- XML - utilisé dans les requêtes SOAP (toujours) et REST (moins souvent) ;
- JSON - utilisé dans les requêtes REST.
Aujourd'hui, je vais vous présenter XML.
XML , traduit de l'anglais e X tensible M arkup L anguage est un langage de balisage extensible. Utilisé pour stocker et transmettre des données. Vous pouvez donc le voir non seulement dans l'API, mais également dans le code.
Ce format est recommandé par le World Wide Web Consortium (W3C), il est donc souvent utilisé pour transférer des données via l'API. Dans l'API SOAP, c'est généralement le seul format possible pour les données d'entrée et de sortie!
Voir aussi:
Qu'est-ce qu'une API - une introduction générale à l'API
Introduction à SOAP et REST: ce que c'est et avec quoi manger - une vidéo sur la différence entre SOAP et REST.
Voyons donc à quoi il ressemble, comment le lire et comment le casser! Oui, oui, mais où sans cela? Après tout, nous devons savoir comment le système réagira au format de courbe des données envoyées.

Contenu
Comment fonctionne XML
Prenons un exemple de la documentation des indices de nom complet de Dadata :
<req>
<query> </query>
<count>7</count>
</req>Et voyons ce que signifie cette entrée.

Mots clés
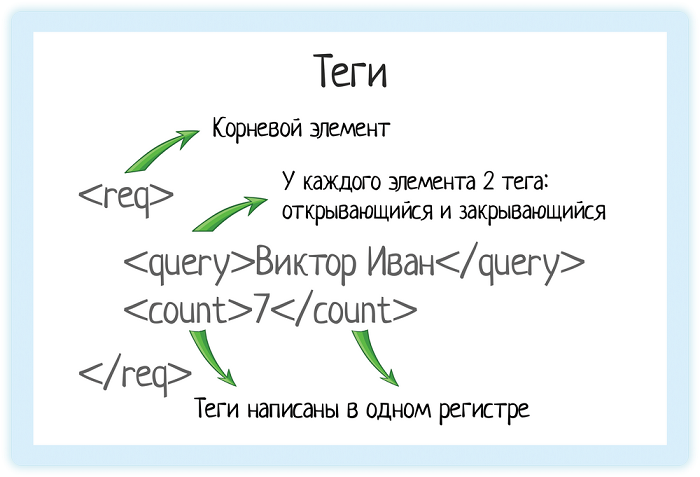
En XML, chaque élément doit être entouré de balises. Une balise est un texte entre crochets:
<tag>Le texte entre les crochets angulaires est le nom de la balise.
Il y a toujours deux balises:
- Ouvreur - texte entre crochets angulaires
<tag> - Clôture - le même texte (c'est important!), Mais le symbole "/" est ajouté
</tag>
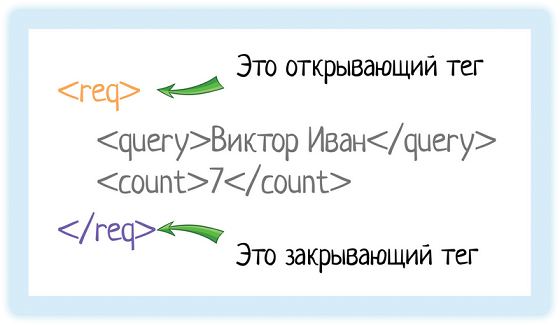
Oh, d'accord, je me suis fait prendre! Pas toujours. Il y a aussi des éléments vides, ils ont une balise, à la fois d'ouverture et de fermeture en même temps. Mais plus là-dessus plus tard!
À l'aide de balises, nous montrons le système "ici l'élément commence, et ici il se termine". C'est comme des panneaux de signalisation:
- A l'entrée de la ville, son nom est écrit: Moscou
- A la sortie, le même nom est écrit, mais barré:
* Un exemple avec des panneaux de signalisation que j'ai lu une fois il y a longtemps dans un article de Yandex, seulement je ne me souviens plus du lien. Et un excellent exemple!

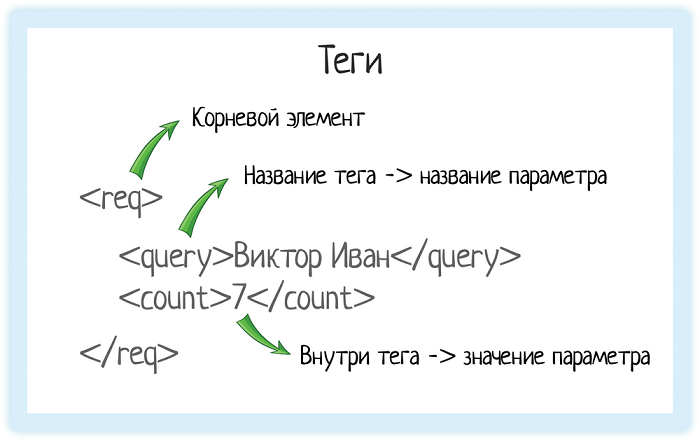
Élément racine
Tout document XML a un élément racine. Il s'agit de la balise à partir de laquelle le document commence et se termine. Dans le cas de l'API REST, un document est une demande que le système envoie. Ou la réponse qu'elle obtient.
Pour désigner cette requête, nous avons besoin d'un élément racine. Dans les info-bulles, l' élément racine est "req".

Cela pourrait être appelé différemment:
<main><sugg>Oui, peu importe. Il montre le début et la fin de notre demande, rien de plus. Mais à l'intérieur, il y a déjà le corps du document - la requête elle-même. Ces paramètres que nous transmettons au système externe. Bien sûr, ils seront également dans les balises, mais dans les balises normales, pas dans les balises racine.
Valeur de l'article
La valeur de l'élément est stockée entre les balises de début et de fin. Cela peut être un nombre, une chaîne ou même des balises imbriquées!
Ici, nous avons la balise "query". Il désigne la demande que nous envoyons aux info-bulles.

À l'intérieur - la valeur de la demande.
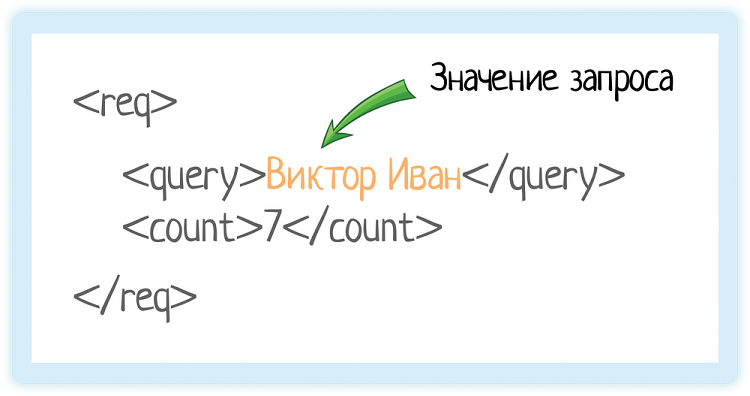
C'est comme si nous avions enfoncé la ligne «Victor Ivan» dans l'interface graphique (interface utilisateur graphique): L'
utilisateur n'a pas besoin d'un cerclage supplémentaire, il a besoin d'une belle forme. Mais le système doit en quelque sorte transmettre que «l'utilisateur a saisi exactement cela». Comment lui montrer où commence et où se termine la valeur passée? C'est à cela que servent les balises.
Le système voit la balise "query" et comprend qu'elle contient "une chaîne pour laquelle des invites doivent être renvoyées". Nombre de
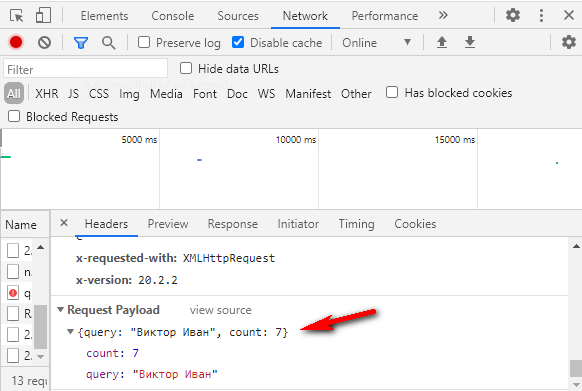
paramètres = 7indique le nombre d'indices à renvoyer dans la réponse. Si vous donnez des conseils sur le formulaire de démonstration de Dadata , 7 conseils nous reviendront. C'est parce que la valeur count = 7 y est cousue . Mais si vous vous référez à la documentation de la méthode , le nombre peut être sélectionné de 1 à 20.
Ouvrez la console développeur via f12 , onglet Réseau , et voyez quelle demande est envoyée au serveur. Il y aura un compte = 7 .
Voir aussi:
Ce qu'un testeur doit savoir sur le panneau des développeurs - En savoir plus sur l'utilisation de la console.
Remarque:
- Victor Ivan - chaîne
- 7 - numéro
Mais les deux valeurs sont sans guillemets. En XML, nous n'avons pas besoin de mettre la valeur de la chaîne entre guillemets (mais en JSON, nous devons le faire).
Attributs d'élément
Un élément peut avoir un ou plusieurs attributs. Nous les indiquons à l'intérieur de l'étiquette détachable après le nom de l'étiquette séparés par un espace dans le formulaire
_ = « »Par exemple:
<query attr1=“value 1”> </query>
<query attr1=“value 1” attr2=“value 2”> </query>
Pourquoi est-ce nécessaire? À partir des attributs, le système qui reçoit la demande d'API comprend ce qu'il a reçu.
Par exemple, nous effectuons une recherche sur le système, à la recherche de clients avec le nom Oleg. Nous envoyons une simple demande:
<query></query>Et en retour, nous recevons tout un pack d'Olegs! Avec différentes dates de naissance, numéros de téléphone et autres données. Disons que l'un des résultats de la recherche ressemble à ceci:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name"> </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Jetons un coup d'œil à cette entrée. Nous avons le parti élément principal .

Il a 3 attributs:
- type = «PHYSICAL» — . , : , , . , . ! , , — ,
- sourceSystem = «AL» — . , , .
- rawId = «2» — . , , . , ? sourceSystem + rawId!

Il y a des éléments de terrain à l'intérieur du groupe . Les éléments de champ ont un attribut de nom . La valeur de l'attribut est le nom du champ: nom, date de naissance, type ou numéro de téléphone. C'est ainsi que nous comprenons ce qui est caché sous un champ spécifique . Ceci est pratique du point de vue du support lorsque vous avez un produit en boîte et plus de 10 clients. Chaque client aura son propre ensemble de champs: quelqu'un a un DCI dans le système, quelqu'un n'en a pas, l'un est important sur la date de naissance, l'autre pas, etc. Mais, malgré la différence de modèles, tous les clients auront un schéma XSD (qui décrit la demande et la réponse): - il y a un élément partie; - il a des éléments de champ;


- chaque élément de champ a un attribut de nom qui stocke le nom du champ.
Mais les noms spécifiques des champs ne peuvent plus être décrits dans XSD. Ils "regardent déjà dans les savoirs traditionnels". Bien sûr, lorsqu'il n'y a qu'un seul client ou que vous créez un logiciel pour vous-même ou «en général pour tout le monde», il est plus pratique d'utiliser des champs nommés - c'est-à-dire des balises «parlantes». Quels sont les avantages de cette approche:
- Lors de la lecture de XSD, les champs réels sont immédiatement visibles. TK peut être obsolète et le code sera à jour
- La requête est facile à extraire manuellement dans SOAP Ui - elle créera immédiatement tous les champs nécessaires, il vous suffit de renseigner les valeurs. C'est pratique pour le testeur + le client teste parfois comme ça, il est aussi bon.
En général, toute approche a le droit d'exister. Il est nécessaire de regarder le projet, qui sera plus pratique pour vous. Dans mon exemple, j'ai des noms d'éléments non parlants - tous comme un serachamp . Mais par les attributs, vous pouvez déjà comprendre ce que c'est.
En plus des éléments de champ , la partie a un élément d' attribut . Ne confondez pas la notation xml et la lecture professionnelle:
- d'un point de vue commercial, il s'agit d'un attribut d'un individu, d'où le nom de l'élément - attribut .
- du point de vue de xml c'est un élément (pas un attribut!), il a simplement été nommé attribut . XML ne se soucie pas (presque) de la façon dont vous nommez les éléments, donc ça va.

L' attribut élément a des attributs:
- type = "PHONE" - type d'attribut. Après tout, ils peuvent être différents: téléphone, adresse, email ...
- rawId = "AL.2.PH.1" - identifiant dans le système source. Il est nécessaire pour la mise à jour. Après tout, un client peut avoir plusieurs téléphones, comment peut-on comprendre lequel est mis à jour sans identifiant?

Tel est le XML avéré. Et simplifié. Dans les vrais systèmes où les individus sont stockés, il y a beaucoup plus de données: environ 20 champs de l'individu lui-même, plusieurs adresses, numéros de téléphone, adresses e-mail ...
Mais lire même un énorme XML ne sera pas difficile si vous savez où se trouve. Et s'il est formaté, les éléments imbriqués sont décalés vers la droite, le reste est au même niveau. Ce sera difficile sans formatage ...
Et tout est si simple - nous avons des éléments enfermés dans des balises. À l'intérieur des balises se trouve le nom de l'élément. S'il y a quelque chose après le nom, séparé par un espace: ce sont les attributs de l'élément.
Prologue XML
Parfois, en haut du document XML, vous verrez quelque chose de similaire:
<?xml version="1.0" encoding="UTF-8"?>Cette ligne s'appelle le prologue XML. Il montre la version de XML utilisée dans le document, ainsi que l'encodage. Le prologue est facultatif, s'il n'y est pas - c'est ok. Mais si c'est le cas, alors ce doit être la première ligne du document XML.
UTF-8 est le codage par défaut pour les documents XML.
Schéma XSD
XSD ( X ML S chema D efinition) est votre description XML. À quoi devrait-il ressembler, que devrait-il être? C'est TK écrit dans le langage de la machine - après tout, nous écrivons le schéma ... Aussi au format XML! Le résultat est du XML qui décrit un autre XML.
L'astuce est que la vérification selon le schéma peut être déléguée à la machine. Et le développeur n'a même pas à planifier chaque vérification. Qu'il suffise de dire "voici un diagramme, vérifiez-le".
Si nous créons une méthode SOAP, alors nous indiquons dans le schéma:
- quels champs seront dans la demande;
- quels champs seront dans la réponse;
- quels types de données chaque champ possède;
- quels champs sont obligatoires et lesquels ne le sont pas;
- Le champ a-t-il une valeur par défaut et ce qu'elle est;
- Le champ a-t-il une limite de longueur?
- Le champ a-t-il d'autres paramètres?
- ;
- ...
Maintenant, lorsqu'une demande nous parvient, son exactitude est d'abord vérifiée conformément au schéma. Si la demande est correcte, nous lançons la méthode et élaborons la logique métier. Et cela peut être complexe et gourmand en ressources! Par exemple, créez un échantillon à partir d'une base de données de plusieurs millions de dollars. Ou effectuer une dizaine de vérifications sur différentes tables de bases de données ...
Alors pourquoi lancer une procédure complexe si la requête est visiblement «mauvaise»? Et donner une erreur après 5 minutes, et pas immédiatement? La validation de schéma permet de filtrer rapidement les demandes manifestement invalides sans surcharger le système.

De plus, certains programmes clients mettent une protection similaire pour l'envoi de requêtes. Par exemple, SOAP Ui peut vérifier votre demande de XML bien formé, et il ne l'enverra tout simplement pas au serveur si vous vous trompez. Gain de temps sur le transfert de données, bravo!

Et pour l'utilisateur simple de votre API SOAP, le schéma vous aide à comprendre comment composer une requête. Qu'est-ce qu'un «utilisateur commun»?
- Le développeur du système utilisant votre API - il doit écrire dans le code ce qu'il doit envoyer exactement de son système au vôtre.
- Un testeur qui a besoin de vérifier cette API même - il doit comprendre comment la demande est formée.
Oui, oui, idéalement, nous avons un savoir traditionnel détaillé, où tout est bien décrit. Mais hélas et ah, ce n'est pas toujours le cas. Parfois, les savoirs traditionnels n'existent tout simplement pas et parfois ils sont obsolètes. Mais le schéma ne deviendra pas obsolète, car il est mis à jour lorsque le code est mis à jour. Et cela aide simplement à comprendre à quoi devrait ressembler la demande.

En résumé, comment le schéma est utilisé lors du développement de l'API SOAP:
- Notre développeur écrit un schéma XSD pour la requête API: il faut passer un élément tel ou tel, qui aura tel ou tel enfant, avec tel ou tel type de données. Celles-ci sont obligatoires, elles ne le sont pas.
- Le développeur du système client, qui est intégré au nôtre, lit ce schéma et construit ses demandes en fonction de celui-ci.
- Le système client nous envoie des demandes.
- Notre système vérifie les demandes de XSD - si quelque chose ne va pas, c'est juste une secousse.
- Si la requête XSD a réussi la vérification, activez la logique métier!
Voyons maintenant à quoi pourrait ressembler le circuit! Prenez la méthode doRegister dans Users par exemple . Pour envoyer une demande, nous devons transmettre l'email, le nom et le mot de passe. Il existe des tonnes de façons d'écrire une requête correcte et incorrecte:
| Demande correcte | Requête invalide |
|---|---|
|
Aucun champ de nom requis |
|
Une faute de frappe dans le nom de la balise (courrier au lieu de courrier électronique) |
| ... | ... |
Essayons d'écrire un diagramme pour cela. La requête doit contenir 3 éléments ( email, nom, mot de passe ) de type "string" (string). Nous écrivons:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>Et dans le WSDl du service, c'est écrit encore plus facilement:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>Bien sûr, il peut y avoir plus que de simples éléments en ligne dans un schéma. Il peut s'agir de nombres, de dates, de valeurs booléennes et même de certains de leurs propres types:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>Vous pouvez également faire référence à un autre schéma dans un schéma, ce qui facilite l'écriture du code - vous pouvez réutiliser des schémas pour différentes tâches.
Voir aussi:
XSD - smart XML - article utile de Habr
XSD Schema Definition Language - il existe des tableaux pratiques avec des valeurs que vous pouvez utiliser
XSD Schema Description Language (XML-Schema)
Un exemple de schéma XML dans le tutoriel
Site officiel w3.org
Pratique: rédiger votre demande
Ok, maintenant nous savons comment "lire" une requête pour une méthode API au format XML. Mais comment le rédiger selon les savoirs traditionnels? Essayons. Nous regardons la documentation. Et c'est pourquoi je donne un exemple de Dadata - c'est une excellente documentation !

Que faire si je souhaite renvoyer uniquement les prénoms féminins commençant par "An"? Prenons notre exemple original:
<req>
<query> </query>
<count>7</count>
</req>Tout d'abord, nous modifions la demande elle-même. Désormais, ce n'est plus "Victor Ivan", mais "An":
<req>
<query></query>
<count>7</count>
</req>Ensuite, nous examinons les savoirs traditionnels. Comment retourner uniquement les pourboires féminins? Il existe un paramètre spécial - le sexe . Le nom du paramètre est le nom des balises. Et nous avons déjà mis le sol à l'intérieur. «Female» en anglais est FEMALE , dans la documentation également. Total reçu:
<req>
<query></query>
<count>7</count>
<gender>FEMALE</gender>
</req>Vous pouvez supprimer les fichiers inutiles. Si nous ne nous soucions pas du nombre d'indices, nous supprimons le paramètre count. Après tout, selon la documentation, c'est facultatif. Reçu une demande:
<req>
<query></query>
<gender>FEMALE</gender>
</req>C'est tout! Nous avons pris un exemple comme base, changé une valeur, ajouté un paramètre, supprimé un. Ce n'est pas si dur. Surtout quand il y a une spécification détaillée et un exemple)))
Essayez-le vous-même!
Écrivez une demande pour la méthode MagicSearch dans Utilisateurs. Nous voulons trouver tous les Ivanov par pure coïncidence, sur lesquels reposent des tâches urgentes.
XML bien formé
Il appartient au développeur de décider quel XML est correct et lequel ne l'est pas. Mais il existe des règles générales qui ne peuvent être violées. Le XML doit être bien formé, c'est-à-dire syntaxiquement correct.
Pour vérifier la syntaxe XML, vous pouvez utiliser n'importe quel validateur XML (et google). Je recommande le site w3schools . Il y a le validateur lui-même + une description des erreurs typiques avec des exemples.
Dans le validateur terminé, vous insérez simplement votre XML (par exemple, une requête pour le serveur) et voyez si tout va bien. Mais vous pouvez le vérifier vous-même. Parcourez les règles de syntaxe et voyez si votre requête les suit.
Règles XML bien formées:
- Il y a un élément racine.
- Chaque élément a une balise de fermeture.
- Les balises sont sensibles à la casse!
- L'imbrication correcte des éléments est respectée.
- Les attributs sont entre guillemets.
Passons en revue chaque règle et discutons de la manière dont nous pouvons les appliquer dans les tests. Autrement dit, comment «casser» correctement une requête en la comparant à un XML bien formé. Pourquoi est-ce nécessaire? Regardez les commentaires du système. Pouvez-vous comprendre à partir du texte de l'erreur exactement où vous vous êtes trompé?
Voir aussi: Les
messages d'erreur sont aussi de la documentation, testez-les! - pourquoi tester les messages d'erreur
1. Il y a un élément racine
Vous ne pouvez pas simplement mettre 2 XML côte à côte et supposer que «le système comprendra de lui-même qu'il s'agit de deux requêtes, pas d'une seule». Je ne comprendrai pas. Parce que tu ne devrais pas.
Et si vous avez plusieurs balises d'affilée sans parent commun, c'est un mauvais XML, pas bien formé. Il devrait toujours y avoir un élément racine:
| Non | Oui |
|---|---|
Il y a des éléments "test" et "dev", mais ils sont situés l'un à côté de l'autre, mais il n'y a pas de racine, à l'intérieur de laquelle tout se trouve. Cela ressemble plus à 2 documents XML |
Et ici, il y a déjà un élément d'identification, qui est la racine |
Que faisons-nous pour tester cette condition? C'est vrai, nous supprimons les balises racine de notre requête!
2. Chaque élément a une balise de fermeture
Tout est simple ici - si une balise s'est ouverte quelque part, elle doit se fermer quelque part. Envie de casser? Supprimez la balise de fermeture de tout élément.
Mais ici, il convient de noter qu'il ne peut y avoir qu'une seule balise. Si l'élément est vide, on peut s'en tirer avec une balise en la fermant à la fin:
<name/>C'est la même chose que de lui passer une valeur vide
<name></name>De même, le serveur peut nous renvoyer une valeur de balise vide. Vous pouvez essayer d'envoyer des champs vides aux utilisateurs dans la méthode FullUpdateUser . Et cela est acceptable dans la requête (j'ai envoyé le champ name1 vide ), et dans la réponse SOAP Ui, il nous rend exactement les champs vides.

Total - s'il y a une balise d'ouverture, il doit y avoir une balise de fermeture. Ou ce sera une balise avec une barre oblique à la fin.
Pour les tests, supprimez toute balise de fermeture dans la requête.
| Non | Oui |
|---|---|
|
|
|
|
3. Les balises sont sensibles à la casse
Comme ils ont écrit le premier - nous écrivons également le dernier. SIMILAIRE! Et pas comme tu le voulais.
Mais pour les tests, nous changeons le registre de l'une des pièces. Un tel XML sera invalide
| Non | Oui |
|---|---|
|
|
4. Imbrication correcte des éléments
Les éléments peuvent aller l'un après l'autre
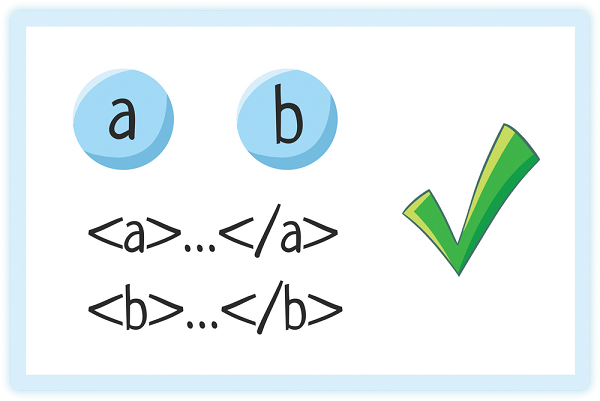
Un élément peut être imbriqué dans un autre

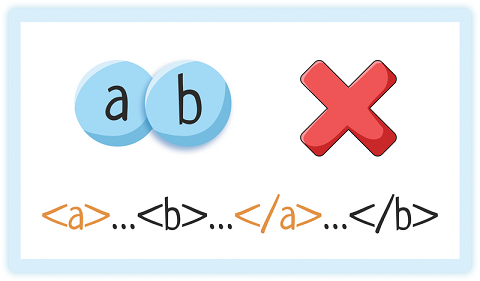
Mais les éléments ne peuvent PAS se chevaucher!
| Non | Oui |
|---|---|
|
|
|
|
5. Les attributs sont entre guillemets
Même si vous considérez l'attribut comme un nombre, il sera cité:
<query attr1=“123”> </query>
<query attr1=“” attr2=“123” > </query>À des fins de test, nous essayons de le passer sans guillemets:
<query attr1=123> </query>Total
XML (e X tensible M arkup L anguage) est utilisé pour stocker et transférer des données.
— API-. SOAP-, . SOAP XML. REST, — XML, JSON.
— XML . , . XML - , , - .
XML open-source folks. , JacksonJsonProvider, «» — , (featuresToEnable), , (featuresToDisable).
Le format XML suit les normes. Une requête syntaxiquement incorrecte n'ira même pas sur le serveur, le client la coupera. Bien formé d'abord, puis logique métier.
Règles XML bien formées:
- Il y a un élément racine.
- Chaque élément a une balise de fermeture.
- Les balises sont sensibles à la casse!
- L'imbrication correcte des éléments est respectée.
- Les attributs sont entre guillemets.

Si vous êtes un testeur, lorsque vous testez des requêtes XML, assurez-vous d'essayer d'enfreindre toutes les règles! Oui, le système doit être capable de gérer de telles erreurs et de renvoyer un message d'erreur adéquat. Mais elle ne fait pas toujours cela.
Et si le système est public et renvoie une réponse vide à une demande incorrecte, c'est mauvais. Parce que le développeur d'un autre système le corrigera dans la requête, et par la réponse vide, il ne comprendra même pas où exactement. Et ça va harceler le support: "Qu'est-ce qui ne va pas avec moi?", Lancement d'informations morceau par morceau et sous forme de captures d'écran du code source. En as-tu besoin? Non? Ensuite, assurez-vous que le système vous donne un message d'erreur clair!
Voir aussi:
Qu'est-ce que XML
Tutorial
XML Apprendre XML. Eric Ray (Livre XML)
Notes sur XML et XLST
PS - Recherchez des articles plus utiles dans mon blog sous la balise «utile» . Et des vidéos utiles sont sur ma chaîne youtube