Cet article portera sur cette nuance.
Je lance le sélénium comme d'habitude, et après le premier clic sur le lien où se trouve le tableau requis avec les résultats des élections de la République du Tatarstan, il plante

Comme vous l'avez compris, la nuance réside dans le fait qu'après chaque clic sur le lien, un captcha apparaît.
Après avoir analysé la structure du site, il a été constaté que le nombre de liens atteint environ 30 mille.
Je n'avais pas d'autre choix que de rechercher sur Internet des moyens de reconnaître le captcha. Un service trouvé
+ Captcha est reconnu à 100%, tout comme une personne
- Le temps de reconnaissance moyen est de 9 secondes, ce qui est très long, car nous avons environ 30000 liens différents, que nous devons suivre et reconnaître le captcha.
J'ai immédiatement abandonné cette idée. Après plusieurs tentatives pour obtenir le captcha, j'ai remarqué que cela ne change pas grand-chose, tous les mêmes chiffres noirs sur fond vert.
Et comme j'ai longtemps voulu toucher «l'ordinateur de vision» avec mes mains, j'ai décidé que j'avais une grande chance d'essayer moi-même le problème MNIST préféré de tout le monde.
Il était déjà 17h00 et j'ai commencé à chercher des modèles pré-entraînés pour reconnaître les nombres. Après les avoir vérifiés sur ce captcha, la précision ne m'a pas satisfait - eh bien, il est temps de collecter des images et de former votre réseau de neurones.
Tout d'abord, vous devez collecter un échantillon de formation.
J'ouvre le pilote Web Chrome et j'écris 1000 captchas dans mon dossier.
from selenium import webdriver
i = 1000
driver = webdriver.Chrome('/Users/aleksejkudrasov/Downloads/chromedriver')
while i>0:
driver.get('http://www.vybory.izbirkom.ru/region/izbirkom?action=show&vrn=4274007421995®ion=27&prver=0&pronetvd=0')
time.sleep(0.5)
with open(str(i)+'.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
i = i - 1Comme nous n'avons que deux couleurs, j'ai converti nos captchas en bw:
from operator import itemgetter, attrgetter
from PIL import Image
import glob
list_img = glob.glob('path/*.png')
for img in list_img:
im = Image.open(img)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
#
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
im2.save(img)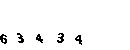
Nous devons maintenant couper nos captchas en nombres et les convertir en une taille unique de 10 * 10.
Tout d'abord, nous coupons le captcha en nombres, puis, comme le captcha est décalé le long de l'axe OY, nous devons recadrer tout ce qui n'est pas nécessaire et faire pivoter l'image de 90 °.
def crop(im2):
inletter = False
foundletter = False
start = 0
end = 0
count = 0
letters = []
name_slise=0
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
# OX
if foundletter == False and inletter == True:
foundletter = True
start = y
# OX
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
for letter in letters:
#
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
# 90°
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
#
for y in range(im3.size[0]): # slice across
for x in range(im3.size[1]): # slice down
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
#
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
#
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
resized_img.save(path+name_slise+'.png')
name_slise+=1
«Il est déjà temps, 18h00, il est temps de terminer ce problème», ai-je pensé, dispersant les numéros en cours de route dans des dossiers avec leurs numéros.
Nous déclarons un modèle simple qui accepte une matrice étendue de notre image comme entrée.
Pour ce faire, créez une couche d'entrée de 100 neurones, car la taille de l'image est de 10 * 10. En tant que couche de sortie, il y a 10 neurones, dont chacun correspond à un chiffre de 0 à 9.
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
def mnist_make_model(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(image_w*image_h, activation='relu', input_shape=(image_h*image_h)))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
return model
Nous divisons nos données en ensembles de formation et de test:
list_folder = ['0','1','2','3','4','5','6','7','8','9']
X_Digit = []
y_digit = []
for folder in list_folder:
for name in glob.glob('path'+folder+'/*.png'):
im2 = Image.open(name)
X_Digit.append(np.array(im2))
y_digit.append(folder)Nous le divisons en ensemble de formation et de test:
from sklearn.model_selection import train_test_split
X_Digit = np.array(X_Digit)
y_digit = np.array(y_digit)
X_train, X_test, y_train, y_test = train_test_split(X_Digit, y_digit, test_size=0.15, random_state=42)
train_data = X_train.reshape(X_train.shape[0], 10*10) # 100
test_data = X_test.reshape(X_test.shape[0], 10*10) # 100
# 10
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
Nous formons le modèle.
Sélectionnez empiriquement les paramètres du nombre d'époques et de la taille du "lot":
model = mnist_make_model(10,10)
model.fit(train_data, train_labels_cat, epochs=20, batch_size=32, verbose=1, validation_data=(test_data, test_labels_cat))
Nous économisons les poids:
model.save_weights("model.h5")
La précision à la 11e époque s'est avérée excellente: précision = 1,0000. Satisfait, je rentre me reposer chez moi à 19h00, demain j'ai encore besoin d'écrire un analyseur pour collecter les informations du site CEC.
Matin le lendemain.
Le sujet est resté petit, il reste à parcourir toutes les pages du site CEC et à récupérer les données:
Chargez les poids du modèle entraîné:
model = mnist_make_model(10,10)
model.load_weights('model.h5')
Nous écrivons une fonction pour enregistrer le captcha:
def get_captcha(driver):
with open('snt.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
im2 = Image.open('path/snt.png')
return im2
Écrivons une fonction pour la prédiction captcha:
def crop_predict(im):
list_cap = []
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
count = 0
letters = []
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
for letter in letters:
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
for y in range(im3.size[0]):
for x in range(im3.size[1]):
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
img_arr = np.array(resized_img)/255
img_arr = img_arr.reshape((1, 10*10))
list_cap.append(model.predict_classes([img_arr])[0])
return ''.join([str(elem) for elem in list_cap])
Ajoutez une fonction qui télécharge la table:
def get_table(driver):
html = driver.page_source #
soup = BeautifulSoup(html, 'html.parser') # " "
table_result = [] #
tbody = soup.find_all('tbody') #
list_tr = tbody[1].find_all('tr') #
ful_name = list_tr[0].text #
for table in list_tr[3].find_all('table'): #
if len(table.find_all('tr'))>5: #
for tr in table.find_all('tr'): #
snt_tr = []#
for td in tr.find_all('td'):
snt_tr.append(td.text.strip())#
table_result.append(snt_tr)#
return (ful_name, pd.DataFrame(table_result, columns = ['index', 'name','count']))
Nous collectons tous les liens pour le 13 septembre:
df_table = []
driver.get('http://www.vybory.izbirkom.ru')
driver.find_element_by_xpath('/html/body/table[2]/tbody/tr[2]/td/center/table/tbody/tr[2]/td/div/table/tbody/tr[3]/td[3]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
list_a = soup.find_all('table')[1].find_all('a')
for a in list_a:
name = a.text
link = a['href']
df_table.append([name,link])
df_table = pd.DataFrame(df_table, columns = ['name','link'])
À 13h00, je finis d'écrire le code pour parcourir toutes les pages:
result_df = []
for index, line in df_table.iterrows():#
driver.get(line['link'])#
time.sleep(0.6)
try:#
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:#
pass
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
if soup.find('select') is None:#
time.sleep(0.6)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
for i in range(len(soup.find_all('tr'))):#
if '\n \n' == soup.find_all('tr')[i].text:# ,
rez_link = soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
time.sleep(0.6)
try:
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)#
head_name = line['name']
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
else:# ,
options = soup.find('select').find_all('option')
for option in options:
if option.text == '---':#
continue
else:
link = option['value']
head_name = option.text
driver.get(link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html2 = driver.page_source
second_soup = BeautifulSoup(html2, 'html.parser')
for i in range(len(second_soup.find_all('tr'))):
if '\n \n' == second_soup.find_all('tr')[i].text:
rez_link = second_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
if second_soup.find('select') is None:
continue
else:
options_2 = second_soup.find('select').find_all('option')
for option_2 in options_2:
if option_2.text == '---':
continue
else:
link_2 = option_2['value']
child_name = option_2.text
driver.get(link_2)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html3 = driver.page_source
thrid_soup = BeautifulSoup(html3, 'html.parser')
for i in range(len(thrid_soup.find_all('tr'))):
if '\n \n' == thrid_soup.find_all('tr')[i].text:
rez_link = thrid_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
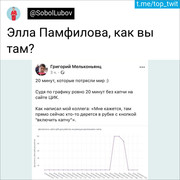
Et puis vient le tweet qui a changé ma vie