
Imaginez un journal de 2,5 gigaoctets après une compilation échouée. Cela fait trois millions de lignes. Vous recherchez un bug ou une régression qui apparaît sur la millionième ligne. Il est probablement tout simplement impossible de trouver une de ces lignes manuellement. Une option est une différence entre les dernières versions réussies et échouées dans l'espoir que le bogue écrit des lignes inhabituelles dans les journaux. La solution de Netflix est plus rapide et plus précise que LogReduce - sous la coupe.
Netflix et la ligne dans la pile de journaux
Le diff standard md5 est rapide, mais il imprime au moins des centaines de milliers de lignes candidates pour la visualisation car il montre les différences de lignes. Une variante de logreduce est un diff flou utilisant une recherche de k-plus proche voisin qui trouve environ 40 000 candidats, mais cela prend une heure. La solution ci-dessous trouve 20 000 chaînes candidates en 20 minutes. Grâce à la magie de l'open source, il ne s'agit que d'une centaine de lignes de code Python.
Solution - une combinaison de représentations vectorielles de mots qui codent les informations sémantiques des mots et des phrases, et un hachage basé sur l'emplacement(LSH - Local Sensitive Hash), qui distribue efficacement des éléments approximativement proches dans certains groupes et des éléments distants dans d'autres groupes. La combinaison de représentations vectorielles des mots et LSH est une excellente idée moins de dix ans il y a .
Remarque: nous avons exécuté Tensorflow 2.2 sur le processeur et avec une exécution immédiate pour l'apprentissage par transfert et scikit-learnNearestNeighborpour les k voisins les plus proches. Il existe des implémentations sophistiquées du plus proche voisin approximatif qui seraient meilleures pour résoudre le problème du plus proche voisin basé sur un modèle.
Représentation de mots vectoriels: qu'est-ce que c'est et pourquoi?
Construire un sac de mots avec k catégories (encodage k-hot, une généralisation de l'encodage unitaire) est un point de départ typique (et utile) pour les problèmes de déduplication, de recherche et de similitude entre le texte non structuré et semi-structuré. Ce type de sac de codage de mots ressemble à un dictionnaire avec des mots individuels et leur nombre. Exemple avec la phrase "log in error, check log".
{"log": 2, "in": 1, "error": 1, "check": 1}
Ce codage est également représenté par un vecteur, où l'index correspond à un mot et la valeur correspond au nombre de mots. Ci-dessous, la phrase «log in error, check log» comme vecteur, où la première entrée est réservée pour compter les mots «log», la seconde pour compter les mots «in», et ainsi de suite:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Remarque: le vecteur est composé de nombreux zéros. Les zéros sont tous les autres mots du dictionnaire qui ne figurent pas dans cette phrase. Le nombre total d'entrées vectorielles possibles, ou la dimension d'un vecteur, est la taille du vocabulaire de votre langue, qui est souvent des millions de mots ou plus, mais compressé à des centaines de milliers avec des astuces intelligentes .
Regardons le dictionnaire et les représentations vectorielles de l'expression "problème d'authentification". Les mots correspondant aux cinq premières entrées vectorielles n'apparaissent pas du tout dans la nouvelle phrase.
{"problem": 1, "authenticating": 1}
Il s'avère:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
Les phrases «problème d'authentification» et «erreur de connexion, journal de vérification» sont sémantiquement similaires. Autrement dit, ils sont essentiellement les mêmes, mais lexicalement aussi différents que possible. Ils n'ont pas de mots communs. En termes de diff flou, on pourrait dire qu'ils sont trop similaires pour les distinguer, mais l'encodage md5 et le document traité par k-hot avec kNN ne le supportent pas.
La réduction de dimension utilise une algèbre linéaire ou des réseaux de neurones artificiels pour placer des mots, des phrases ou des lignes de log sémantiquement similaires les uns à côté des autres dans un nouvel espace vectoriel. Des représentations vectorielles sont utilisées. Dans notre exemple, "log in error, check log" peut avoir un vecteur à cinq dimensions pour représenter:
[0.1, 0.3, -0.5, -0.7, 0.2]
L'expression "problème d'authentification" peut être
[0.1, 0.35, -0.5, -0.7, 0.2]
Ces vecteurs sont proches les uns des autres en termes de mesures telles que la similarité cosinus , par opposition à leurs vecteurs wordbag. Les vues denses de petite taille sont vraiment utiles pour les documents courts comme les lignes d'assemblage ou le syslog.
En fait, vous remplaceriez des milliers ou plus des dimensions du dictionnaire par une représentation à 100 dimensions riche en informations (et non en cinq). Les méthodes modernes de réduction de dimensionnalité comprennent la décomposition de la valeur singulière du mot matrice de co-occurrence ( GANT ) et les réseaux de neurones spécialisés ( word2vec , BERT , Elmo ).
Qu'en est-il du clustering? Revenons au journal de construction
Nous plaisantons en disant que Netflix est un service de production de journaux qui diffuse parfois des vidéos. Journalisation, diffusion en continu, gestion des exceptions - ce sont des centaines de milliers de requêtes par seconde. Par conséquent, la mise à l'échelle est nécessaire lorsque nous voulons appliquer le ML appliqué dans la télémétrie et la journalisation. Pour cette raison, nous faisons attention à la mise à l'échelle de la déduplication de texte, à la recherche de similitudes sémantiques et à la détection des valeurs aberrantes de texte. Lorsque les problèmes commerciaux sont résolus en temps réel, il n'y a pas d'autre moyen.
Notre solution consiste à représenter chaque ligne dans un vecteur de faible dimension et éventuellement à «affiner» ou à mettre à jour simultanément le modèle incorporé, à l'attribuer à un cluster et à définir les lignes dans différents clusters comme «différentes». Hachage sensible à l'emplacement- un algorithme probabiliste qui vous permet d'assigner des clusters en temps constant et de rechercher les voisins les plus proches en temps presque constant.
LSH fonctionne en mappant une représentation vectorielle à un ensemble de scalaires. Les algorithmes de hachage standard ont tendance à éviter les collisions entre deux entrées correspondantes. LSH cherche à éviter les collisions si les entrées sont éloignées et les favorise si elles sont différentes mais proches les unes des autres dans l'espace vectoriel.
Le vecteur représentant la phrase «log in error, check error» peut être mis en correspondance avec un nombre binaire
01. Puis01représente un cluster. Le vecteur "problème d'authentification" avec une probabilité élevée peut également être affiché dans 01. Ainsi, LSH fournit une comparaison floue et résout le problème inverse - une différence floue. Les premières applications du LSH concernaient des espaces vectoriels multidimensionnels à partir d'un ensemble de mots. Nous ne pouvions penser à une seule raison pour laquelle il ne travaillerait pas avec des espaces de représentation vectorielle des mots. Il y a des indications que d' autres pensaient la même chose .

Ce qui précède montre l'utilisation de LSH lors du placement de caractères dans le même groupe, mais à l'envers.
Le travail que nous avons effectué pour appliquer les découpes LSH et vectorielles en détectant les valeurs aberrantes de texte dans les journaux de construction permet désormais à l'ingénieur de visualiser une petite partie des lignes de journal pour identifier et corriger les erreurs potentielles critiques pour l'entreprise. Il vous permet également de réaliser un clustering sémantique de presque toutes les lignes du journal en temps réel.
Cette approche fonctionne désormais dans toutes les versions de Netflix. La partie sémantique vous permet de regrouper des éléments apparemment différents en fonction de leur signification et d'afficher ces éléments dans les rapports d'émissions.
Quelques exemples
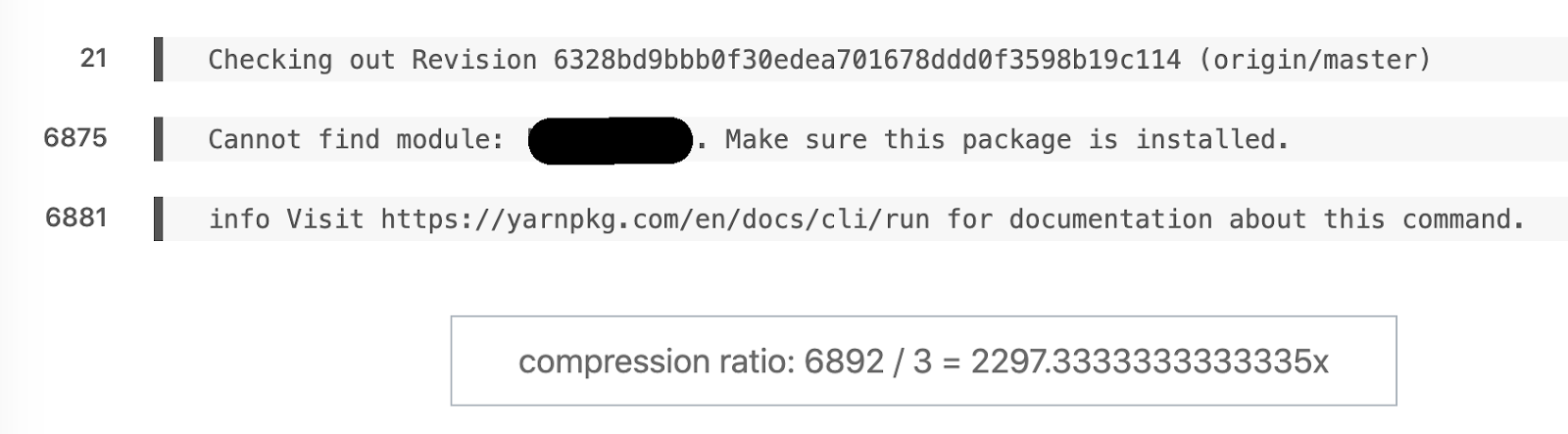
Exemple préféré de diff sémantique. 6892 lignes transformées en 3.
Autre exemple: cet assemblage a enregistré 6044 lignes, mais 171 sont restés dans le rapport. Le principal problème a surgi presque immédiatement à la ligne 4036.

Bien sûr, il est plus rapide d' analyser 171 lignes que 6044. Mais comment obtenir des journaux d'assemblage aussi volumineux? Certaines des milliers de tâches de construction qui sont des tests de résistance pour l'électronique grand public sont effectuées en mode trace. Il est difficile de travailler avec un tel volume de données sans traitement préalable.

Taux de compression: 91366/455 = 205,3.
Il existe divers exemples qui reflètent les différences sémantiques entre les frameworks, les langages et les scripts de construction.
Conclusion
La maturité des produits d'apprentissage de transfert open source et du SDK a permis à LSH de résoudre le problème de recherche sémantique du plus proche voisin en très peu de lignes de code. Nous nous sommes intéressés aux avantages particuliers que le transfert d'apprentissage et la mise au point apportent à l'application. Nous sommes heureux de pouvoir résoudre ces problèmes et d'aider les gens à faire ce qu'ils font mieux et plus rapidement.
Nous espérons que vous envisagez de rejoindre Netflix et de devenir l'un des excellents collègues dont nous vous facilitons la vie grâce à l'apprentissage automatique. L'engagement est la valeur fondamentale de Netflix, et nous sommes particulièrement intéressés à favoriser différentes perspectives sur les équipes techniques. Par conséquent, si vous êtes dans l'analyse, l'ingénierie, la science des données ou tout autre domaine et que vous avez une formation non typique de l'industrie, nous aimerions particulièrement vous entendre!
Si vous avez des questions sur les fonctionnalités de Netflix, veuillez contacter les contributeurs LinkedIn: Stanislav Kirdey , William High Comment résolvez-vous le problème de recherche dans les journaux
?
Découvrez comment obtenir une profession de haut niveau à partir de zéro ou augmenter vos compétences et vos salaires en suivant les cours en ligne SkillFactory:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
