
Un chemin épineux et difficile d'une personne qui est entrée en collision avec le FSIS USRN Rosreestr. Il attend une attente interminable du chargement du navigateur, des clés, des captchas, des intervalles entre les requêtes de 5 minutes. Pourquoi souffre-t-il autant? Il avait déjà contribué son argent durement gagné lorsqu'il a décidé de travailler avec ce système et de commander ses extraits. Mais non - obtenir un extrait de l'USRN, c'est comme déshabiller des oignons. La dernière étape qui attend la victime - l'extrait téléchargé et convoité est représenté par une archive zip, dans laquelle, euh, une autre archive et un fichier sig. Et le fichier de déclaration lui-même est déjà à l'intérieur. Mais ce n'est pas facile non plus de le lire - il est en xml. Et pour que tout se développe ensemble, il s'avère nécessaire de télécharger ce xml avec sig sur une page spéciale de Rosreestr. Et là, il y a encore un captcha en attente. Et donc avec chaque déclaration! Nous surmonterons cette dernière douleur aujourd'hui en utilisant python.
Tâche:
- décompressez tous les zip du dossier,
- télécharger selon les spécifications. lien vers Rosreestr,
- enfin télécharger!, une vue lisible par l'homme de la déclaration.
Donc, initialement dans le dossier, il y a des archives zip téléchargées d'extraits:
Après l'importation de modules python:
import os
import zipfile
import webbrowser,time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
Décompressons toutes les archives zip et supprimons-les afin qu'elles ne soient pas confondues avec le contenu:
zipFiles = []
sigFiles = []
for filename in os.listdir('.'):
if filename.endswith('.zip'):
zipfile.ZipFile(filename, 'r').extractall()
os.remove(filename)
Nous avons obtenu des archives zip et des fichiers sig pour eux, qui seront ensuite téléchargés sur le site Web de Rosreestr:
Accédez à la boucle principale du programme pour tous les fichiers du répertoire (dans mon cas, "C: / 2"):
for filename in zipFiles:
act = browser.find_element_by_id('sig_file')
act.send_keys('C:\\2\\'+str(filename)+'.sig')
act = browser.find_element_by_id('xml_file')
# zip
zip_ref = zipfile.ZipFile(filename, 'r').extractall()
# xml
for f in os.listdir('.'):
if f.endswith('.xml'):
print(f)
# xml
act.send_keys('C:\\2\\'+str(f))
act = browser.find_element_by_css_selector('input.brdg1111')
act.click()
i = str(input(" : "))
for b in i:
act.send_keys(b)
time.sleep (0.1)
#act.submit()
act = browser.find_element_by_css_selector('.terminal-button-bright')
act.click()
time.sleep (5)
try:
act = browser.find_element_by_link_text(' ')
act.click()
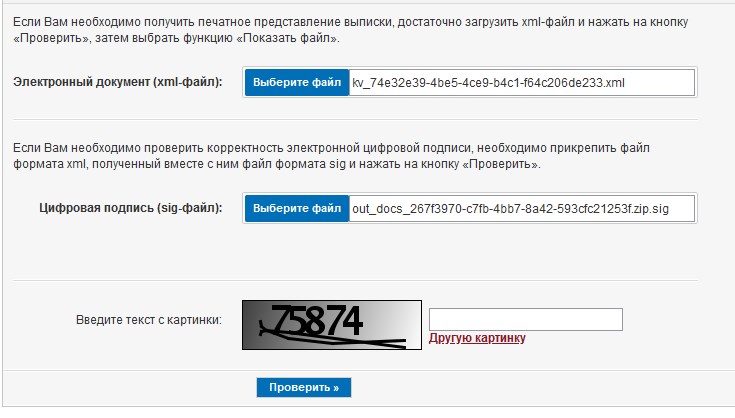
Après le chargement réussi de la page du portail Rosreestr rosreestr.gov.ru/wps/portal/cc_vizualisation , le programme trouvera l'archive zip dans le répertoire, récupérera le fichier de déclaration xml à partir de là et l'insérera dans le champ requis sur le site. Le programme fera de même avec le fichier sig attaché au xml:
Ensuite, le programme attendra que le captcha soit entré:
Après que l'utilisateur entre le captcha, il l'enverra au site et cliquera sur le lien de téléchargement pour l'extrait "normal" de l'USRN:
Une fenêtre s'ouvrira dans laquelle le extrait, qui peut être enregistré en html ou en appuyant sur CTRL + P dans Chrome - en pdf.
Il reste à ajouter un captcha à résolution automatique et le téléchargement automatique d'extraits lisibles par l'homme. Mais c'est la chose la plus simple ici, n'est-ce pas?
Le code du programme est ici .