
Récemment, les grandes entreprises russes se tournent de plus en plus vers des solutions de stockage abordables. Les SGBD open source deviennent des concurrents d'Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB, etc. Les géants occidentaux - Alibaba, Instagram, Skype - les utilisent depuis longtemps dans leurs paysages informatiques.
Dans le cadre du projet de l'Union russe des assureurs automobiles (RSA), où Jet Infosystems construisait l'infrastructure informatique du nouvel AIS OSAGO, les développeurs ont utilisé le SGBD PostgreSQL. Et nous avons réfléchi à la manière de garantir une disponibilité maximale de la base de données et une perte de données minimale en cas de panne matérielle. Et cette description «sur papier» de la solution semble aussi simple que 2 + 2, en fait, notre équipe a dû travailler dur pour atteindre la tolérance aux pannes.
Il existe plusieurs outils de clustering de basculement pour PostgreSQL. Ce sont Stolon, Patroni, Repmgr, Pacemaker + Corosync, etc.
Nous avons choisi Patroni car ce projet se développe activement, contrairement à des projets similaires, il dispose d'une documentation claire et devient de plus en plus le choix des administrateurs de bases de données.
La composition du "service à soupe"
Patroni est un ensemble de scripts python permettant d'automatiser le basculement du rôle principal du serveur de base de données PostgreSQL vers la réplique. Il peut également stocker, modifier et appliquer les paramètres du SGBD PostgreSQL lui-même. Il s'avère qu'il n'est pas nécessaire de mettre à jour les fichiers de configuration PostgreSQL sur chaque serveur séparément.
PostgreSQL est une base de données relationnelle open source. Il a fait ses preuves dans des processus analytiques vastes et complexes.
Keepalived - dans une configuration multi-nœuds, il est utilisé pour activer une adresse IP dédiée sur le nœud même du cluster où le rôle du nœud PostgreSQL principal est actuellement utilisé. L'adresse IP sert de point d'entrée pour les applications et les utilisateurs.
DCS est un stockage de configuration distribué. Patroni l'utilise pour stocker des informations sur la composition du cluster, les rôles des serveurs du cluster, ainsi que pour stocker ses propres paramètres de configuration et ceux de PostgreSQL. Cet article se concentrera sur etcd.
Expériences avec des nuances
A la recherche de la solution optimale de tolérance aux pannes et afin de tester nos hypothèses sur le fonctionnement des différentes options, nous avons créé plusieurs bancs de test. Au départ, nous avons envisagé des solutions différentes de l'architecture cible: par exemple, nous avons utilisé Haproxy comme nœud principal de PostgreSQL ou DCS était situé sur les mêmes serveurs que PostgreSQL. Nous avons organisé des hackathons internes, étudié le comportement de Patroni en cas de défaillance d'un composant serveur, d'indisponibilité du réseau, de débordement du système de fichiers, etc. Autrement dit, ils ont élaboré divers scénarios de défaillance. À la suite de ces «études scientifiques», l'architecture finale de la solution tolérante aux pannes a été formée.
Plat de haute cuisine informatique
Il existe des rôles de serveur dans PostgreSQL: primaire - une instance avec la capacité d'écrire / lire des données; réplica - une instance en lecture seule, constamment synchronisée avec primaire. Ces rôles sont statiques lorsque PostgreSQL est en cours d'exécution et si un serveur avec le rôle principal échoue, l'administrateur de base de données doit élever manuellement le rôle de réplica au rôle principal.
Patroni crée des clusters de basculement, c'est-à-dire qu'il combine des serveurs avec les rôles principal et de réplique. Il y a un changement de rôle automatique entre eux en cas d'échec.

L'illustration ci-dessus montre comment les serveurs d'applications se connectent à l'un des serveurs du cluster Patroni. Cette configuration utilise un nœud principal et deux réplicas, dont l'un est synchrone. Avec la réplication synchrone, PostgreSQL fonctionne de telle manière que le serveur principal attend toujours que les modifications soient écrites sur le réplica. Si le réplica synchrone n'est pas disponible, le principal n'écrira pas les modifications sur lui-même, il sera en lecture seule. C'est l'architecture de PostgreSQL. Pour "changer sa nature", le deuxième réplica est utilisé - asynchrone (si la réplication synchrone n'est pas requise, vous pouvez vous limiter à un réplica).
Lors de l'utilisation de deux répliques ou plus et de l'activation de la réplication synchrone, Patroni crée toujours une seule réplique synchrone. Si le nœud principal échoue, Patroni augmente le niveau de la réplique synchrone.
L'illustration suivante montre des fonctionnalités Patroni supplémentaires qui sont vitales dans les solutions d'entreprise industrielles - réplication de données sur un site de sauvegarde.
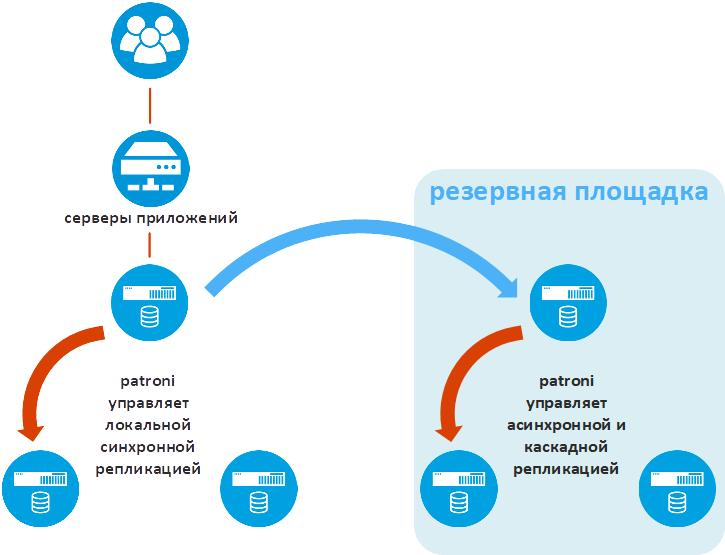
Patroni appelle cette fonctionnalité standby_cluster. Il permet à un cluster Ratroni d'être utilisé sur un site distant en tant que réplica asynchrone. Si le site principal est perdu, le cluster Patroni commencera à fonctionner comme s'il s'agissait du site principal.
L'un des nœuds du cluster de sites de sauvegarde est appelé Standby Leader. Il s'agit d'une réplique asynchrone du nœud principal du site principal. Les deux nœuds restants du cluster de sites de sauvegarde reçoivent des données du leader de secours. C'est ainsi que la réplication en cascade est mise en œuvre, ce qui réduit le volume de trafic entre les sites technologiques.
Composition des applications du cluster Patroni
Une fois lancé, Patroni crée un port TCP séparé. Après avoir effectué une requête HTTP sur ce port, vous pouvez comprendre quel nœud du cluster est principal et quel est le réplica.

Dans keepalived, nous avons spécifié un petit script personnalisé comme objet de surveillance qui interroge le port TCP Patroni. Le script attend une réponse HTTP GET 200. Le nœud de cluster qui répond est le nœud principal, sur lequel keepalived démarre l'adresse IP dédiée à la connexion au cluster.
Si vous configurez la deuxième instance keepalived pour attendre une réponse HTTP GET 200 d'un réplica synchrone, keepalived sur le même nœud de cluster lancera une autre adresse IP dédiée. Cette adresse peut être utilisée par l'application pour lire les données de la base de données. Cette option est utile, par exemple, pour préparer des rapports.
Puisque Patroni est un ensemble de scripts, ses instances sur chaque nœud ne "communiquent" pas directement entre elles, mais utilisent le magasin de configuration pour cela. Nous utilisons etcd comme tel, qui est un quorum pour Patroni lui-même - le nœud principal actuel met constamment à jour la clé dans le stockage etcd, indiquant qu'il s'agit du premier. Le reste des nœuds du cluster lisent constamment cette clé et «comprennent» qu'il s'agit de répliques. Le service etcd est situé sur des serveurs dédiés à raison de 3 ou 5. La synchronisation des données dans le stockage etcd entre ces serveurs est effectuée au moyen du service etcd lui-même.
Au cours de nos expériences, nous avons découvert que le service etcd doit être déplacé vers des serveurs séparés. Premièrement, etcd est extrêmement sensible à la latence du réseau et à la réactivité du sous-système de disque, et les serveurs dédiés ne seront pas chargés. Deuxièmement, avec une possible séparation du réseau des nœuds du cluster Patroni, une «fracture cérébrale» peut se produire - deux nœuds primaires apparaîtront, qui ne sauront rien l'un de l'autre, puisque le cluster etcd se «désintégrera» également.
Contrôle pratique
A l'échelle d'un projet de construction d'une infrastructure informatique pour AIS OSAGO, la réalisation de la tolérance aux pannes de PostgreSQL est l'une des tâches consistant à «implanter» un SGBD ouvert dans le paysage informatique de l'entreprise. À côté, il y a des problèmes liés à l'intégration du cluster PostgreSQL avec les systèmes de sauvegarde, la surveillance de l'infrastructure et la sécurité des informations, la sécurité des données fiables sur le site de sauvegarde. Chacune de ces directions a ses propres écueils et les moyens de les contourner. Nous avons déjà écrit sur l'un d'entre eux - nous avons parlé de la sauvegarde PostgreSQL à l'aide de solutions d'entreprise .

L'architecture de tolérance aux pannes de PostgreSQL, pensée et testée par nos soins sur les stands, a prouvé son efficacité dans la pratique. La solution est prête à «transférer» diverses pannes système et logiques. Maintenant, il fonctionne sur 10 clusters Patroni hautement chargés et résiste au traitement PostgreSQL avec des centaines de gigaoctets de données par heure.
Auteur: Dmitry Erykin, et ingénieur-concepteur des systèmes informatiques de Jet Infosystems