Tâche
Donné: un projet basé sur OpenWRT (et il est basé sur BuildRoot) avec un référentiel supplémentaire connecté en tant que flux. Objectif: fusionner un référentiel supplémentaire avec le référentiel principal.
Contexte
Nous fabriquons des routeurs et, un jour, nous voulions donner aux clients la possibilité d'inclure leurs applications dans le firmware. Afin de ne pas souffrir de l'allocation du SDK, de la chaîne d'outils et des difficultés qui en découlent, nous avons décidé de mettre l'ensemble du projet sur github dans un référentiel privé. Structure du référentiel:
/target //
/toolchain // gcc, musl
/feeds //
/package //
...
Il a été décidé de transférer certaines des applications de notre propre développement du référentiel principal vers le référentiel supplémentaire, afin que personne n'ait espionné. Nous avons tout fait, l'avons mis sur github et c'est devenu bon.
Beaucoup d'eau a coulé sous le pont depuis ce temps ...
Le client est parti depuis longtemps, le référentiel a été supprimé de github et l'idée même de donner aux clients l'accès au référentiel est pourrie. Cependant, deux référentiels sont restés dans le projet. Et tous les scripts / applications, d'une manière ou d'une autre liés à git, sont contraints de devenir compliqués à travailler avec une telle structure. En termes simples, c'est une dette technique. Par exemple, pour garantir la reproductibilité des versions, vous devez valider dans le référentiel principal un fichier, secondary.version, avec un hachage du deuxième référentiel. Bien sûr, le script le fait, et ce n'est pas très difficile pour cela. Mais il existe une douzaine de ces scripts, et ils sont tous plus compliqués qu'ils ne pourraient l'être. En général, j'ai pris la décision volontaire de fusionner le référentiel secondaire dans le référentiel principal. Dans le même temps, la condition principale était posée: préserver la reproductibilité des versions.
Une fois qu'une telle condition est définie, les méthodes de fusion triviales, telles que la validation de tout depuis le secondaire séparément, puis, par le haut, la validation de fusion de deux arbres indépendants, ne fonctionneront pas. Vous devez ouvrir le capot et vous salir les mains.
Structure de données Git
Tout d'abord, à quoi ressemble un dépôt git? Ceci est une base de données d'objets. Les objets sont de trois types: blobs, arborescences et validations. Tous les objets sont adressés par le hachage sha1 de leur contenu. Un blob est, bêtement, des données sans aucun attribut supplémentaire. Un arbre est une liste triée de liens vers des arbres et des objets blob de la forme «<right> <type> <hash> <name>» (où <type> est soit un blob soit un arbre). Ainsi, une arborescence est comme un répertoire dans le système de fichiers, et un objet blob est comme un fichier. Un commit contient le nom de l'auteur et du committer, la date de création et d'ajout, un commentaire, un hachage de l'arborescence et un nombre arbitraire (généralement un ou deux) de liens vers les commits parents. Ces liens vers les commits parents transforment la base d'objets en un digraphe acyclique (parmi les étrangers, appelé DAG).Lire en détailici :
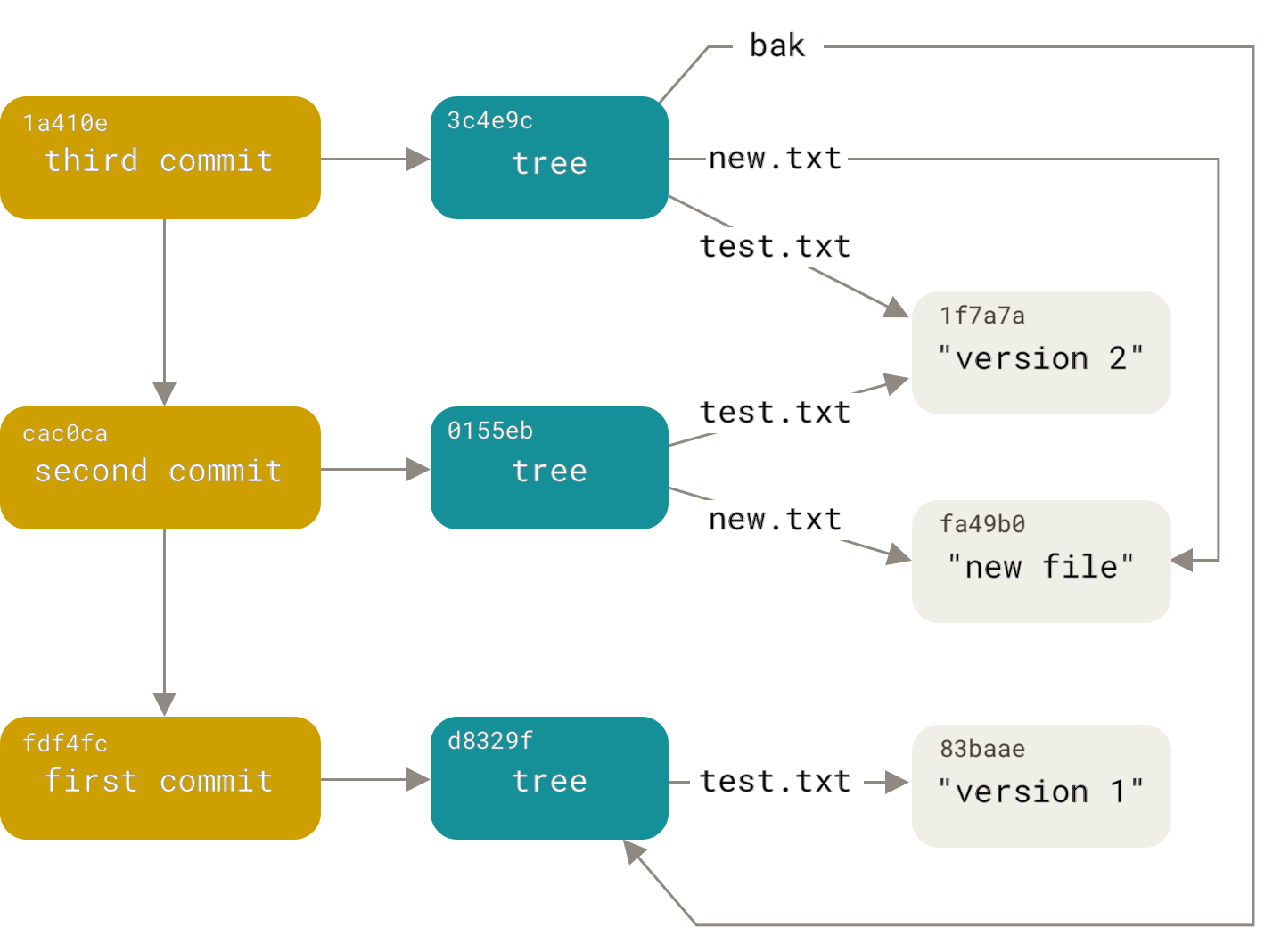
Ainsi, notre tâche s'est transformée en tâche de construction d'un nouveau digraphe, répétant la structure de l'ancien. Mais avec le remplacement des commits du fichier secondaire.version par des commits du référentiel supplémentaire, le

processus de développement est loin d'être le classique gitflow. Nous confions tout au maître, en essayant de ne pas le casser en même temps. Nous faisons des builds à partir de là. Si nécessaire, nous créons des branches de stabilisation, que nous fusionnons ensuite dans le maître. En conséquence, le graphe du référentiel ressemble à un tronc nu d'un séquoia tressé de vignes.
Une analyse
La tâche se décompose naturellement en deux étapes: l'analyse et la synthèse. Puisque pour la synthèse, il est nécessaire, évidemment, de courir à partir du moment même de l'allocation du dépôt secondaire à toutes les balises et branches, en insérant des commits du deuxième dépôt, puis au stade de l'analyse, il est nécessaire de trouver des endroits où insérer des commits secondaires et ceux-ci se commits eux-mêmes. Donc, vous devez construire un graphe réduit, où les nœuds seront les commits du graphe principal qui changent le fichier secondaire.version (commits clés). De plus, si les nœuds de ce git font référence aux parents, alors dans le nouveau graphe, des références aux descendants sont nécessaires. Je crée un tuple nommé:
node = namedtuple(‘Node’, [‘primary_commit’, ‘secondary_commit’, ‘children’])
réservation nécessaire
, . , .
Je l'ai mis dans le dictionnaire:
master_tip = repo.commit(‘master’)
commit_map = {master_tip : node(master_tip, get_sec_commit(master_tip), [])}J'y mets tous les commits qui changent la version secondaire:
for c in repo.iter_commits(all=True, path=’secondary.verion’) :
commit_map[c] = node(c, get_sec_commit(c), [])Et je construis un algorithme récursif simple:
def build_dag(commit, commit_map, node):
for p in commit.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
build_dag(p, commit_map, commit_map[p])
else :
build_dag(p, commit_map, node)Autrement dit, j'étire les nœuds clés dans le passé et les attache à de nouveaux parents.
Je l'exécute et ... RuntimeError profondeur de récursivité maximale dépassée
Comment cela s'est-il passé? Y a-t-il trop de commits? git log et wc connaissent la réponse. Le total des commits depuis le fractionnement est d'environ 20 000, et ceux affectant la version secondaire - près de 700. La recette est connue, une version non récursive est nécessaire.
def build_dag(master_tip, commit_map, master_node):
to_process = [(master_tip, master_node)]
while len(to_process) > 0:
c, node = to_process.pop()
for p in c.parents :
if p in commit_map :
if node not in commit_map[p].children :
commit_map[p].children.append(node)
to_process.append(p, commit_map[p])
else :
to_process.append(p, node)(Et vous avez dit que tous ces algorithmes ne sont nécessaires que pour que l'interview passe!) Je le
lance, et ... ça marche. Une minute, cinq, vingt ... Non, vous ne pouvez pas prendre si longtemps. J'arrête. Apparemment, chaque commit et chaque chemin sont traités plusieurs fois. Combien de branches y a-t-il dans l'arbre? Il s'est avéré qu'il y avait 40 branches dans l'arbre et, en conséquence,chemins différents uniquement à partir du maître. Et il existe de nombreux chemins menant à une part importante des commits clés. Comme je n'ai pas des milliers d'années en réserve, je dois changer l'algorithme pour que chaque commit soit traité exactement une fois. Pour ce faire, j'ajoute un ensemble, où je marque chaque commit traité. Mais il y a un petit problème: avec cette approche, certains liens seront perdus, car différents chemins avec des validations de clé différentes peuvent passer par les mêmes commits, et seul le premier ira plus loin. Pour contourner ce problème, je remplace l'ensemble par un dictionnaire, où les clés sont des validations, et les valeurs sont des listes de validations de clés accessibles:
def build_dag(master_tip, commit_map, master_node):
processed_commits = {}
to_process = [(master_tip, master_node, [])]
while len(to_process) > 0:
c, node, path = to_process.pop()
p_node = commit_map.get(c)
if p_node :
commit_map[p].children.append(p_node)
for path_c in path :
if all(p_node.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(p_node)
path = []
node = p_node
processed_cmmts[c] = []
for p in c.parents :
if p != root_commit and and p not in processed_cmmts :
newpath = path.copy()
newpath.append(c)
to_process.append((p, node, newpath,))
else :
p_node = commit_map.get(p)
if p_node is None :
p_nodes = processed_cmmts.get(p, [])
else :
p_nodes = [p_node]
for pn in p_nodes :
node.children.append(pn)
if all(pn.trunk_commit != nc.trunk_commit for nc
in processed_cmmts[c]) :
processed_cmmts[c].append(pn)
for path_c in path :
if all(pn.trunk_commit != nc.trunk_commit
for nc in processed_cmmts[path_c]) :
processed_cmmts[path_c].append(pn)À la suite de cet échange ingénieux de mémoire pendant un certain temps, le graphique est construit en 30 secondes.
Synthèse
Maintenant, j'ai un commit_map avec des nœuds clés liés à un graphique via des liens enfants. Pour plus de commodité, je vais le transformer en une séquence de paires (ancêtre, descendant) . La séquence doit être garantie que toutes les paires où un nœud apparaît en tant qu'enfant sont situées avant toute paire où un nœud apparaît en tant qu'ancêtre. Ensuite, il vous suffit de parcourir cette liste et de valider d'abord les commits depuis le référentiel principal, puis depuis le dépôt supplémentaire. Ici, vous devez vous rappeler que le commit contient un lien vers l'arborescence, qui est l'état du système de fichiers. Étant donné que le référentiel supplémentaire contient des sous-répertoires supplémentaires dans le répertoire package /, il sera alors nécessaire de créer de nouvelles arborescences pour tous les commits. Dans la première version, je viens d'écrire des objets blob dans des fichiers et j'ai demandé au git de créer un index sur le répertoire de travail. Cependant, cette méthode n'était pas très productive. Il y a encore 20 000 engagements, et chacun doit être à nouveau engagé. La performance compte donc beaucoup. Un peu de recherche sur les éléments internes de GitPython m'a conduit à la classe gitdb.LooseObjectDB , qui expose directement les objets du référentiel git. Avec lui, les blobs et les arbres (ainsi que tous les autres objets) d'un référentiel peuvent être écrits directement dans un autre. Une propriété merveilleuse de la base de données d'objets git est que l'adresse de tout objet est un hachage de ses données. Par conséquent, le même objet blob aura la même adresse, même dans des référentiels différents.
secondary_paths = set()
ldb = gitdb.LooseObjectDB(os.path.join(repo.git_dir, 'objects'))
while len(pc_pairs) > 0:
parent, child = pc_pairs.pop()
for c in all_but_last(repo.iter_commits('{}..{}'.format(
parent.trunk_commit, child.trunk_commit), reverse = True)) :
newparents = [new_commits.get(p, p) for p in c.parents]
new_commits[c] = commit_primary(repo, newparents, c, secondary_paths)
newparents = [new_commits.get(p, p) for p in child.trunk_commit.parents]
c = secrepo.commit(child.src_commit)
sc_message = 'secondary commits {}..{} <devonly>'.format(
parent.src_commit, child.src_commit)
scm_details = '\n'.join(
'{}: {}'.format(i.hexsha[:8], textwrap.shorten(i.message, width = 70))
for i in secrepo.iter_commits(
'{}..{}'.format(parent.src_commit, child.src_commit), reverse = True))
sc_message = '\n\n'.join((sc_message, scm_details))
new_commits[child.trunk_commit] = commit_secondary(
repo, newparents, c, secondary_paths, ldb, sc_message)Le commit fonctionne lui-même:
def commit_primary(repo, parents, c, secondary_paths) :
head_tree = parents[0].tree
repo.index.reset(parents[0])
repo.git.read_tree(c.tree)
for p in secondary_paths :
# primary commits don't change secondary paths, so we'll just read secondary
# paths into index
tree = head_tree.join(p)
repo.git.read_tree('--prefix', p, tree)
return repo.index.commit(c.message, author=c.author, committer=c.committer
, parent_commits = parents
, author_date=git_author_date(c)
, commit_date=git_commit_date(c))
def commit_secondary(repo, parents, sec_commit, sec_paths, ldb, message):
repo.index.reset(parents[0])
if len(sec_paths) > 0 :
repo.index.remove(sec_paths, r=True, force = True, ignore_unmatch = True)
for o in sec_commit.tree.traverse() :
if not ldb.has_object(o.binsha) :
ldb.store(gitdb.IStream(o.type, o.size, o.data_stream))
if o.path.find(os.sep) < 0 and o.type == 'tree': # a package root
repo.git.read_tree('--prefix', path, tree)
sec_paths.add(p)
return repo.index.commit(message, author=sec_commit.author
, committer=sec_commit.committer
, parent_commits=parents
, author_date=git_author_date(sec_commit)
, commit_date=git_commit_date(sec_commit))
Comme vous pouvez le voir, les validations du référentiel secondaire sont ajoutées en masse. Au début, je me suis assuré que des commits individuels étaient ajoutés, mais (soudainement!) Il s'est avéré que parfois un commit de clé plus récent contient une version précédente du référentiel secondaire (en d'autres termes, la version est annulée). Dans une telle situation, la méthode iter_commit passe et retourne une liste vide. En conséquence, le référentiel est incorrect. Par conséquent, je devais simplement valider la version actuelle.
L'historique de l'apparition du générateur all_but_last est intéressant. J'ai omis la description, mais elle fait exactement ce que vous attendez. Au début, il y avait juste un défi
repo.iter_commits('{}..{}^'.format(parent.trunk_commit, child.trunk_commit), reverse = True)En général, tout s'est bien terminé. Le script entier tient en 300 lignes et a duré environ 6 heures. Morale: GitPython est pratique pour faire toutes sortes de choses intéressantes avec les référentiels, mais il est préférable de traiter la dette technique en temps opportun