J'ai senti que tout irait bien pour moi et j'ai fait un voyage dans le monde Linux. Dans ce numéro #IBelieveinDoing, il y avait des tutoriels non seulement sur Linux, mais aussi sur Git. Des parallèles peuvent être établis entre ces systèmes. Linux est un système d'exploitation open source utilisé par les programmeurs, et Git est un système de contrôle de version utilisé pour suivre les modifications du code source lors du développement de programmes. Il convient de noter que l'apprentissage de Linux et de Git s'est avéré être une expérience très excitante. Mais Git est un système assez complexe, il était donc plus difficile de maîtriser ses bases que les bases de Linux. Dans cet article, je souhaite partager avec vous ce que j'ai appris en maîtrisant Linux et Git.

Commandes Linux de base
pwd: Cette commande permet d'afficher des informations sur le répertoire de travail.
ls: Avec cette commande, vous pouvez afficher des informations sur le contenu d'un répertoire. S'il est exécuté sous cette forme, sans arguments de ligne de commande, il donne des informations au format par défaut.
cd: cette commande est pour changer de répertoire.
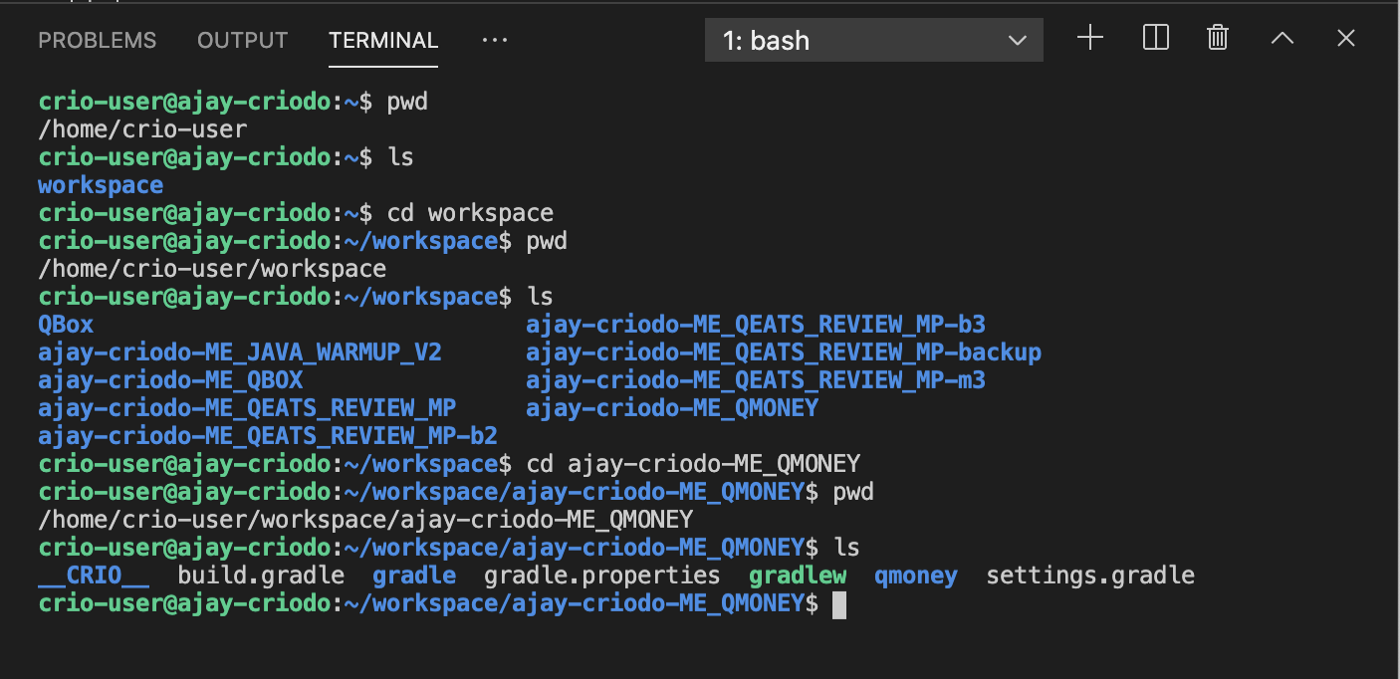
Expérimentation des commandes Linux
cp : Cette commande sert à copier des fichiers et des dossiers.
mv: Avec cette commande, vous pouvez renommer ou déplacer des fichiers et des dossiers.
touch: Cette commande est utilisée pour créer des fichiers vides et pour modifier l'horodatage des fichiers.
cat: cette commande vous permet d'afficher le contenu des fichiers, avec son aide, vous pouvez créer des copies de fichiers, joindre le contenu de certains fichiers à d'autres.
tree: Cette commande vous permet d'afficher les informations de répertoire dans un format arborescent. La commande, par défaut, affiche des informations sur les dossiers et fichiers et des informations sur le nombre de fichiers et de dossiers dans sa structure de sortie. Voici un exemple de son utilisation
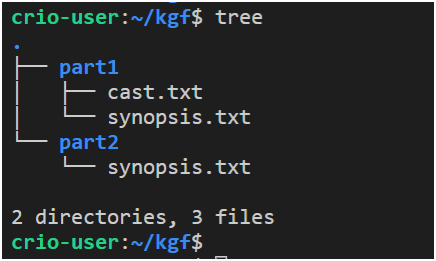
Exemple d'utilisation de la commande d'arborescence
Ici, les noms de dossier sont surlignés en bleu, les noms de fichiers sont en blanc. D'autres couleurs sont utilisées dans les structures affichées par cette commande.
echo: Cette commande permet d'afficher à l'écran les données qui lui sont transmises.
grep: Cette commande sert à travailler avec des données texte. En particulier, il vous permet de rechercher des chaînes.
tail: Cette commande imprime les 10 dernières lignes d'un fichier.
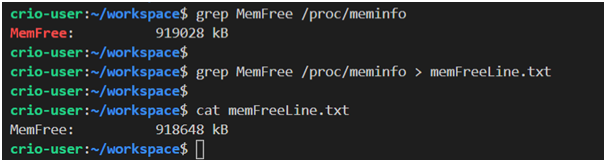
Exemples d'utilisation des commandes grep et cat
awk : Cette commande est destinée à fonctionner avec l'utilitaire correspondant, qui nous donne des outils puissants pour traiter les chaînes, dont les capacités sont comparables à celles disponibles dans les langages de programmation à part entière.
Sous Linux, vous pouvez utiliser des pipelines, qui sont des canaux à sens unique que vous pouvez utiliser pour communiquer entre les processus. Lors de la description des pipelines, le symbole (
|) est utilisé. À l'aide de ce symbole, vous pouvez, par exemple, acheminer la sortie d'une commande vers l'entrée d'une autre.

Un exemple d'utilisation du pipeline
ssh : cette commande vous permet de travailler avec un client ssh, qui est utilisé pour se connecter à des systèmes distants et y exécuter des commandes. Le protocole SSH vise à organiser l'interaction sécurisée des ordinateurs.
rm: Cette commande est utilisée pour supprimer des fichiers et des dossiers. Par exemple, l'appeler sous la formerm fileconduit à la suppression du fichier, et sous la formerm -r directory - à la suppression du répertoire et de tout son contenu.
Structure de répertoires Linux
Linux utilise une structure de répertoires en forme d'arborescence. Le début de cette structure hiérarchique se trouve dans le répertoire racine. Tous les autres répertoires sont imbriqués dans ce répertoire. La barre oblique (
/) est utilisée pour séparer les noms de répertoire lors de la spécification des chemins d'accès aux fichiers et aux dossiers .
Voici à quoi pourrait ressembler la structure du système de fichiers sur un système Linux.
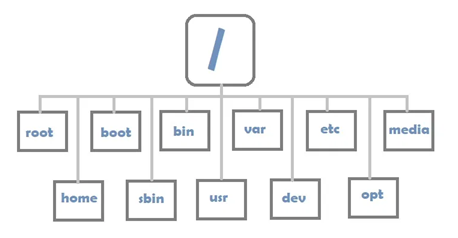
Structure des répertoires sous Linux
Voici les caractéristiques de certains dossiers importants.
| Chemin du répertoire | Remarques |
|
Répertoire racine. |
|
Le répertoire dans lequel les matériaux de l'utilisateur sont stockés. |
|
C'est là que sont stockés les fichiers nécessaires à l'exécution de Linux. |
|
Les exécutables se trouvent ici. |
|
Contient divers fichiers utilisés par le système et les programmes installés. Il peut s'agir de fichiers journaux, de bases de données, de contenu de page Web mis en cache. |
Adressage absolu et relatif
Les chemins d'accès absolus aux fichiers contiennent toujours le chemin d'accès complet du répertoire racine aux répertoires contenant les fichiers requis.
Les chemins relatifs sont relatifs au répertoire courant.
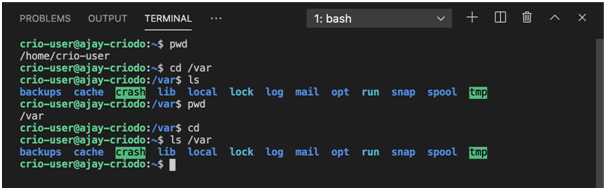
Expérimentation des chemins
Il existe des chemins relatifs spéciaux, qui sont décrits dans le tableau suivant.
| Chemin relatif | La description | Exemple | Notes d'exemple |
|
Répertoire de travail actuel. | |
Affiche des informations sur le contenu du répertoire actuel. |
|
Dossier Parent. | |
Montez d'un niveau dans le répertoire parent. |
|
Répertoire de travail précédent. | |
Revenez au répertoire de travail précédent. |
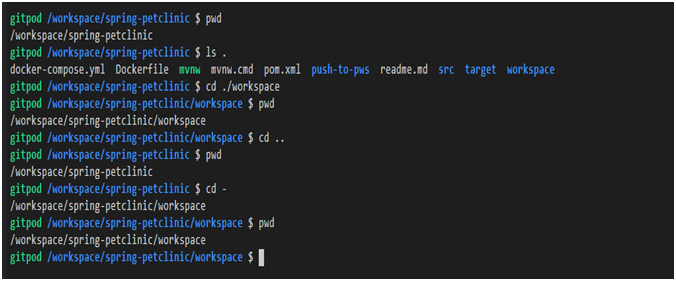
Exemples d'utilisation de chemins relatifs spéciaux
Liens souples et matériels vers des fichiers
Un lien de fichier souple (symbolique) contient un pointeur vers le nom du fichier. Ces liens ressemblent à des raccourcis utilisés pour accéder rapidement à un fichier à partir de différents répertoires. Si un fichier contenant un lien logiciel est supprimé, le lien reste, mais cesse de fonctionner.
Un lien physique est un lien vers l'emplacement sur le disque dur où se trouve le fichier. Le système considère que le fichier existe tant qu'il existe au moins un lien physique vers celui-ci. En fait, si un fichier a plusieurs liens physiques, il peut être comparé à un fichier ayant plusieurs noms.
La commande est utilisée pour créer des liens physiques et logiciels vers des fichiers
ln. Voici un exemple de création d'un lien symbolique avec celui-ci:
ln -s /path/to/file linkname
Contrôle du comportement des commandes
Le comportement des commandes Linux peut être contrôlé en leur passant des arguments de ligne de commande (commutateurs, options, indicateurs) lorsqu'ils sont appelés. Ils ressemblent généralement à un trait d'union (
-) suivi d'un nom de clé à une lettre (une telle construction peut ressembler, par exemple -a). Ils peuvent également ressembler à deux traits d'union ( --) suivis d'un nom de clé plus long (en quelque sorte --all).
Pour en savoir plus sur les commandes Linux, vous pouvez utiliser le système d'aide intégré, accessible via la commande
man. Par exemple, lsvous pouvez utiliser la commande pour obtenir de l'aide sur une commande man ls. Voici le résultat d'une commande similaire.
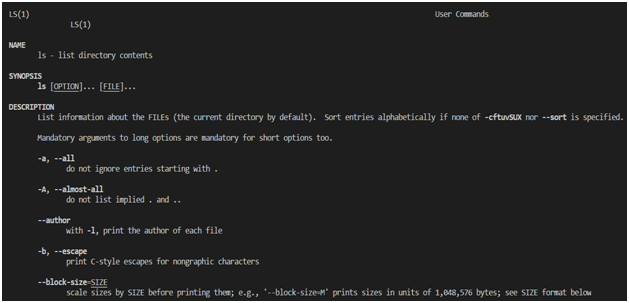
Ls Command
Reference Les pages de référence des commandes sont divisées en plusieurs sections. Parmi eux sont les suivants:
NAME(Nom). Celui-ci contient le nom de la commande et une brève description de ce qu'elle fait.SYNOPSIS(résumé de la syntaxe de la commande). Voici un schéma d'utilisation de la commande.DESCRIPTION(la description). Cette section fournit une description détaillée de la commande et des commutateurs de ligne de commande qu'elle prend en charge.
Par exemple, la commande est
lssouvent utilisée avec une option -lqui vous permet d'afficher des détails sur le contenu d'un répertoire.
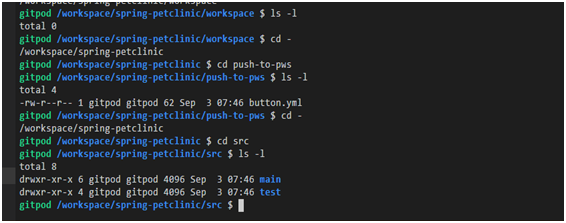
Utilisation de la commande ls -l
Dans l'image précédente, vous avez peut-être remarqué les constructions de vue
drwxr-xr-x. Ceci est une description des autorisations de fichier.
Droits d'accès aux fichiers
Supposons que nous ayons la construction suivante décrivant les autorisations de fichier:
- rwx r-- r--
Veuillez noter que quatre groupes de symboles peuvent y être distingués:
- Le premier symbole indique exactement ce à quoi nous avons affaire. À savoir, s'il y a un signe (
-) ici , alors nous avons un fichier devant nous. La lettre (d) indique un répertoire. La lettre (l) est pour un lien. - Les trois symboles suivants vous indiquent les autorisations dont dispose son propriétaire pour travailler avec un fichier donné:
r- lecture,w- écriture,x- exécution. L'ensemble complet des autorisations est représenté par une séquencerwx, si une certaine autorisation est absente, un symbole (-) est placé à la place correspondante . - , ( , ). , .
- , , , , .
La commande est utilisée pour gérer les autorisations de fichiers
chmod. Par exemple, pour ajouter aux règles actuelles d'accès à l'autorisation de fichier pour l'exécuter, vous pouvez utiliser le schéma suivant appelle: chmod +x <filename>. La conception +xindique que cette autorisation est ajoutée pour tous les utilisateurs.
Parlons de certaines des spécificités de la configuration des autorisations de fichiers à l'aide de
chmod. Ainsi, pour attribuer une certaine autorisation à tous les utilisateurs, des constructions similaires à celle décrite ci-dessus sont utilisées +x. L'opérateur ( +) est utilisé pour ajouter des autorisations, l'opérateur ( -) vous permet de supprimer des autorisations, l'opérateur ( =) est utilisé pour définir certains droits pour l'utilisateur propriétaire du fichier ( u, utilisateur), pour le groupe (g, group), pour les autres utilisateurs ( o, others) et pour tous les utilisateurs ( a, all). Ceci est fait dans les constructions de vue chmod u=rwx,g=rx,o=rx filename.
Lors de l'attribution des autorisations, elles sont souvent écrites sous forme numérique. Les codes octaux correspondent à certains droits. Ainsi, le
xcode correspondant 1, wle code approprié 2et rle code correspondant 4. Le code0correspond à l'absence totale d'autorisations pour travailler avec le fichier. Les autorisations de fichier sont décrites par un nombre à trois chiffres, l'ordre des numéros dans lequel correspond à l'ordre décrit ci-dessus des groupes d'autorisations. Autrement dit, le premier numéro décrit les autorisations du propriétaire du fichier, le second décrit les autorisations du groupe et le troisième décrit les autorisations des autres utilisateurs. Chacun de ces nombres est la somme des codes d'autorisation r, wet x.
Par exemple, une commande du formulaire
chmod 444 filenamesignifie que tout le monde n'aura que le droit de lire le fichier ( r--r--r--), et une commande du formulaire chmod 700 filenameindique que le propriétaire aura le droit de lire, d'écrire et d'exécuter le fichier ( rwx, 4+2+1), et personne d'autre n'a le droit d'effectuer des actions avec le fichier. ( rwx------).
Travailler avec Git
Lorsque vous travaillez avec Git, la séquence d'actions suivante est généralement utilisée:
- Modifier un fichier dans le répertoire de travail local.
- Indexation des fichiers (commande
git add). - Enregistrement d'un instantané des données indexées dans la base de données interne (
git commit). - Soumettre les modifications du référentiel local au remote (
git push). - Chargement des modifications d'un référentiel distant vers un référentiel local (
git pull).
Voici un diagramme illustrant cette séquence d'étapes.
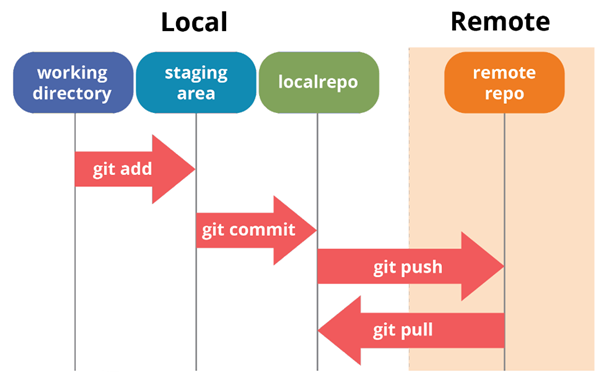
Les
fichiers de flux de travail Git typiques peuvent être dans différents états lorsque vous travaillez avec Git.
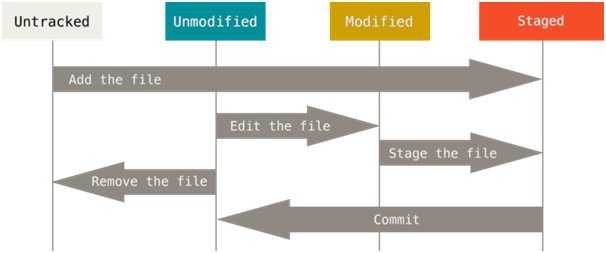
États des fichiers
- Untracked est un fichier que Git ne surveille pas pour les changements. Ce fichier peut être ajouté à l'index et être dans un état par étapes.
- Non modifié - Un fichier qui a été surveillé mais dont le contenu n'a pas changé. Si vous supprimez ce fichier, il ne sera plus surveillé. Si vous le modifiez, il passera à l'état Modifié.
- Modifié - le fichier qui est surveillé, dont le contenu a changé. Il peut être indexé et mis à l'état Staged.
- Staged est un fichier surveillé et inclus dans l'index. Les modifications correspondantes peuvent être fusionnées dans la base de données Git.
Examinons certaines des commandes Git.
git init: Cette commande crée un référentiel Git vide dans le répertoire. Il s'agit de la première étape de la création d'un nouveau référentiel. Après avoir exécuté cette commande, vous pouvez utiliser les commandes git addet git commit.

git addCommande Git init : cette commande ajoute des fichiers à l'index. Il prend en charge, dans le formulairegit add ., l'ajout de tous les fichiers non indexés à l'index, sous la formegit add filename- ajout d'un fichier spécifique à l'index, sous la formegit add dirname- ajout d'un répertoire à l'index.

git commitCommande Git add : cette commande écrit les modifications dans le référentiel local. Ces changements sont appelés, par analogie avec le nom de la commande, "commits". Chaque commit a un identifiant unique, ce qui facilite le travail avec les commits.

git statusCommande Git commit : cette commande vous permet d'obtenir des informations sur l'état actuel du référentiel.
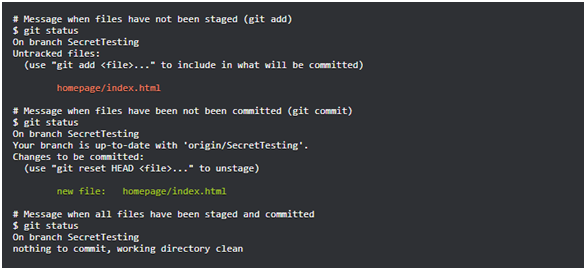
git configCommande d' état Git : cette commande vous permet de personnaliser Git. Parmi les paramètres Git peut être notéuser.nameetuser.email. Ils contiennent le nom de l'utilisateur et l'adresse e-mail utilisés dans les commits et indiquent qui les a effectués. Si ungit configindicateur--globalest utilisélors de l'appel de la commande, lesparamètres sont appliqués à tous les référentiels locaux. Sans cet indicateur, les paramètres s'appliquent uniquement au référentiel actuel.

git checkoutCommande Git config : Cette commande est utilisée pour basculer entre les branches d'un référentiel (asgit checkout <branch_name>). Avec son aide, vous pouvez créer une nouvelle branche et y basculer (git checkout -b <new_branch>).
git merge: Cette commande vous permet de fusionner les branches du référentiel. Il prend les modifications dans une branche et les fusionne dans l'autre branche. Par exemple, il existe une branche qui travaille sur une nouvelle fonctionnalité de projet. Une fois cette fonctionnalité terminée, les modifications sont transmises à la branche qui stocke les fonctionnalités stables.
git clone: Cette commande est utilisée pour créer une copie de travail locale d'un référentiel distant. Lorsqu'il est exécuté, les matériaux du référentiel distant sont téléchargés sur l'ordinateur. Le clonage d'un référentiel existant est comparable à la création d'un nouveau référentiel avec la commandegit init... Mais lors du clonage, nous avons un référentiel à notre disposition, dans lequel il y a déjà quelque chose, et lorsque la commande git initest exécutée , un référentiel vide.
git pull: Cette commande permet de télécharger de nouvelles données à partir d'un référentiel distant.
git push: Cette commande peut être utilisée pour pousser les commits locaux vers le référentiel distant. Lorsque vous appelez cette commande, vous devez lui transmettre des informations sur le référentiel distant et sur la branche du référentiel local, qui doivent être envoyées au référentiel distant.
Résultat
Je vous ai raconté tout ce que j'ai appris au cours de mon voyage dans le monde de Linux et Git. C'était très excitant. J'espère que vous voudrez faire quelque chose de similaire et apprendre quelque chose de nouveau, quelque chose qui élargit vos horizons professionnels.
Si vous avez récemment maîtrisé quelque chose d'intéressant, veuillez nous en parler.

