
Source de l'image
Deux révolutions dans le traitement du langage naturel
La première révolution de la PNL a été associée au succès des modèles basés sur des représentations vectorielles de la sémantique d'un langage, obtenues par des méthodes d'apprentissage non supervisées. La floraison de ces modèles a commencé avec la publication des résultats de Tomáš Mikolov , doctorant Yoshua Bengio (l'un des pères fondateurs de l'apprentissage profond moderne, lauréat du prix Turing) et l'émergence de l'outil populaire word2vec. La deuxième révolution a commencé avec le développement de mécanismes d'attention dans les réseaux de neurones récurrents, ce qui a permis de comprendre que le mécanisme d'attention est autosuffisant et pourrait bien être utilisé sans le réseau récurrent lui-même. Le modèle de réseau neuronal qui en résulte est appelé le «transformateur». Il a été présenté à la communauté scientifique en 2017 dans un article intitulé «Attention Is All You Need », rédigé par un groupe de chercheurs de Google Brain et Google Research. Le développement rapide des réseaux basés sur des transformateurs a abouti à des modèles de langage géants comme le Generative Pre-Training Transformer 3 (GPT-3) d' OpenAIcapable de résoudre efficacement de nombreux problèmes de PNL.
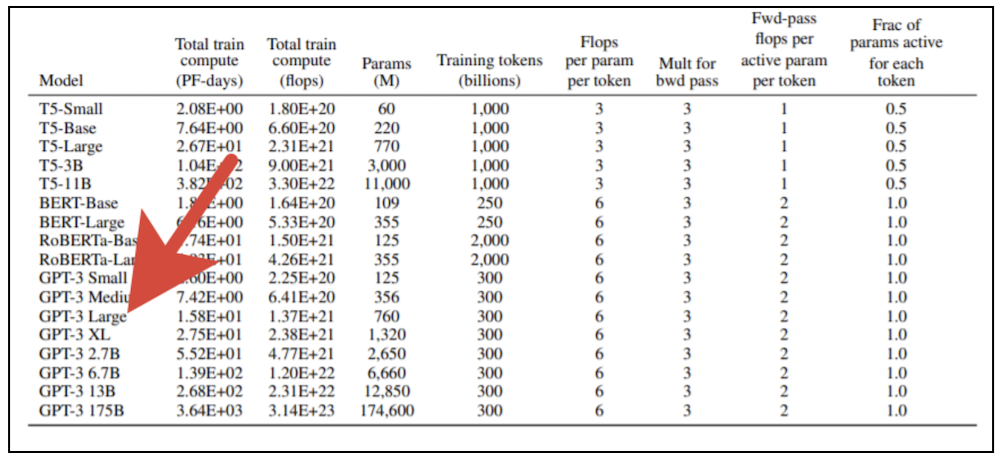
Il faut des ressources informatiques importantes pour former des modèles de transformateurs géants. Vous ne pouvez pas simplement prendre une carte graphique moderne et entraîner un tel modèle sur votre ordinateur personnel. La publication originale d'OpenAI présente 8 variantes du modèle, et si vous prenez la plus petite d'entre elles (GPT-3 Small) avec 125 millions de paramètres et essayez de l'entraîner à l'aide d'une carte vidéo professionnelle NVidia V100 équipée de puissants cœurs de tenseur, cela prendra environ six mois. Si nous prenons la plus grande version du modèle avec 175 milliards de paramètres, le résultat devra attendre près de 500 ans. Le coût de la formation de la plus grande version du modèle aux tarifs des services cloud qui fournissent des appareils informatiques modernes à la location,dépasse le milliard de roubles (et cela reste soumis à une mise à l'échelle linéaire des performances avec une augmentation du nombre de processeurs impliqués, ce qui est en principe impossible à atteindre).
Vive les supercalculateurs!
Il est clair que de telles expériences ne sont disponibles que pour les entreprises disposant de ressources informatiques importantes. Pour résoudre ces problèmes, la Sberbank a mis en service en 2019 le supercalculateur Christophari , qui a pris la première place en performance parmi les supercalculateurs disponibles dans notre pays. 75 nœuds de calcul DGX-2 (chacun avec 16 cartes NVidia V100 ) connectés par un bus ultra-rapide basé sur la technologie Infinibandvous permettent de former GPT-3 Small en quelques heures seulement. Cependant, même pour une telle machine, la tâche de former des variantes plus grandes du modèle n'est pas anodine. Premièrement, une partie de la machine est engagée dans la formation d'autres modèles conçus pour résoudre des problèmes dans le domaine de la vision par ordinateur, de la reconnaissance et de la synthèse de la parole et de nombreux autres domaines d'intérêt pour diverses entreprises de l'écosystème Sberbank. Deuxièmement, le processus d'apprentissage lui-même, qui utilise simultanément de nombreux nœuds de calcul dans une situation où les poids du modèle ne tiennent pas dans la mémoire d'une carte, est plutôt non standard.
En général, nous nous trouvions dans une situation où la torche distribuée, familière à beaucoup, ne convenait pas à nos fins. Nous n'avions pas autant d'options, nous nous sommes donc tournés vers l'implémentation "native" pour NVidia Megatron-LMet la nouvelle invention de Microsoft - DeepSpeed , qui a nécessité la création de conteneurs Docker personnalisés sur Christophari, avec lesquels nos collègues de SberCloud nous ont rapidement aidés . DeepSpeed, tout d'abord, nous a donné des outils pratiques pour la formation en parallèle de modèles, c'est-à-dire la diffusion d'un modèle sur plusieurs GPU et pour le partage de l'optimiseur entre les GPU. Cela vous permet d'utiliser des lots plus importants, ainsi que des modèles de train avec plus de 1,5 milliard de poids sans une montagne de code supplémentaire.
Étonnamment, la technologie au cours du dernier demi-siècle dans son développement a décrit le prochain tour de la spirale - il semble que l'ère des mainframes (ordinateurs puissants avec accès aux terminaux) est de retour. Nous sommes déjà habitués au fait que les principaux outils de développement sont un ordinateur personnel attribué à l'usage exclusif du développeur. À la fin des années 60 et au début des années 70, une heure de fonctionnement du mainframe coûtait à peu près le même prix qu'un mois complet de salaire pour un opérateur informatique! Il semblait que ces temps étaient révolus pour toujours et que le «fer» devenait à jamais moins cher que le temps de travail. Cependant, il semble que le matériel ait fait un retour impressionnant. La vie quotidienne d'un spécialiste moderne de l'apprentissage automatique ressemble à nouveau à la vie quotidienne de Sasha Privalov d'après l'histoire des frères Strugatsky "Lundi commence le samedi", à la seule différence que la place d '"Aldan" dans notre cas est prise par "Christofari", et le rôle de la magie et de la sorcellerie est joué par des méthodes d'apprentissage en profondeur.
De l'expérience SberDevices
Plusieurs fois dans le passé, nous avons dû apprendre d'autres modèles basés sur des transformateurs - il s'agit de divers héritiers de BERT et de modèles d'encodeur-décodeur, comme le T5 de Google . Assistants virtuels créés par SberDevices pour différentes surfaces, à commencer par les dernières SberBox et SberPortalet se terminant par l'application habituelle Sberbank Online, ils utilisent plusieurs modèles similaires dans leur travail pour résoudre divers problèmes au cours de la communication avec l'utilisateur. Par exemple, l'assistant virtuel Joy utilise le modèle GPT-2 Medium en mode chat, formé sur un grand corpus de littérature russe, formé sur un jeu de données de dialogue spécial et équipé d'un mécanisme de classement spécial conçu pour sélectionner les réponses les plus intéressantes. Ces modèles sont capables de mener une conversation avec l'utilisateur, non pas en choisissant des indices dans une bibliothèque de réponses pré-préparée, mais en créant leurs propres phrases à la volée, ce qui rend la communication avec eux plus variée et divertissante.
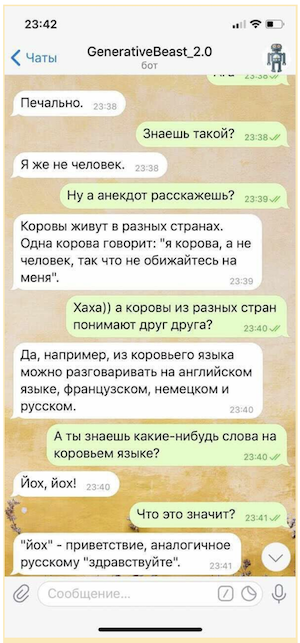

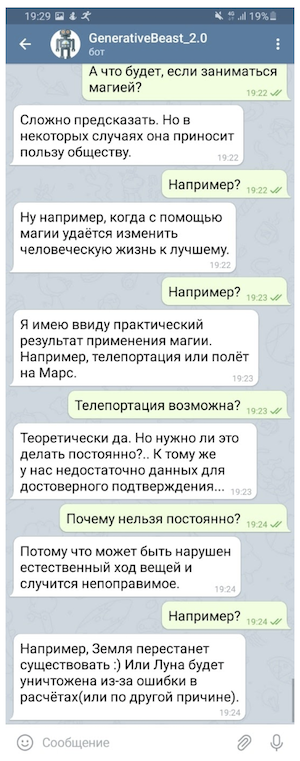
Bien sûr, un tel «bavardage» ne peut pas être utilisé sans une certaine assurance sous la forme d'un système de microintents (règles conçues pour fournir des réponses contrôlées à certaines des questions les plus sensibles) et d'un modèle séparé conçu pour éviter les questions provocantes, mais même sous une forme aussi limitée Le «bavardage» «génératif» est capable de rehausser considérablement l'humeur de son interlocuteur.
En un mot, notre expérience dans l'enseignement de grands modèles de transformateurs s'est avérée utile lorsque la direction de Sberbank a décidé d'allouer des ressources informatiques à un projet de recherche visant à former GPT-3. Un tel projet exigeait de combiner les efforts de plusieurs unités à la fois. Du côté de SberDevices, le rôle de leadership dans ce processus a été assumé par le Département des systèmes expérimentaux d'apprentissage automatique (avec la participation d'un certain nombre d'experts d'autres équipes), et de la part de Sberbank.AI - par l'équipe AGI NLP . Nos collègues de SberCloud, qui soutiennent Christophari, ont également activement rejoint le projet.
En collaboration avec des collègues de l'équipe AGI NLP, nous avons réussi à assembler la première version du corpus de formation en russe avec un volume total de plus de 600 Go. Il comprend une énorme collection de littérature russe, des instantanés de Wikipedia russe et anglais, une collection d'instantanés de sites d'actualités et de questions - réponses , des sections publiques de Pikabu , une collection complète de documents du portail scientifique populaire 22century.ru et du portail bancaire banki.ru , ainsi que du corpus Omnia Russica . De plus, comme nous voulions expérimenter la capacité de gérer le code du programme, nous avons inclus des instantanés de github et de StackOverflow dans le corpus de formation.... L'équipe AGI NLP a effectué beaucoup de nettoyage et de déduplication des données, ainsi que la préparation des kits de validation et de test des modèles. Si dans le corpus original utilisé par OpenAI, le rapport de l'anglais aux autres langues est de 93: 7, alors dans notre cas, le rapport du russe aux autres langues est d'environ 9: 1.
Nous avons choisi les architectures GPT-3 Medium (350 millions de paramètres) et GPT-3 Large (760 millions de paramètres) comme base des premières expériences. Ce faisant, nous avons formé le modèle comme avec une alternance de blocs transformateur avec un clairseméeet des mécanismes et des modèles d'attention dense dans lesquels tous les blocs d'attention étaient complets. Le fait est que le travail original d'OpenAI parle de l'entrelacement de blocs, mais ne fournit pas leur séquence spécifique. Si tous les blocs d'attention dans le modèle sont complets, cela augmente le coût de calcul de la formation, mais garantit que le potentiel prédictif du modèle est pleinement utilisé. Actuellement, la communauté scientifique étudie activement divers modèles d'attention, conçus pour réduire les coûts de calcul des modèles de formation et augmenter la précision. En peu de temps, les chercheurs ont proposé un longformer , un reformeur , un transformateur avec une durée d'attention adaptative., transformateur compressif , transformateur par blocs , BigBird , linformer et un certain nombre d'autres modèles similaires. Nous sommes également engagés dans des recherches dans ce domaine, alors que les modèles composés uniquement de blocs denses sont une sorte de benchmark qui nous permet d'évaluer le degré de diminution de la précision des différentes versions «accélérées» du modèle.
Concours "AI 4 Humanities: ruGPT-3"
Cette année, dans le cadre d'AI Journey, l'équipe Sberbank.AI a organisé le concours AI 4 Humanities: ruGPT-3. Dans le cadre du test global, les participants sont invités à soumettre des prototypes de solutions pour tout problème commercial ou social créé à l'aide du modèle ruGPT-3 pré-formé. Les participants à la nomination spéciale "AIJ Junior" sont invités à créer une solution pour générer des essais significatifs sur quatre sujets humanitaires (langue russe, histoire, littérature, sciences sociales) de 11e année (USE) sur la base de ruGPT-3 sur la base de ruGPT-3 pour un sujet / texte donné du devoir.
Surtout pour ces compétitions, nous avons formé trois versions du modèle GPT-3: 1) GPT-3 Medium, 2) GPT-3 Large avec alternance de blocs clairsemés et denses du transformateur, 3) le plus "puissant" GPT-3 Large, composé uniquement de blocs denses. Les jeux de données d'entraînement et les tokenizers sont identiques pour tous les modèles - le tokenizer BBPE et notre jeu de données personnalisé Large1 avec un volume de 600 Go ont été utilisés (sa composition est donnée dans le texte ci-dessus).
Les trois modèles sont disponibles en téléchargement dans le référentiel du concours.
Voici quelques exemples amusants du fonctionnement du troisième modèle:



Comment des modèles comme GPT-3 vont-ils changer notre monde?
Il est important de comprendre que les modèles comme GPT-1/2/3, en fait, résolvent exactement un problème - ils essaient de prédire le prochain jeton (généralement un mot ou une partie de celui-ci) dans la séquence des précédents. Cette approche permet d'utiliser des données «non étiquetées» pour la formation, c'est-à-dire de se passer d'un «enseignant», et d'autre part, elle permet de résoudre un assez large éventail de problèmes du domaine de la PNL. En effet, dans le texte d'un dialogue, par exemple, une réponse-réponse est une continuation de l'histoire de la communication, dans une œuvre de fiction - le texte de chaque paragraphe continue le texte précédent, et dans une séance de questions-réponses, le texte de la réponse suit le texte de la question. En conséquence, les modèles à grande capacité peuvent résoudre de nombreux problèmes de ce type sans formation supplémentaire spéciale - ils n'ont besoin que des exemples qui s'inscrivent dans le «contexte du modèle»que GPT-3 a assez impressionnant - jusqu'à 2048 jetons.
GPT-3 est capable non seulement de générer des textes (y compris des poèmes, des blagues et des parodies littéraires), mais aussi de corriger des erreurs grammaticales, de mener des dialogues et même (HORS ÉTAT!) Écrire du code de programme plus ou moins significatif. De nombreuses utilisations intéressantes de GPT-3 peuvent être trouvées sur le site du chercheur indépendant Gwern Branwen. Branuen, développant une idée exprimée dans un tweet blague d'Andrej Karpathy, pose une question intéressante: assistons-nous à l'émergence d'un nouveau paradigme de programmation?
Voici le texte du tweet original de Karpaty:
«J'adore l'idée du logiciel 3.0. La programmation passe de la préparation des ensembles de données à la préparation des requêtes qui permettent au système de méta-apprentissage de «comprendre» l'essence de la tâche qu'il doit effectuer. LOL "[J'adore l'idée du logiciel 3.0. La programmation passe de la conservation des ensembles de données à la conservation des invites pour que le méta-apprenant «obtienne» la tâche qu'il est censé accomplir. LOL].
Développant l'idée de Karpaty, Branuen écrit:
« GPT-3 [ ] , : , , , ( GPT-2); , , , [prompt], , , «» - , , . , , «» «», GPT-3 . « » , : , , , , , , , , , ».
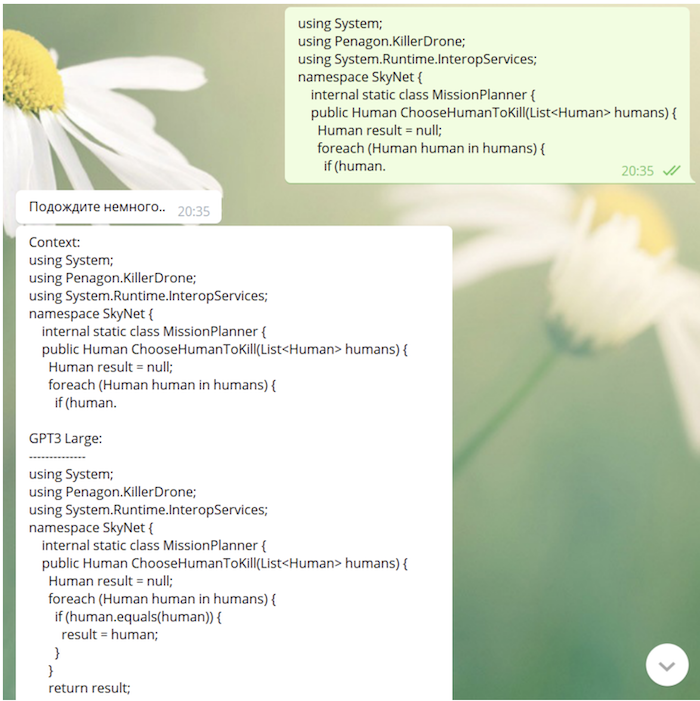
Puisque notre modèle a "vu" github et StackOverflow dans le processus d'apprentissage, il est tout à fait capable d'écrire du code (parfois pas dépourvu de sens très profond):
Et après
Cette année, nous continuerons à travailler sur des modèles de transformateurs géants. D'autres plans sont liés à l'expansion et au nettoyage des ensembles de données (ils comprendront en particulier des instantanés du service de pré-impression arxiv.org pour les publications scientifiques et la bibliothèque de recherche PubMed Central, des ensembles de données de dialogue spécialisés et des ensembles de données sur la logique symbolique), augmentant la taille des modèles formés, ainsi que l'utilisation tokenizer amélioré.
Nous espérons que la publication de modèles formés stimulera le travail des chercheurs et développeurs russes qui ont besoin de modèles de langage super puissants, car sur la base de ruGPT-3, vous pouvez créer vos propres produits originaux, résoudre divers problèmes scientifiques et commerciaux. Essayez d'utiliser nos modèles, expérimentez-les et assurez-vous de partager tous les résultats que vous obtenez. Le progrès scientifique rend notre monde meilleur et plus intéressant, améliorons le monde ensemble!