Il y a une légende de l'Ancien Testament sur la façon dont les gens de l'ancienne ville de Babylone ont commencé à construire une tour, mais le Tout-Puissant a mélangé leurs langues et la tour n'a pas été achevée. Pourtant, parce que la tour a été construite par des centaines de petits groupes, qui ensemble ne se comprenaient pas. Et sans se comprendre, il est impossible d'interagir. En effet, c'est simplement de la folie d'appeler une seule et même chose, l'impliquant comme la même, dans des mots différents. Et il n'y a rien de surprenant ici.
La légende de l'Ancien Testament peut être facilement transférée aux grandes entreprises modernes mettant en œuvre des solutions informatiques modernes. Un exemple de telles entreprises peut sans aucun doute être attribué aux banques russes modernes, qui ont des dizaines, voire des centaines d'unités commerciales, qui ont leur propre sous-culture de la communication, construite sur leurs propres règles et un style unique de chiffre d'affaires. Naturellement, lors de la formation de l'infrastructure informatique, le style de dénomination des entités commerciales qui a été établi dans l'équipe est pris en compte. Au cours des dix dernières années, de nombreux travaux sur ce thème sont apparus, par exemple celui-ci [1]. Ceux qui sont tombés sur l’analyse des systèmes d’information dans les banques savent ce que signifie faire la soi-disant «cartographie» des données, surtout si les systèmes finaux ont été réalisés par différentes équipes d’analystes, de développeurs et de clients ou fournisseurs. Habituellement,60% de compilation de mappage est une compréhension de l'essence et de la sémantique des données transmises.
La tendance actuelle est d'utiliser un ensemble de méthodologies agiles. Tout le monde parle d' Agile . Vous pouvez argumenter jusqu'à enrouer si c'est bon pour les affaires ou pour le mal. Mais une chose ne fera rejeter personne. Dans le cadre d' Agile, de nombreuses équipes différentes, à la fois au sein de la banque et auprès de différents fournisseurs, créent une variété de solutions informatiques pour les entreprises et, souvent, sans interagir les unes avec les autres, les équipes créent leur propre terminologie bien établie. Et au moment où l'intégration se produit, la même situation décrite dans l'Ancien Testament se produit. Comment ne ressemble-t-il pas au bazar babylonien avec ses milliers de marchands, de magasins, de marchandises, de saints imbéciles, de fakirs et de cracheurs de feu? Et ainsi, tous ces gens, armés d'idées et de pensées différentes, commencent à construire la Tour.
XSD ( JSON ) , - . , , «» , Confluence, Zoom Webex, « » , — .
, ESB ( ) -, , , «-» , . … , , . , , - , Kafka. , , , . XML , XSD , , , , JSON, - , «» «». , , , JSON . . , . XSD , . JSON . .
? , - . , ?
.
- . , . MS Excel, , , «» . ( JSON path), — . «». . , :
« »
« »
«20- »
«12- »
« , »
, , , , -. , : , . – “ ”. , , , , , , .
, , , PIP! xslx , . , , Python, .
, – Python. , Python. , , - . , , . – , , . : « , ». — - PyQt Tkinter. , . .
, JSONpath , . , , , Python. , .
. JSON.
. “” 33- . 33 ? – “33” . «». . , , , [2]. . «» . : , , 33- . . . , ABC :
où chaque coordonnée x à la position correspondante est le numéro de la lettre correspondante du commentaire de champ dans le fichier Excel. Par exemple, nous avons le commentaire «Numéro de compte individuel». Comparons pour cela un vecteur émergeant de l'origine des coordonnées du système cartésien dans un espace alphabétique de 33 dimensions, il ressemblera à ceci: coordonnée X A - correspond au nombre de lettres "a". Et c'est égal à deux. X B - dans ce cas, il sera égal à zéro, car il n'y a pas de lettre «b» dans cette déclaration. La même chose s'applique à x B - la lettre " B " est manquante. Mais x Et - sera égal à 3, puisque la lettre «et» dans le commentaire apparaît trois fois.

Graphique 1 . , « » . «»= 2, «» =3. – xA=2, x=3.
, , ( ) , 33- « », :
, , « «»» ( , , «» «») « ». :
Nous allons maintenant trouver la différence entre les vecteurs dans le système de coordonnées cartésien de l'espace alphabétique, on la retrouve, respectivement, selon la formule bien connue de la géométrie analytique:
Où et les coordonnées vectorielles correspondantes pour l'axe correspondant à la lettre.
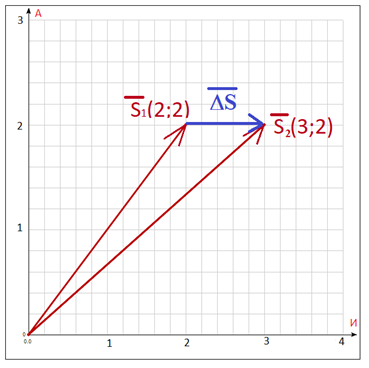
Figure 2. La couleur bleue montre la différence entre les vecteurssur le plan des lettres - de l'espace alphabétique.
Ainsi, le vecteur correspondant à la différence entre les relevés "Numéro de compte d'un individu" et "Numéro de compte d'un physicien" ressemblera à ceci:
, le
vecteur correspondant à la différence entre les relevés "Numéro de compte d'un particulier" et "Numéro de compte client" ressemblera à ceci:
En outre, la longueur des vecteurs de différence calculés obtenus par la formule:
Si vous effectuez un calcul arithmétique, vous obtenez:
Cela suppose mathématiquement que l'expression «numéro de compte d'une personne» a une signification plus proche de «numéro de compte d'un physicien» que de «numéro de compte d'une personne morale». Ceci est indiqué par les longueurs des vecteurs de différence. Plus la longueur est courte, plus les déclarations sont proches les unes des autres. Si, par exemple, nous prenons et comparons les relevés «Numéro de compte d'un particulier» et «numéro de l'agence dans laquelle un compte d'un particulier est ouvert», nous obtenons le chiffre 6.63. Ce qui indiquera que si les deux premiers énoncés sont proches dans leur sens de l'original (la différence des vecteurs 3,32 et 4,00, respectivement), alors le troisième, évidemment, aura même une essence commerciale différente, malgré l'ensemble de mots apparemment identique ...
Vous pouvez aller plus loin et tenter, à travers la vectorisation, de quantifier la proximité des commentaires dans le sens. Pour ce faire, je suggère d'utiliser des projections vectorielles les unes sur les autres. Trouvez ensuite le rapport entre la projection longue du vent comparé et la longueur de celui avec lequel il est comparé. Ce rapport sera toujours inférieur ou égal à un. Et en conséquence, si les déclarations sont identiques les unes aux autres, la projection fusionnera avec le vecteur sur lequel la projection est faite. Plus l'énoncé comparé est loin dans le sens, moins la projection sera. Si vous le multipliez par 100%, vous pouvez obtenir le degré de correspondance des instructions vectorisées en pourcentage. Ainsi, la projection du vecteur déclaration comparée sur le vecteur de la déclaration originale sera trouvée par la formule suivante:
Ainsi, le degré de conformité sera calculé à l'aide de la formule suivante:

Figure 3. Illustration d'une projection vecteur par vecteur ...
C'est ce paramètre qu'il est proposé de prendre comme base pour déterminer la correspondance sémantique.
Implémentation de l'algorithme en Python . Un peu d'abricot. Comment définir et gérer les vecteurs
J'ai nommé l' algorithme Jerdella . Rien d'étrange, je viens de Rostov-sur-le-Don.
. , --, , , . , , -, -, -, “”. , .
, , Python , . , . , NumPy. , , NumPy? , – , , - « », . , NumPy. — . , , PIP... Par conséquent, notre Jerdella utilisera les packages standard inclus dans PyCharm Community Edition pour l'interpréteur Python 3 .
Donc, la bonne chose à propos de Python est qu'il a la capacité d'implémenter une grande variété de structures de données. Et pourquoi ne sommes-nous pas satisfaits d'une liste pour enregistrer un vecteur? Une liste d'éléments de type int est ce dont vous avez besoin pour définir un vecteur dans l'espace alphabétique et d'autres opérations avec lui.
Nous avons rédigé un certain nombre de procédures fondamentales, que je décrirai brièvement ci-dessous.
Comment définir un vecteur?
J'ai défini le vecteur avec la procédure vectorielle suivante:
def vector(self,a):
vector=[]
abc = ["", '', "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",
"", "", "", "", "", "", "", "", "", "", "", "", ""]
for char in abc:
count=a.count(char)
vector.append(count)
return(vector)Autrement dit, dans la boucle for sur les éléments de la liste abc précédemment préparée , j'ai utilisé l'opération standard pour trouver des pièces jointes à la chaîne de comptage . Après cela, en utilisant la méthode d' ajout, j'ai rempli une nouvelle liste de vecteurs , qui sera le vecteur pour d'autres calculs.
Comment calculer la différence de vecteurs?
Pour ce faire, j'ai créé une procédure delta qui prend deux listes en entrée - a et b .
def delta(self, a, b):
delta = []
for char1, char2 in zip(a, b):
d = char1 - char2
delta.append(d)
return (delta)Dans la boucle for , en itérant sur les deux listes, la différence a été comptée, ajoutée à chaque étape d'itération à la fin de la liste delta , que la procédure a finalement renvoyée sous forme de vecteur.
Comment calculer la longueur d'un vecteur et ainsi estimer la différence?
Pour ce faire, j'ai créé une procédure len_delta , qui prend une liste en entrée, et en itérant sur chaque élément de cette liste (c'est aussi une coordonnée dans l'espace alphabétique), selon la règle de recherche du module vectoriel, calcule la longueur du vecteur.
def len_delta(self, a):
len = 0
for d in a:
len += d * d
return round(math.sqrt(len), 2)Comment calculer le rapport de la projection sur un vecteur et ainsi estimer le pourcentage de coïncidence?
Pour cela, une procédure simplifiée a été créée qui prend deux listes en entrée. Dans ce document, j'ai mis en œuvre la formule (6). Et ici, un point important est de déterminer quel vecteur a la plus grande longueur. Pour une plus grande clarté de l'évaluation des coïncidences, il est plus pratique de projeter un plus petit vecteur sur un plus grand.
def simplify(self, a, b):
len1 = 0
len2 = 0
scalar = 0
for x in a: len1 += x * x
for y in b: len2 += y * y
for x, y in zip(a, b): scalar += x * y
if len1 > len2:
return (scalar / len1) * 100
else:
return (scalar / len2) * 100Discussion des résultats obtenus. Conquérir l'espace sémantique en le structurant
, , Jerdella . : 1) , , . 2) -. , CRM Siebel ESB, -. , , , -. , , . … . , , , …
… 2 , Agile, , point-to-point, , .
. , , . 2-3 , , . , , , : « » « », « », « », « », , . , 3000 , 500 ? – ? . , - 3000 ?
. «» , . . Python . «». “” , . « ». , , , – .
, :
{'Numéro de compte d'un individu': [{4.69: 'Compte bancaire du client'}, {6.0: 'Nom de famille'}, {4.8: 'Numéro de compte métal'}, {4.8: 'Numéro de client'}]}.
Ce diagramme peut également être visualisé sous forme de graphique. Vous pouvez faire beaucoup avec les dictionnaires en Python ... Pour la visualisation et la démonstration des résultats, nous avons utilisé le projet Internet ouvert www.graphonline.ru . Cette plateforme vous permet de construire rapidement un graphique écrit en utilisant GraphML .

Figure 4. Graphique de la relation de l'entité "Nombre d'un individu". Une illustration de la présence «d'orbites de correspondance sémantique» dans une entité.
«» , (3) , , «» , . « » « ». , . , , , . .
? , « » «-». ( ( 3) (5)), . , « » . , « ».
, , , . . .

5. , .
, . … , , . , – ? ? ? — . 80%, , . , . , … - – . , .
, , , , . , , «» ( 6), . «», «», «», - -. , 30% . . , . , , , .

6. «» . , .
. .
«-» . , , - . ? , -.
. - . , . : « - ». , , . « » . , , , . – « ! - »…
, , - , , « », « » « », « », « ». , « ». , . ? ? « »?
, , , , , . – .
, :
[1] . . : . . 2010.
[2]. , . , . . Python. . – . , 2019, — 368 .
P.S. Accenture — ,