- Salut! Je vais vous dire quels problèmes vous devez résoudre lorsque vous devez préparer votre service pour des charges de plusieurs centaines de gigabits, voire de térabits par seconde. Nous avons rencontré un tel problème pour la première fois en 2018 alors que nous nous préparions pour les diffusions de la Coupe du monde de football.
Commençons par ce que sont les protocoles de streaming et comment ils fonctionnent - l'option de présentation la plus superficielle.

Tout protocole de streaming est basé sur un manifeste ou une liste de lecture. Il s'agit d'un petit fichier texte contenant des méta-informations sur le contenu. Il décrit le type de contenu - diffusion en direct ou diffusion VoD (vidéo à la demande). Par exemple, dans le cas d'un live, il s'agit d'un match de football ou d'une conférence en ligne, comme nous l'avons maintenant avec vous, et dans le cas de la VoD, votre contenu est préparé à l'avance et se trouve sur vos serveurs, prêt à être distribué aux utilisateurs. Le même fichier décrit la durée du contenu, des informations sur DRM.

Il décrit également les variations de contenu - pistes vidéo, pistes audio, sous-titres. Les pistes vidéo peuvent être représentées dans différents codecs. Par exemple, le H.264 générique est pris en charge sur n'importe quel appareil. Avec lui, vous pouvez lire des vidéos sur n'importe quel fer à repasser de votre maison. Ou il existe des codecs HEVC et VP9 plus modernes et plus efficaces qui vous permettent de diffuser des images 4K HDR.
Les pistes audio peuvent également être présentées dans différents codecs avec différents débits binaires. Et il peut également y en avoir plusieurs - la piste audio originale du film en anglais, la traduction en russe, intershum ou, par exemple, un enregistrement d'un événement sportif directement depuis le stade sans commentateurs.

Que fait le joueur avec tout cela? La tâche du joueur est, tout d'abord, de choisir les variations de contenu qu'il peut lire, simplement parce que tous les codecs ne sont pas universels, ne peuvent pas tous être lus sur un appareil particulier.
Après cela, il doit sélectionner la qualité de la vidéo et de l'audio à partir de laquelle il commencera à jouer. Il peut le faire sur la base des conditions du réseau, s'il les connaît, ou sur la base d'une heuristique très simple. Par exemple, commencez à jouer avec une qualité médiocre et, si le réseau le permet, augmentez lentement la résolution.
À ce stade également, il sélectionne la piste audio à partir de laquelle il commencera à jouer. Supposons que vous ayez l'anglais dans votre système d'exploitation. Ensuite, il peut choisir la piste audio anglaise par défaut. Ce sera peut-être plus pratique pour vous.
Après cela, il commence à générer des liens vers des segments vidéo et audio. En fait, ce sont des liens HTTP réguliers, les mêmes que dans tous les autres scénarios sur Internet. Et il commence à télécharger des segments vidéo et audio, les plaçant l'un après l'autre dans la mémoire tampon et la lecture de manière transparente. Ces segments vidéo durent généralement 2, 4, 6 secondes, peut-être 10 secondes selon votre service.

Quels sont les points importants auxquels nous devons penser lorsque nous concevons notre CDN? Tout d'abord, nous avons une session utilisateur.
Nous ne pouvons pas simplement donner un fichier à un utilisateur et oublier cet utilisateur. Il revient constamment et télécharge de nouveaux et de nouveaux segments dans sa mémoire tampon.
Il est important de comprendre ici que le temps de réponse du serveur compte également. Si nous diffusons une sorte de diffusion en direct en temps réel, nous ne pouvons pas créer une grande mémoire tampon simplement parce que l'utilisateur souhaite regarder la vidéo aussi près que possible du temps réel. En principe, votre tampon ne peut pas être volumineux. En conséquence, si le serveur n'a pas le temps de répondre alors que l'utilisateur a le temps de visualiser le contenu, la vidéo se figera simplement à un moment donné. De plus, le contenu est assez lourd. Le débit binaire standard pour Full HD 1080p est de 3 à 5 Mbps. Par conséquent, sur un serveur Gigabit, vous ne pouvez pas servir plus de 200 utilisateurs en même temps. Et c'est une image idéale, car, en règle générale, les utilisateurs ne suivent pas leurs demandes uniformément dans le temps.

À quel moment un utilisateur interagit-il réellement avec votre CDN? L'interaction se produit principalement à deux endroits: lorsque le lecteur télécharge le manifeste (playlist) et lorsqu'il télécharge des segments.
Nous avons déjà parlé des manifestes, ce sont de petits fichiers texte. Il n'y a pas de problèmes particuliers avec la distribution de ces fichiers. Si vous le souhaitez, distribuez-les depuis au moins un serveur. Et s'il s'agit de segments, ils constituent la majorité de votre trafic. Nous en parlerons.
La tâche de tout notre système est réduite au fait que nous voulons former le lien correct vers ces segments et y substituer le domaine correct de certains de nos hôtes CDN. À ce stade, nous utilisons la stratégie suivante: immédiatement dans la liste de lecture, nous donnons l'hôte CDN souhaité, où l'utilisateur ira. Cette approche est dépourvue de nombreux inconvénients, mais présente une nuance importante. Vous devez vous assurer que vous disposez d'un mécanisme pour éloigner l'utilisateur d'un hôte à un autre de manière transparente pendant la lecture sans interrompre la visualisation. En fait, tous les protocoles de streaming modernes ont cette capacité, HLS et DASH la prennent en charge. Nuance: assez souvent, même dans les bibliothèques open source très populaires, une telle possibilité n'est pas implémentée, bien qu'elle existe par le standard. Nous avons dû nous-mêmes envoyer des bundles à la bibliothèque open source Shaka,c'est javascript, utilisé pour le lecteur Web, pour jouer à DASH.
Il existe un autre schéma - le schéma anycast, lorsque vous utilisez un seul domaine et que vous le donnez dans tous les liens. Dans ce cas, vous n'avez pas besoin de penser à des nuances - vous donnez un domaine et tout le monde est heureux. (...)
Parlons maintenant de la façon dont nous allons former nos liens.
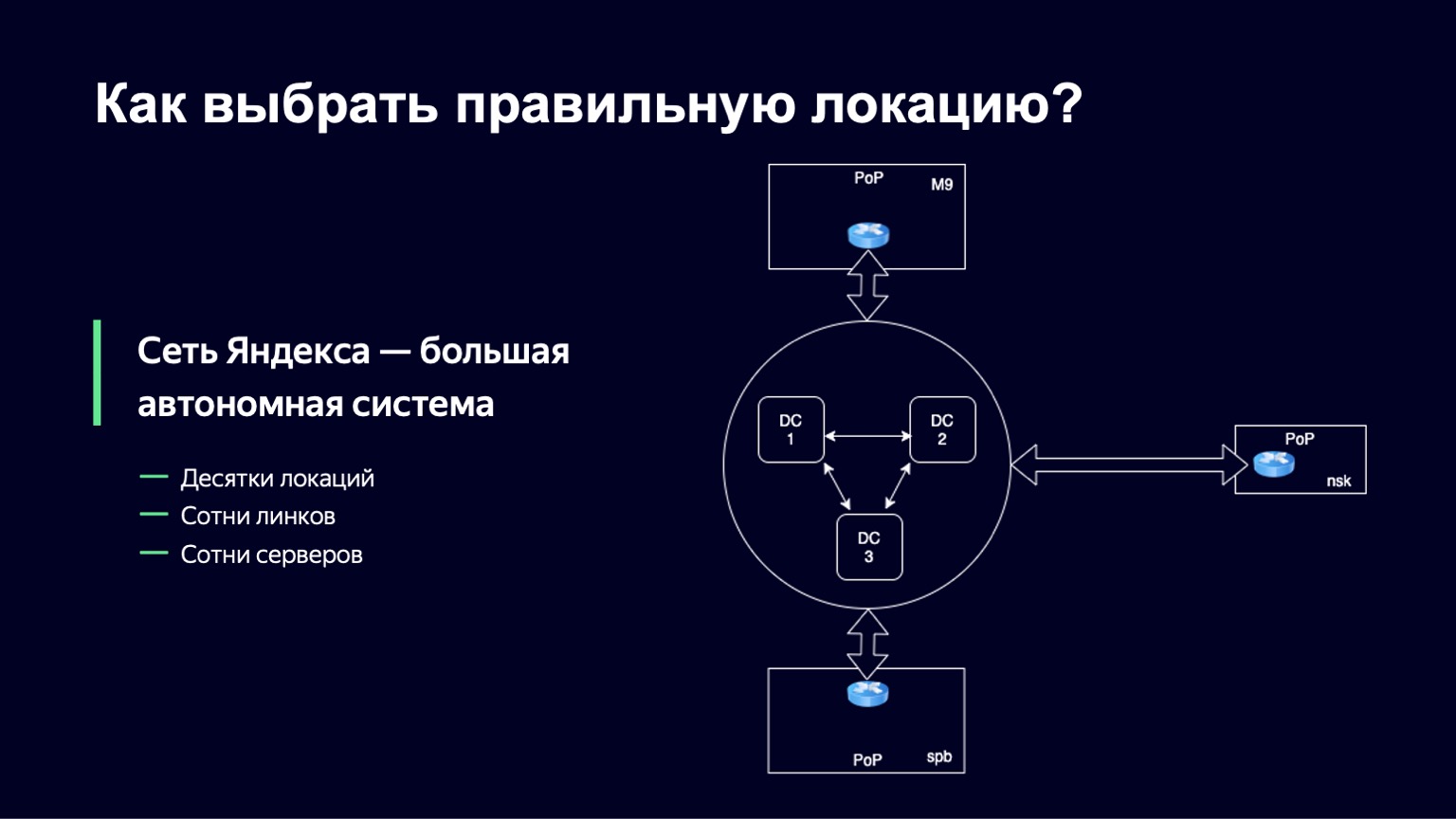
Du point de vue du réseau, toute grande entreprise est organisée comme un système autonome, et souvent même pas un. En fait, un système autonome est un système de réseaux IP et de routeurs qui sont contrôlés par un seul opérateur et fournissent une politique de routage unique avec le réseau externe, avec Internet. Yandex ne fait pas exception. Le réseau Yandex est également un système autonome et la communication avec d'autres systèmes autonomes a lieu en dehors des centres de données Yandex aux points de présence. Des câbles physiques de Yandex, des câbles physiques d'autres opérateurs arrivent à ces points de présence, et ils sont commutés sur place, sur des équipements de fer. C'est à de tels moments que nous avons l'opportunité de mettre plusieurs de nos serveurs, disques durs, SSD. C'est là que nous dirigerons le trafic des utilisateurs.
Nous appellerons cet ensemble de serveurs un emplacement. Et dans chacun de ces emplacements, nous avons un identifiant unique. Nous l'utiliserons dans le cadre du nom de domaine des hébergeurs sur ce site et juste pour l'identifier de manière unique.
Il y a plusieurs dizaines de sites de ce type dans Yandex, il y a plusieurs centaines de serveurs sur eux, et des liens de plusieurs opérateurs arrivent à chaque emplacement, nous avons donc également plusieurs centaines de liens.
Comment choisirons-nous vers quel emplacement envoyer un utilisateur particulier?

Il n'y a pas beaucoup d'options à ce stade. Nous ne pouvons utiliser l'adresse IP que pour prendre des décisions. Une équipe de trafic Yandex distincte nous aide dans ce domaine, qui sait tout sur le fonctionnement du trafic et du réseau dans l'entreprise, et c'est elle qui recueille les itinéraires d'autres opérateurs afin que nous puissions utiliser ces connaissances dans le processus d'équilibrage des utilisateurs.
Il collecte un ensemble de routes à l'aide de BGP. Nous n'allons pas parler de BGP en détail, c'est un protocole qui permet aux participants du réseau aux frontières de leurs systèmes autonomes d'annoncer les routes que leur système autonome peut desservir. L'équipe de trafic recueille toutes ces informations, agrège, analyse et construit une carte complète de l'ensemble du réseau, que nous utilisons pour l'équilibrage.
Nous recevons de l'équipe de trafic un ensemble de réseaux et de liens IP à travers lesquels nous pouvons servir les clients. Ensuite, nous devons comprendre quel sous-réseau IP convient à un utilisateur particulier.
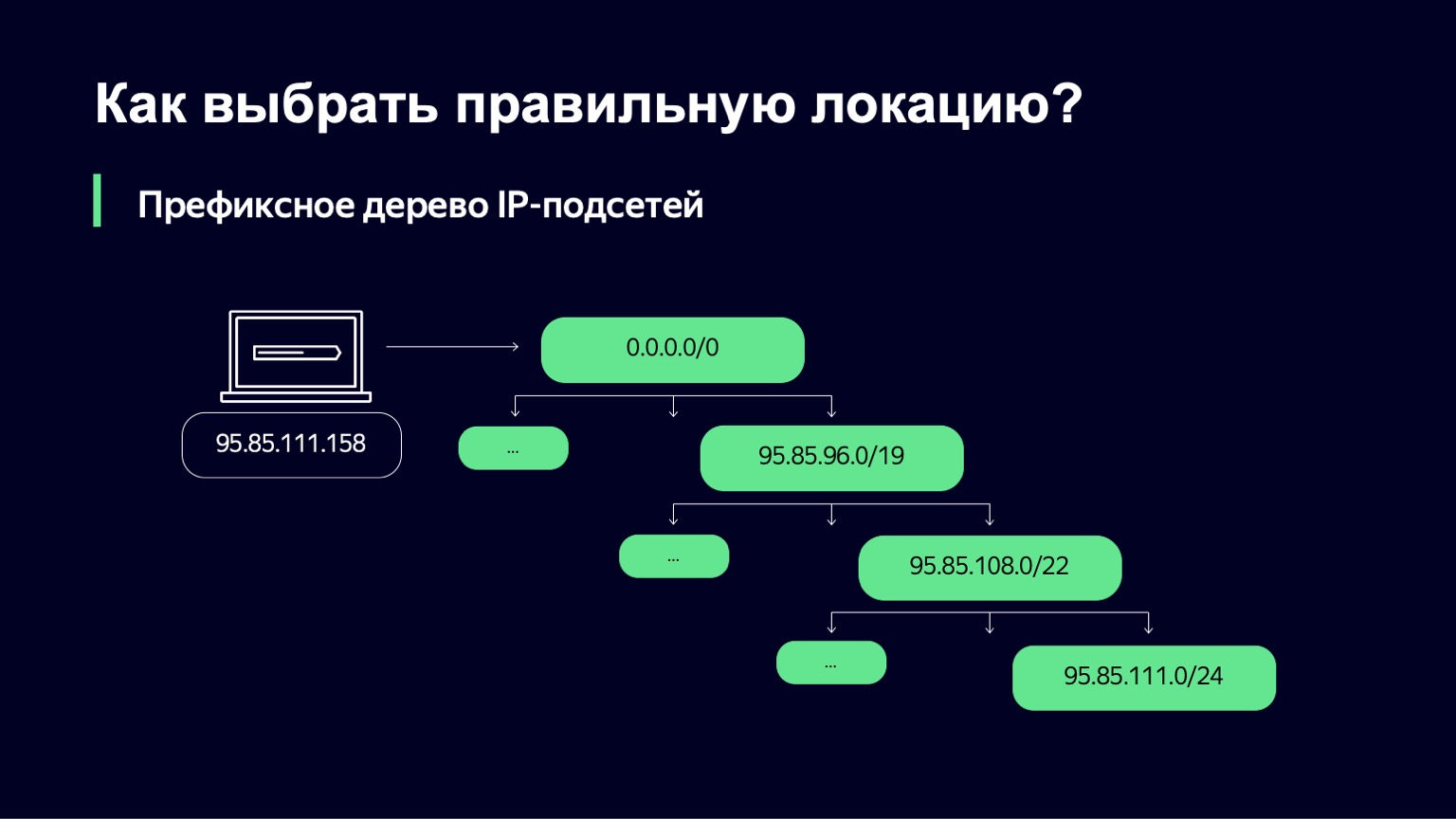
Nous faisons cela d'une manière assez simple - nous construisons un arbre de préfixes. Et puis notre tâche est d'utiliser l'adresse IP de l'utilisateur comme clé pour trouver quel sous-réseau correspond le plus à cette adresse IP.
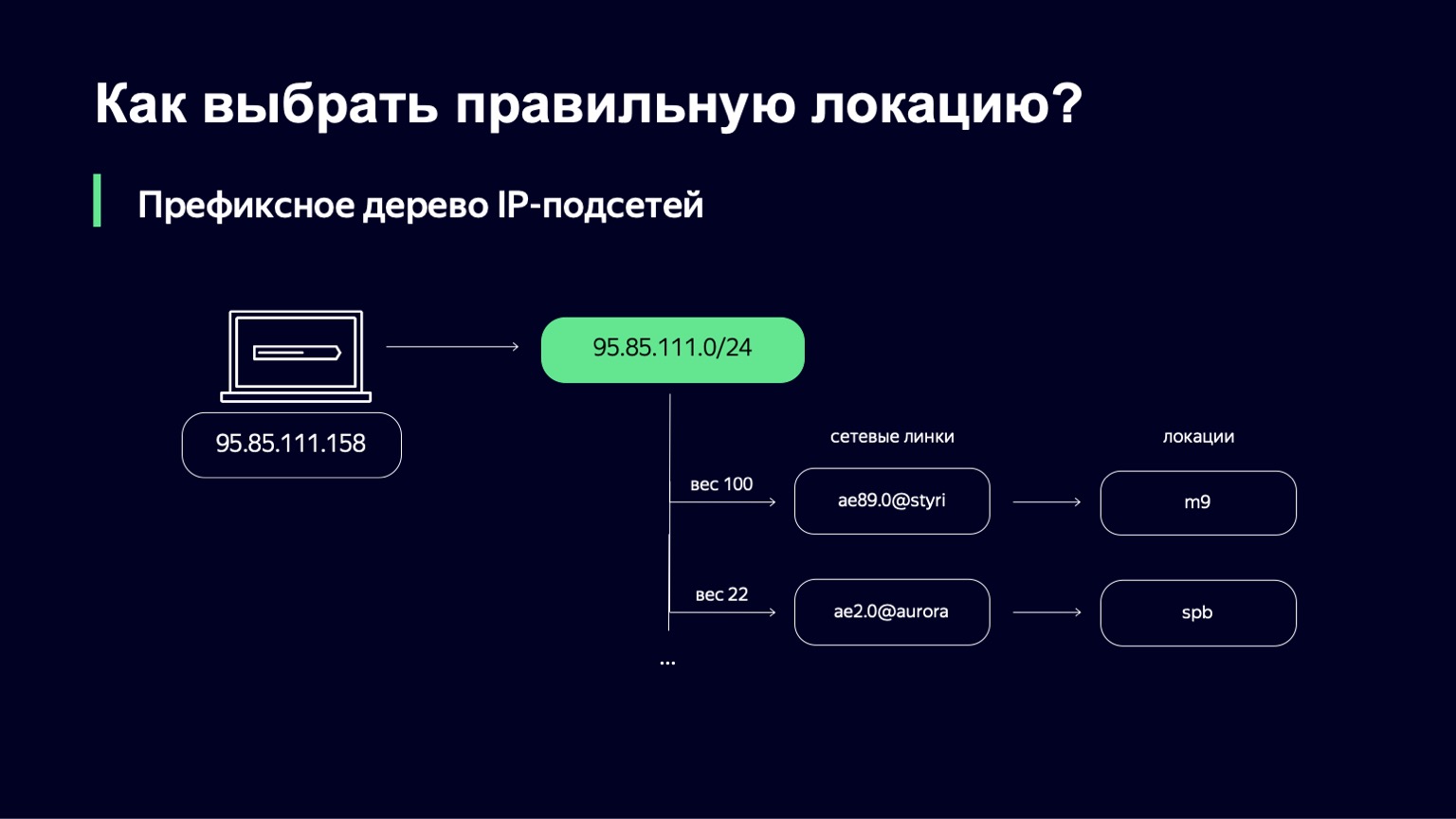
Lorsque nous l'avons trouvé, nous avons une liste de liens, leurs poids et, par des liens, nous pouvons déterminer de manière unique l'emplacement où nous enverrons l'utilisateur.

Quel est le poids dans cet endroit? Il s'agit d'une métrique qui vous permet de gérer la répartition des utilisateurs sur différents emplacements. On peut avoir des liens, par exemple, de capacités différentes. Nous pouvons avoir un lien 100 Gigabit et un lien 10 Gigabit sur le même site. De toute évidence, nous voulons envoyer plus d'utilisateurs vers le premier lien, car il est plus volumineux. Ce poids prend en compte la topologie du réseau, car Internet est un graphe complexe d'équipements réseau interconnectés, votre trafic peut emprunter des chemins différents, et cette topologie doit également être prise en compte.
Assurez-vous de regarder comment les utilisateurs téléchargent réellement les données. Cela peut être fait à la fois côté serveur et côté client. Sur le serveur, nous collectons activement les connexions des utilisateurs dans les journaux d'informations TCP, en examinant le temps d'aller-retour. Du côté de l'utilisateur, nous collectons activement les journaux de performances du navigateur et des joueurs. Ces journaux de performance contiennent des informations détaillées sur la manière dont les fichiers ont été téléchargés à partir de notre CDN.
Si nous analysons tout cela, agrégons, puis avec l'aide de ces données, nous pouvons améliorer les poids qui ont été choisis lors de la première étape par l'équipe de trafic.

Disons que nous avons sélectionné un lien. Pouvons-nous y envoyer des utilisateurs à ce stade? Nous ne pouvons pas, car le poids est assez statique sur une longue période de temps, et il ne prend en compte aucune dynamique réelle de la charge. Nous voulons déterminer en temps réel si nous pouvons maintenant utiliser un lien qui est, disons, chargé à 80%, alors qu'il y a un lien de priorité légèrement inférieure à proximité qui n'est chargé qu'à 10%. Très probablement, dans ce cas, nous voulons simplement utiliser le second.

Que faut-il encore prendre en compte dans cet endroit? Il faut prendre en compte la bande passante du lien, comprendre son état actuel. Cela peut fonctionner ou être techniquement défectueux. Ou peut-être voulons-nous l'amener au service afin de ne pas laisser les utilisateurs là-bas et de le servir, de l'étendre, par exemple. Il faut toujours prendre en compte la charge actuelle de ce lien.
Il y a ici quelques nuances intéressantes. Vous pouvez collecter des informations sur le chargement des liens en plusieurs points - par exemple, sur l'équipement réseau. C'est le moyen le plus précis, mais son problème est que sur l'équipement réseau, vous ne pouvez pas obtenir une période de mise à jour rapide pour ce téléchargement. Par exemple, à Yandex, l'équipement du réseau est assez varié, et nous ne pouvons pas collecter ces données plus d'une fois par minute. Si le système est assez stable en termes de charge, ce n'est pas du tout un problème. Tout fonctionnera très bien. Mais dès que vous avez des afflux soudains de charge, vous n'avez tout simplement pas le temps de réagir, ce qui conduit, par exemple, à des baisses de colis.
D'autre part, vous savez combien d'octets ont été envoyés à l'utilisateur. Vous pouvez collecter ces informations sur les machines distributrices elles-mêmes, créer directement un compteur d'octets. Mais ce ne sera pas aussi précis. Pourquoi?
Il y a d'autres utilisateurs sur notre CDN. Nous ne sommes pas le seul service à utiliser ces distributeurs. Et dans le contexte de notre charge, la charge des autres services n'est pas si importante. Mais même dans notre contexte, cela peut être tout à fait perceptible. Leurs distributions ne passent pas par notre circuit, nous ne pouvons donc pas contrôler ce trafic.
Autre point: même si vous pensez sur la machine émettrice que vous avez envoyé du trafic vers un lien spécifique, c'est loin d'être un fait, car BGP en tant que protocole ne vous donne pas une telle garantie. Et il existe des moyens d'augmenter la probabilité que vous devinerez, mais c'est un sujet pour une autre discussion.

Disons que nous avons calculé les métriques, tout collecté. Nous avons maintenant besoin d'un algorithme pour prendre une décision lors de l'équilibrage. Il doit avoir quatre propriétés importantes:
- Fournir la bande passante du lien.
- Évitez la surcharge de lien, simplement parce que si vous avez chargé un lien à 95% ou 98%, les tampons sur l'équipement réseau commencent à déborder, les paquets perdus, les retransmissions commencent et les utilisateurs n'en tirent rien de bon.
- Pour avertir "bu" des charges, nous en reparlerons un peu plus tard.
«Dans un monde idéal, ce serait formidable si nous pouvions apprendre à recycler un lien à un certain niveau que nous pensons être juste. Par exemple, 85% de téléchargement.

Nous avons pris l'idée suivante comme base. Nous avons deux classes différentes de sessions utilisateur. Le premier cours concerne les nouvelles sessions, lorsque l'utilisateur vient d'ouvrir le film, n'a encore rien regardé et nous essayons de savoir où l'envoyer. Ou la deuxième classe, lorsque nous avons une session en cours, l'utilisateur est déjà servi sur le lien, occupe une certaine partie de la bande passante, est servi sur un serveur spécifique.
Qu'allons-nous en faire? Nous introduisons une valeur probabiliste pour chacune de ces classes de la session. Nous aurons une valeur appelée Slowdown, qui détermine le pourcentage de nouvelles sessions que nous n'autoriserons pas sur ce lien. Si le ralentissement est nul, alors nous acceptons toutes les nouvelles sessions, et s'il est de 50%, alors chaque deuxième session, grosso modo, nous refusons de servir sur ce lien. En même temps, notre algorithme d'équilibrage à un niveau supérieur vérifiera les alternatives pour cet utilisateur. Drop - le même, uniquement pour les sessions en cours. Nous pouvons retirer certaines des sessions utilisateur du site ailleurs.
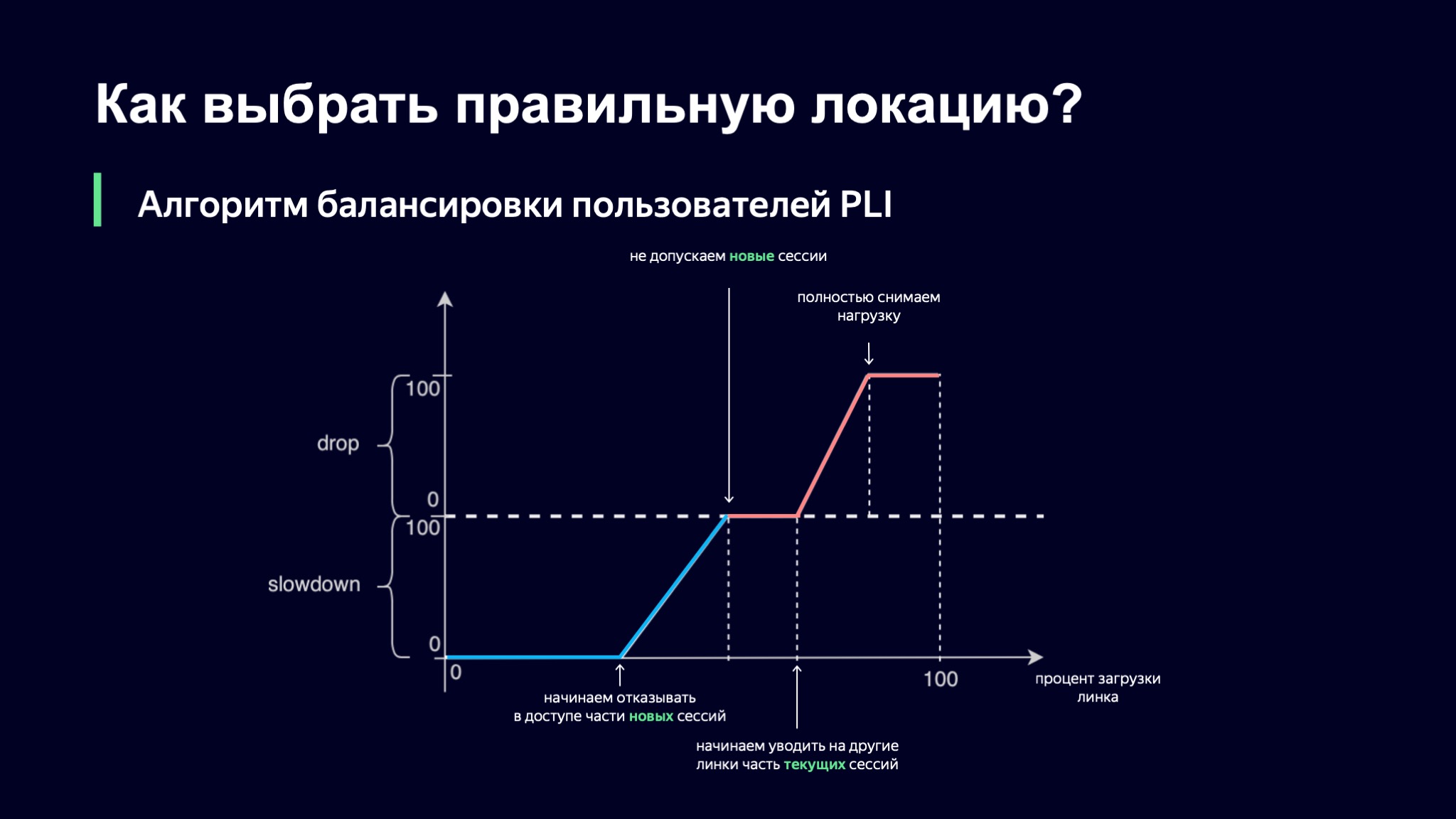
Comment choisissons-nous la valeur de nos métriques probabilistes? Prenons le pourcentage de la charge de liaison comme base, puis notre première idée était la suivante: utilisons une interpolation linéaire par morceaux.
Nous avons pris une telle fonction, qui a plusieurs points de réfraction, et nous regardons la valeur de nos coefficients en l'utilisant. Si le niveau de téléchargement du lien est minimal, alors tout va bien, Slowdown et Drop sont égaux à zéro, nous laissons entrer tous les nouveaux utilisateurs. Dès que le niveau de charge franchit un certain seuil, nous commençons à refuser le service à certains utilisateurs sur ce lien. À un moment donné, si la charge continue d'augmenter, nous arrêtons simplement de lancer de nouvelles sessions.
Il y a ici une nuance intéressante: les sessions en cours sont prioritaires dans ce schéma. Je pense qu'il est clair pourquoi cela se produit: si votre utilisateur vous fournit déjà un modèle de charge stable, vous ne voulez pas l'emmener nulle part, car de cette façon vous augmentez la dynamique du système, et plus le système est stable, plus il nous est facile de le contrôler.
Cependant, le téléchargement peut continuer à augmenter. À un moment donné, nous pouvons commencer à supprimer certaines sessions ou même supprimer complètement la charge de ce lien.
C'est sous cette forme que nous avons lancé cet algorithme lors des premiers matchs de la Coupe du monde de football. Il est probablement intéressant de voir quelle image nous avons vue. Elle parlait de ce qui suit.
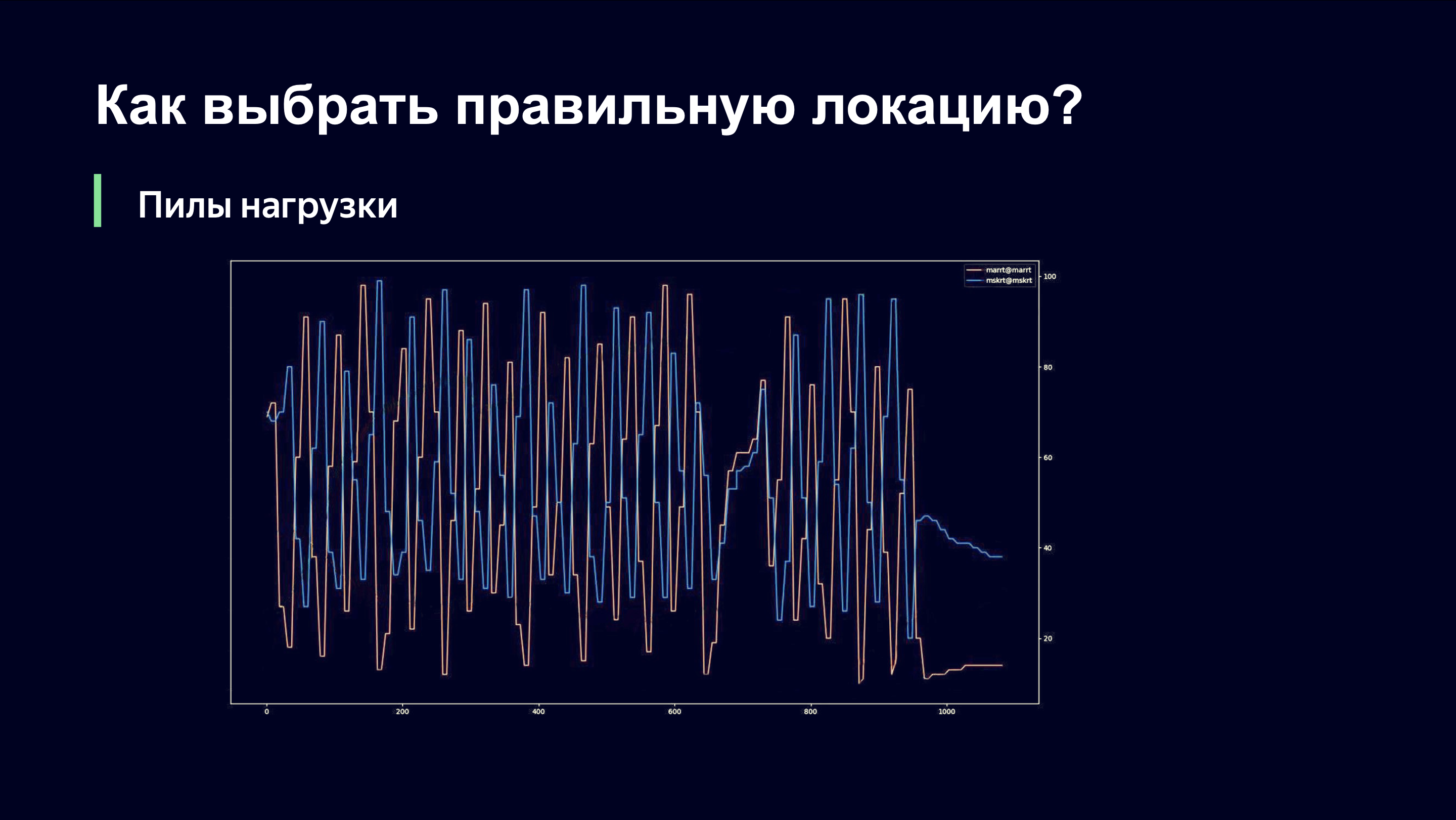
Même à l'œil nu, un observateur extérieur peut comprendre que quelque chose ne va probablement pas ici, et me demander: "Andrey, ça va bien?" Et si vous étiez mon patron, vous courriez dans la pièce en criant: «Andrey, mon Dieu! Faites rouler le tout! Remettez tout tel quel! " Disons ce qui se passe ici.
Sur l'axe X, le temps, sur l'axe Y, on observe le niveau de charge de la liaison. Il existe deux liens qui desservent le même site. Il est important de comprendre qu'à ce moment, nous n'avons utilisé que le schéma de surveillance de charge de liaison qui est retiré de l'équipement de réseau, et ne pouvait donc pas répondre rapidement à la dynamique de charge.
Lorsque nous envoyons des utilisateurs vers l'un des liens, il y a une forte augmentation du trafic sur ce lien. Le lien est surchargé. Nous déchargons et nous nous retrouvons sur le côté droit de la fonction que nous avons vue dans le graphique précédent. Et nous commençons à abandonner les anciens utilisateurs et à cesser d'en laisser entrer de nouveaux. Ils doivent aller quelque part, et ils vont, bien sûr, au lien suivant. La dernière fois, c'était peut-être une priorité moindre, mais maintenant ils l'ont en priorité.
Le deuxième lien répète la même image. On augmente fortement la charge, on constate que le lien est surchargé, on enlève la charge, et ces deux liens sont en antiphase en termes de niveau de charge.
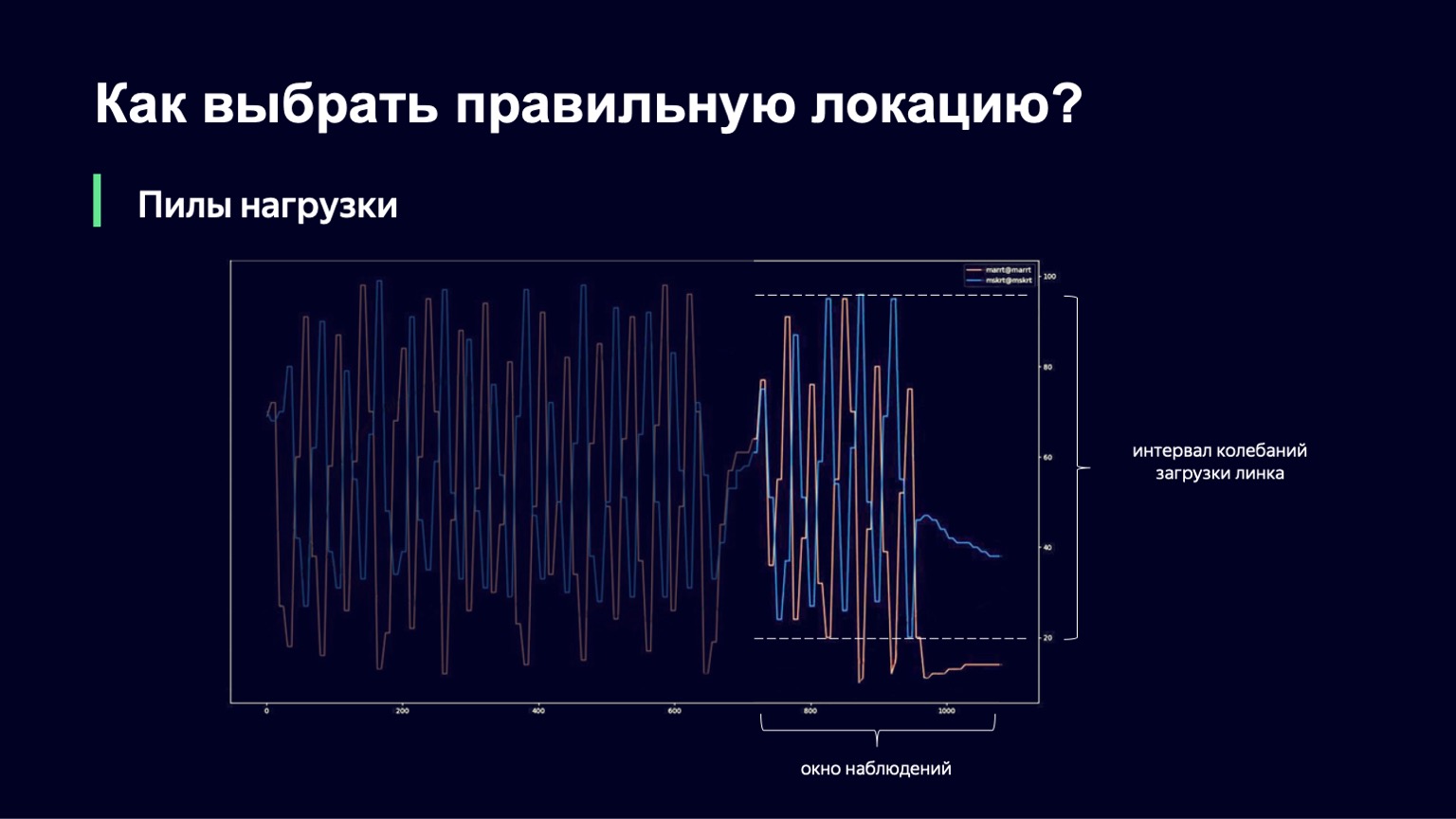
Ce qui peut être fait? Nous pouvons analyser la dynamique du système, le remarquer avec une forte augmentation de la charge et l'amortir un peu. C'est exactement ce que nous avons fait. Nous avons pris le moment actuel, avons pris la fenêtre d'observation dans le passé pendant quelques minutes, par exemple 2-3 minutes, et avons regardé combien la charge de liaison change dans cet intervalle. La différence entre les valeurs minimum et maximum sera appelée intervalle d'oscillation de ce lien. Et si cet intervalle d'oscillation est grand, nous ajouterons de l'amortissement, augmentant ainsi notre ralentissement et commençant à exécuter moins de sessions.
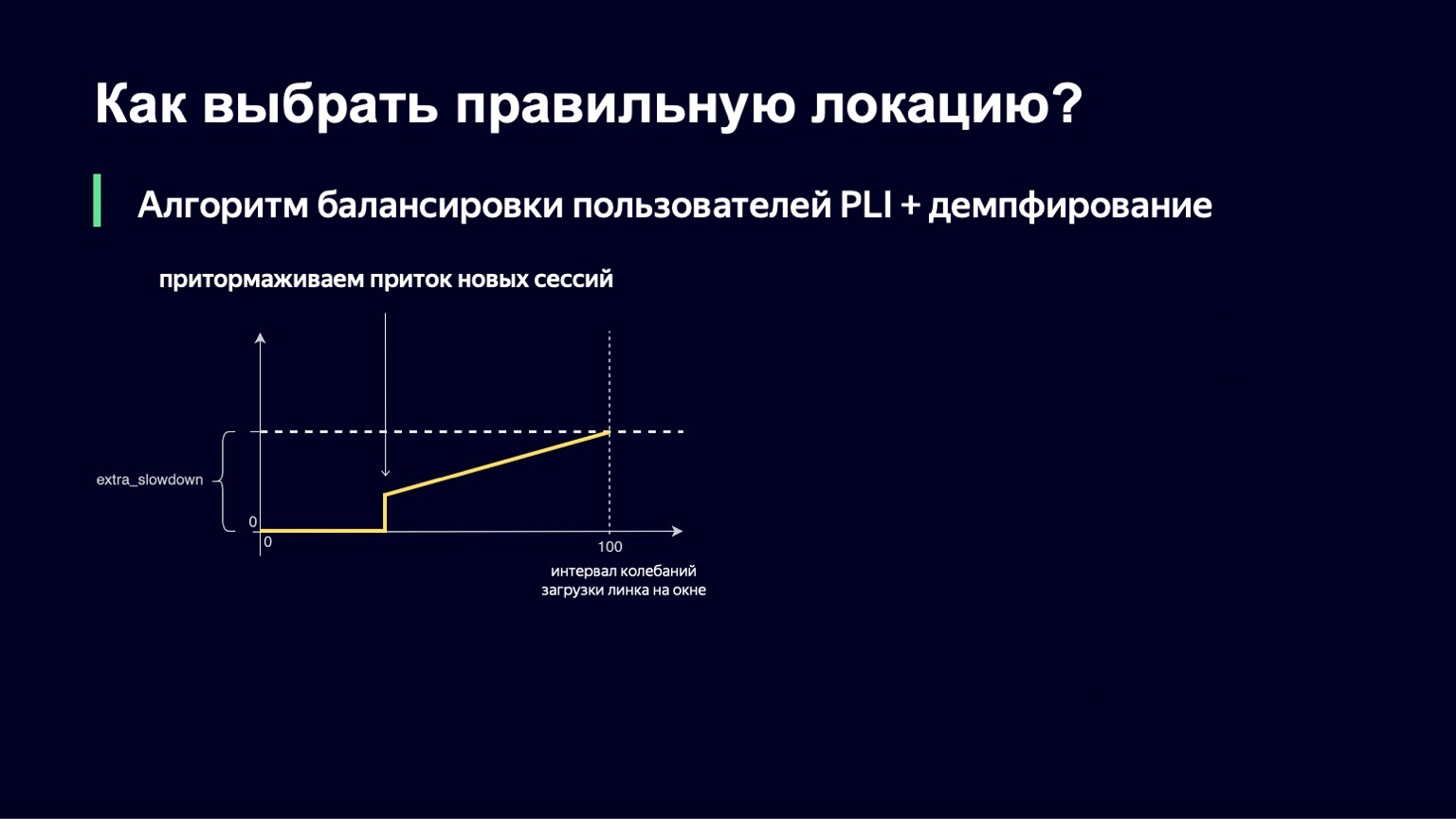
Cette fonction ressemble à peu près à la précédente, avec un peu moins de fractures. Si nous avons un petit intervalle pour télécharger les oscillations, nous n'ajouterons aucun extra_slowdown. Et si l'intervalle d'oscillation commence à augmenter, alors extra_slowdown prend des valeurs non nulles, plus tard nous l'ajouterons au ralentissement principal.
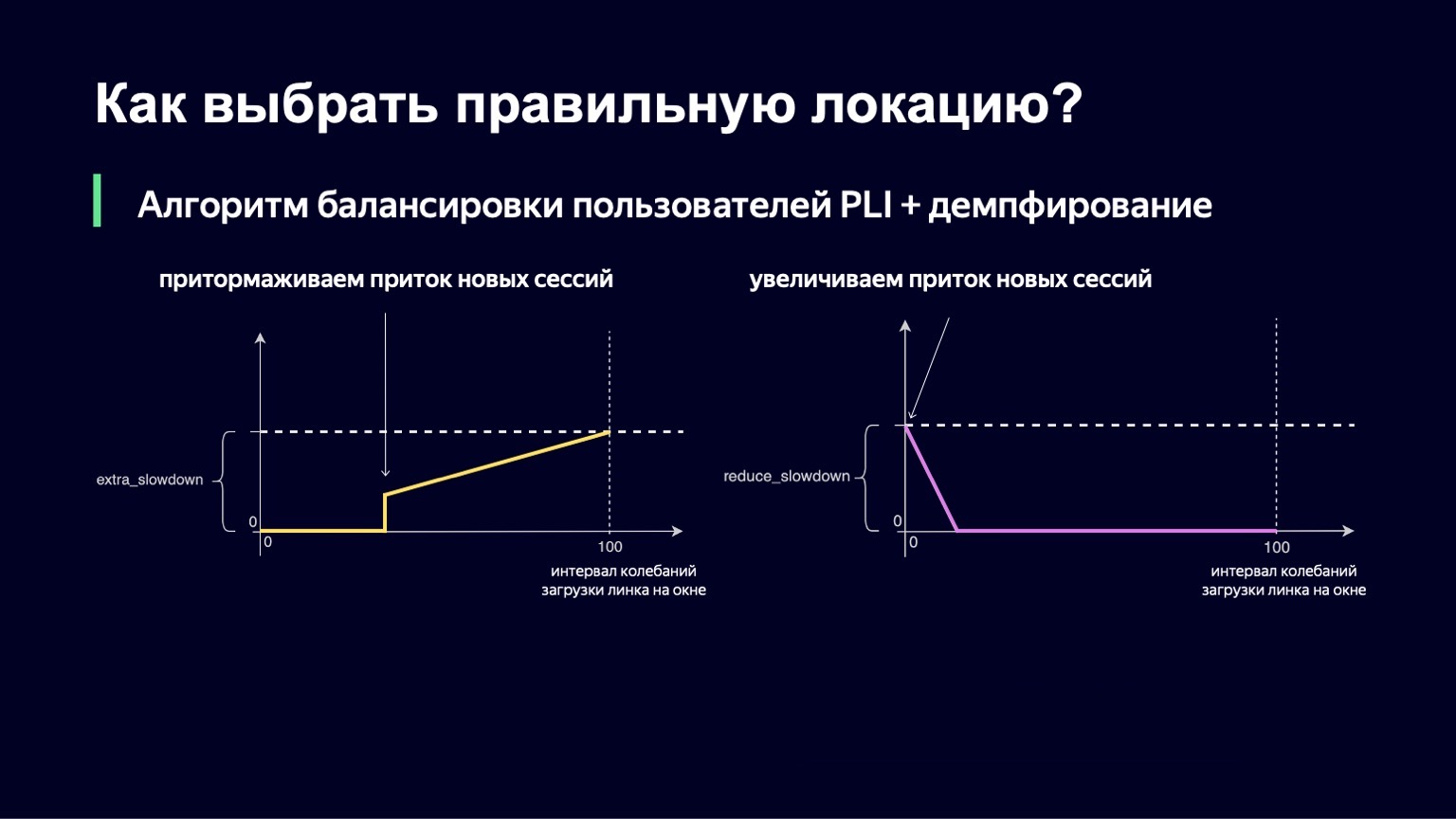
La même logique fonctionne à des valeurs faibles de l'intervalle d'oscillation. Si vous avez un minimum d'hésitation sur le lien, alors, au contraire, vous voulez laisser un peu plus d'utilisateurs là-bas, réduire le ralentissement et ainsi mieux utiliser votre lien.
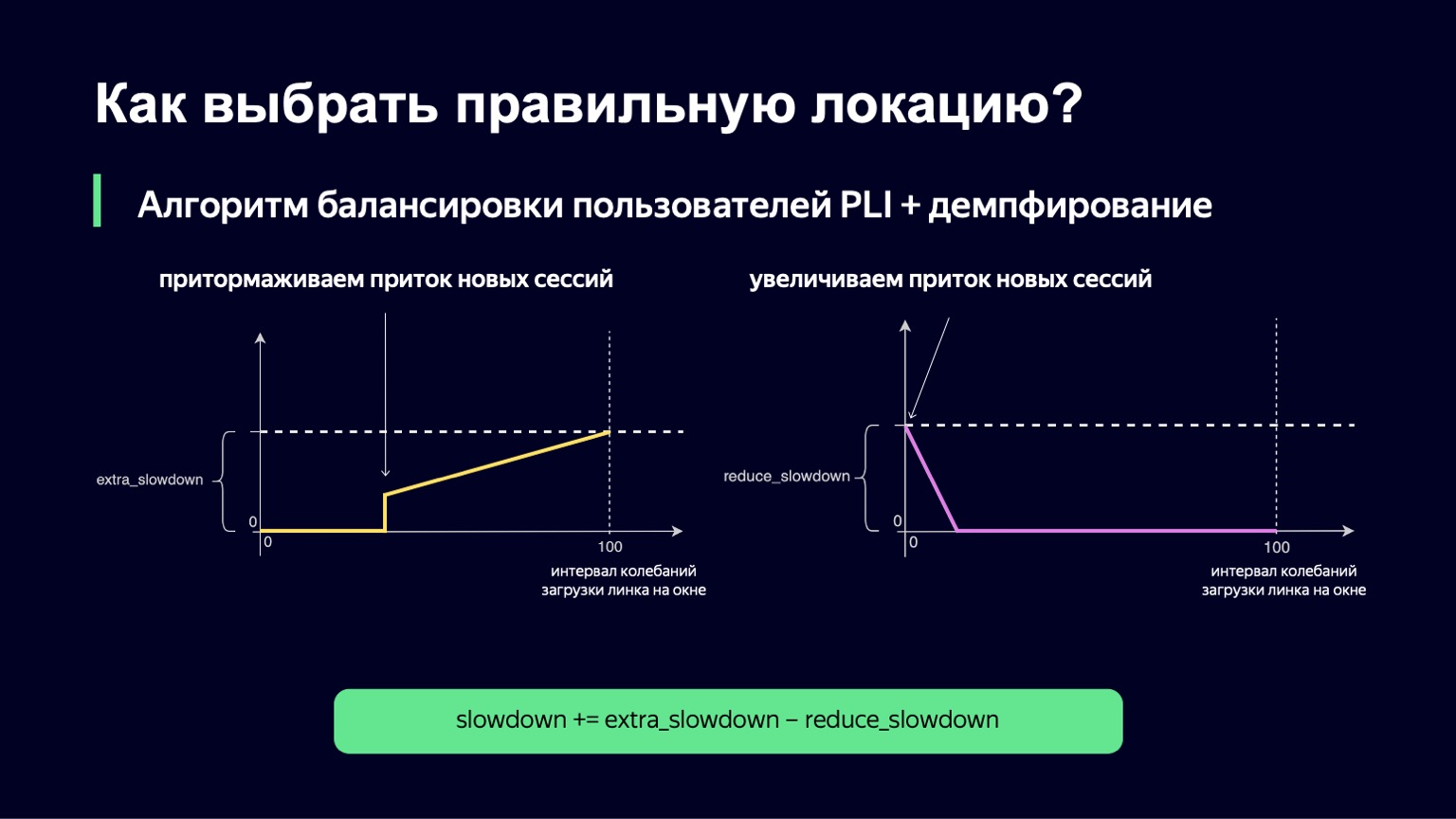
Nous avons également implémenté cette partie. La formule finale ressemble à ceci. Dans le même temps, nous garantissons que ces deux valeurs - extra_slowdown et reduction_slowdown - n'ont jamais une valeur différente de zéro en même temps, donc une seule d'entre elles fonctionne efficacement. C'est sous cette forme que cette formule d'équilibrage a survécu à tous les meilleurs matches de la Coupe du monde. Même dans les matchs les plus populaires, elle a plutôt bien travaillé: ce sont "Russie - Croatie", "Russie - Espagne". Au cours de ces matchs, nous avons distribué un record pour les volumes de trafic Yandex - 1,5 térabit par seconde. Nous l'avons traversé calmement. Depuis lors, la formule n'a en rien changé, car il n'y a pas eu de trafic de ce type sur notre service depuis lors - jusqu'à un certain moment.
Puis une pandémie nous est venue. Les gens ont été envoyés s'asseoir à la maison, et à la maison il y a une bonne connexion Internet, une télévision, une tablette et beaucoup de temps libre. Le trafic vers nos services a commencé à croître de manière organique, plutôt rapidement et de manière significative. Aujourd'hui, ce genre de charge, comme lors de la Coupe du monde, est notre routine quotidienne. Depuis, nous avons un peu élargi nos canaux avec les opérateurs, mais nous avons néanmoins commencé à réfléchir à la prochaine itération de notre algorithme, à ce qu'elle devrait être et à la manière dont nous pouvons mieux utiliser notre réseau.

Quels sont les inconvénients de notre algorithme précédent? Nous n'avons pas résolu deux problèmes. Nous ne nous sommes pas complètement débarrassés des charges de «scie». Nous avons grandement amélioré l'image et l'amplitude de ces fluctuations est minime, la période a considérablement augmenté, ce qui permet également une meilleure utilisation du réseau. Mais tout de même ils apparaissent de temps en temps, restent. Nous n'avons pas appris à utiliser le réseau au niveau souhaité. Par exemple, nous ne pouvons pas utiliser la configuration pour définir le niveau de charge de liaison maximal souhaité de 80 à 85%.

Que pensons-nous de la prochaine itération de l'algorithme? Comment envisageons-nous l'utilisation idéale du réseau? L'un des domaines prometteurs, semble-t-il, est l'option lorsque vous disposez d'un seul endroit pour prendre des décisions sur le trafic. Vous collectez toutes les métriques en un seul endroit, une demande utilisateur de téléchargement de segments arrive, et à chaque instant, vous avez un état complet du système, il vous est très facile de prendre des décisions.
Mais il y a deux nuances ici. Premièrement, il n'est pas d'usage dans Yandex d'écrire des «points de décision communs», tout simplement parce qu'avec nos niveaux de charge, avec notre trafic, un tel endroit devient rapidement un goulot d'étranglement.
Il y a une autre nuance: il est également important d'écrire des systèmes tolérants aux pannes dans Yandex. Nous fermons souvent complètement les centres de données, tandis que votre composant devrait continuer à fonctionner sans erreur, sans interruption. Et sous cette forme, cet endroit unique devient, en fait, un système distribué que vous devez contrôler, et c'est une tâche légèrement plus difficile que celle que nous aimerions résoudre ici.

Nous avons certainement besoin de métriques rapides. Sans eux, la seule chose que vous pouvez faire pour éviter la souffrance des utilisateurs est de sous-utiliser le réseau. Mais cela ne nous convient pas non plus.
Si vous regardez notre système à un niveau élevé, il devient clair que notre système est un système dynamique avec rétroaction. Nous avons une charge personnalisée, qui est un signal d'entrée. Les gens vont et viennent. Nous avons un signal de contrôle - les deux valeurs que nous pouvons modifier en temps réel. Pour de tels systèmes dynamiques avec rétroaction, la théorie du contrôle automatique a été développée depuis longtemps, plusieurs décennies. Et ce sont ses composants que nous aimerions utiliser pour stabiliser notre système.
Nous avons examiné le filtre de Kalman. C'est une chose tellement cool qui vous permet de construire un modèle mathématique du système et, avec des métriques bruyantes ou en l'absence de certaines classes de métriques, d'améliorer le modèle en utilisant votre système réel. Et puis prendre une décision sur un système réel basé sur un modèle mathématique. Malheureusement, il s'est avéré que nous n'avons pas beaucoup de classes de métriques que nous pouvons utiliser, et cet algorithme ne peut pas être appliqué.
Nous nous sommes approchés de l'autre côté, nous avons pris comme base un autre composant de cette théorie - le contrôleur PID. Il ne sait rien de votre système. Son travail est de connaître l'état idéal du système, c'est-à-dire le niveau de charge souhaité et l'état actuel du système, par exemple, le niveau de charge. Il considère la différence entre ces deux états comme une erreur et, à l'aide de ses algorithmes internes, gère le signal de commande, c'est-à-dire nos valeurs de ralentissement et de chute. Son but est de minimiser l'erreur dans le système.
Nous allons essayer ce contrôleur PID en production au jour le jour. Peut-être que dans quelques mois, nous pourrons vous parler des résultats.
Sur ce, nous finirons probablement sur le réseau. J'aimerais beaucoup vous parler de la façon dont nous distribuons le trafic au sein même de l'emplacement, lorsque nous l'avons déjà choisi entre les hôtes. Mais il n'y a pas de temps pour ça. C'est probablement un sujet pour un grand rapport séparé.

Par conséquent, dans la prochaine série, vous apprendrez comment utiliser de manière optimale le cache sur les hôtes, que faire avec le trafic chaud et froid, ainsi que d'où vient le trafic chaud, comment le type de contenu affecte l'algorithme pour sa distribution et quelle vidéo donne le plus grand succès de cache sur le service, et qui qui chante une chanson.
J'ai une autre histoire intéressante. Au printemps, comme vous le savez, la quarantaine a commencé. Yandex dispose depuis longtemps d'une plate-forme pédagogique appelée Yandex.Tutorial, qui permet aux enseignants de télécharger des vidéos et des leçons. Les étudiants viennent là-bas et regardent le contenu. Pendant la pandémie, Yandex a commencé à soutenir les écoles, à les inviter activement sur sa plateforme afin que les étudiants puissent étudier à distance. Et à un moment donné, nous avons vu une assez bonne croissance du trafic, une image assez stable. Mais un des soirs d'avril, nous avons vu quelque chose comme ce qui suit sur les graphiques.
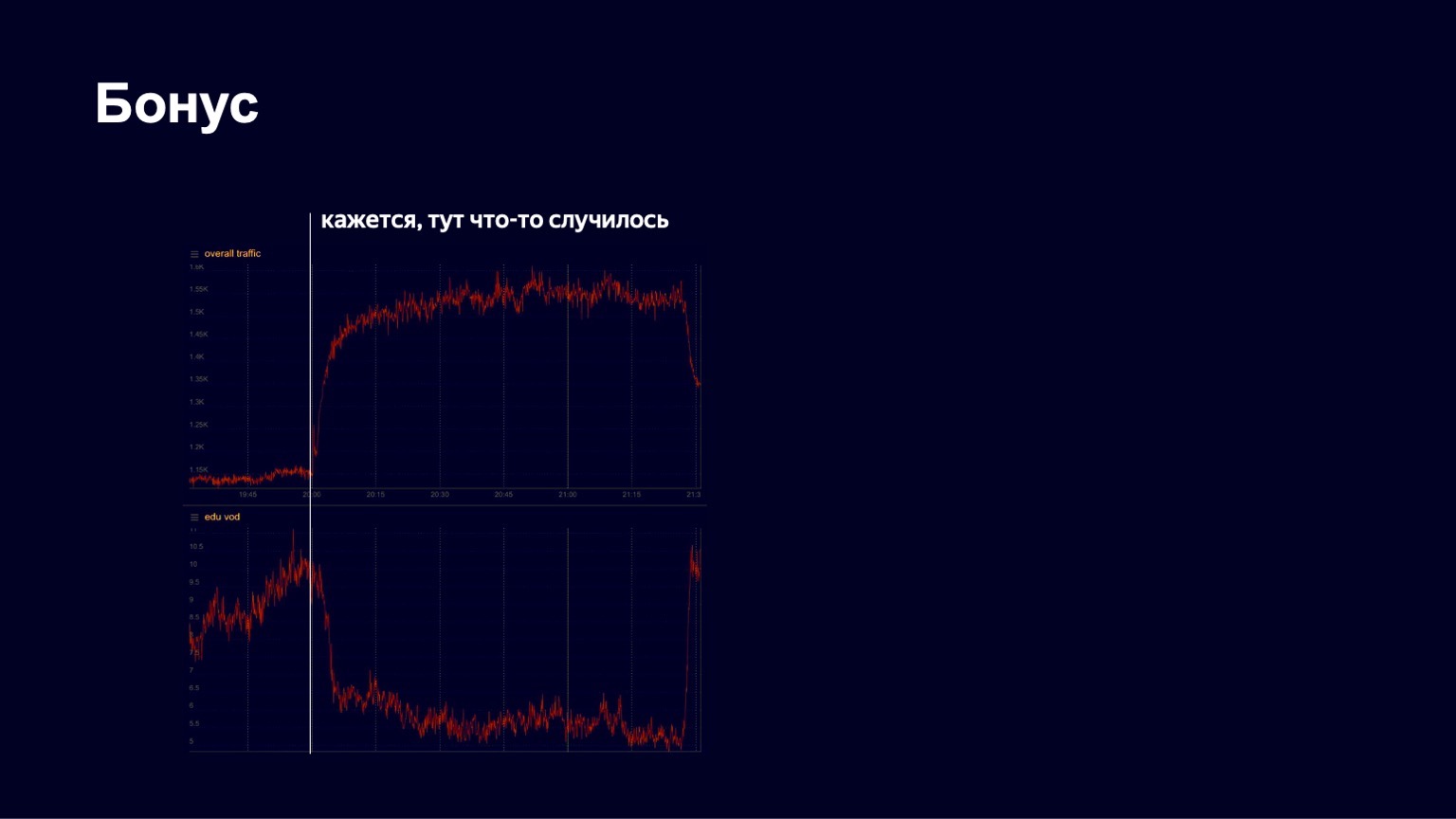
Ci-dessous, une image du trafic sur le contenu éducatif. Nous avons vu qu'il est tombé brusquement à un moment donné. Nous avons commencé à paniquer, à découvrir ce qui se passait en général, ce qui était cassé. Ensuite, nous avons remarqué que le trafic total vers le service a commencé à augmenter. De toute évidence, quelque chose d'intéressant s'est produit.
En fait, à ce moment-là, ce qui suit s'est produit.
C'est à quelle vitesse l'homme danse.
Le concert de Little Big a commencé et tous les étudiants sont partis pour le regarder. Mais après la fin du concert, ils sont revenus et ont continué à étudier avec succès. Nous voyons de telles images assez souvent sur notre service. Par conséquent, je pense que notre travail est assez intéressant. Merci à tous! Je finirai probablement par ceci à propos de CDN.