
Dans plusieurs articles précédents de cette série, nous avons déjà évoqué le concept de rendu différentiel . Aujourd'hui, il est temps de clarifier ce que c'est et avec quoi il est mangé.
, , 3D ML . , — SoftRasterizer PyTorch 3D. , , “ ” , , .
3D ML :
IT- “VR/AR & AI” — PHYGITALISM.
Rendering pipeline: forward and inverse
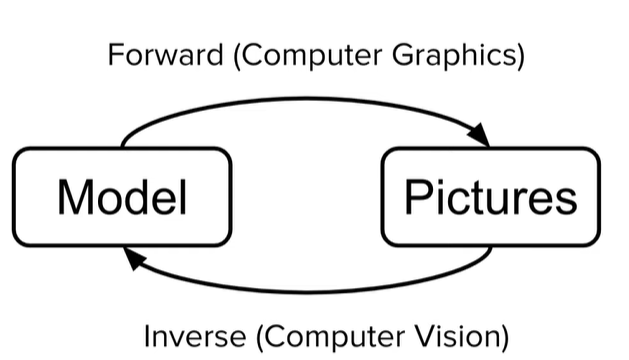
, - 3D , :
- , 3D ( ) .. forward rendering;
- , 3D ( ) .. inverse rendering.
, , ( ).
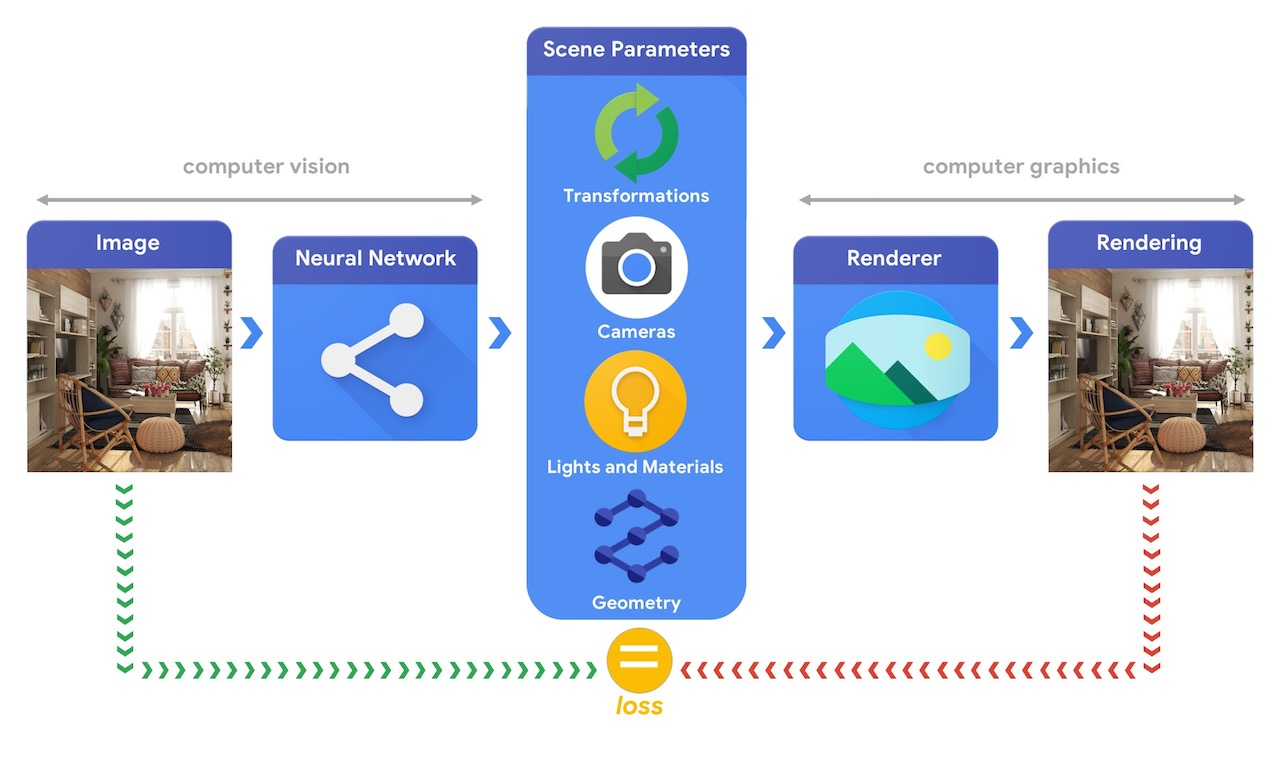
.1 TensorFlow Graphics (github page).
, “3D mesh reconstruction from single image”, . , 3D ( №2 ). , 3D , - ( .2).
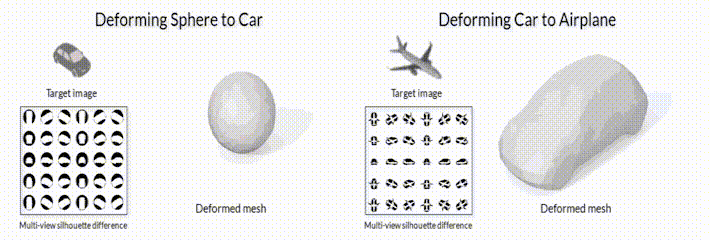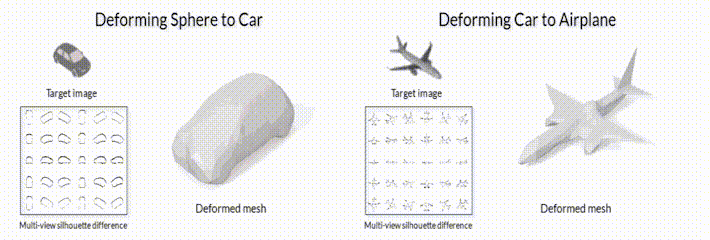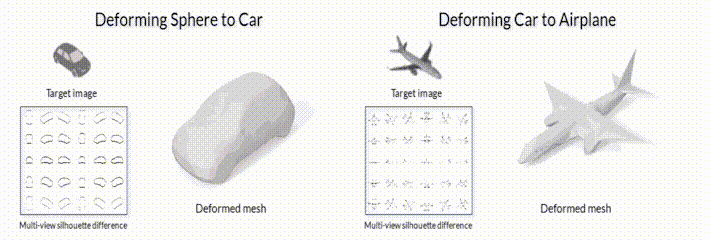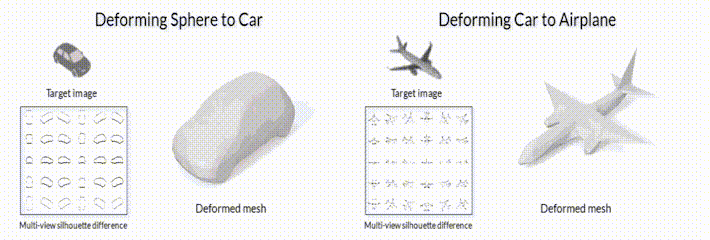
.2 SoftRas (github page).
, , 3D :
- 3D , ;
- (, , ..);
- ;
- , .
, .
, .
Why is rendering not differentiable?
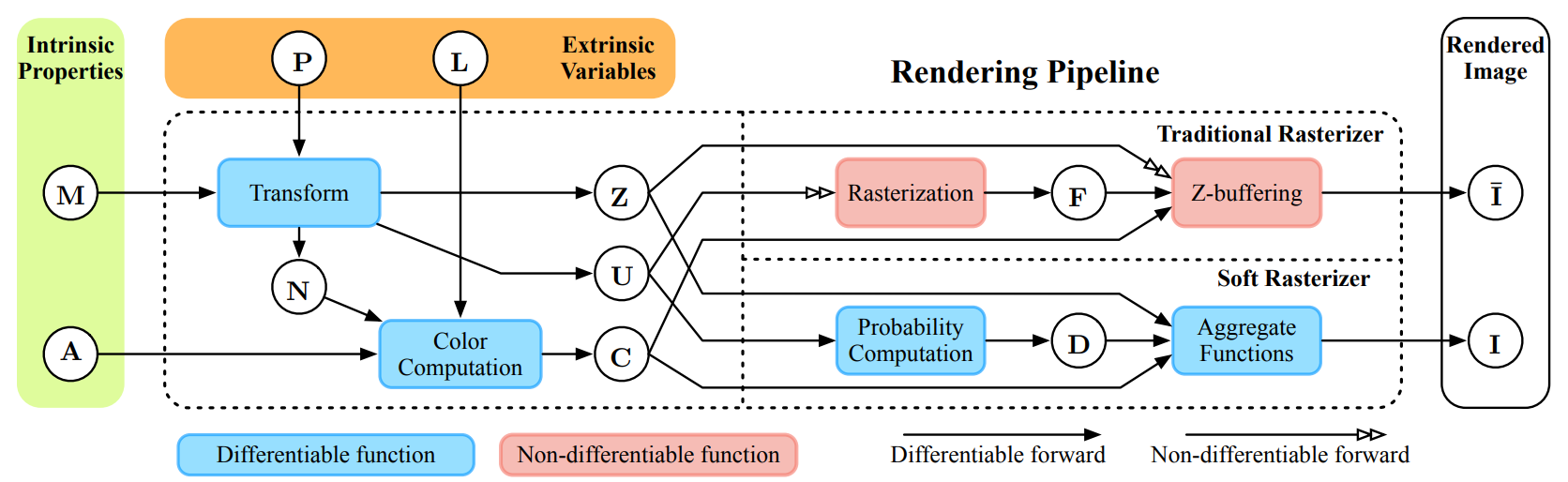
.3 Soft Rasterizer [1]. : — , — , — , — , — , — , — 3D 2D , — , — Soft Rasterizer, — SoftRas . — , — .

, : “ — , , , 3D 2D ”.
.
№1 ( )
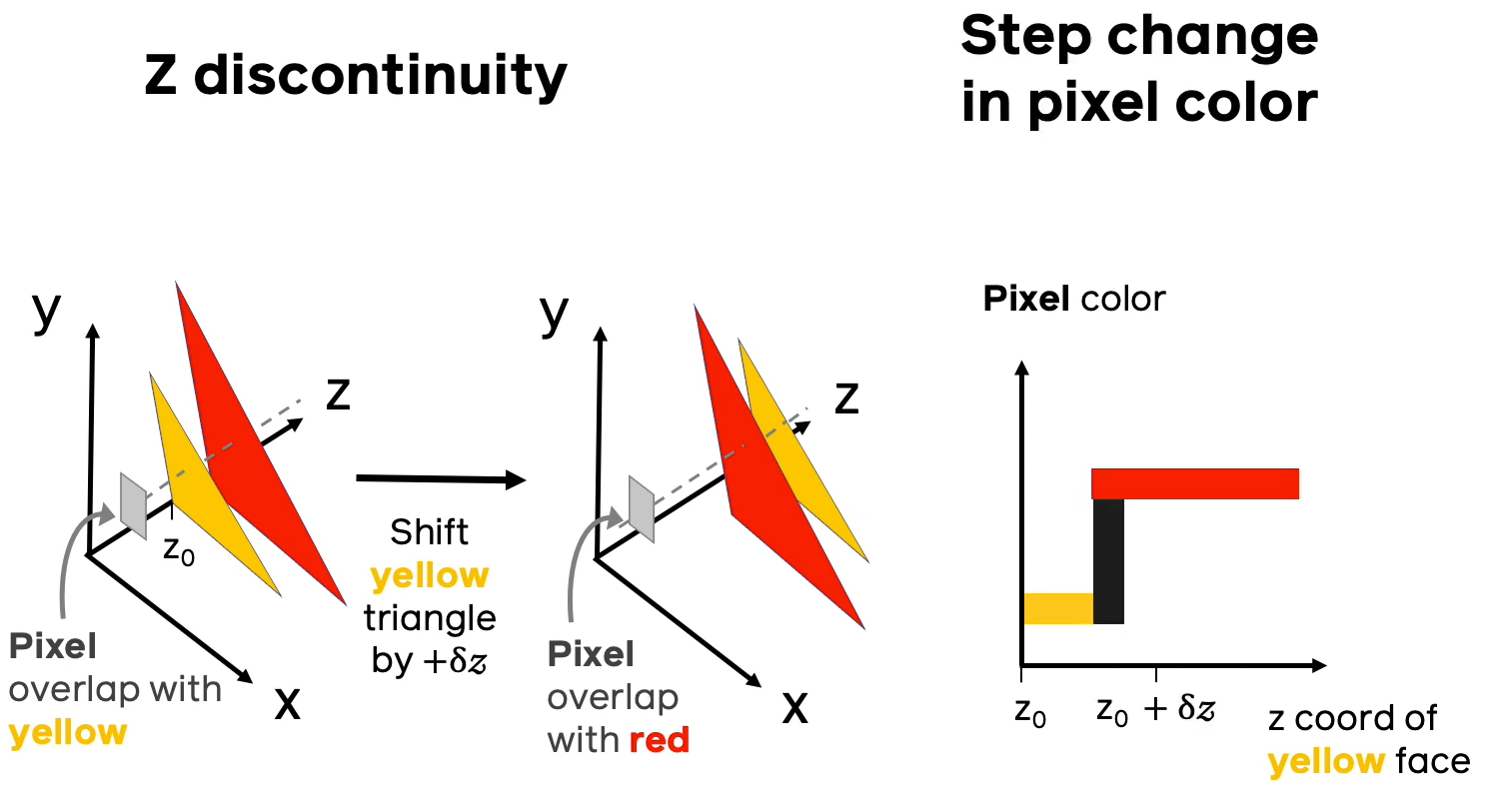
, , , , . , , , . ( ) . , , .
№2 ( )
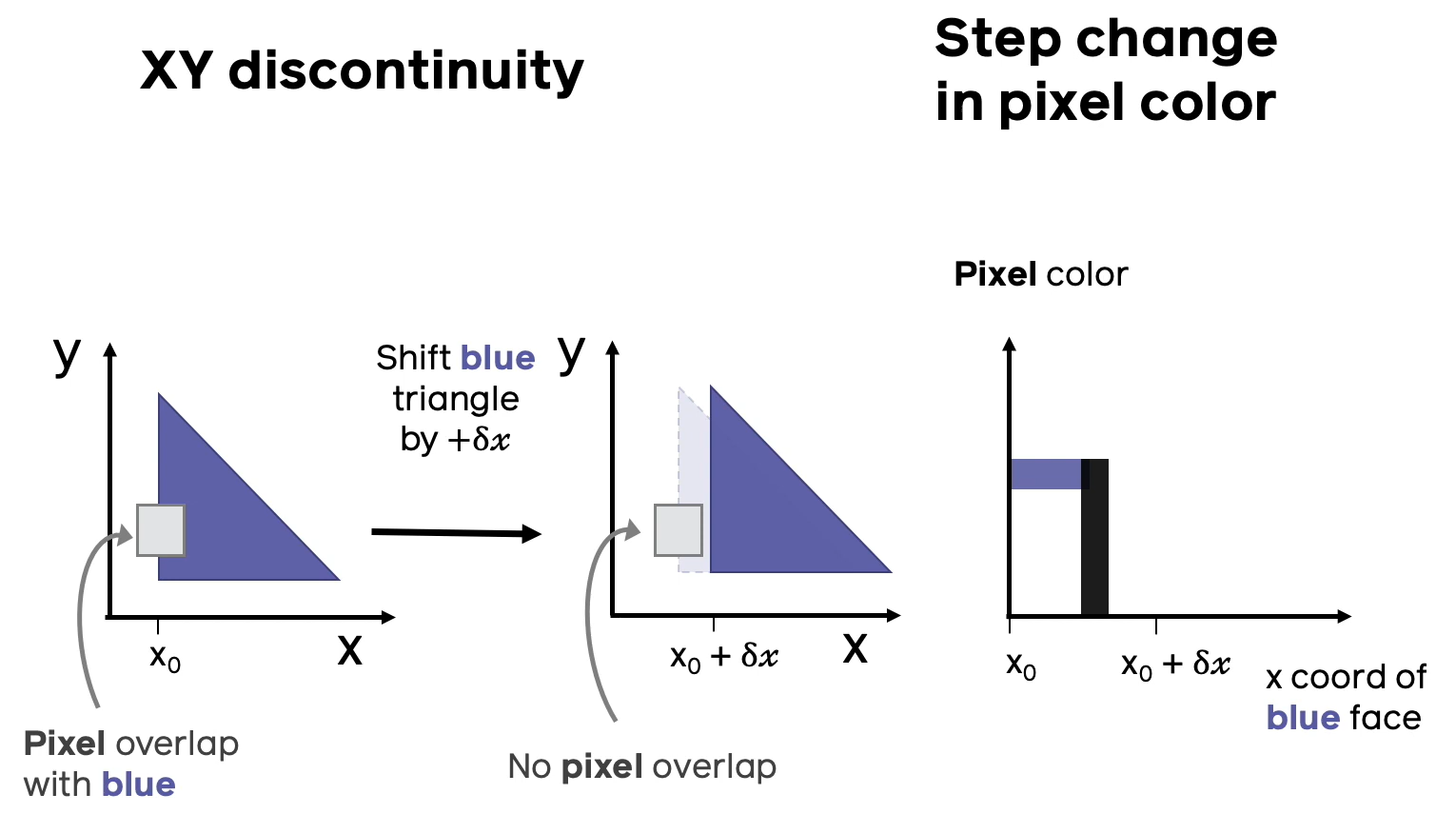
, , , , . , .
Make it differentiable! — Soft Rasterizer
, , 3D ML — , .
:
- Loper, M.M. and Black, M.J., 2014, September. OpenDR: An approximate differentiable renderer. In European Conference on Computer Vision (pp. 154-169). Springer, Cham.
- Kato, H., Ushiku, Y. and Harada, T., 2018. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3907-3916).
- Li, T.M., Aittala, M., Durand, F. and Lehtinen, J., 2018. Differentiable monte carlo ray tracing through edge sampling. ACM Transactions on Graphics (TOG), 37(6), pp.1-11.
- Liu, S., Li, T., Chen, W. and Li, H., 2019. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 7708-7717).
- Chen, W., Ling, H., Gao, J., Smith, E., Lehtinen, J., Jacobson, A. and Fidler, S., 2019. Learning to predict 3d objects with an interpolation-based differentiable renderer. In Advances in Neural Information Processing Systems (pp. 9609-9619).
. , Soft Rasterizer, : -, , -, PyTorch 3D [6].
[1], .
№2, “” , .

, 0 1 — (- ). — ( , ), — ( , , , , ), — , 1 -1 ( , , , ), — , .
№1, “” k — (blending).
: - , k — , . (background colour), — . — - - , — ( , ).
Soft Rasterizer, , .
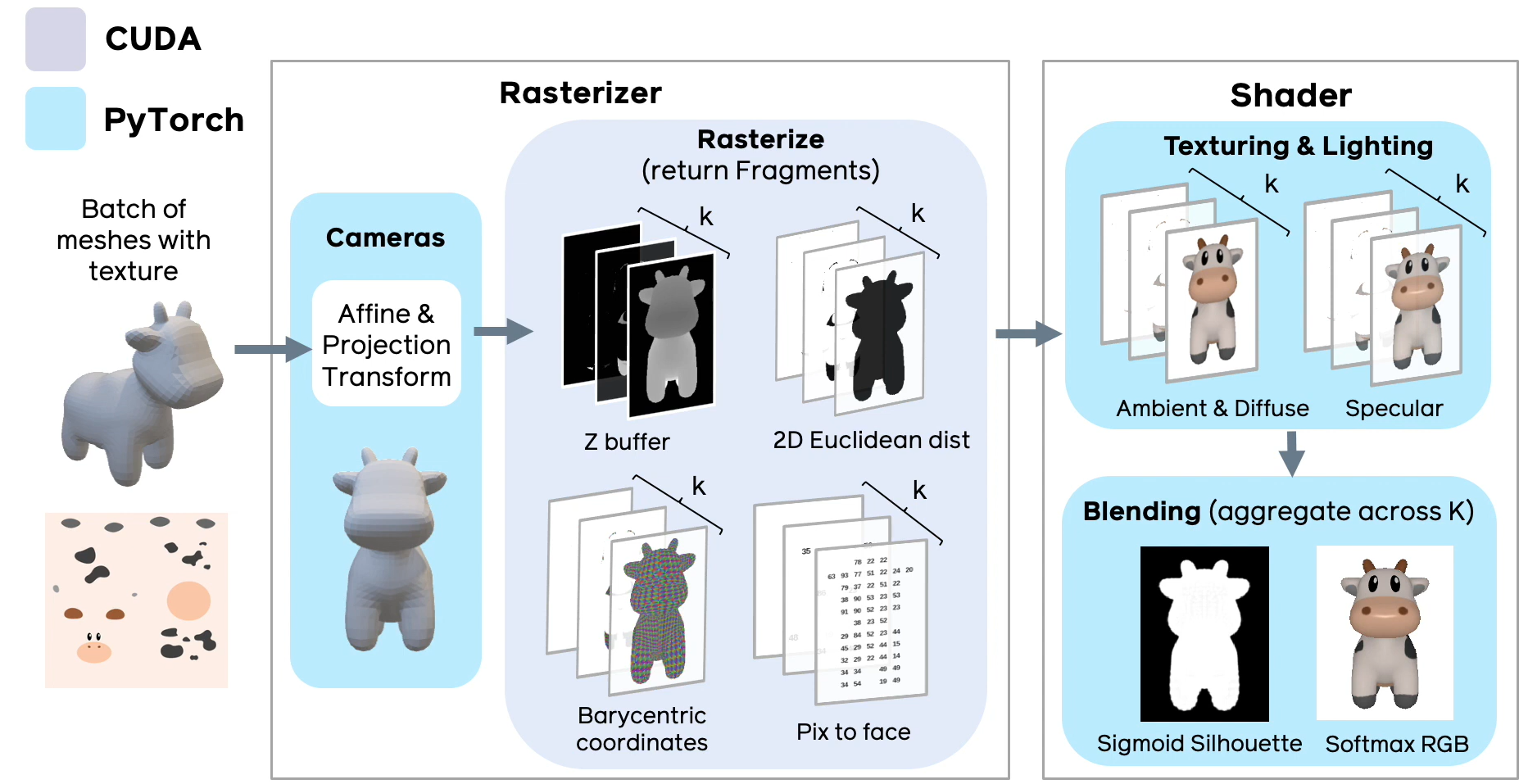
.4 PyTorch 3D ( ).
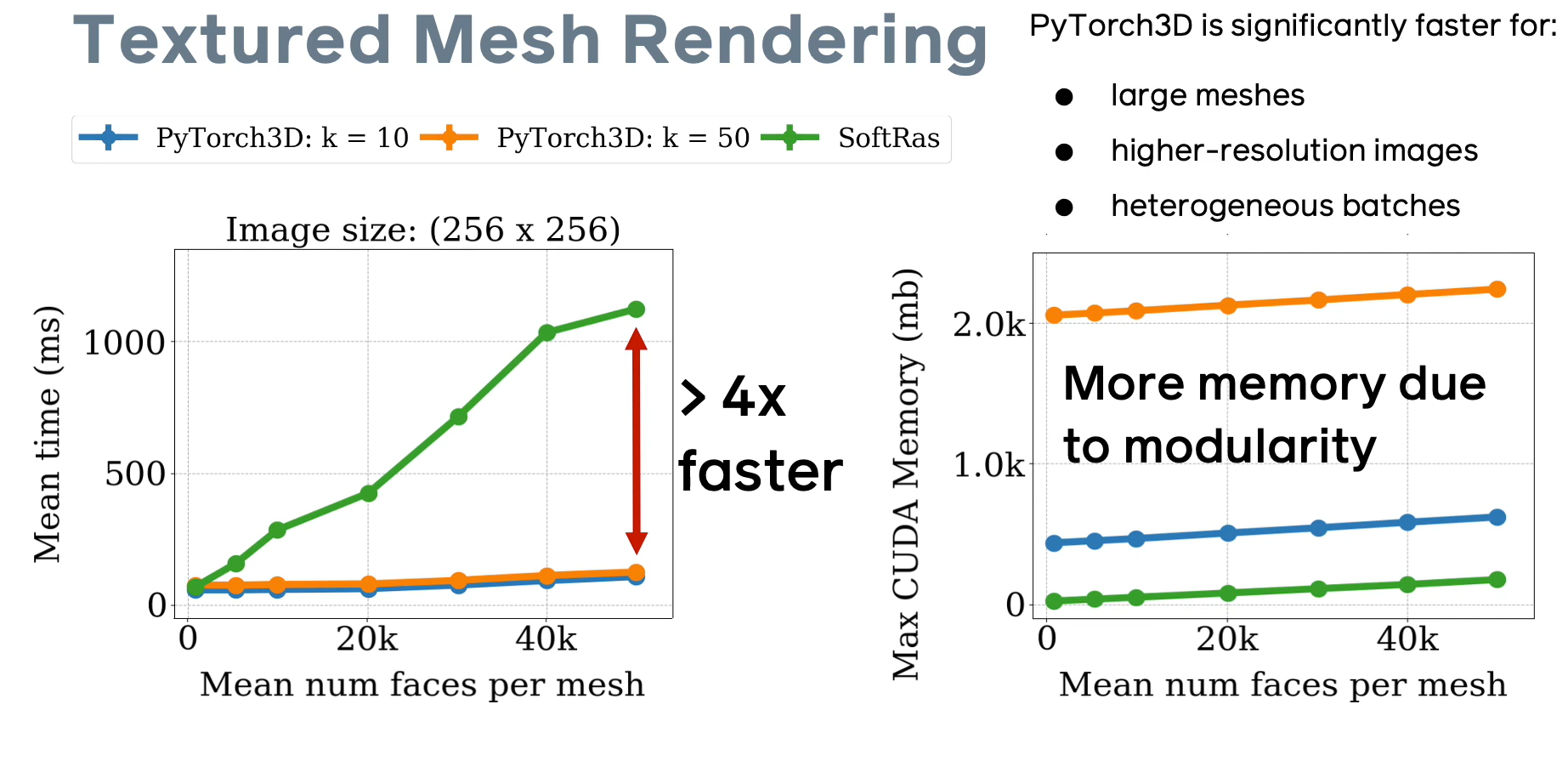
Soft Rasterizer PyTorch 3D , PyTorch, CUDA. [github page], 4- ( ), , ( , , , ) k .
PyTorch 3D, Soft Rasterizer. , \sigma, \gamma.
anaconda, pytorch 1.1.0. CUDA.
import matplotlib.pyplot as plt
import os
import tqdm
import numpy as np
import imageio
import soft_renderer as sr
input_file = 'path/to/input/file'
output_dir = 'path/to/output/dir' , ( , texture_type=’vertex’), .
# camera settings
camera_distance = 2.732
elevation = 30
azimuth = 0
# load from Wavefront .obj file
mesh = sr.Mesh.from_obj(
input_file,
load_texture=True,
texture_res=5,
texture_type='surface')
# create renderer with SoftRas
renderer = sr.SoftRenderer(camera_mode='look_at')
os.makedirs(args.output_dir, exist_ok=True), .
# draw object from different view
loop = tqdm.tqdm(list(range(0, 360, 4)))
writer = imageio.get_writer(
os.path.join(output_dir, 'rotation.gif'),
mode='I')
for num, azimuth in enumerate(loop):
# rest mesh to initial state
mesh.reset_()
loop.set_description('Drawing rotation')
renderer.transform.set_eyes_from_angles(
camera_distance,
elevation,
azimuth)
images = renderer.render_mesh(mesh)
image = images.detach().cpu().numpy()[0].transpose((1, 2, 0))
writer.append_data((255*image).astype(np.uint8))
writer.close(). .
# draw object from different sigma and gamma
loop = tqdm.tqdm(list(np.arange(-4, -2, 0.2)))
renderer.transform.set_eyes_from_angles(camera_distance, elevation, 45)
writer = imageio.get_writer(
os.path.join(output_dir, 'bluring.gif'),
mode='I')
for num, gamma_pow in enumerate(loop):
# rest mesh to initial state
mesh.reset_()
renderer.set_gamma(10**gamma_pow)
renderer.set_sigma(10**(gamma_pow - 1))
loop.set_description('Drawing blurring')
images = renderer.render_mesh(mesh)
image = images.detach().cpu().numpy()[0].transpose((1, 2, 0))
writer.append_data((255*image).astype(np.uint8))
writer.close()
# save to textured obj
mesh.reset_()
mesh.save_obj(
os.path.join(args.output_dir, 'saved_spot.obj'),
save_texture=True)(cow.obj, cow.mtl, cow.png — , , wget) :

Neural rendering

3D ML, , (neural rendering). , : .
, :
- SOTA [7] CVPR 2020;
- CVPR 2020, ;
- MIT DL Neural rendering ;
- Medium ;
- youtube two minute papers .
Experiment: Mona Liza reconstruction
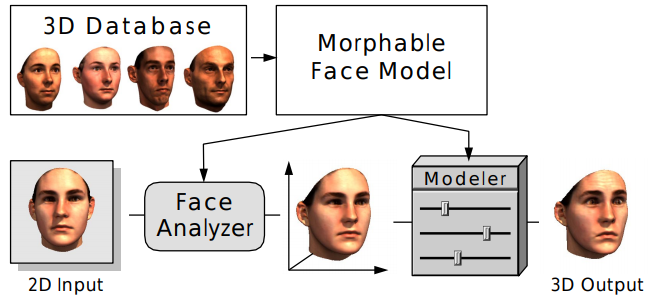
, .. 3D morphable model [8] — , 3D. 3D , , ( , Word2Vec 3D ).
Basel face model (2017 version). model2017-1_bfm_nomouth.h5 .
.
import torch
import pyredner
import h5py
import urllib
import time
from matplotlib.pyplot import imshow
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.display import display, clear_output
from matplotlib import animation
from IPython.display import HTML# Load the Basel face model
with h5py.File(r'model2017-1_bfm_nomouth.h5', 'r') as hf:
shape_mean = torch.tensor(hf['shape/model/mean'],
device = pyredner.get_device())
shape_basis = torch.tensor(hf['shape/model/pcaBasis'],
device = pyredner.get_device())
triangle_list = torch.tensor(hf['shape/representer/cells'],
device = pyredner.get_device())
color_mean = torch.tensor(hf['color/model/mean'],
device = pyredner.get_device())
color_basis = torch.tensor(hf['color/model/pcaBasis'],
device = pyredner.get_device()) — shape_basis ( 199 PCA), — color_basis ( 199 PCA), — shape_mean, color_mean. triangle_list .
, , , .
indices = triangle_list.permute(1, 0).contiguous()
def model(
cam_pos,
cam_look_at,
shape_coeffs,
color_coeffs,
ambient_color,
dir_light_intensity):
vertices = (shape_mean + shape_basis @ shape_coeffs).view(-1, 3)
normals = pyredner.compute_vertex_normal(vertices, indices)
colors = (color_mean + color_basis @ color_coeffs).view(-1, 3)
m = pyredner.Material(use_vertex_color = True)
obj = pyredner.Object(vertices = vertices,
indices = indices,
normals = normals,
material = m,
colors = colors)
cam = pyredner.Camera(position = cam_pos,
# Center of the vertices
look_at = cam_look_at,
up = torch.tensor([0.0, 1.0, 0.0]),
fov = torch.tensor([45.0]),
resolution = (256, 256))
scene = pyredner.Scene(camera = cam, objects = [obj])
ambient_light = pyredner.AmbientLight(ambient_color)
dir_light = pyredner.DirectionalLight(torch.tensor([0.0, 0.0, -1.0]),
dir_light_intensity)
img = pyredner.render_deferred(scene = scene,
lights = [ambient_light, dir_light])
return img. . , :
cam_pos = torch.tensor([-0.2697, -5.7891, 373.9277])
cam_look_at = torch.tensor([-0.2697, -5.7891, 54.7918])
img = model(cam_pos,
cam_look_at,
torch.zeros(199, device = pyredner.get_device()),
torch.zeros(199, device = pyredner.get_device()),
torch.ones(3),
torch.zeros(3))
imshow(torch.pow(img, 1.0/2.2).cpu())
face_url = 'https://raw.githubusercontent.com/BachiLi/redner/master/tutorials/mona-lisa-cropped-256.png'
urllib.request.urlretrieve(face_url, 'target.png')
target = pyredner.imread('target.png').to(pyredner.get_device())
imshow(torch.pow(target, 1.0/2.2).cpu())
, .
# Set requires_grad=True since we want to optimize them later
cam_pos = torch.tensor([-0.2697, -5.7891, 373.9277],
requires_grad=True)
cam_look_at = torch.tensor([-0.2697, -5.7891, 54.7918],
requires_grad=True)
shape_coeffs = torch.zeros(199, device = pyredner.get_device(),
requires_grad=True)
color_coeffs = torch.zeros(199, device = pyredner.get_device(),
requires_grad=True)
ambient_color = torch.ones(3, device = pyredner.get_device(),
requires_grad=True)
dir_light_intensity = torch.zeros(3, device = pyredner.get_device(),
requires_grad=True)
# Use two different optimizers for different learning rates
optimizer = torch.optim.Adam(
[
shape_coeffs,
color_coeffs,
ambient_color,
dir_light_intensity],
lr=0.1)
cam_optimizer = torch.optim.Adam([cam_pos, cam_look_at], lr=0.5), ( MSE + ) 3D .
plt.figure()
imgs, losses = [], []
# Run 500 Adam iterations
num_iters = 500
for t in range(num_iters):
optimizer.zero_grad()
cam_optimizer.zero_grad()
img = model(cam_pos, cam_look_at, shape_coeffs,
color_coeffs, ambient_color, dir_light_intensity)
# Compute the loss function. Here it is L2 plus a regularization
# term to avoid coefficients to be too far from zero.
# Both img and target are in linear color space,
# so no gamma correction is needed.
loss = (img - target).pow(2).mean()
loss = loss
+ 0.0001 * shape_coeffs.pow(2).mean()
+ 0.001 * color_coeffs.pow(2).mean()
loss.backward()
optimizer.step()
cam_optimizer.step()
ambient_color.data.clamp_(0.0)
dir_light_intensity.data.clamp_(0.0)
# Plot the loss
f, (ax_loss, ax_diff_img, ax_img) = plt.subplots(1, 3)
losses.append(loss.data.item())
# Only store images every 10th iterations
if t % 10 == 0:
# Record the Gamma corrected image
imgs.append(torch.pow(img.data, 1.0/2.2).cpu())
clear_output(wait=True)
ax_loss.plot(range(len(losses)), losses, label='loss')
ax_loss.legend()
ax_diff_img.imshow((img -target).pow(2).sum(dim=2).data.cpu())
ax_img.imshow(torch.pow(img.data.cpu(), 1.0/2.2))
plt.show()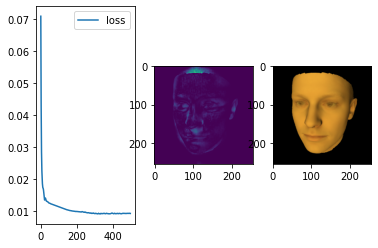
:
fig = plt.figure()
# Clamp to avoid complains
im = plt.imshow(imgs[0].clamp(0.0, 1.0), animated=True)
def update_fig(i):
im.set_array(imgs[i].clamp(0.0, 1.0))
return im,
anim = animation.FuncAnimation(fig, update_fig,
frames=len(imgs), interval=50, blit=True)
HTML(anim.to_jshtml())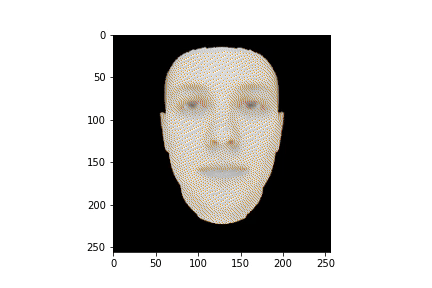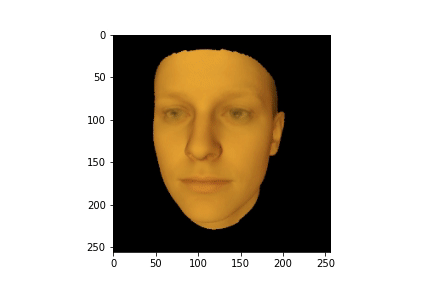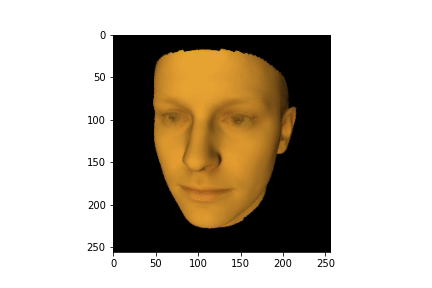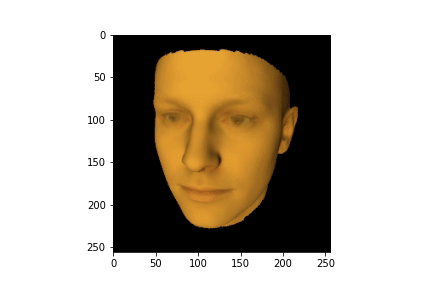
Conclusions
— , . , .
( Kaolin, PyTorch 3D, TensorFlow Graphics), . , (Soft Rasterizer, redner). , .
, . , 2D 3D . .
- Liu, S., Li, T., Chen, W. and Li, H., 2019. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 7708-7717). [ paper ]
- Loper, M.M. and Black, M.J., 2014, September. OpenDR: An approximate differentiable renderer. In European Conference on Computer Vision (pp. 154-169). Springer, Cham. [ paper ]
- Kato, H., Ushiku, Y. and Harada, T., 2018. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3907-3916). [ paper ]
- Li, T.M., Aittala, M., Durand, F. and Lehtinen, J., 2018. Differentiable monte carlo ray tracing through edge sampling. ACM Transactions on Graphics (TOG), 37(6), pp.1-11. [ paper ]
- Chen, W., Ling, H., Gao, J., Smith, E., Lehtinen, J., Jacobson, A. and Fidler, S., 2019. Learning to predict 3d objects with an interpolation-based differentiable renderer. In Advances in Neural Information Processing Systems (pp. 9609-9619). [ paper ]
- Ravi, N., Reizenstein, J., Novotny, D., Gordon, T., Lo, W.Y., Johnson, J. and Gkioxari, G., 2020. Accelerating 3D Deep Learning with PyTorch3D. arXiv preprint arXiv:2007.08501. [ paper ] [ github ]
- Tewari, A., Fried, O., Thies, J., Sitzmann, V., Lombardi, S., Sunkavalli, K., Martin-Brualla, R., Simon, T., Saragih, J., Nießner, M. and Pandey, R., 2020. State of the Art on Neural Rendering. arXiv preprint arXiv:2004.03805. [ paper ]
- Blanz, V. and Vetter, T., 1999, July. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques (pp. 187-194). [ paper ][ project page ]