisés, il ne vaut donc pas la peine de se fier au fait que tout objet inutilisé sera supprimé de la mémoire après un démarrage du GC, mais si la quantité de mémoire utilisée par l'application est stable grandit sans raison apparente pendant longtemps, alors il est temps de réfléchir à ce qui aurait pu conduire à une telle situation.
Le jvm comprend un utilitaire multifonctionnel Visual VM (ci-après dénommé VM). VM permet d'observer visuellement la dynamique des indicateurs clés de jvm dans les graphiques, en particulier, la quantité de mémoire libre et occupée dans le tas, le nombre de classes chargées, de threads, etc. En outre, à l'aide de la machine virtuelle, vous pouvez effectuer et examiner les vidages de mémoire. Bien sûr, la machine virtuelle permet également le vidage de threads et le profilage d'applications, mais une vue d'ensemble de ces fonctionnalités dépasse le cadre de cet article. Tout ce dont nous avons besoin de la machine virtuelle dans cet exemple est de se connecter à la machine virtuelle et d'examiner d'abord l'image générale de l'utilisation de la mémoire. Je tiens à noter que pour connecter une VM à un serveur distant, les paramètres jmxremote doivent être configurés dessus, car la connexion se fait via jmx.Pour une description de ces paramètres, vous pouvez vous référer à la documentation officielle d'Oracle ou à de nombreux articles sur Habré.
Supposons donc que nous nous soyons connectés avec succès au serveur d'applications à l'aide de la machine virtuelle et examinons les graphiques.
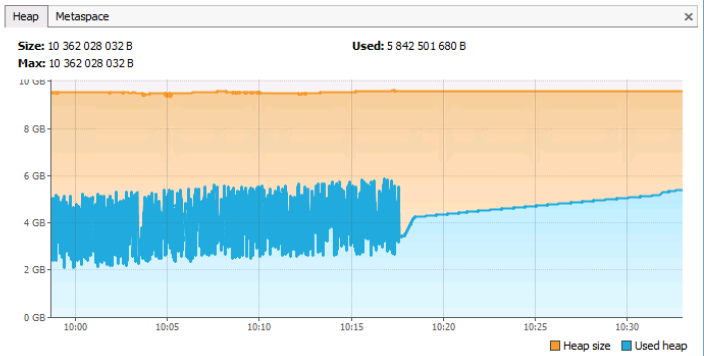
Sur l'onglet Heap, vous pouvez voir la mémoire totale et utilisée de jvm. Il est à noter que cet onglet prend également en compte la mémoire de type Metaspace (enfin, comment, car c'est aussi un tas). L'onglet Metaspace affiche uniquement des informations sur la mémoire occupée par les métadonnées (par les classes elles-mêmes et les objets qui leur sont liés).
En regardant le graphique, nous pouvons voir que la mémoire totale du tas est d'environ 10 Go, l'espace occupé actuel est d'environ 5,8 Go. Les crêtes dans le graphique correspondent aux appels GC, une ligne presque droite (pas de crêtes) commençant vers 10:18 peut (mais pas nécessairement!) Indiquer que le serveur d'application n'a pratiquement pas fonctionné depuis, car il n'y avait pas d'allocation et de libération actives Mémoire. En général, ce graphe correspond au fonctionnement normal du serveur d'application (si, bien sûr, pour juger le travail uniquement à partir de la mémoire). Le tracé du problème serait celui où une ligne bleue horizontale droite sans arêtes serait à peu près à la ligne orange, qui représente la quantité maximale de mémoire dans le tas.
Jetons maintenant un œil à un autre graphique.
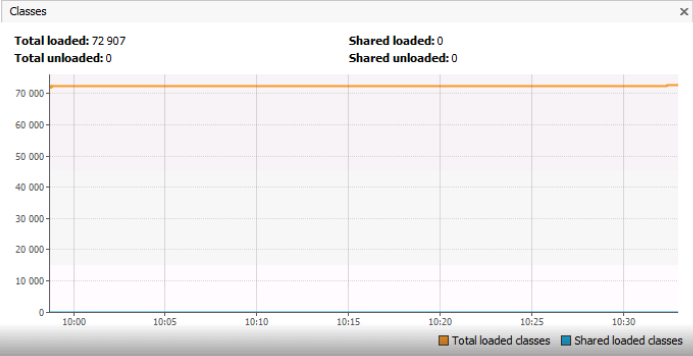
Nous arrivons ici directement à l'analyse de l'exemple, qui est le sujet principal de cet article. Le graphique Classes montre le nombre de classes chargées dans Metaspace, et il est d'environ 73 000 objets. Je voudrais attirer votre attention sur le fait que nous ne parlons pas d'instances de classe, mais des classes elles-mêmes, c'est-à-dire des objets de type Class <?>. Le graphique n'indique pas clairement combien d'instances de chaque type individuel ClassA ou ClassB sont chargées en mémoire. Peut-être que le nombre de classes identiques de type ClassA se multiplie pour une raison quelconque? Je dois dire que dans l'exemple qui sera décrit ci-dessous, 73 000 classes uniques étaient une situation tout à fait normale.
Le fait est que dans l'un des projets auxquels l'auteur de cet article a participé, un mécanisme a été développé pour la description universelle des entités du domaine (comme dans 1C) appelé système de dictionnaire, et des analystes qui personnalisent le système pour un client spécifique ou pour un domaine d'activité spécifique, a eu l'opportunité, via un éditeur spécial, de modéliser un business model en créant de nouvelles entités existantes évolutives, opérant non pas au niveau des tables, mais avec des concepts tels que "Document", "Compte", "Employé", etc. Le noyau système créait des tables dans un SGBD relationnel pour les données d'entité, et plusieurs tables pouvaient être créées pour chaque entité, puisque le système universel permettait historiquement de stocker des valeurs d'attribut et bien plus encore nécessitant la création de tables de service supplémentaires dans la base de données.
Je crois que ceux qui ont dû travailler avec des frameworks ORM ont déjà deviné de quoi parlait l'auteur, distraits du sujet principal de l'article en parlant de tableaux. Le projet utilisait Hibernate et pour chaque table, il devait y avoir une classe de bean Entity. Dans le même temps, puisque de nouvelles tables ont été créées dynamiquement pendant le travail du système par les analystes, les classes de bean Hibernate ont été générées, et non écrites manuellement par les développeurs. Et avec chaque génération suivante, environ 50 à 60 000 nouvelles classes ont été créées. Il y avait beaucoup moins de tables dans le système (environ 5 à 6 000), mais pour chaque table, non seulement la classe de bean Entity a été générée, mais également de nombreuses classes auxiliaires, ce qui a finalement conduit à un chiffre commun.
Le mécanisme de travail était le suivant. Au début du système, les classes de bean Entity et les classes auxiliaires (ci-après simplement les classes de bean) ont été générées sur la base des métadonnées de la base de données. Lorsque le système était en cours d'exécution, la fabrique de sessions Hibernate créait des sessions, les sessions créaient des instances d'objets de classe bean. Lors de la modification de la structure (ajout, modification de tables), les classes de bean ont été régénérées et une nouvelle fabrique de session a été créée. Après la régénération, la nouvelle fabrique a créé de nouvelles sessions qui utilisaient les nouvelles classes de bean, l'ancienne usine et les sessions ont été fermées, et les anciennes classes de bean ont été déchargées par le GC, puisqu'elles n'étaient plus référencées à partir des objets d'infrastructure Hibernate.
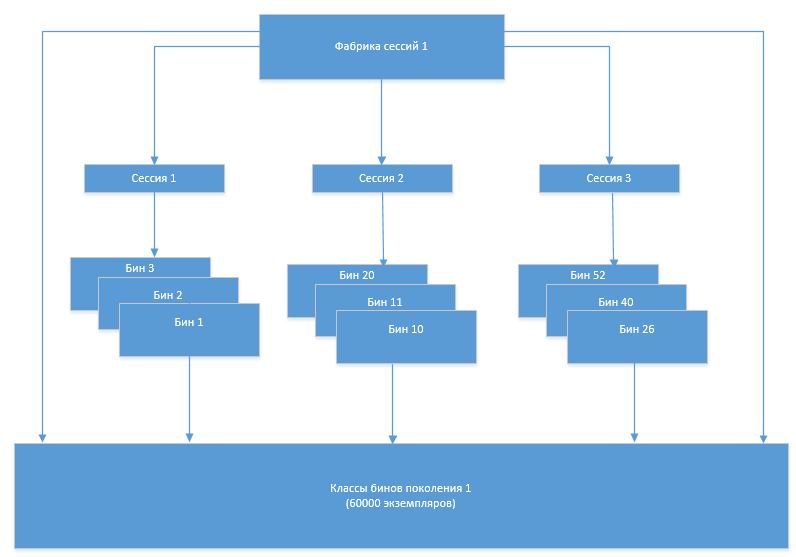
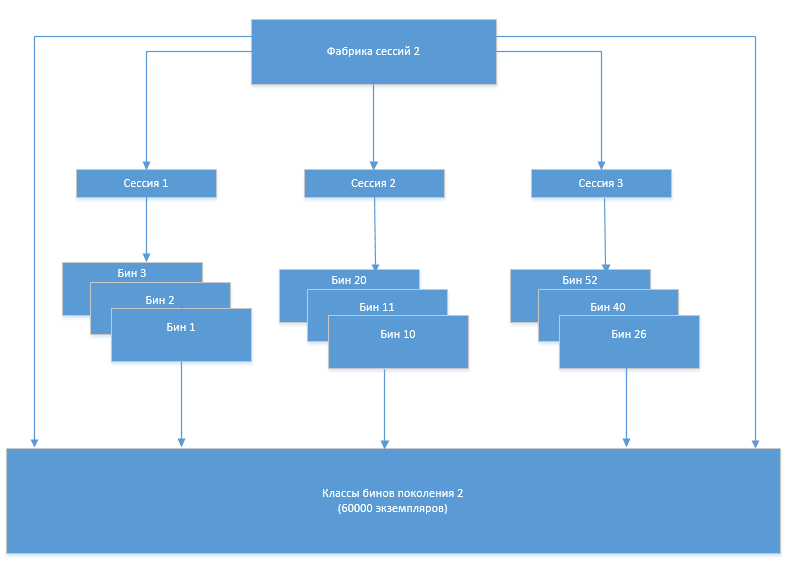
À un moment donné, un problème est survenu: le nombre de classes de casiers a commencé à augmenter après chaque régénération suivante. De toute évidence, cela était dû au fait que l'ancien ensemble de classes, qui ne devrait plus être utilisé, pour une raison quelconque, n'était pas déchargé de la mémoire. Afin de comprendre les raisons de ce comportement du système, l'analyseur de mémoire Eclipse (MAT) est venu à notre aide.
Trouver une fuite de mémoire
MAT est capable de travailler avec des vidages de mémoire, y trouvant des problèmes potentiels, mais vous devez d'abord obtenir ce vidage de mémoire, mais dans des environnements réels, il existe certaines nuances avec l'obtention d'un vidage.
Suppression d'une image mémoire
Comme mentionné ci-dessus, le vidage de la mémoire peut être supprimé directement de la VM en appuyant sur le bouton
But, en raison de la grande taille du vidage, la VM peut tout simplement ne pas faire face à cette tâche, se figeant un certain temps après avoir appuyé sur le bouton Heap Dump. De plus, ce n'est pas du tout un fait qu'il sera possible de se connecter via jmx au serveur d'application produit requis pour la VM. Dans ce cas, un autre utilitaire jvm appelé jMap vient à notre secours. Il s'exécute en ligne de commande, directement sur le serveur sur lequel jvm est en cours d'exécution, et vous permet de définir des paramètres de vidage supplémentaires:
jmap -dump: live, format = b, file = / tmp / heapdump.bin 14616
Le paramètre –dump: live est extrêmement important, car vous permet de réduire considérablement sa taille, en excluant les objets qui ne sont plus référencés.
Une autre situation courante est lorsque le vidage manuel n'est pas possible en raison du fait que jvm se plante avec une OutOfMemoryError. Dans cette situation, l'option -XX: + HeapDumpOnOutOfMemoryError vient à la rescousse et, en plus de cela, -XX: HeapDumpPath , qui vous permet de spécifier le chemin vers le vidage capturé.
Ensuite, ouvrez le vidage capturé à l'aide de l'analyseur de mémoire Eclipse. Le fichier peut être volumineux (plusieurs gigaoctets), vous devez donc fournir suffisamment de mémoire dans le fichier
MemoryAnalyzer.ini : -Xmx4096m
Localisation du problème à l'aide de MAT
Alors, considérons une situation où le nombre de classes chargées augmente de multiples par rapport au niveau initial et ne diminue pas même après un appel forcé au garbage collection (cela peut être fait en appuyant sur le bouton correspondant dans la VM).
Ci-dessus, le processus de régénération des classes de haricots et leur utilisation ont été décrits conceptuellement. Sur un plan plus technique, cela ressemblait à ceci:
- Toutes les sessions Hibernate sont fermées (classe SessionImpl)
- L'ancienne fabrique de session (SessionFactoryImpl) est fermée et la référence à celle-ci à partir du LocalSessionFactoryBean est réinitialisée
- ClassLoader est recréé
- Les références aux anciennes classes de bean dans la classe du générateur sont annulées
- Les classes de haricots sont régénérées
En l'absence de références aux anciennes classes de bean, le nombre de classes ne doit pas augmenter après le garbage collection.
Exécutez MAT et ouvrez le fichier d'image mémoire précédemment obtenu. Après avoir ouvert le vidage, MAT affiche les plus grandes chaînes d'objets en mémoire.
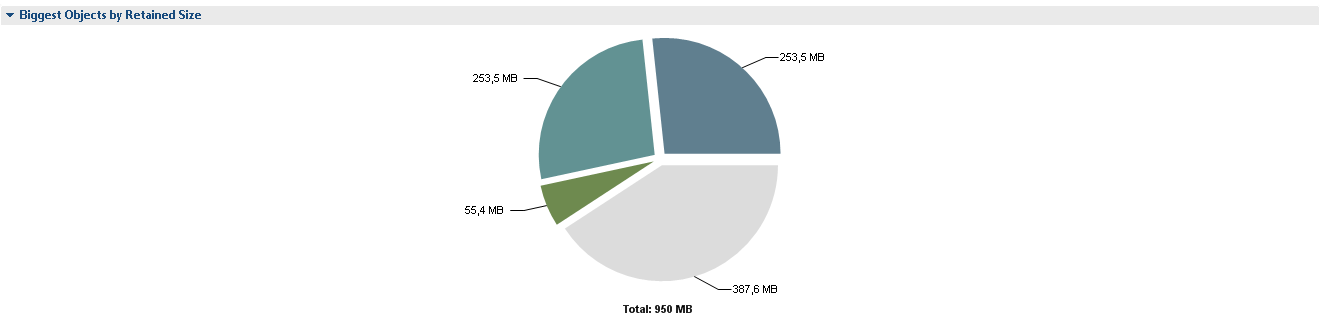
Après avoir cliqué sur Leak Suspects, nous voyons les détails:
2 segments d'un cercle de 265 M chacun sont 2 instances de SessionFactoryImpl. On ne sait pas pourquoi il y en a 2 instances et, très probablement, chacune des instances contient des références à l'ensemble complet des classes de bean Entity. MAT nous informe des problèmes potentiels comme suit.

Je constate tout de suite que le problème suspect 3 n'est pas vraiment un problème. Le projet a implémenté un analyseur de son propre langage, qui est un add-on multiplateforme sur SQL et vous permet d'opérer non pas avec des tables, mais avec des entités système, et 121M occupe son cache de requêtes.
Revenons à deux instances de SessionFactoryImpl. Cliquez sur Duplicate Classes et voyez qu'il y a vraiment 2 instances de chaque classe de bean Entity. Autrement dit, les liens vers les anciennes classes des beans Entity restent et, très probablement, ce sont des liens de SesssionFactoryImpl. Sur la base du code source de cette classe, les références aux classes de bean doivent être stockées dans le champ classMetaData.
Cliquez sur Problème Suspect 1, puis sur la classe SessionFactoryImpl et sélectionnez List Objects-> With Outgouing References dans le menu contextuel. De cette façon, nous pouvons voir tous les objets référencés par SessionFactoryImpl.
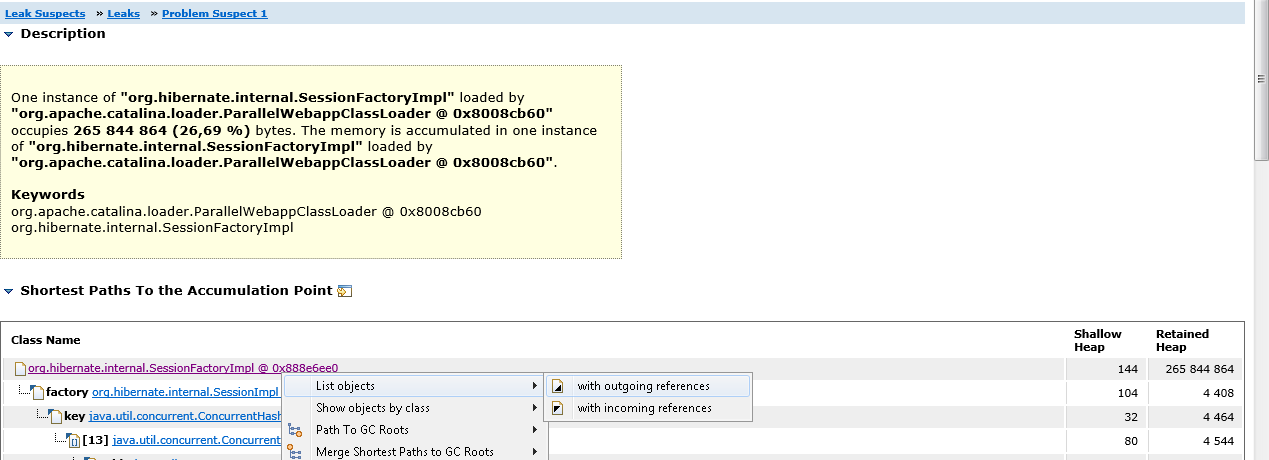
Nous développons l'objet classMetaData et nous nous assurons qu'il stocke réellement un tableau de classes de beans Entity.
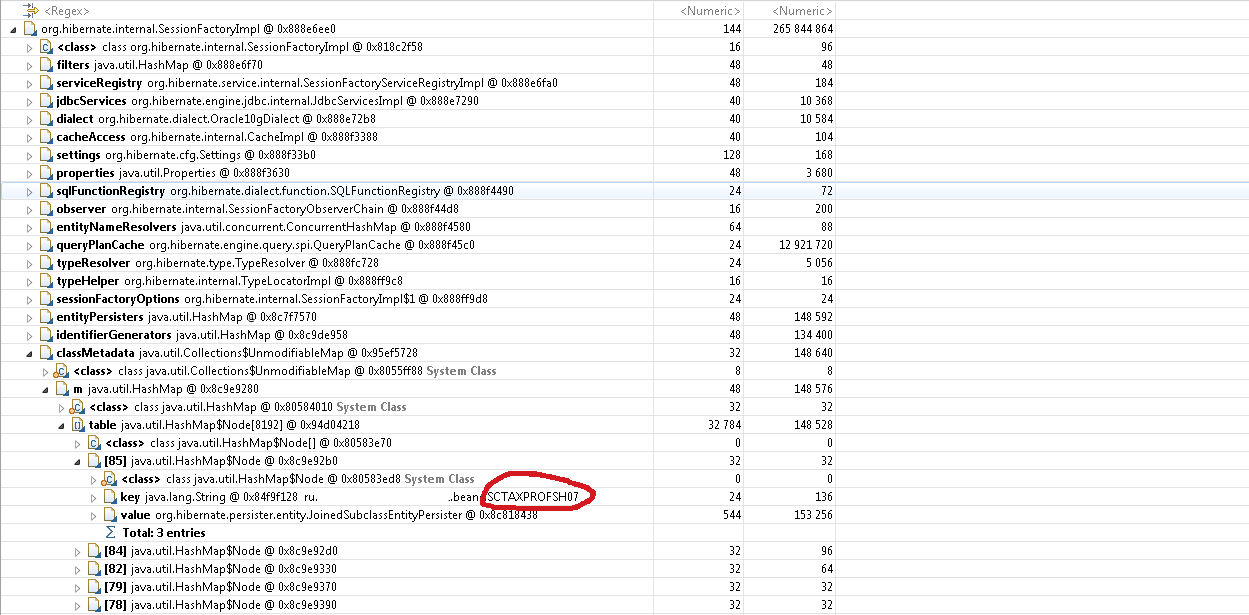
Nous devons maintenant comprendre ce qui empêche le garbage collector de supprimer une seule instance de SessionFactoryImpl. Si nous retournons à Leak Suspects-> Leaks-> Problem Suspect 1, nous verrons une pile de liens menant à un lien vers SessionFactoryImpl.
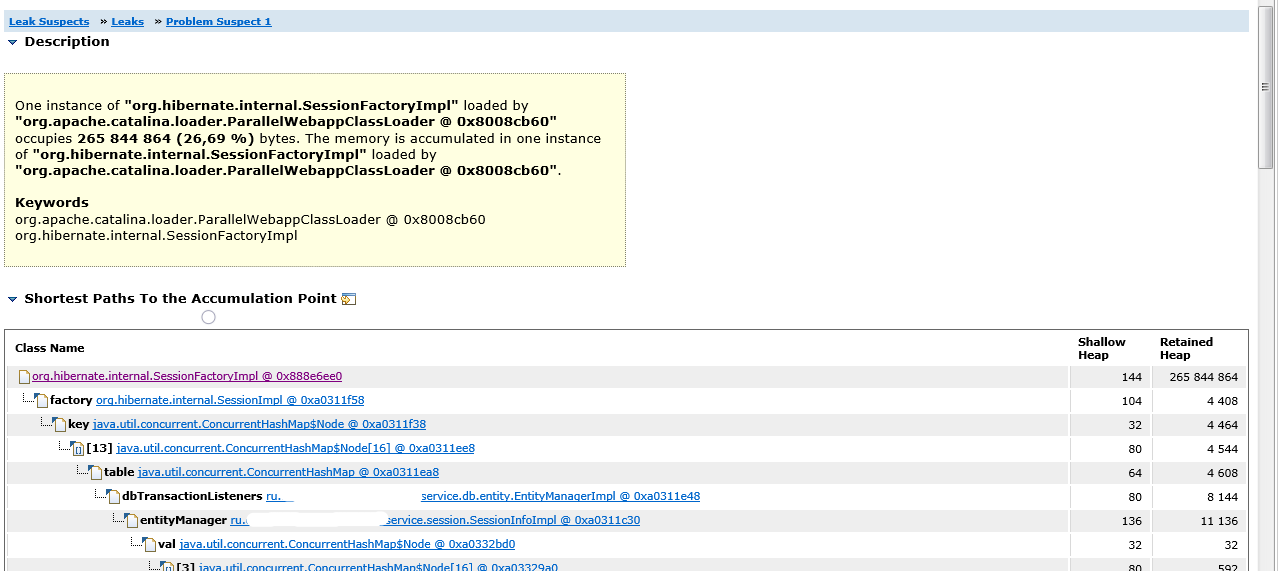
Nous voyons que la variable entityManager du bean SessionInfoImpl contenant le contexte de la session HTTP contient un tableau dbTransactionListeners qui utilise les objets Hibernate SessionImpl comme clés, et les sessions font référence à SessionFactoryImpl.
Le fait est que les objets de session étaient mis en cache dans dbTransactionListeners à certaines fins, et avant que les classes de bean ne soient régénérées, les références à eux pouvaient rester dans ce tableau. Les sessions, à leur tour, référencaient la fabrique de sessions, qui stockait un tableau de références à toutes les classes de bean. De plus, les sessions conservaient des références à des instances de classes d'entités et faisaient référence aux classes de bean elles-mêmes.
Ainsi, le point d'entrée du problème a été trouvé. Il s'est avéré qu'il s'agissait de références à d'anciennes sessions de dbTransactionListeners. Une fois l'erreur corrigée et le tableau dbTransactionListeners commencé à être effacé, le problème a été résolu.
Caractéristiques de l'analyseur de mémoire Eclipse
Ainsi, Eclipse Memory Analyzer vous permet de:
- Découvrez quelles chaînes d'objets occupent le maximum de mémoire et déterminez les points d'entrée dans ces chaînes (Leak Suspects)
- Afficher une arborescence de toutes les références d'objets entrants (Chemins les plus courts vers le point d'accumulation)
- Afficher l'arborescence de toutes les références de sortie d'un objet (Objet-> Liste des objets-> Avec références de sortie)
- Voir les classes en double chargées par différents ClassLoaders (classes en double)