Nous continuons une série d'articles sur la modération de contenu sur les sites du Centre de développement des technologies financières de la Banque agricole russe. Dans le dernier article, nous avons parlé de la façon dont nous avons résolu le problème de la modération de texte pour l'un des sites de l'écosystème pour les agriculteurs «Own Farming» . Vous pouvez lire un peu sur le site lui-même et quel résultat nous avons obtenu ici .
Bref, nous avons utilisé un ensemble d'un classifieur naïf (filtre par dictionnaire) et BERT. Les textes qui passaient le filtre du dictionnaire étaient autorisés à entrer dans BERT, où ils étaient également vérifiés.
Et nous, avec le laboratoire MIPT, continuons à améliorer notre site, nous fixant une tâche plus difficile de pré-modération des informations graphiques. Cette tâche s'est avérée plus difficile que la précédente, car lors du traitement d'un langage naturel, on peut se passer de modèles de réseaux de neurones. Avec les images, tout est plus compliqué - la plupart des tâches sont résolues à l'aide de réseaux de neurones et de la sélection de leur architecture correcte. Mais avec cette tâche, comme il nous semble, nous nous sommes bien débrouillés! Et ce que nous en avons tiré, lisez la suite.

Ce que nous voulons?
Alors allons-y! Définissons immédiatement ce que devrait être un outil de modération d'image. Par analogie avec un outil de modération de texte, cela devrait être une sorte de "boîte noire". En soumettant une image téléchargée par les vendeurs de biens sur le site en entrée, nous aimerions comprendre comment cette image est acceptable pour publication sur le site. Ainsi, nous obtenons la tâche: déterminer si l'image est apte à être publiée sur le site ou non.
La tâche de pré-modération des images est courante, mais la solution diffère souvent d'un site à l'autre. Ainsi, les images d'organes internes peuvent être acceptables pour les forums médicaux, mais pas adaptées aux réseaux sociaux. Ou, par exemple, les images de carcasses d'animaux coupées sont acceptables sur un site Web où elles sont vendues, mais il est peu probable qu'elles soient appréciées par les enfants qui vont en ligne pour regarder Smesharikov. Quant à notre site, des images de produits agricoles (légumes / fruits, aliments pour animaux, engrais, etc.) lui seraient acceptables. En revanche, il est évident que le thème de notre marketplace n'implique pas la présence d'images avec divers contenus obscènes ou offensants.
Pour commencer, nous avons décidé de nous familiariser avec les solutions déjà connues au problème et d'essayer de les adapter à notre site. En règle générale, de nombreuses tâches de modération de contenu graphique sont réduites à la résolution de problèmes de la classe NSFW , pour laquelle il existe un ensemble de données accessible au public.
Pour résoudre les tâches NSFW, en règle générale, des classificateurs basés sur ResNet sont utilisés, qui montrent une précision de qualité> 93%.
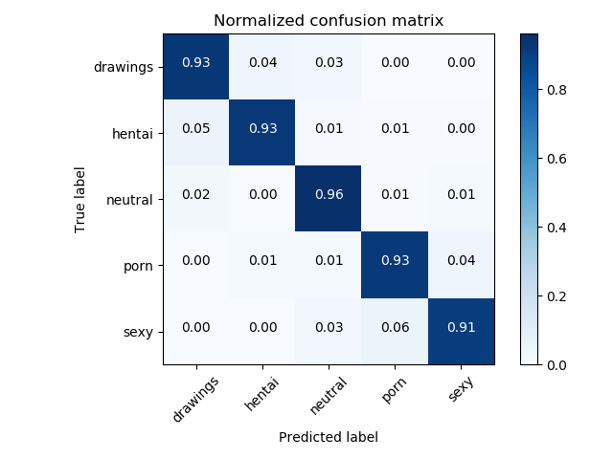
Matrice d'erreur du classificateur NSFW d'origine
Ok, disons que nous avons un bon modèle et un jeu de données prêt à l'emploi pour NSFW, mais cela suffira-t-il à déterminer l'acceptabilité de l'image pour le site? Il s'est avéré que non. Après avoir discuté de cette approche initiale avec le modèle NSFW avec nos propriétaires de sites, nous avons réalisé que nous devions définir un peu plus de catégories, à savoir:
- ( , )
- ( , , , . )
- ( )
Autrement dit, nous devions encore composer notre propre ensemble de données et réfléchir à quels autres modèles pourraient être utiles.
C'est là que nous nous heurtons à un problème commun de machine learning: le manque de données. Cela est dû au fait que notre site a été créé il n'y a pas si longtemps et qu'il n'y a pas d'exemples négatifs, c'est-à-dire marqué comme inacceptable. Pour le résoudre, la méthode d' apprentissage en quelques coups vient à notre aide . L'essence de cette méthode est que nous pouvons recycler, par exemple, ResNet sur de petits ensembles de données que nous avons assemblés, et obtenir une précision plus élevée que si nous fabriquions un classificateur à partir de zéro et en utilisant uniquement notre petit ensemble de données.
Comment avez-vous fait?
Vous trouverez ci-dessous un schéma général de notre solution, à partir de l'image d'entrée et se terminant par le résultat de la détection de diverses catégories, si une image de pomme est envoyée à l'entrée.

Schéma général de la solution
Considérons chaque partie du schéma plus en détail.
Étape 1: Détecteur de graffitis
Nous nous attendons à ce que les marchandises contenant du texte sur les colis soient chargées sur notre site et, en conséquence, la tâche de détecter les inscriptions et d'identifier leur signification se pose.
Lors de la première étape, nous avons utilisé la bibliothèque OpenCV Text Detection pour trouver les étiquettes sur les packages.
OpenCV Text Detection est un outil de reconnaissance optique de caractères (OCR) pour Python. Autrement dit, il reconnaît et «lit» le texte incorporé dans les images.

Exemple de fonctionnement du détecteur EAST
Vous pouvez voir un exemple de détection d'inscriptions sur la photo. Pour identifier la boîte englobante, nous avons utilisé le modèle EAST, mais ici, le lecteur peut ressentir une prise, car ce modèle est entraîné à reconnaître des textes anglais et sur nos images, les textes sont en russe. C'est pourquoi, en outre, nous utilisons un modèle de classification binaire (graffiti / non graffiti) basé sur ResNet, qui a été formé à la qualité requise sur nos données. Nous avons choisi ResNet-18, car ce modèle s'est avéré être le meilleur lors du choix d'une architecture.
Dans notre tâche, nous aimerions distinguer les photos où les inscriptions sont des inscriptions sur les emballages de marchandises issues de graffitis. Par conséquent, nous avons décidé de diviser toutes les photos avec texte en deux classes: graffitis et non graffitis
.
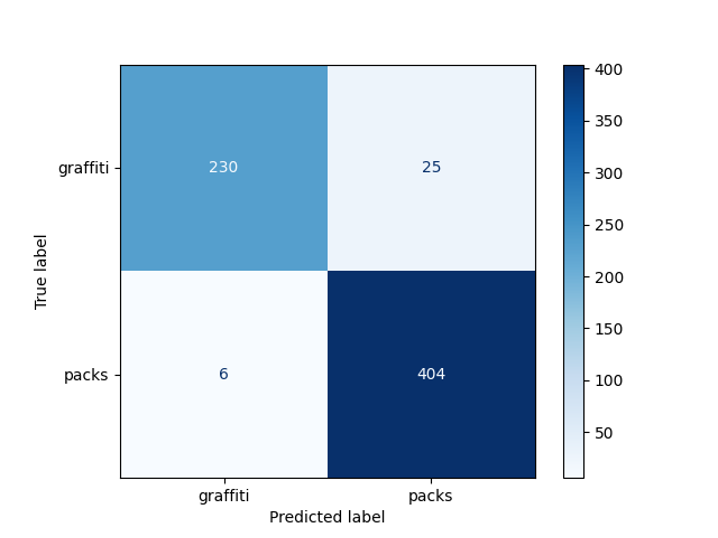
Matrice de bogues du détecteur de graffitis
Pas mal! Nous sommes maintenant en mesure d'isoler le texte de la photo et avec une bonne probabilité de comprendre s'il convient à la publication. Mais que faire s'il n'y a pas de texte sur la photo?
Étape 2: détecteur NSFW
Si nous ne trouvons pas de texte dans l'image, cela ne signifie pas qu'il est inacceptable, par conséquent, nous voulons en outre évaluer comment le contenu de l'image correspond au thème du site.
À ce stade, la tâche consiste à affecter l'image à l'une des catégories:
- médicaments
- porno (porno)
- animaux
- photos pouvant entraîner un rejet (y compris les dessins) (gore / drawing_gore)
- hentai (hentai)
- images neutres (neutres)
Il est important que le modèle renvoie non seulement la catégorie, mais également le degré de confiance des algorithmes qu'elle contient.
Un modèle basé sur NSFW a été utilisé pour la classification. Elle est formée de telle manière qu'elle divise la photo en 7 classes et une seule d'entre elles que nous nous attendons à voir sur le site. Par conséquent, nous ne laissons que des photos neutres.
Le résultat d'un tel modèle est 97% (en termes de précision)

matrice d'erreur du détecteur NSFW
Étape 3: Détecteur de personne
Mais même après avoir appris à filtrer NSFW, le problème ne peut toujours pas être considéré comme résolu. Par exemple, une photo d'une personne n'entre ni dans la catégorie NSFW ni dans la catégorie photo avec texte, mais nous n'aimerions pas non plus voir de telles images sur le site. Puis nous avons ajouté à notre architecture un modèle de détection humaine - Single Shot Detector (ci-après dénommé SSD).
La sélection de personnes ou d'un autre objet précédemment connu est également une tâche populaire avec un large éventail d'applications. Nous avons utilisé le modèle nvidia_ssd prêt à l'emploi de pytorch.

Un exemple de l'algorithme SSD
Les résultats du modèle sont inférieurs (précision - 96%):

Matrice d'erreur du détecteur humain
résultats
Nous avons évalué la qualité de notre instrument à l'aide de métriques pondérées F1, Précision, Rappel. Les résultats sont présentés dans le tableau:
| Métrique | Précision obtenue |
| F1 pondéré | 0,96 |
| Précision pondérée | 0,96 |
| Rappel pondéré | 0,96 |
Et voici quelques exemples plus illustratifs de son travail:
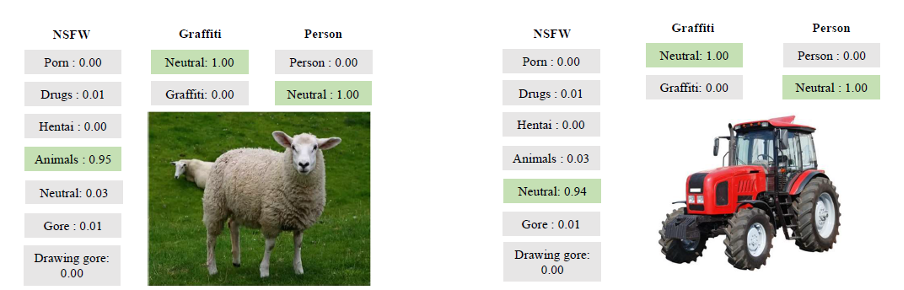
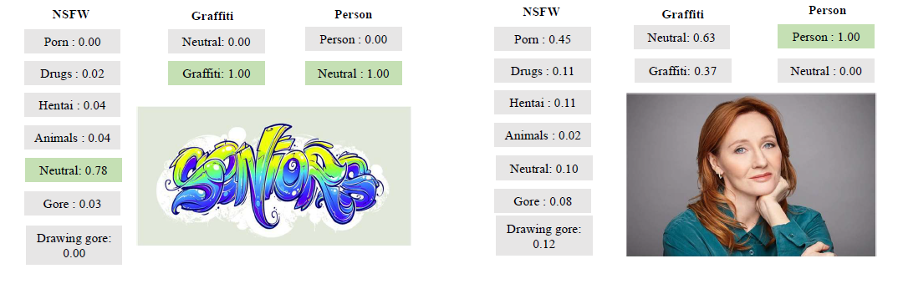
Exemples de l'outil
Conclusion
Dans le processus de résolution, nous avons utilisé tout un «zoo» de modèles qui sont souvent utilisés pour les tâches de vision par ordinateur. Nous avons appris à «lire» le texte d'une photo, à trouver des personnes et à distinguer les contenus inappropriés.
Enfin, je voudrais noter que le problème considéré est utile du point de vue de l'acquisition d'expérience et de l'utilisation de modèles classiques modifiés. Voici quelques-unes des idées que nous avons obtenues:
- Vous pouvez contourner le problème de pénurie de données en utilisant la méthode d'apprentissage en quelques étapes: les grands modèles peuvent être entraînés avec la précision requise sur leurs propres données
- : ,
- , ,
- , , . , , ,
- Malgré le fait que la tâche de modération d'image est assez populaire, sa solution, comme dans le cas des textes, peut différer d'un site à l'autre, car chacun d'eux est conçu pour un public différent. Dans notre cas, par exemple, en plus du contenu inapproprié, nous avons également détecté des animaux et des personnes
Merci de votre attention et à bientôt dans le prochain article!