
WebAssembly (WASM abrégé) est une technologie permettant d'exécuter du code binaire précompilé dans un navigateur côté client. Il a été introduit pour la première fois en 2015 et est actuellement pris en charge par la plupart des navigateurs modernes.
Un cas d'utilisation courant est le prétraitement côté client des données avant l'envoi de fichiers au serveur. Dans cet article, nous allons comprendre comment cela se fait.
Avant le début
L'architecture et les étapes générales de WebAssembly sont décrites plus en détail ici et ici . Nous ne reviendrons que sur les faits de base.
L'utilisation de WebAssembly commence par le pré-assemblage des artefacts requis pour exécuter le code compilé côté client. Il y en a deux: le fichier binaire WASM proprement dit et une couche JavaScript à travers laquelle vous pouvez appeler les méthodes qui y sont exportées.
Un exemple du code C ++ le plus simple pour la compilation
#include <algorithm>
extern "C" {
int calculate_gcd(int a, int b) {
while (a != 0 && b != 0) {
a %= b;
std::swap(a, b);
}
return a + b;
}
}Pour l'assemblage, Emscripten est utilisé , qui, en plus de l'interface principale de ces compilateurs, contient des indicateurs supplémentaires par lesquels la configuration de la machine virtuelle et les méthodes exportées sont définies. Le lancement le plus simple ressemble à ceci:
em++ main.cpp --std=c++17 -o gcd.html \
-s EXPORTED_FUNCTIONS='["_calculate_gcd"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]'En spécifiant un fichier * .html comme objet , il indique au compilateur de créer également un balisage html simple avec une console js. Maintenant, si nous démarrons le serveur sur les fichiers reçus, nous verrons cette console avec la possibilité d'exécuter _calculate_gcd:
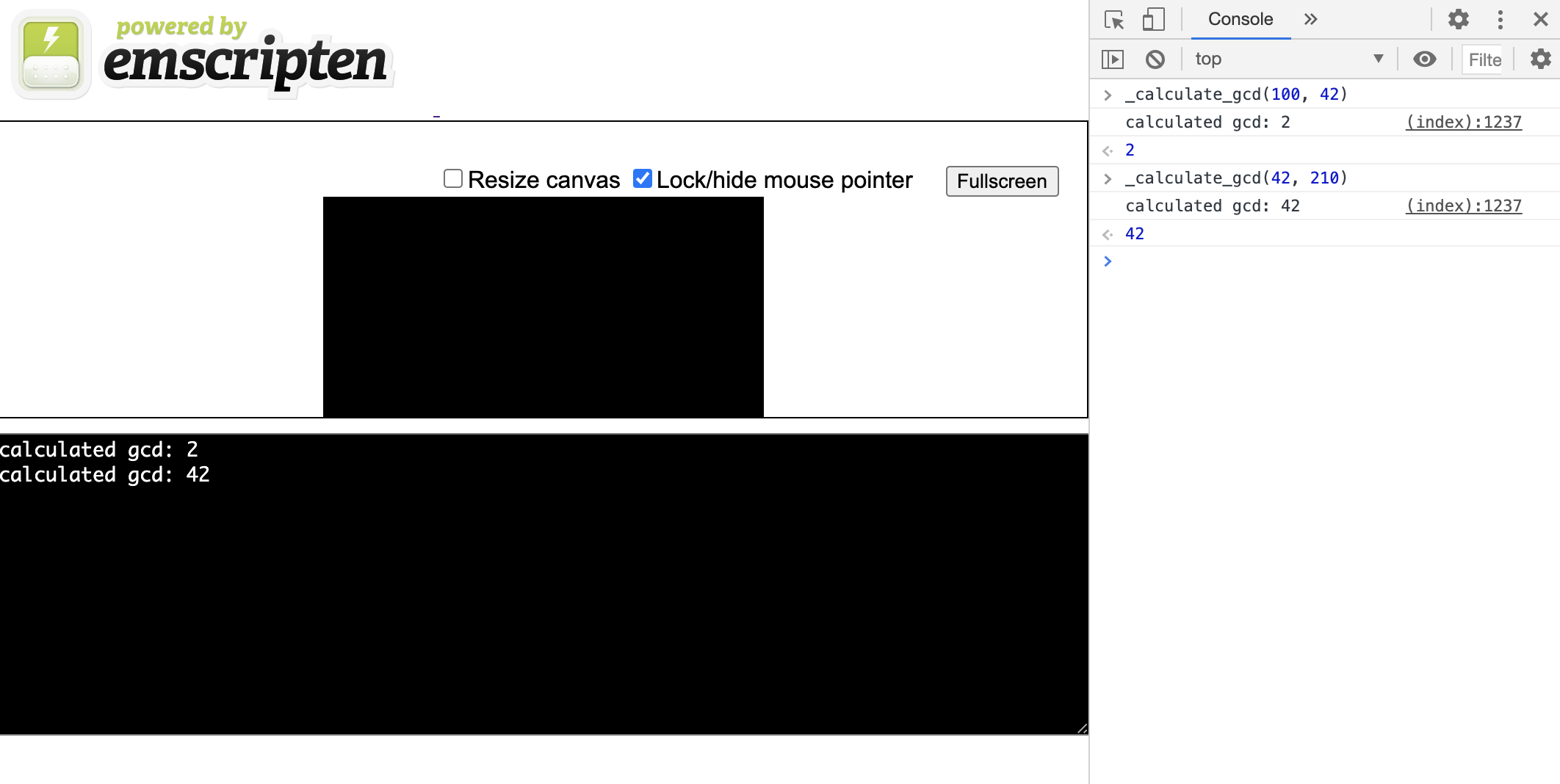
Traitement de l'information
Analysons-le en utilisant un exemple simple de compression lz4 en utilisant une bibliothèque écrite en C ++. Notez que les nombreuses langues prises en charge ne s'arrêtent pas là.
Malgré la simplicité et la nature synthétique de l'exemple, c'est une illustration plutôt utile de la façon de travailler avec des données. De même, vous pouvez effectuer sur eux toutes les actions pour lesquelles la puissance du client est suffisante: prétraitement d'image avant l'envoi au serveur, compression audio, comptage de diverses statistiques, et bien plus encore.
Le code complet peut être trouvé ici.
Partie C ++
Nous utilisons une implémentation prête à l'emploi de lz4 . Ensuite, le fichier principal aura l'air très laconique:
#include "lz4.h"
extern "C" {
uint32_t compress_data(uint32_t* data, uint32_t data_size, uint32_t* result) {
uint32_t result_size = LZ4_compress(
(const char *)(data), (char*)(result), data_size);
return result_size;
}
uint32_t decompress_data(uint32_t* data, uint32_t data_size, uint32_t* result, uint32_t max_output_size) {
uint32_t result_size = LZ4_uncompress_unknownOutputSize(
(const char *)(data), (char*)(result), data_size, max_output_size);
return result_size;
}
}Comme vous pouvez le voir, il déclare simplement les fonctions externes (en utilisant le mot clé extern ) qui appellent en interne les méthodes correspondantes depuis la bibliothèque avec lz4.
D'une manière générale, dans notre cas, le fichier est inutile: vous pouvez immédiatement utiliser l'interface native de lz4.h . Cependant, dans des projets plus complexes (par exemple, combinant les fonctionnalités de différentes bibliothèques), il est pratique d'avoir un tel point d'entrée commun répertoriant toutes les fonctions utilisées.
Ensuite, nous compilons le code en utilisant le compilateur Emscripten déjà mentionné :
em++ main.cpp lz4.c -o wasm_compressor.js \
-s EXPORTED_FUNCTIONS='["_compress_data","_decompress_data"]' \
-s EXTRA_EXPORTED_RUNTIME_METHODS='["cwrap"]' \
-s WASM=1 -s ALLOW_MEMORY_GROWTH=1La taille des artefacts reçus est alarmante:
$ du -hs wasm_compressor.*
112K wasm_compressor.js
108K wasm_compressor.wasm
Si vous ouvrez la couche de fichiers JS, vous pouvez voir quelque chose comme ce qui suit:

Il contient beaucoup de choses inutiles: des commentaires aux fonctions de service, dont la plupart ne sont pas utilisées. La situation peut être corrigée en ajoutant l'indicateur -O2, dans le compilateur Emscripten, il inclut également l'optimisation du code js.
Après cela, le code js est plus joli:

Code client
Vous devez appeler le gestionnaire côté client d'une manière ou d'une autre. Tout d'abord, chargez le fichier fourni par l'utilisateur via
FileReader, nous allons stocker les données brutes dans une primitive Uint8Array:
var rawData = new Uint8Array(fileReader.result);Ensuite, vous devez transférer les données téléchargées vers la machine virtuelle. Pour ce faire, nous allouons d'abord le nombre d'octets requis à l'aide de la méthode _malloc, puis nous y copions le tableau JS à l'aide de la méthode set. Pour plus de commodité, séparons cette logique dans la fonction arrayToWasmPtr (array):
function arrayToWasmPtr(array) {
var ptr = Module._malloc(array.length);
Module.HEAP8.set(array, ptr);
return ptr;
}Après avoir chargé les données dans la mémoire de la machine virtuelle, vous devez en quelque sorte appeler la fonction à partir du traitement. Mais comment trouver cette fonction? La méthode cwrap nous aidera - le premier argument spécifie le nom de la fonction requise, le second - le type de retour et le troisième - une liste avec des arguments d'entrée.
compressDataFunction = Module.cwrap('compress_data', 'number', ['number', 'number', 'number']);Enfin, vous devez renvoyer les octets finis de la machine virtuelle. Pour ce faire, nous écrivons une autre fonction qui les copie dans un tableau JS en utilisant la méthode
subarray
function wasmPtrToArray(ptr, length) {
var array = new Int8Array(length);
array.set(Module.HEAP8.subarray(ptr, ptr + length));
return array;
}Le script complet de traitement des fichiers entrants est ici . Le balisage HTML contenant le formulaire de téléchargement de fichier et les artefacts wasm sont téléchargés ici .
Résultat
Vous pouvez jouer avec le prototype ici .
Le résultat est une sauvegarde fonctionnelle utilisant WASM. Parmi les inconvénients - la mise en œuvre actuelle de la technologie ne permet pas de libérer de la mémoire allouée dans la machine virtuelle. Cela crée une fuite implicite lorsqu'un grand nombre de fichiers est chargé dans une session, mais peut être corrigé en réutilisant la mémoire existante au lieu d'en allouer une nouvelle.

